 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixBCT: Towards Self-Adapting Backward-Compatible Training
Aug 14, 2023The exponential growth of data, alongside advancements in model structures and loss functions, has necessitated the enhancement of image retrieval systems through the utilization of new models with superior feature embeddings. However, the expensive process of updating the old retrieval database by replacing embeddings poses a challenge. As a solution, backward-compatible training can be employed to avoid the necessity of updating old retrieval datasets. While previous methods achieved backward compatibility by aligning prototypes of the old model, they often overlooked the distribution of the old features, thus limiting their effectiveness when the old model's low quality leads to a weakly discriminative feature distribution. On the other hand, instance-based methods like L2 regression take into account the distribution of old features but impose strong constraints on the performance of the new model itself. In this paper, we propose MixBCT, a simple yet highly effective backward-compatible training method that serves as a unified framework for old models of varying qualities. Specifically, we summarize four constraints that are essential for ensuring backward compatibility in an ideal scenario, and we construct a single loss function to facilitate backward-compatible training. Our approach adaptively adjusts the constraint domain for new features based on the distribution of the old embeddings. We conducted extensive experiments on the large-scale face recognition datasets MS1Mv3 and IJB-C to verify the effectiveness of our method. The experimental results clearly demonstrate its superiority over previous methods. Code is available at https://github.com/yuleung/MixBCT
Local Sample-weighted Multiple Kernel Clustering with Consensus Discriminative Graph
Jul 05, 2022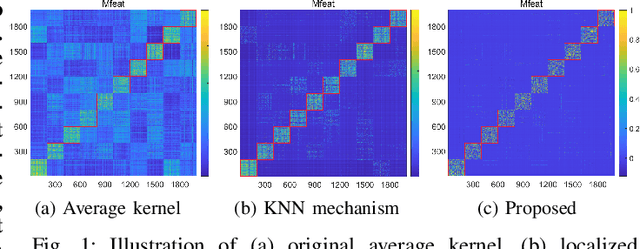
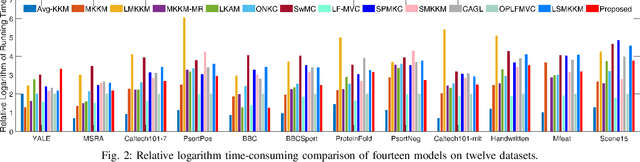
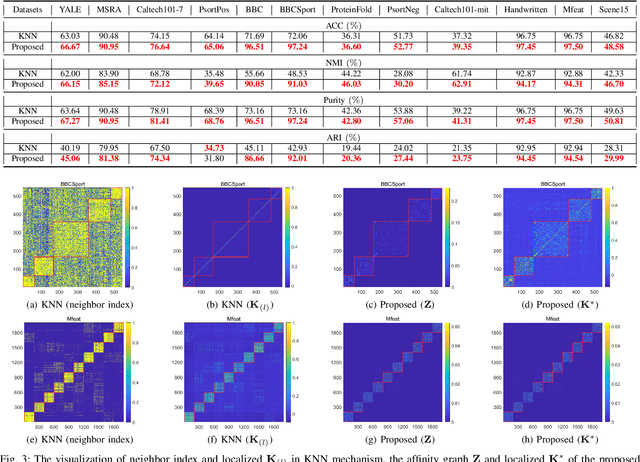
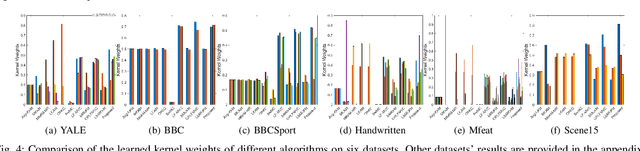
Multiple kernel clustering (MKC) is committed to achieving optimal information fusion from a set of base kernels. Constructing precise and local kernel matrices is proved to be of vital significance in applications since the unreliable distant-distance similarity estimation would degrade clustering per-formance. Although existing localized MKC algorithms exhibit improved performance compared to globally-designed competi-tors, most of them widely adopt KNN mechanism to localize kernel matrix by accounting for {\tau} -nearest neighbors. However, such a coarse manner follows an unreasonable strategy that the ranking importance of different neighbors is equal, which is impractical in applications. To alleviate such problems, this paper proposes a novel local sample-weighted multiple kernel clustering (LSWMKC) model. We first construct a consensus discriminative affinity graph in kernel space, revealing the latent local structures. Further, an optimal neighborhood kernel for the learned affinity graph is output with naturally sparse property and clear block diagonal structure. Moreover, LSWMKC im-plicitly optimizes adaptive weights on different neighbors with corresponding samples. Experimental results demonstrate that our LSWMKC possesses better local manifold representation and outperforms existing kernel or graph-based clustering algo-rithms. The source code of LSWMKC can be publicly accessed from https://github.com/liliangnudt/LSWMKC.
