 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-dependent Sample Complexity Bounds for Zero-sum Matrix Games
Mar 19, 2023We study the sample complexity of identifying an approximate equilibrium for two-player zero-sum $n\times 2$ matrix games. That is, in a sequence of repeated game plays, how many rounds must the two players play before reaching an approximate equilibrium (e.g., Nash)? We derive instance-dependent bounds that define an ordering over game matrices that captures the intuition that the dynamics of some games converge faster than others. Specifically, we consider a stochastic observation model such that when the two players choose actions $i$ and $j$, respectively, they both observe each other's played actions and a stochastic observation $X_{ij}$ such that $\mathbb E[ X_{ij}] = A_{ij}$. To our knowledge, our work is the first case of instance-dependent lower bounds on the number of rounds the players must play before reaching an approximate equilibrium in the sense that the number of rounds depends on the specific properties of the game matrix $A$ as well as the desired accuracy. We also prove a converse statement: there exist player strategies that achieve this lower bound.
Instance-Dependent Near-Optimal Policy Identification in Linear MDPs via Online Experiment Design
Jul 06, 2022While much progress has been made in understanding the minimax sample complexity of reinforcement learning (RL) -- the complexity of learning on the "worst-case" instance -- such measures of complexity often do not capture the true difficulty of learning. In practice, on an "easy" instance, we might hope to achieve a complexity far better than that achievable on the worst-case instance. In this work we seek to understand the "instance-dependent" complexity of learning near-optimal policies (PAC RL) in the setting of RL with linear function approximation. We propose an algorithm, \textsc{Pedel}, which achieves a fine-grained instance-dependent measure of complexity, the first of its kind in the RL with function approximation setting, thereby capturing the difficulty of learning on each particular problem instance. Through an explicit example, we show that \textsc{Pedel} yields provable gains over low-regret, minimax-optimal algorithms and that such algorithms are unable to hit the instance-optimal rate. Our approach relies on a novel online experiment design-based procedure which focuses the exploration budget on the "directions" most relevant to learning a near-optimal policy, and may be of independent interest.
Instance-optimal PAC Algorithms for Contextual Bandits
Jul 05, 2022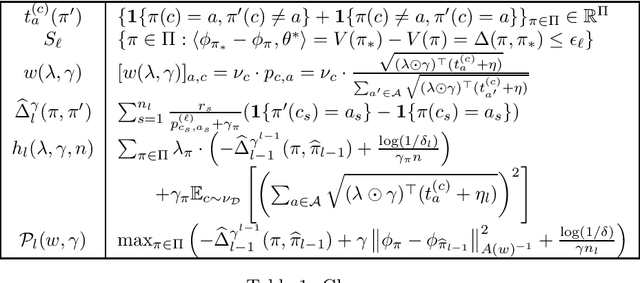
In the stochastic contextual bandit setting, regret-minimizing algorithms have been extensively researched, but their instance-minimizing best-arm identification counterparts remain seldom studied. In this work, we focus on the stochastic bandit problem in the $(\epsilon,\delta)$-$\textit{PAC}$ setting: given a policy class $\Pi$ the goal of the learner is to return a policy $\pi\in \Pi$ whose expected reward is within $\epsilon$ of the optimal policy with probability greater than $1-\delta$. We characterize the first $\textit{instance-dependent}$ PAC sample complexity of contextual bandits through a quantity $\rho_{\Pi}$, and provide matching upper and lower bounds in terms of $\rho_{\Pi}$ for the agnostic and linear contextual best-arm identification settings. We show that no algorithm can be simultaneously minimax-optimal for regret minimization and instance-dependent PAC for best-arm identification. Our main result is a new instance-optimal and computationally efficient algorithm that relies on a polynomial number of calls to an argmax oracle.
