 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeaded Span-Based Projective Dependency Parsing
Aug 10, 2021
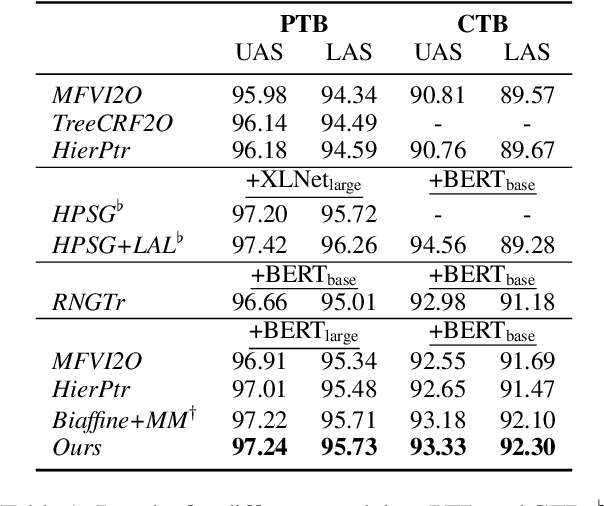
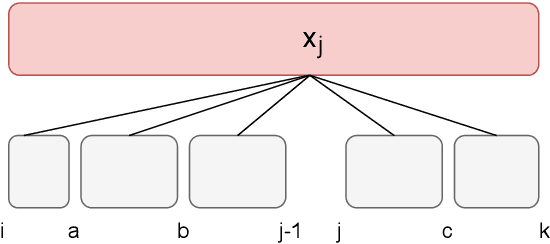

We propose a headed span-based method for projective dependency parsing. In a projective tree, the subtree rooted at each word occurs in a contiguous sequence (i.e., span) in the surface order, we call the span-headword pair \textit{headed span}. In this view, a projective tree can be regarded as a collection of headed spans. It is similar to the case in constituency parsing since a constituency tree can be regarded as a collection of constituent spans. Span-based methods decompose the score of a constituency tree sorely into the score of constituent spans and use the CYK algorithm for global training and exact inference, obtaining state-of-the-art results in constituency parsing. Inspired by them, we decompose the score of a dependency tree into the score of headed spans. We use neural networks to score headed spans and design a novel $O(n^3)$ dynamic programming algorithm to enable global training and exact inference. We evaluate our method on PTB, CTB, and UD, achieving state-of-the-art or comparable results.
Enhanced Universal Dependency Parsing with Automated Concatenation of Embeddings
Jul 06, 2021
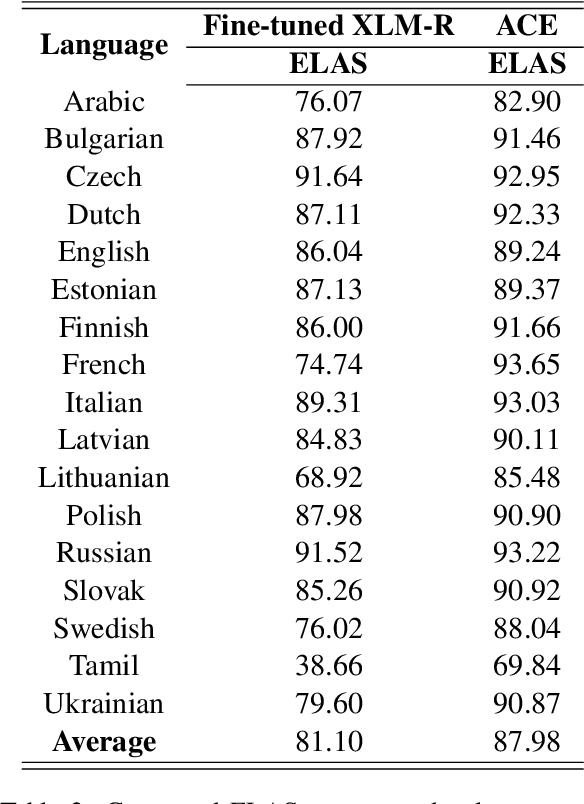
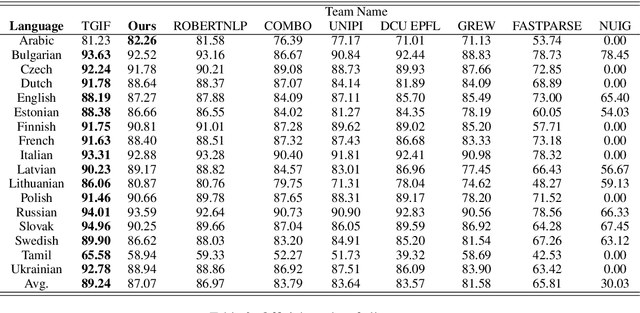
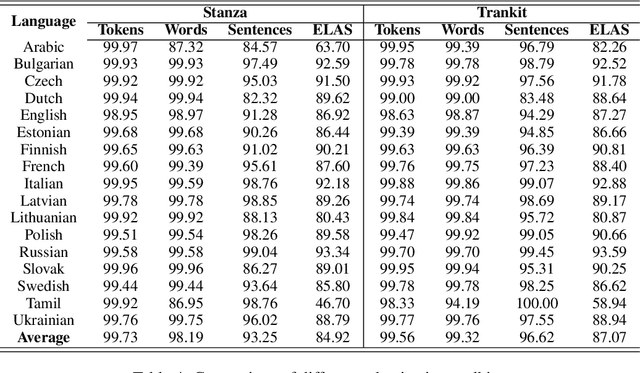