On the Properties of Kullback-Leibler Divergence Between Gaussians
Feb 24, 2021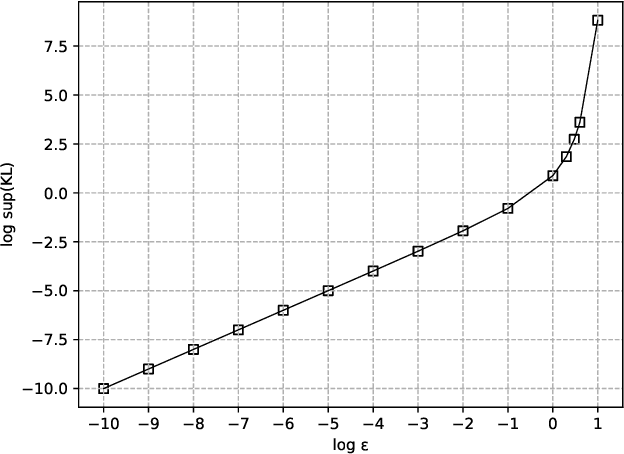
Kullback-Leibler (KL) divergence is one of the most important divergence measures between probability distributions. In this paper, we investigate the properties of KL divergence between Gaussians. Firstly, for any two $n$-dimensional Gaussians $\mathcal{N}_1$ and $\mathcal{N}_2$, we find the supremum of $KL(\mathcal{N}_1||\mathcal{N}_2)$ when $KL(\mathcal{N}_2||\mathcal{N}_1)\leq \epsilon$ for $\epsilon>0$. This reveals the approximate symmetry of small KL divergence between Gaussians. We also find the infimum of $KL(\mathcal{N}_1||\mathcal{N}_2)$ when $KL(\mathcal{N}_2||\mathcal{N}_1)\geq M$ for $M>0$. Secondly, for any three $n$-dimensional Gaussians $\mathcal{N}_1, \mathcal{N}_2$ and $\mathcal{N}_3$, we find a bound of $KL(\mathcal{N}_1||\mathcal{N}_3)$ if $KL(\mathcal{N}_1||\mathcal{N}_2)$ and $KL(\mathcal{N}_2||\mathcal{N}_3)$ are bounded. This reveals that the KL divergence between Gaussians follows a relaxed triangle inequality. Importantly, all the bounds in the theorems presented in this paper are independent of the dimension $n$.
