 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Cultural Simulation of Citizen Emotional Responses to Bureaucratic Red Tape Using LLM Agents
Apr 14, 2026Improving policymaking is a central concern in public administration. Prior human subject studies reveal substantial cross-cultural differences in citizens' emotional responses to red tape during policy implementation. While LLM agents offer opportunities to simulate human-like responses and reduce experimental costs, their ability to generate culturally appropriate emotional responses to red tape remains unverified. To address this gap, we propose an evaluation framework for assessing LLMs' emotional responses to red tape across diverse cultural contexts. As a pilot study, we apply this framework to a single red-tape scenario. Our results show that all models exhibit limited alignment with human emotional responses, with notably weaker performance in Eastern cultures. Cultural prompting strategies prove largely ineffective in improving alignment. We further introduce \textbf{RAMO}, an interactive interface for simulating citizens' emotional responses to red tape and for collecting human data to improve models. The interface is publicly available at https://ramo-chi.ivia.ch.
CAGMamba: Context-Aware Gated Cross-Modal Mamba Network for Multimodal Sentiment Analysis
Apr 04, 2026Multimodal Sentiment Analysis (MSA) requires effective modeling of cross-modal interactions and contextual dependencies while remaining computationally efficient. Existing fusion approaches predominantly rely on Transformer-based cross-modal attention, which incurs quadratic complexity with respect to sequence length and limits scalability. Moreover, contextual information from preceding utterances is often incorporated through concatenation or independent fusion, without explicit temporal modeling that captures sentiment evolution across dialogue turns. To address these limitations, we propose CAGMamba, a context-aware gated cross-modal Mamba framework for dialogue-based sentiment analysis. Specifically, we organize the contextual and the current-utterance features into a temporally ordered binary sequence, which provides Mamba with explicit temporal structure for modeling sentiment evolution. To further enable controllable cross-modal integration, we propose a Gated Cross-Modal Mamba Network (GCMN) that integrates cross-modal and unimodal paths via learnable gating to balance information fusion and modality preservation, and is trained with a three-branch multi-task objective over text, audio, and fused predictions. Experiments on three benchmark datasets demonstrate that CAGMamba achieves state-of-the-art or competitive results across multiple evaluation metrics. All codes are available at https://github.com/User2024-xj/CAGMamba.
UltraLogic: Enhancing LLM Reasoning through Large-Scale Data Synthesis and Bipolar Float Reward
Jan 06, 2026While Large Language Models (LLMs) have demonstrated significant potential in natural language processing , complex general-purpose reasoning requiring multi-step logic, planning, and verification remains a critical bottleneck. Although Reinforcement Learning with Verifiable Rewards (RLVR) has succeeded in specific domains , the field lacks large-scale, high-quality, and difficulty-calibrated data for general reasoning. To address this, we propose UltraLogic, a framework that decouples the logical core of a problem from its natural language expression through a Code-based Solving methodology to automate high-quality data production. The framework comprises hundreds of unique task types and an automated calibration pipeline across ten difficulty levels. Furthermore, to mitigate binary reward sparsity and the Non-negative Reward Trap, we introduce the Bipolar Float Reward (BFR) mechanism, utilizing graded penalties to effectively distinguish perfect responses from those with logical flaws. Our experiments demonstrate that task diversity is the primary driver for reasoning enhancement , and that BFR, combined with a difficulty matching strategy, significantly improves training efficiency, guiding models toward global logical optima.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Constrained Text Generation with Global Guidance -- Case Study on CommonGen
Mar 12, 2021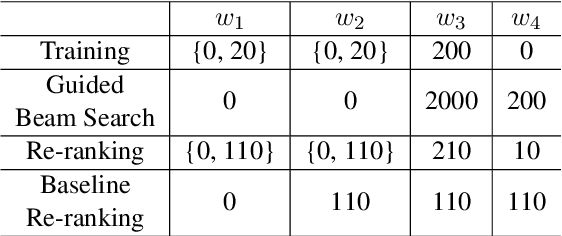
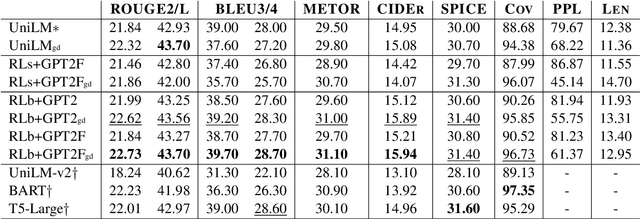

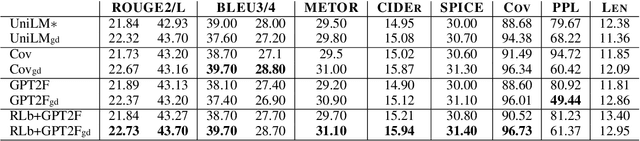
This paper studies constrained text generation, which is to generate sentences under certain pre-conditions. We focus on CommonGen, the task of generating text based on a set of concepts, as a representative task of constrained text generation. Traditional methods mainly rely on supervised training to maximize the likelihood of target sentences.However, global constraints such as common sense and coverage cannot be incorporated into the likelihood objective of the autoregressive decoding process. In this paper, we consider using reinforcement learning to address the limitation, measuring global constraints including fluency, common sense and concept coverage with a comprehensive score, which serves as the reward for reinforcement learning. Besides, we design a guided decoding method at the word, fragment and sentence levels. Experiments demonstrate that our method significantly increases the concept coverage and outperforms existing models in various automatic evaluations.