Active Learning with Safety Constraints
Jun 22, 2022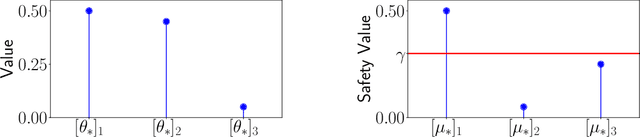
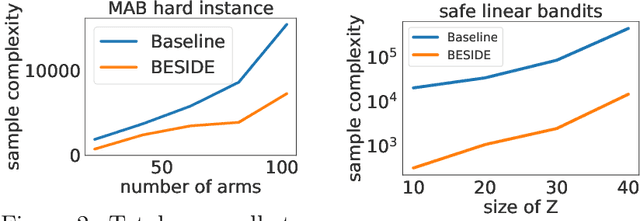
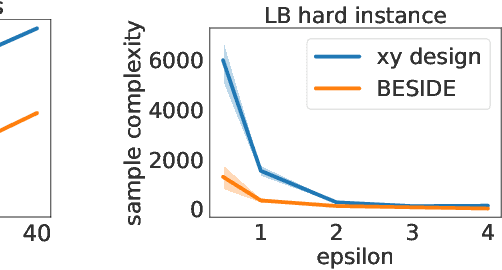
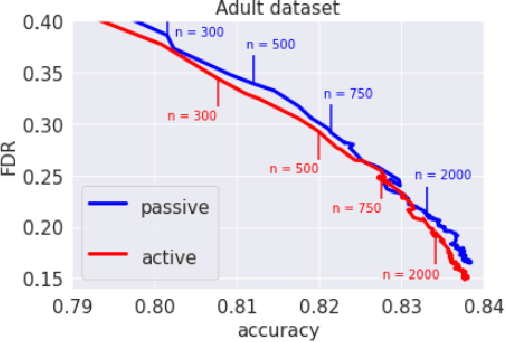
Active learning methods have shown great promise in reducing the number of samples necessary for learning. As automated learning systems are adopted into real-time, real-world decision-making pipelines, it is increasingly important that such algorithms are designed with safety in mind. In this work we investigate the complexity of learning the best safe decision in interactive environments. We reduce this problem to a constrained linear bandits problem, where our goal is to find the best arm satisfying certain (unknown) safety constraints. We propose an adaptive experimental design-based algorithm, which we show efficiently trades off between the difficulty of showing an arm is unsafe vs suboptimal. To our knowledge, our results are the first on best-arm identification in linear bandits with safety constraints. In practice, we demonstrate that this approach performs well on synthetic and real world datasets.
Active Multi-Task Representation Learning
Feb 02, 2022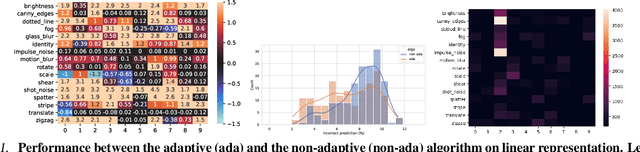
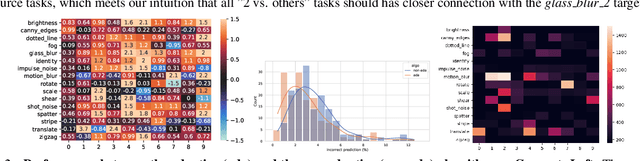
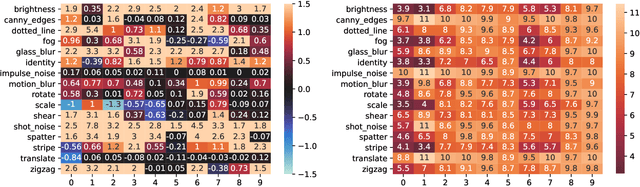
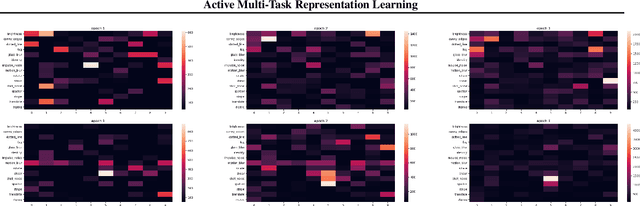
To leverage the power of big data from source tasks and overcome the scarcity of the target task samples, representation learning based on multi-task pretraining has become a standard approach in many applications. However, up until now, choosing which source tasks to include in the multi-task learning has been more art than science. In this paper, we give the first formal study on resource task sampling by leveraging the techniques from active learning. We propose an algorithm that iteratively estimates the relevance of each source task to the target task and samples from each source task based on the estimated relevance. Theoretically, we show that for the linear representation class, to achieve the same error rate, our algorithm can save up to a \textit{number of source tasks} factor in the source task sample complexity, compared with the naive uniform sampling from all source tasks. We also provide experiments on real-world computer vision datasets to illustrate the effectiveness of our proposed method on both linear and convolutional neural network representation classes. We believe our paper serves as an important initial step to bring techniques from active learning to representation learning.