Dynamic Bicycle Dispatching of Dockless Public Bicycle-sharing Systems using Multi-objective Reinforcement Learning
Jan 19, 2021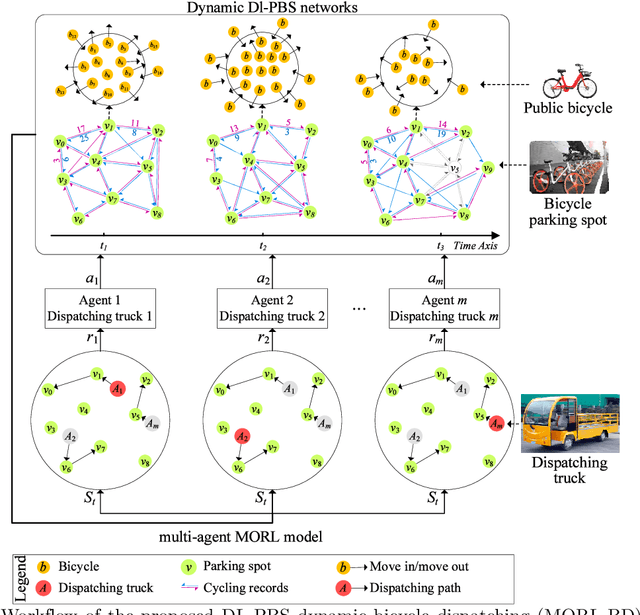
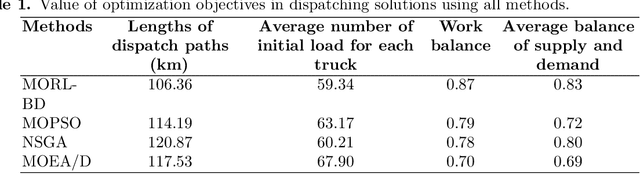

As a new generation of Public Bicycle-sharing Systems (PBS), the dockless PBS (DL-PBS) is an important application of cyber-physical systems and intelligent transportation. How to use AI to provide efficient bicycle dispatching solutions based on dynamic bicycle rental demand is an essential issue for DL-PBS. In this paper, we propose a dynamic bicycle dispatching algorithm based on multi-objective reinforcement learning (MORL-BD) to provide the optimal bicycle dispatching solution for DL-PBS. We model the DL-PBS system from the perspective of CPS and use deep learning to predict the layout of bicycle parking spots and the dynamic demand of bicycle dispatching. We define the multi-route bicycle dispatching problem as a multi-objective optimization problem by considering the optimization objectives of dispatching costs, dispatch truck's initial load, workload balance among the trucks, and the dynamic balance of bicycle supply and demand. On this basis, the collaborative multi-route bicycle dispatching problem among multiple dispatch trucks is modeled as a multi-agent MORL model. All dispatch paths between parking spots are defined as state spaces, and the reciprocal of dispatching costs is defined as a reward. Each dispatch truck is equipped with an agent to learn the optimal dispatch path in the dynamic DL-PBS network. We create an elite list to store the Pareto optimal solutions of bicycle dispatch paths found in each action, and finally, get the Pareto frontier. Experimental results on the actual DL-PBS systems show that compared with existing methods, MORL-BD can find a higher quality Pareto frontier with less execution time.
Dynamic Planning of Bicycle Stations in Dockless Public Bicycle-sharing System Using Gated Graph Neural Network
Jan 19, 2021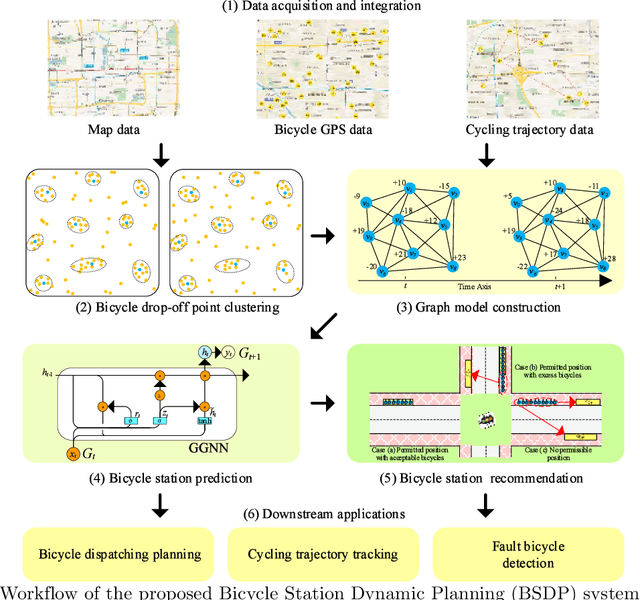

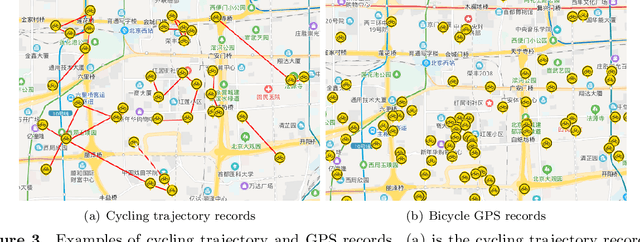
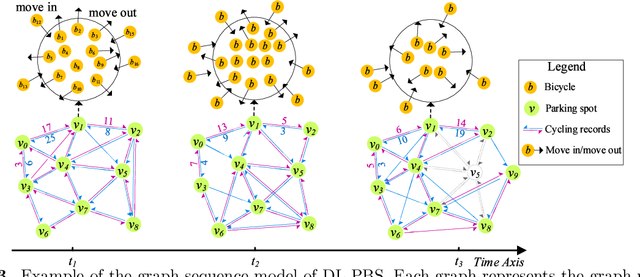