This paper describes the system used in submission from SHANGHAITECH team to the IWPT 2021 Shared Task. Our system is a graph-based parser with the technique of Automated Concatenation of Embeddings (ACE). Because recent work found that better word representations can be obtained by concatenating different types of embeddings, we use ACE to automatically find the better concatenation of embeddings for the task of enhanced universal dependencies. According to official results averaged on 17 languages, our system ranks 2nd over 9 teams.
Improving Named Entity Recognition by External Context Retrieving and Cooperative Learning
Jun 02, 2021
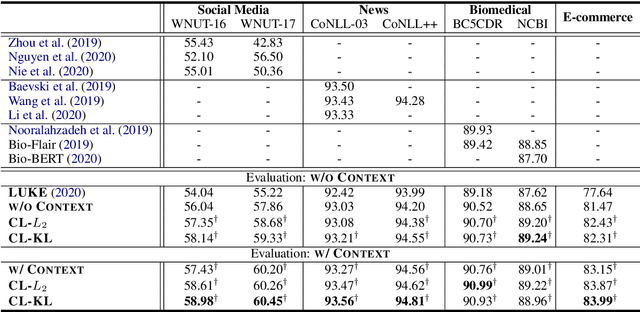
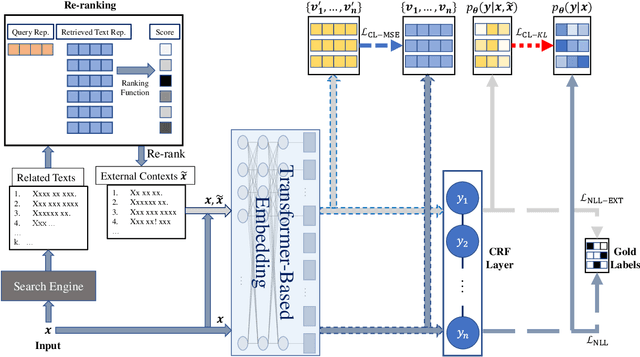
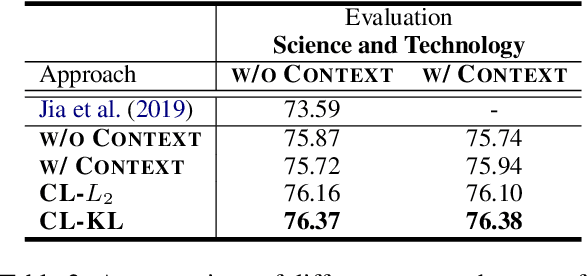
Recent advances in Named Entity Recognition (NER) show that document-level contexts can significantly improve model performance. In many application scenarios, however, such contexts are not available. In this paper, we propose to find external contexts of a sentence by retrieving and selecting a set of semantically relevant texts through a search engine, with the original sentence as the query. We find empirically that the contextual representations computed on the retrieval-based input view, constructed through the concatenation of a sentence and its external contexts, can achieve significantly improved performance compared to the original input view based only on the sentence. Furthermore, we can improve the model performance of both input views by Cooperative Learning, a training method that encourages the two input views to produce similar contextual representations or output label distributions. Experiments show that our approach can achieve new state-of-the-art performance on 8 NER data sets across 5 domains.
