 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExVerus: Verus Proof Repair via Counterexample Reasoning
Mar 26, 2026Large Language Models (LLMs) have shown promising results in automating formal verification. However, existing approaches treat proof generation as a static, end-to-end prediction over source code, relying on limited verifier feedback and lacking access to concrete program behaviors. We present EXVERUS, a counterexample-guided framework that enables LLMs to reason about proofs using behavioral feedback via counterexamples. When a proof fails, EXVERUS automatically generates and validates counterexamples, and then guides the LLM to generalize them into inductive invariants to block these failures. Our evaluation shows that EXVERUS significantly improves proof accuracy, robustness, and token efficiency over the state-of-the-art prompting-based Verus proof generator.
A Neurosymbolic Approach to Natural Language Formalization and Verification
Nov 12, 2025Large Language Models perform well at natural language interpretation and reasoning, but their inherent stochasticity limits their adoption in regulated industries like finance and healthcare that operate under strict policies. To address this limitation, we present a two-stage neurosymbolic framework that (1) uses LLMs with optional human guidance to formalize natural language policies, allowing fine-grained control of the formalization process, and (2) uses inference-time autoformalization to validate logical correctness of natural language statements against those policies. When correctness is paramount, we perform multiple redundant formalization steps at inference time, cross checking the formalizations for semantic equivalence. Our benchmarks demonstrate that our approach exceeds 99% soundness, indicating a near-zero false positive rate in identifying logical validity. Our approach produces auditable logical artifacts that substantiate the verification outcomes and can be used to improve the original text.
Detecting Buggy Contracts via Smart Testing
Sep 06, 2024



Smart contracts are susceptible to critical vulnerabilities. Hybrid dynamic analyses, such as concolic execution assisted fuzzing and foundation model assisted fuzzing, have emerged as highly effective testing techniques for smart contract bug detection recently. This hybrid approach has shown initial promise in real-world benchmarks, but it still suffers from low scalability to find deep bugs buried in complex code patterns. We observe that performance bottlenecks of existing dynamic analyses and model hallucination are two main factors limiting the scalability of this hybrid approach in finding deep bugs. To overcome the challenges, we design an interactive, self-deciding foundation model based system, called SmartSys, to support hybrid smart contract dynamic analyses. The key idea is to teach foundation models about performance bottlenecks of different dynamic analysis techniques, making it possible to forecast the right technique and generates effective fuzz targets that can reach deep, hidden bugs. To prune hallucinated, incorrect fuzz targets, SmartSys feeds foundation models with feedback from dynamic analysis during compilation and at runtime. The interesting results of SmartSys include: i) discovering a smart contract protocol vulnerability that has escaped eleven tools and survived multiple audits for over a year; ii) improving coverage by up to 14.3\% on real-world benchmarks compared to the baselines.
Leveraging Large Language Models for Automated Proof Synthesis in Rust
Nov 07, 2023Formal verification can provably guarantee the correctness of critical system software, but the high proof burden has long hindered its wide adoption. Recently, Large Language Models (LLMs) have shown success in code analysis and synthesis. In this paper, we present a combination of LLMs and static analysis to synthesize invariants, assertions, and other proof structures for a Rust-based formal verification framework called Verus. In a few-shot setting, LLMs demonstrate impressive logical ability in generating postconditions and loop invariants, especially when analyzing short code snippets. However, LLMs lack the ability to retain and propagate context information, a strength of traditional static analysis. Based on these observations, we developed a prototype based on OpenAI's GPT-4 model. Our prototype decomposes the verification task into multiple smaller ones, iteratively queries GPT-4, and combines its output with lightweight static analysis. We evaluated the prototype with a developer in the automation loop on 20 vector-manipulating programs. The results demonstrate that it significantly reduces human effort in writing entry-level proof code.