ShanghaiTech at MRP 2019: Sequence-to-Graph Transduction with Second-Order Edge Inference for Cross-Framework Meaning Representation Parsing
Apr 08, 2020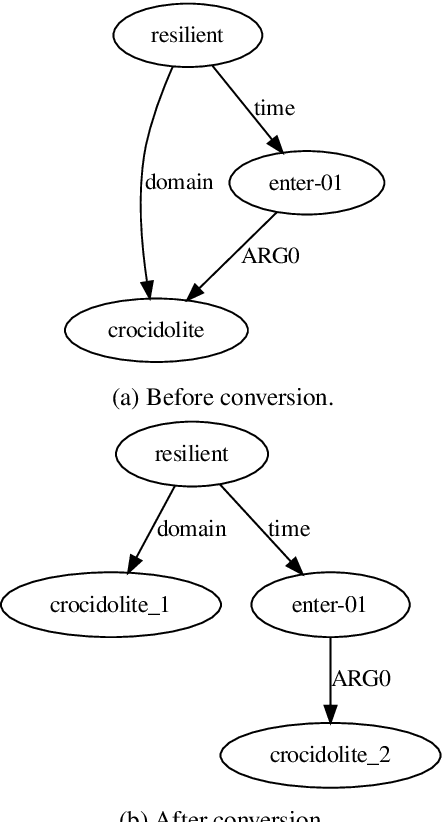
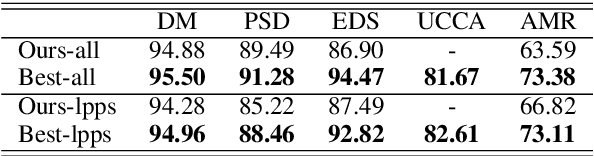
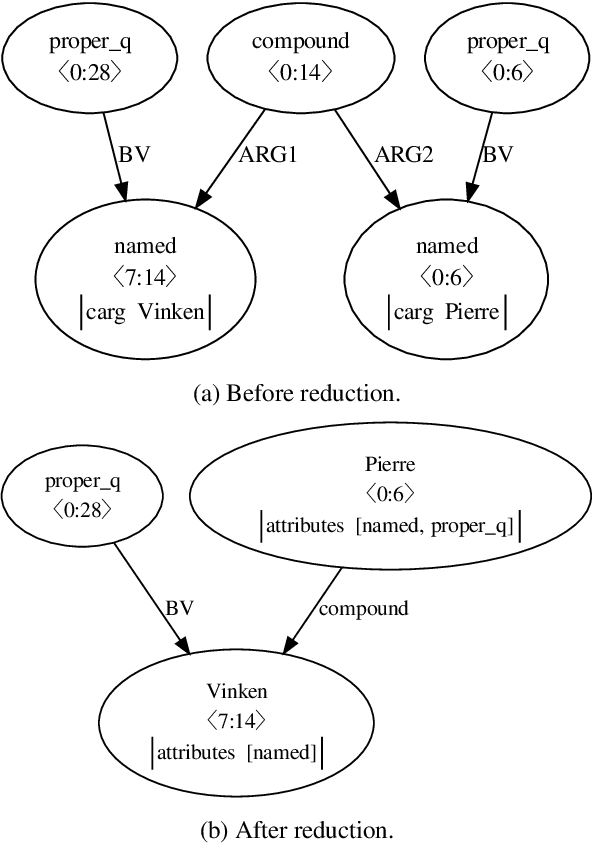
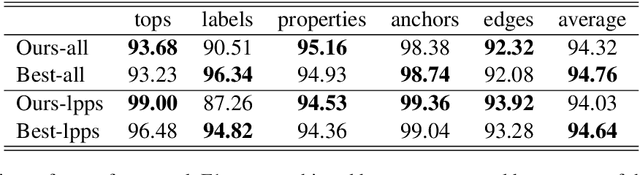
This paper presents the system used in our submission to the \textit{CoNLL 2019 shared task: Cross-Framework Meaning Representation Parsing}. Our system is a graph-based parser which combines an extended pointer-generator network that generates nodes and a second-order mean field variational inference module that predicts edges. Our system achieved \nth{1} and \nth{2} place for the DM and PSD frameworks respectively on the in-framework ranks and achieved \nth{3} place for the DM framework on the cross-framework ranks.