Reward-Free RL is No Harder Than Reward-Aware RL in Linear Markov Decision Processes
Jan 26, 2022Reward-free reinforcement learning (RL) considers the setting where the agent does not have access to a reward function during exploration, but must propose a near-optimal policy for an arbitrary reward function revealed only after exploring. In the the tabular setting, it is well known that this is a more difficult problem than PAC RL -- where the agent has access to the reward function during exploration -- with optimal sample complexities in the two settings differing by a factor of $|\mathcal{S}|$, the size of the state space. We show that this separation does not exist in the setting of linear MDPs. We first develop a computationally efficient algorithm for reward-free RL in a $d$-dimensional linear MDP with sample complexity scaling as $\mathcal{O}(d^2/\epsilon^2)$. We then show a matching lower bound of $\Omega(d^2/\epsilon^2)$ on PAC RL. To our knowledge, our approach is the first computationally efficient algorithm to achieve optimal $d$ dependence in linear MDPs, even in the single-reward PAC setting. Our algorithm relies on a novel procedure which efficiently traverses a linear MDP, collecting samples in any given "feature direction", and enjoys a sample complexity scaling optimally in the (linear MDP equivalent of the) maximal state visitation probability. We show that this exploration procedure can also be applied to solve the problem of obtaining "well-conditioned" covariates in linear MDPs.
First-Order Regret in Reinforcement Learning with Linear Function Approximation: A Robust Estimation Approach
Dec 07, 2021Obtaining first-order regret bounds -- regret bounds scaling not as the worst-case but with some measure of the performance of the optimal policy on a given instance -- is a core question in sequential decision-making. While such bounds exist in many settings, they have proven elusive in reinforcement learning with large state spaces. In this work we address this gap, and show that it is possible to obtain regret scaling as $\mathcal{O}(\sqrt{V_1^\star K})$ in reinforcement learning with large state spaces, namely the linear MDP setting. Here $V_1^\star$ is the value of the optimal policy and $K$ is the number of episodes. We demonstrate that existing techniques based on least squares estimation are insufficient to obtain this result, and instead develop a novel robust self-normalized concentration bound based on the robust Catoni mean estimator, which may be of independent interest.