Neural Bi-Lexicalized PCFG Induction
May 31, 2021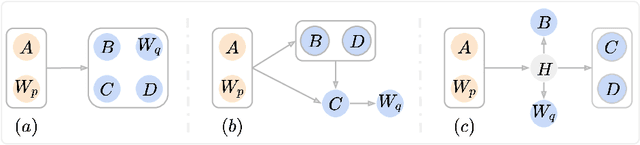

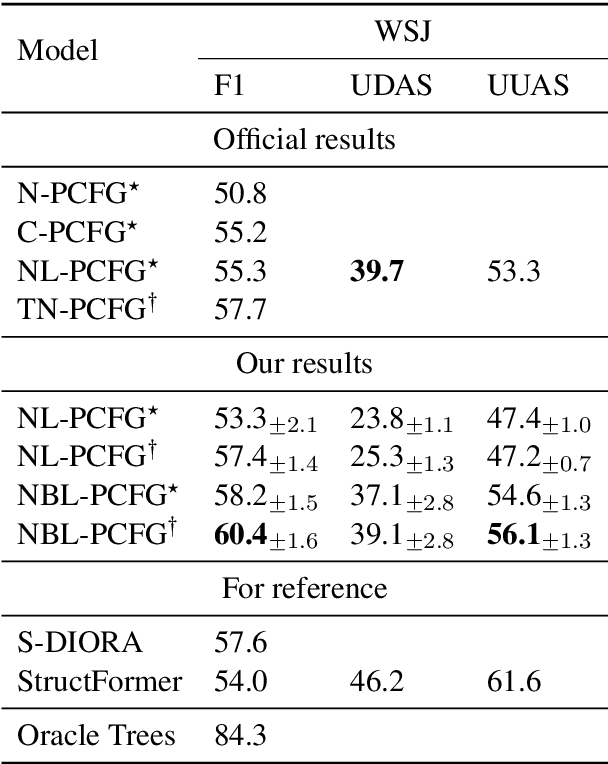
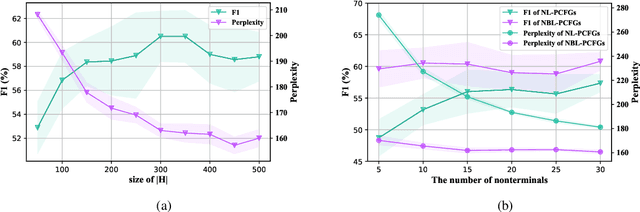
Neural lexicalized PCFGs (L-PCFGs) have been shown effective in grammar induction. However, to reduce computational complexity, they make a strong independence assumption on the generation of the child word and thus bilexical dependencies are ignored. In this paper, we propose an approach to parameterize L-PCFGs without making implausible independence assumptions. Our approach directly models bilexical dependencies and meanwhile reduces both learning and representation complexities of L-PCFGs. Experimental results on the English WSJ dataset confirm the effectiveness of our approach in improving both running speed and unsupervised parsing performance.