Benefiting from convenient cycling and flexible parking locations, the Dockless Public Bicycle-sharing (DL-PBS) network becomes increasingly popular in many countries. However, redundant and low-utility stations waste public urban space and maintenance costs of DL-PBS vendors. In this paper, we propose a Bicycle Station Dynamic Planning (BSDP) system to dynamically provide the optimal bicycle station layout for the DL-PBS network. The BSDP system contains four modules: bicycle drop-off location clustering, bicycle-station graph modeling, bicycle-station location prediction, and bicycle-station layout recommendation. In the bicycle drop-off location clustering module, candidate bicycle stations are clustered from each spatio-temporal subset of the large-scale cycling trajectory records. In the bicycle-station graph modeling module, a weighted digraph model is built based on the clustering results and inferior stations with low station revenue and utility are filtered. Then, graph models across time periods are combined to create a graph sequence model. In the bicycle-station location prediction module, the GGNN model is used to train the graph sequence data and dynamically predict bicycle stations in the next period. In the bicycle-station layout recommendation module, the predicted bicycle stations are fine-tuned according to the government urban management plan, which ensures that the recommended station layout is conducive to city management, vendor revenue, and user convenience. Experiments on actual DL-PBS networks verify the effectiveness, accuracy and feasibility of the proposed BSDP system.
A Survey on Applications of Artificial Intelligence in Fighting Against COVID-19
Jul 04, 2020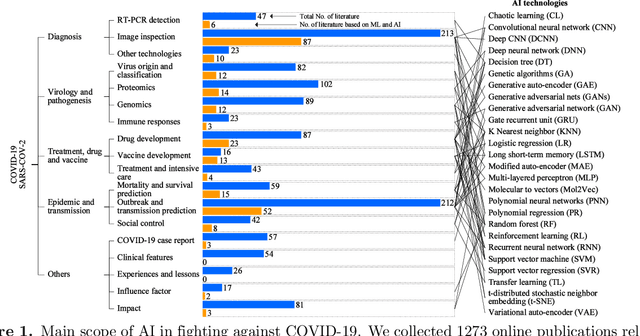
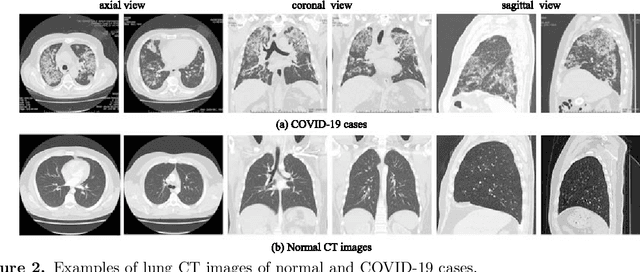
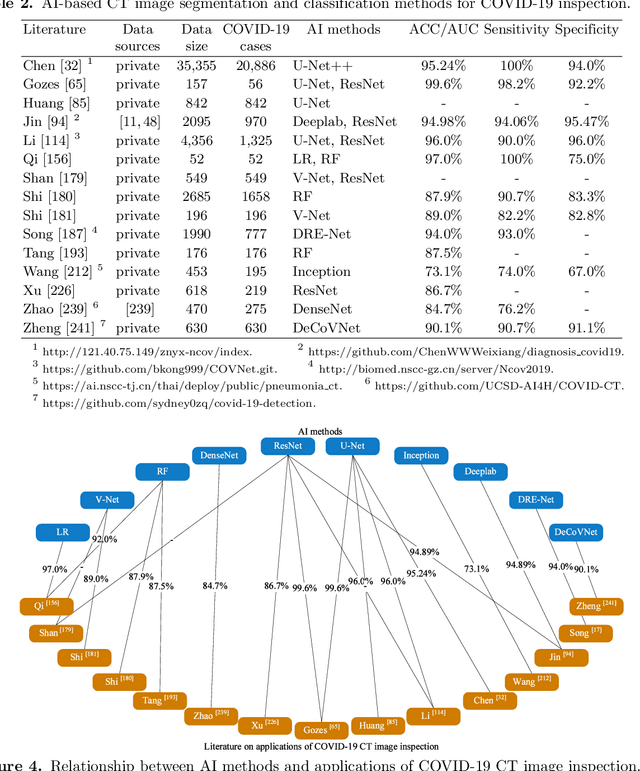
The COVID-19 pandemic caused by the SARS-CoV-2 virus has spread rapidly worldwide, leading to a global outbreak. Most governments, enterprises, and scientific research institutions are participating in the COVID-19 struggle to curb the spread of the pandemic. As a powerful tool against COVID-19, artificial intelligence (AI) technologies are widely used in combating this pandemic. In this survey, we investigate the main scope and contributions of AI