Best Arm Identification with Safety Constraints
Nov 23, 2021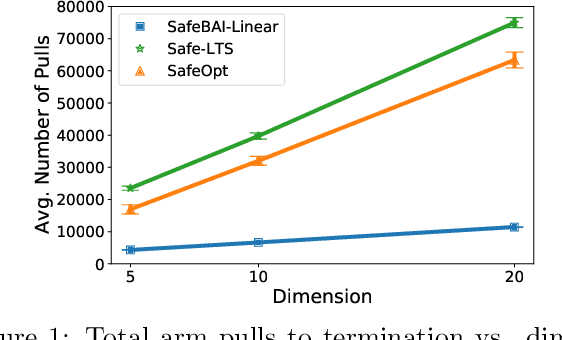
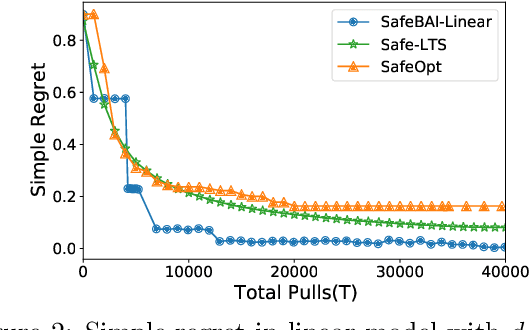
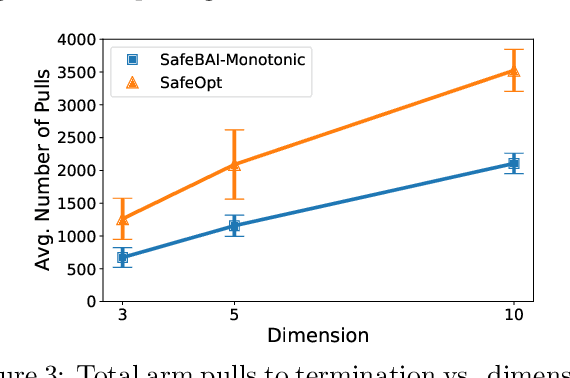
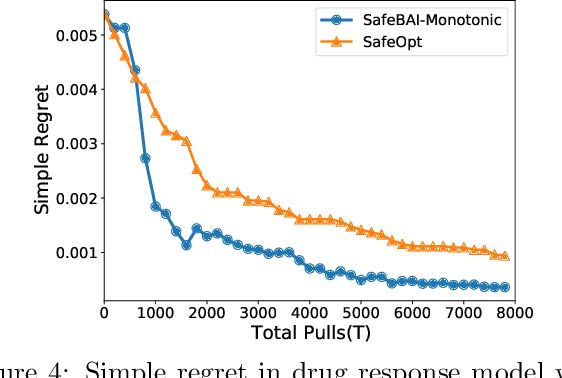
The best arm identification problem in the multi-armed bandit setting is an excellent model of many real-world decision-making problems, yet it fails to capture the fact that in the real-world, safety constraints often must be met while learning. In this work we study the question of best-arm identification in safety-critical settings, where the goal of the agent is to find the best safe option out of many, while exploring in a way that guarantees certain, initially unknown safety constraints are met. We first analyze this problem in the setting where the reward and safety constraint takes a linear structure, and show nearly matching upper and lower bounds. We then analyze a much more general version of the problem where we only assume the reward and safety constraint can be modeled by monotonic functions, and propose an algorithm in this setting which is guaranteed to learn safely. We conclude with experimental results demonstrating the effectiveness of our approaches in scenarios such as safely identifying the best drug out of many in order to treat an illness.
Practical, Provably-Correct Interactive Learning in the Realizable Setting: The Power of True Believers
Nov 09, 2021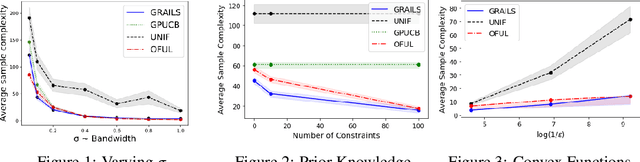
We consider interactive learning in the realizable setting and develop a general framework to handle problems ranging from best arm identification to active classification. We begin our investigation with the observation that agnostic algorithms \emph{cannot} be minimax-optimal in the realizable setting. Hence, we design novel computationally efficient algorithms for the realizable setting that match the minimax lower bound up to logarithmic factors and are general-purpose, accommodating a wide variety of function classes including kernel methods, H{\"o}lder smooth functions, and convex functions. The sample complexities of our algorithms can be quantified in terms of well-known quantities like the extended teaching dimension and haystack dimension. However, unlike algorithms based directly on those combinatorial quantities, our algorithms are computationally efficient. To achieve computational efficiency, our algorithms sample from the version space using Monte Carlo "hit-and-run" algorithms instead of maintaining the version space explicitly. Our approach has two key strengths. First, it is simple, consisting of two unifying, greedy algorithms. Second, our algorithms have the capability to seamlessly leverage prior knowledge that is often available and useful in practice. In addition to our new theoretical results, we demonstrate empirically that our algorithms are competitive with Gaussian process UCB methods.