PCFGs Can Do Better: Inducing Probabilistic Context-Free Grammars with Many Symbols
Apr 28, 2021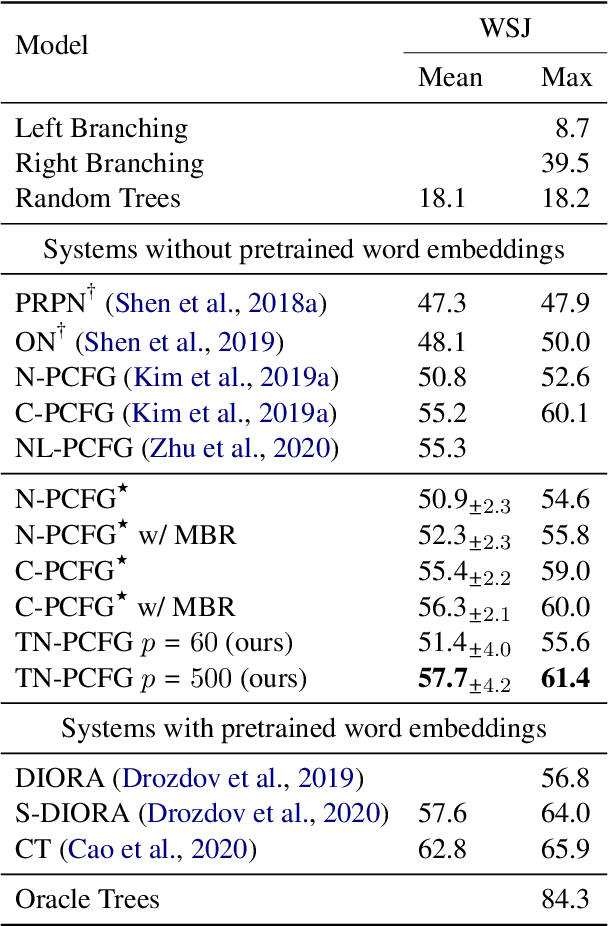
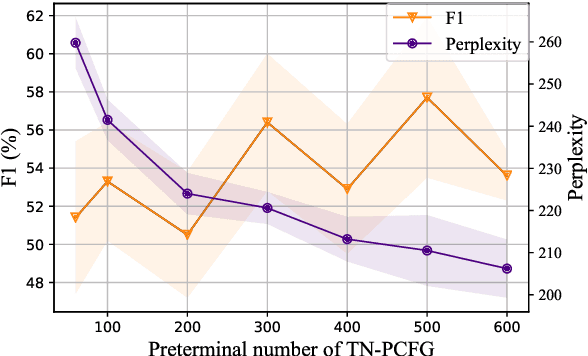

Probabilistic context-free grammars (PCFGs) with neural parameterization have been shown to be effective in unsupervised phrase-structure grammar induction. However, due to the cubic computational complexity of PCFG representation and parsing, previous approaches cannot scale up to a relatively large number of (nonterminal and preterminal) symbols. In this work, we present a new parameterization form of PCFGs based on tensor decomposition, which has at most quadratic computational complexity in the symbol number and therefore allows us to use a much larger number of symbols. We further use neural parameterization for the new form to improve unsupervised parsing performance. We evaluate our model across ten languages and empirically demonstrate the effectiveness of using more symbols. Our code: https://github.com/sustcsonglin/TN-PCFG
Constrained Text Generation with Global Guidance -- Case Study on CommonGen
Mar 12, 2021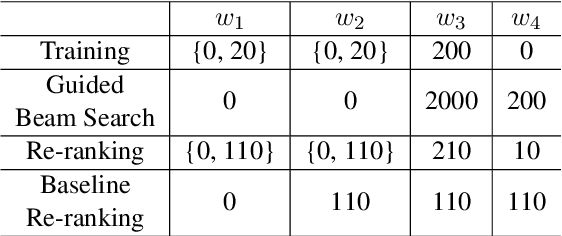
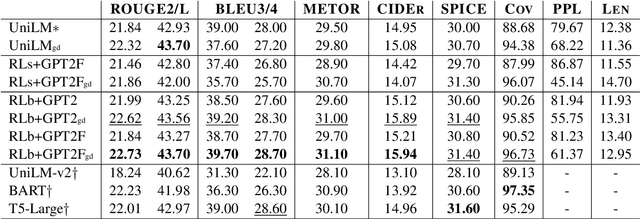

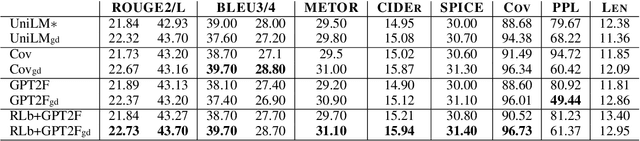
This paper studies constrained text generation, which is to generate sentences under certain pre-conditions. We focus on CommonGen, the task of generating text based on a set of concepts, as a representative task of constrained text generation. Traditional methods mainly rely on supervised training to maximize the likelihood of target sentences.However, global constraints such as common sense and coverage cannot be incorporated into the likelihood objective of the autoregressive decoding process. In this paper, we consider using reinforcement learning to address the limitation, measuring global constraints including fluency, common sense and concept coverage with a comprehensive score, which serves as the reward for reinforcement learning. Besides, we design a guided decoding method at the word, fragment and sentence levels. Experiments demonstrate that our method significantly increases the concept coverage and outperforms existing models in various automatic evaluations.