in combating COVID-19 from the aspects of disease detection and diagnosis, virology and pathogenesis, drug and vaccine development, and epidemic and transmission prediction. In addition, we summarize the available data and resources that can be used for AI-based COVID-19 research. Finally, the main challenges and potential directions of AI in fighting against COVID-19 are discussed. Currently, AI mainly focuses on medical image inspection, genomics, drug development, and transmission prediction, and thus AI still has great potential in this field. This survey presents medical and AI researchers with a comprehensive view of the existing and potential applications of AI technology in combating COVID-19 with the goal of inspiring researches to continue to maximize the advantages of AI and big data to fight COVID-19.
Out-of-Distribution Detection with Distance Guarantee in Deep Generative Models
Feb 09, 2020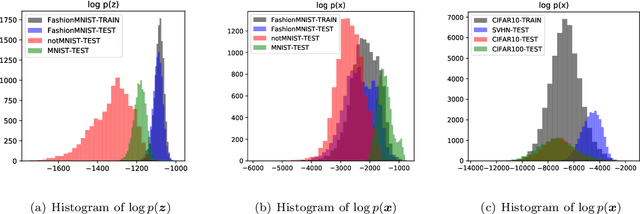
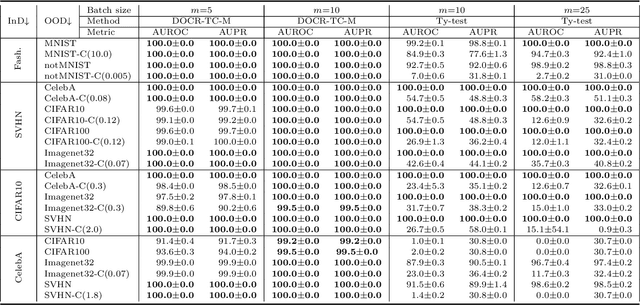
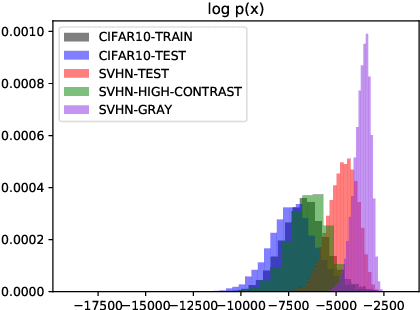
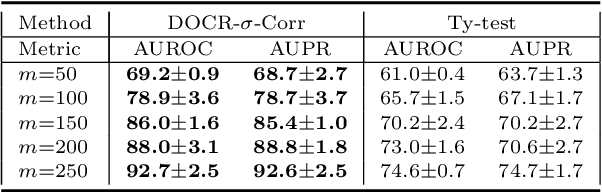
Recent research has shown that it is challenging to detect out-of-distribution (OOD) data in deep generative models including flow-based models and variational autoencoders (VAEs). In this paper, we prove a theorem that, for a well-trained flow-based model, the distance between the distribution of representations of an OOD dataset and prior can be large enough, as long as the distance between the distributions of the training dataset and the OOD dataset is large enough. Furthermore, our observation shows that, for flow-based model and VAE with factorized prior, the representations of OOD datasets are more correlated than that of the training dataset. Based on our theorem and observation, we propose detecting OOD data according to the total correlation of representations in flow-based model and VAE. Experimental results show that our method can achieve nearly 100\% AUROC for all the widely used benchmarks and has robustness against data manipulation. While the state-of-the-art method performs not better than random guessing for challenging problems and can be fooled by data manipulation in almost all cases.