Learning Nonlinear Loop Invariants with Gated Continuous Logic Networks
Apr 10, 2020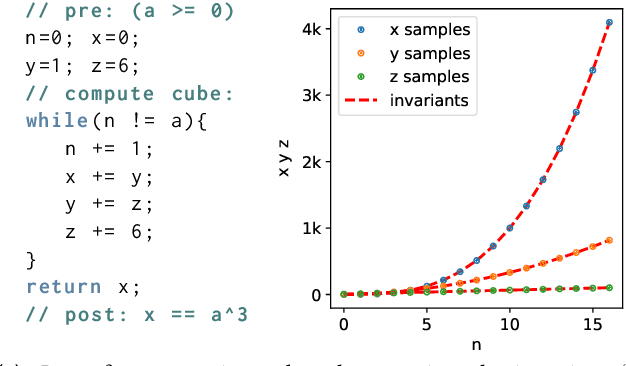
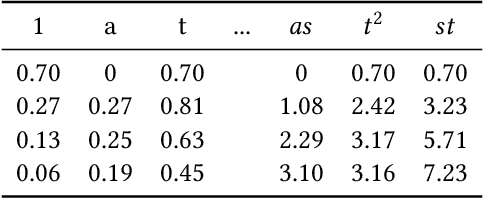
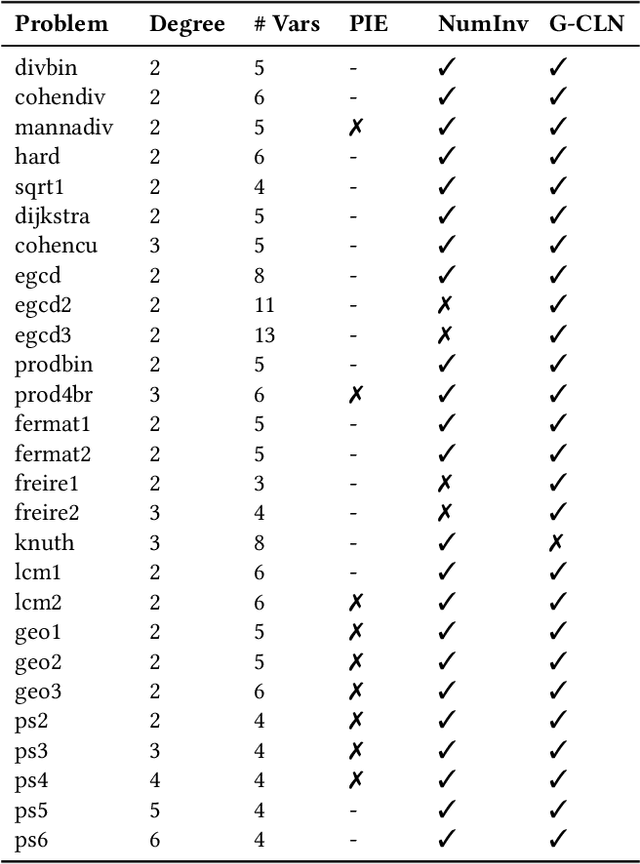
Verifying real-world programs often requires inferring loop invariants with nonlinear constraints. This is especially true in programs that perform many numerical operations, such as control systems for avionics or industrial plants. Recently, data-driven methods for loop invariant inference have shown promise, especially on linear invariants. However, applying data-driven inference to nonlinear loop invariants is challenging due to the large numbers of and magnitudes of high-order terms, the potential for overfitting on a small number of samples, and the large space of possible inequality bounds. In this paper, we introduce a new neural architecture for general SMT learning, the Gated Continuous Logic Network (G-CLN), and apply it to nonlinear loop invariant learning. G-CLNs extend the Continuous Logic Network (CLN) architecture with gating units and dropout, which allow the model to robustly learn general invariants over large numbers of terms. To address overfitting that arises from finite program sampling, we introduce fractional sampling---a sound relaxation of loop semantics to continuous functions that facilitates unbounded sampling on real domain. We additionally design a new CLN activation function, the Piecewise Biased Quadratic Unit (PBQU), for naturally learning tight inequality bounds. We incorporate these methods into a nonlinear loop invariant inference system that can learn general nonlinear loop invariants. We evaluate our system on a benchmark of nonlinear loop invariants and show it solves 26 out of 27 problems, 3 more than prior work, with an average runtime of 53.3 seconds. We further demonstrate the generic learning ability of G-CLNs by solving all 124 problems in the linear Code2Inv benchmark. We also perform a quantitative stability evaluation and show G-CLNs have a convergence rate of $97.5\%$ on quadratic problems, a $39.2\%$ improvement over CLN models.
CLN2INV: Learning Loop Invariants with Continuous Logic Networks
Oct 17, 2019
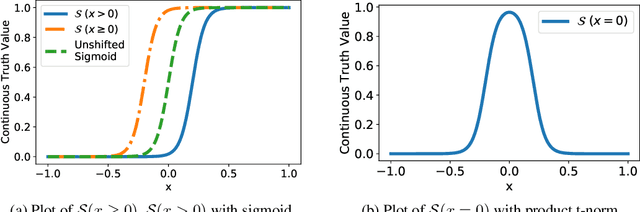

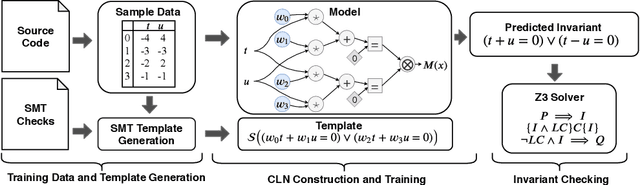
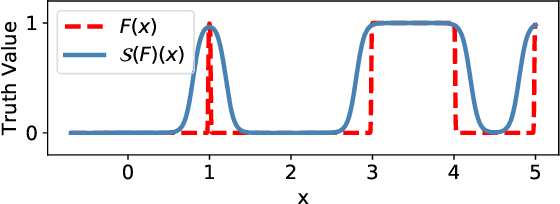
Program verification offers a framework for ensuring program correctness and therefore systematically eliminating different classes of bugs. Inferring loop invariants is one of the main challenges behind automated verification of real-world programs which often contain many loops. In this paper, we present Continuous Logic Network (CLN), a novel neural architecture for automatically learning loop invariants directly from program execution traces. Unlike existing neural networks, CLNs can learn precise and explicit representations of formulas in Satisfiability Modulo Theories (SMT) for loop invariants from program execution traces. We develop a new sound and complete semantic mapping for assigning SMT formulas to continuous truth values that allows CLNs to be trained efficiently. We use CLNs to implement a new inference system for loop invariants, CLN2INV, that significantly outperforms existing approaches on the popular Code2Inv dataset. CLN2INV is the first tool to solve all 124 theoretically solvable problems in the Code2Inv dataset. Moreover, CLN2INV takes only 1.1 seconds on average for each problem, which is 40 times faster than existing approaches. We further demonstrate that CLN2INV can even learn 12 significantly more complex loop invariants than the ones required for the Code2Inv dataset.