An Investigation of Potential Function Designs for Neural CRF
Nov 11, 2020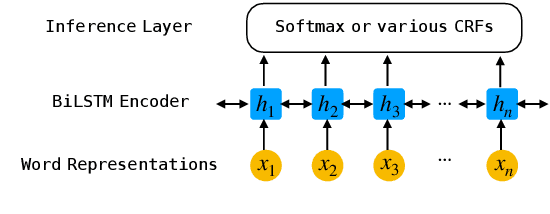
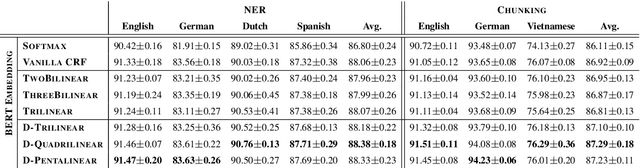
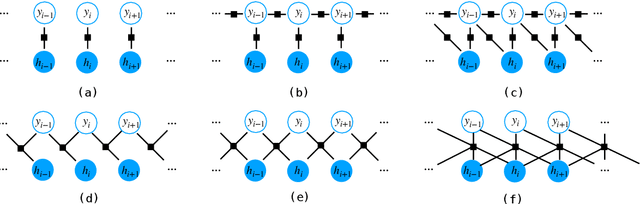
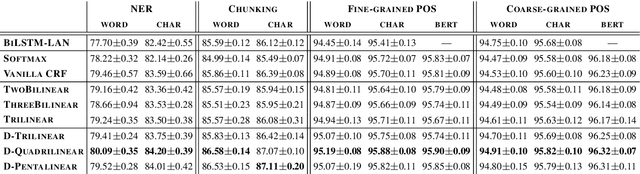
The neural linear-chain CRF model is one of the most widely-used approach to sequence labeling. In this paper, we investigate a series of increasingly expressive potential functions for neural CRF models, which not only integrate the emission and transition functions, but also explicitly take the representations of the contextual words as input. Our extensive experiments show that the decomposed quadrilinear potential function based on the vector representations of two neighboring labels and two neighboring words consistently achieves the best performance.
Neural Latent Dependency Model for Sequence Labeling
Nov 10, 2020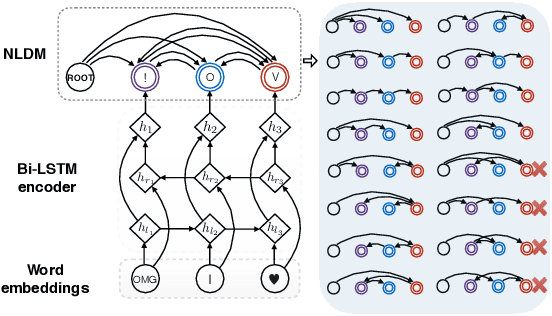

Sequence labeling is a fundamental problem in machine learning, natural language processing and many other fields. A classic approach to sequence labeling is linear chain conditional random fields (CRFs). When combined with neural network encoders, they achieve very good performance in many sequence labeling tasks. One limitation of linear chain CRFs is their inability to model long-range dependencies between labels. High order CRFs extend linear chain CRFs by modeling dependencies no longer than their order, but the computational complexity grows exponentially in the order. In this paper, we propose the Neural Latent Dependency Model (NLDM) that models dependencies of arbitrary length between labels with a latent tree structure. We develop an end-to-end training algorithm and a polynomial-time inference algorithm of our model. We evaluate our model on both synthetic and real datasets and show that our model outperforms strong baselines.