HPC AI500: A Benchmark Suite for HPC AI Systems
Aug 13, 2019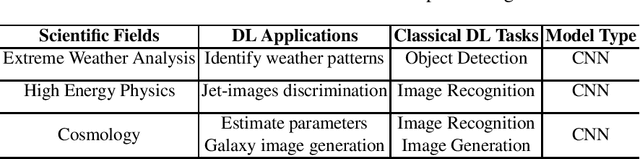
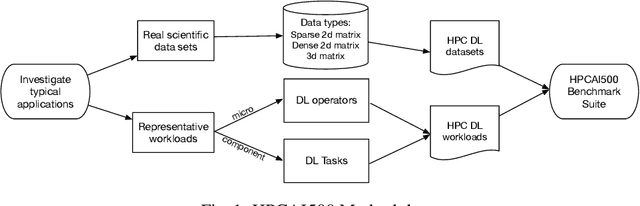

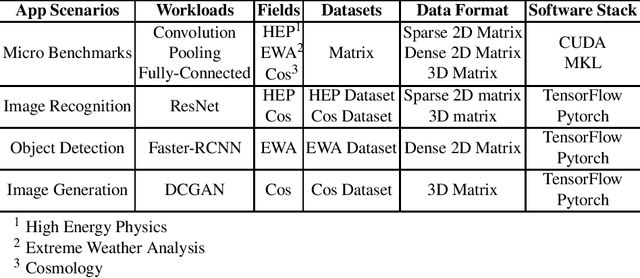
In recent years, with the trend of applying deep learning (DL) in high performance scientific computing, the unique characteristics of emerging DL workloads in HPC raise great challenges in designing, implementing HPC AI systems. The community needs a new yard stick for evaluating the future HPC systems. In this paper, we propose HPC AI500 --- a benchmark suite for evaluating HPC systems that running scientific DL workloads. Covering the most representative scientific fields, each workload from HPC AI500 is based on real-world scientific DL applications. Currently, we choose 14 scientific DL benchmarks from perspectives of application scenarios, data sets, and software stack. We propose a set of metrics for comprehensively evaluating the HPC AI systems, considering both accuracy, performance as well as power and cost. We provide a scalable reference implementation of HPC AI500. HPC AI500 is a part of the open-source AIBench project, the specification and source code are publicly available from \url{http://www.benchcouncil.org/AIBench/index.html}.