Nearly Optimal Algorithms for Level Set Estimation
Nov 02, 2021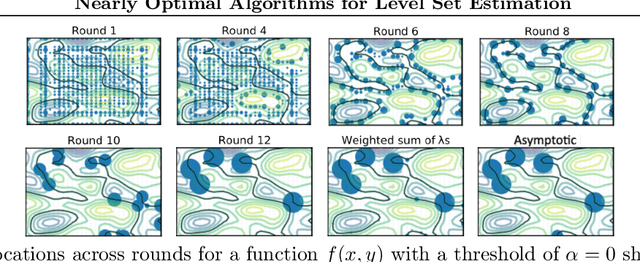

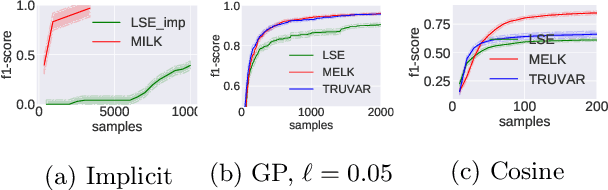
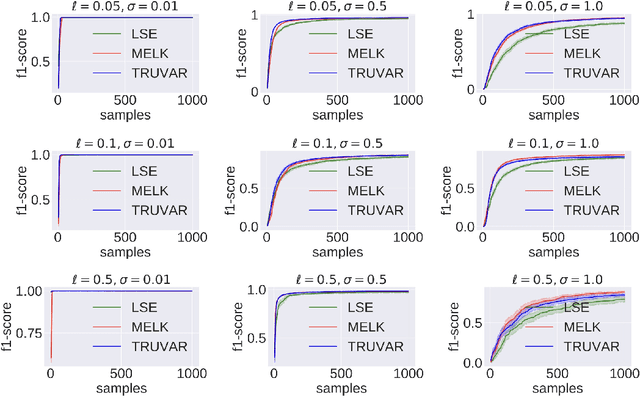
The level set estimation problem seeks to find all points in a domain ${\cal X}$ where the value of an unknown function $f:{\cal X}\rightarrow \mathbb{R}$ exceeds a threshold $\alpha$. The estimation is based on noisy function evaluations that may be acquired at sequentially and adaptively chosen locations in ${\cal X}$. The threshold value $\alpha$ can either be \emph{explicit} and provided a priori, or \emph{implicit} and defined relative to the optimal function value, i.e. $\alpha = (1-\epsilon)f(x_\ast)$ for a given $\epsilon > 0$ where $f(x_\ast)$ is the maximal function value and is unknown. In this work we provide a new approach to the level set estimation problem by relating it to recent adaptive experimental design methods for linear bandits in the Reproducing Kernel Hilbert Space (RKHS) setting. We assume that $f$ can be approximated by a function in the RKHS up to an unknown misspecification and provide novel algorithms for both the implicit and explicit cases in this setting with strong theoretical guarantees. Moreover, in the linear (kernel) setting, we show that our bounds are nearly optimal, namely, our upper bounds match existing lower bounds for threshold linear bandits. To our knowledge this work provides the first instance-dependent, non-asymptotic upper bounds on sample complexity of level-set estimation that match information theoretic lower bounds.