Second-Order Unsupervised Neural Dependency Parsing
Oct 28, 2020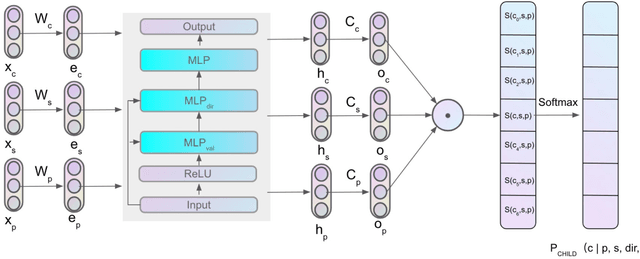
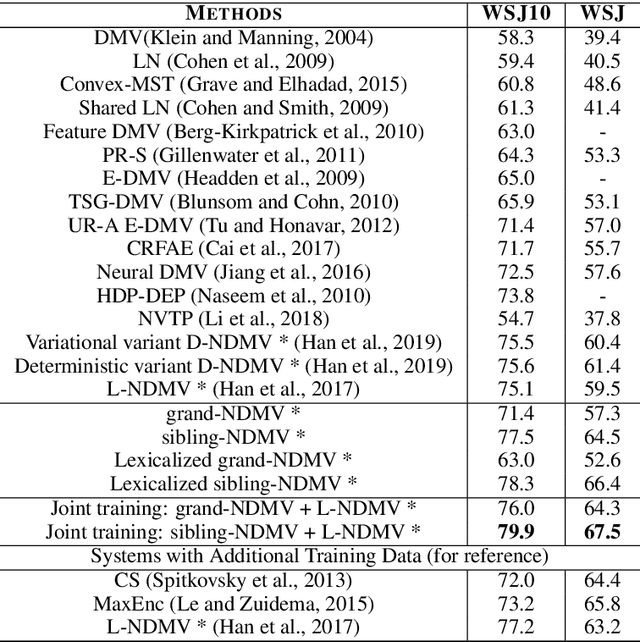
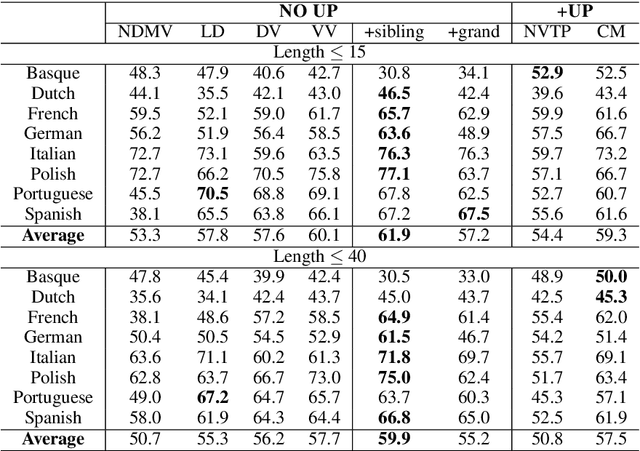
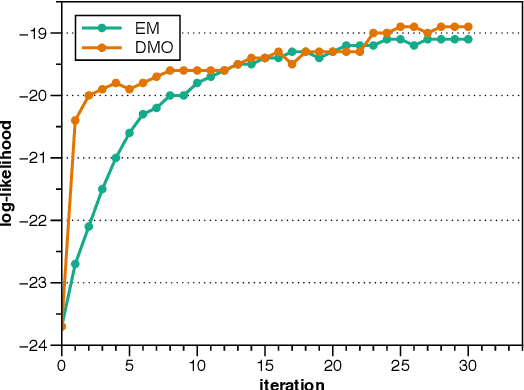
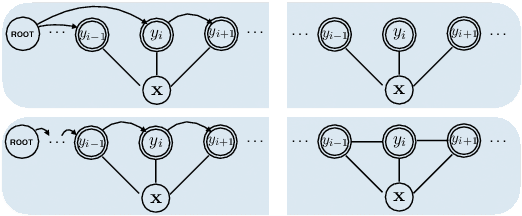
Most of the unsupervised dependency parsers are based on first-order probabilistic generative models that only consider local parent-child information. Inspired by second-order supervised dependency parsing, we proposed a second-order extension of unsupervised neural dependency models that incorporate grandparent-child or sibling information. We also propose a novel design of the neural parameterization and optimization methods of the dependency models. In second-order models, the number of grammar rules grows cubically with the increase of vocabulary size, making it difficult to train lexicalized models that may contain thousands of words. To circumvent this problem while still benefiting from both second-order parsing and lexicalization, we use the agreement-based learning framework to jointly train a second-order unlexicalized model and a first-order lexicalized model. Experiments on multiple datasets show the effectiveness of our second-order models compared with recent state-of-the-art methods. Our joint model achieves a 10% improvement over the previous state-of-the-art parser on the full WSJ test set
Adversarial Attack and Defense of Structured Prediction Models