Distributed Deep Learning Model for Intelligent Video Surveillance Systems with Edge Computing
Apr 12, 2019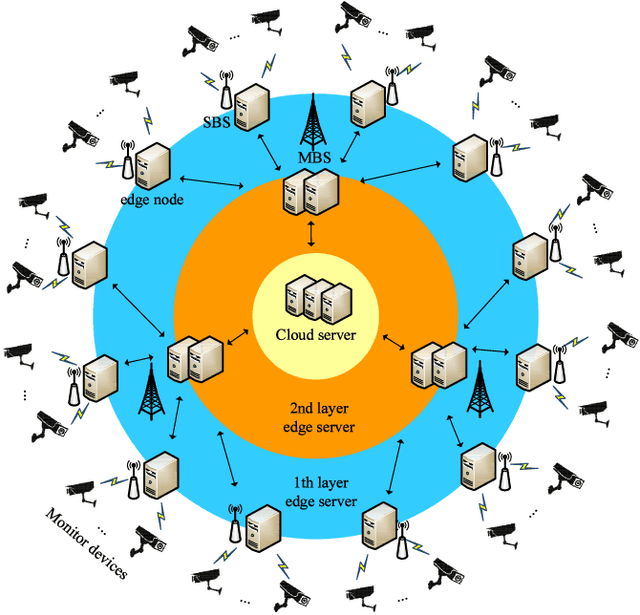
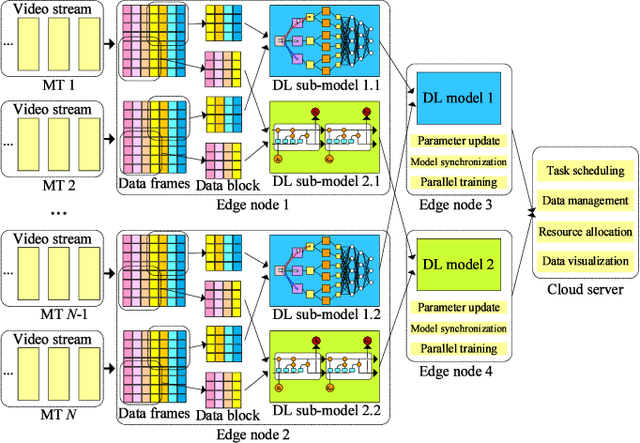
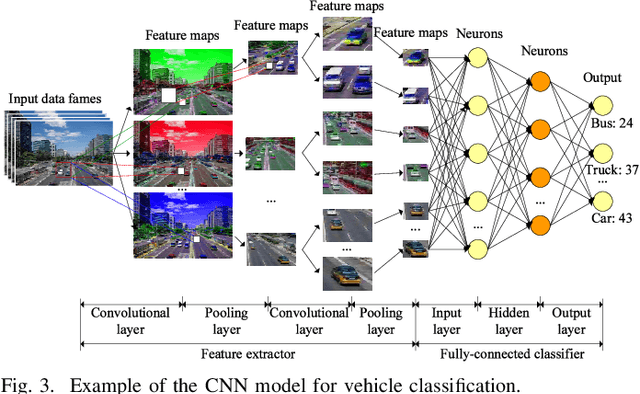
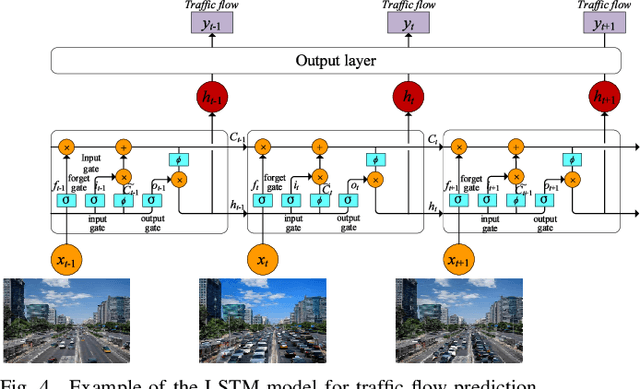
In this paper, we propose a Distributed Intelligent Video Surveillance (DIVS) system using Deep Learning (DL) algorithms and deploy it in an edge computing environment. We establish a multi-layer edge computing architecture and a distributed DL training model for the DIVS system. The DIVS system can migrate computing workloads from the network center to network edges to reduce huge network communication overhead and provide low-latency and accurate video analysis solutions. We implement the proposed DIVS system and address the problems of parallel training, model synchronization, and workload balancing. Task-level parallel and model-level parallel training methods are proposed to further accelerate the video analysis process. In addition, we propose a model parameter updating method to achieve model synchronization of the global DL model in a distributed EC environment. Moreover, a dynamic data migration approach is proposed to address the imbalance of workload and computational power of edge nodes. Experimental results showed that the EC architecture can provide elastic and scalable computing power, and the proposed DIVS system can efficiently handle video surveillance and analysis tasks.
A Periodicity-based Parallel Time Series Prediction Algorithm in Cloud Computing Environments
Oct 17, 2018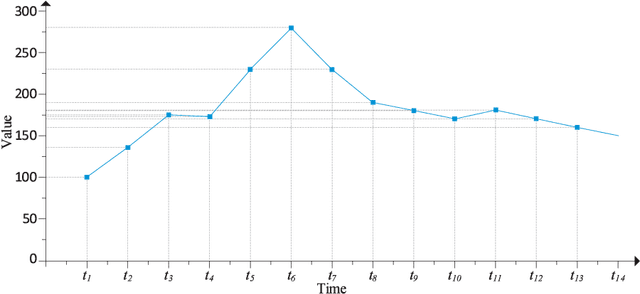

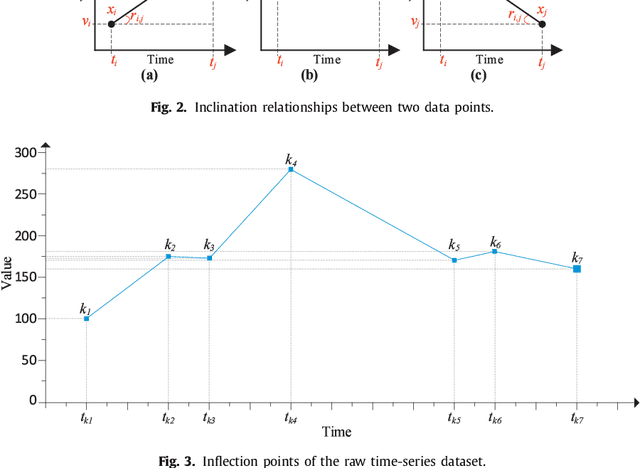
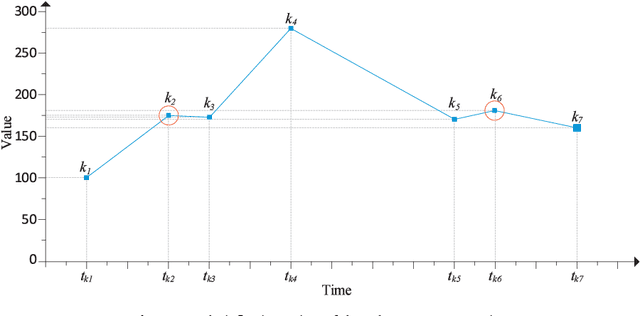
In the era of big data, practical applications in various domains continually generate large-scale time-series data. Among them, some data show significant or potential periodicity characteristics, such as meteorological and financial data. It is critical to efficiently identify the potential periodic patterns from massive time-series data and provide accurate predictions. In this paper, a Periodicity-based Parallel Time Series Prediction (PPTSP) algorithm for large-scale time-series data is proposed and implemented in the Apache Spark cloud computing environment. To effectively handle the massive historical datasets, a Time Series Data Compression and Abstraction (TSDCA) algorithm is presented, which can reduce the data scale as well as accurately extracting the characteristics. Based on this, we propose a Multi-layer Time Series Periodic Pattern Recognition (MTSPPR) algorithm using the Fourier Spectrum Analysis (FSA) method. In addition, a Periodicity-based Time Series Prediction (PTSP) algorithm is proposed. Data in the subsequent period are predicted based on all previous period models, in which a time attenuation factor is introduced to control the impact of different periods on the prediction results. Moreover, to improve the performance of the proposed algorithms, we propose a parallel solution on the Apache Spark platform, using the Streaming real-time computing module. To efficiently process the large-scale time-series datasets in distributed computing environments, Distributed Streams (DStreams) and Resilient Distributed Datasets (RDDs) are used to store and calculate these datasets. Extensive experimental results show that our PPTSP algorithm has significant advantages compared with other algorithms in terms of prediction accuracy and performance.