Oct 18, 2020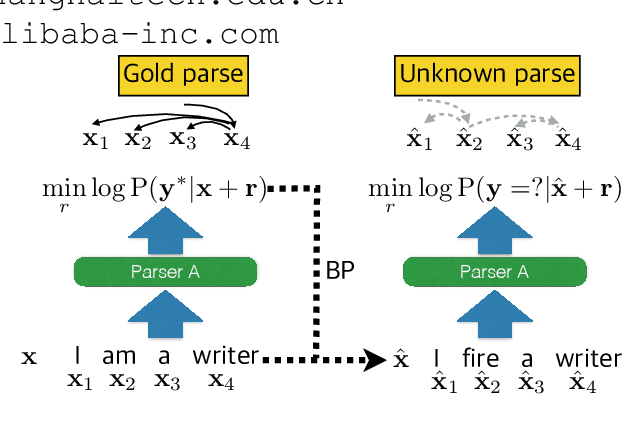

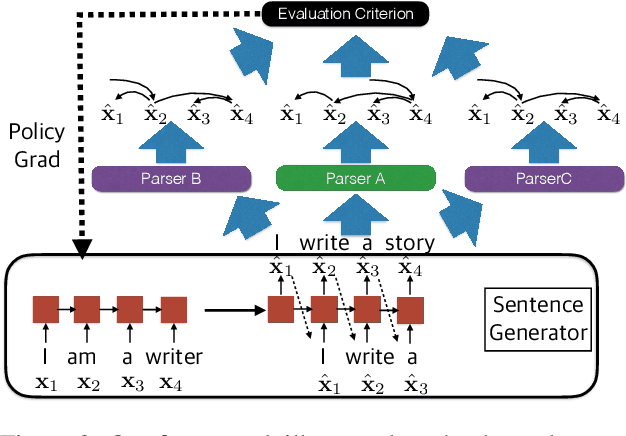
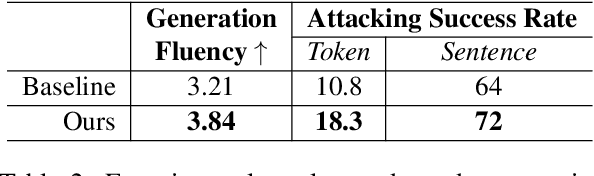
Building an effective adversarial attacker and elaborating on countermeasures for adversarial attacks for natural language processing (NLP) have attracted a lot of research in recent years. However, most of the existing approaches focus on classification problems. In this paper, we investigate attacks and defenses for structured prediction tasks in NLP. Besides the difficulty of perturbing discrete words and the sentence fluency problem faced by attackers in any NLP tasks, there is a specific challenge to attackers of structured prediction models: the structured output of structured prediction models is sensitive to small perturbations in the input. To address these problems, we propose a novel and unified framework that learns to attack a structured prediction model using a sequence-to-sequence model with feedbacks from multiple reference models of the same structured prediction task. Based on the proposed attack, we further reinforce the victim model with adversarial training, making its prediction more robust and accurate. We evaluate the proposed framework in dependency parsing and part-of-speech tagging. Automatic and human evaluations show that our proposed framework succeeds in both attacking state-of-the-art structured prediction models and boosting them with adversarial training.