 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT1-Bench: Benchmarking Multi-Scenario Agents in Real-World Domains
Jun 09, 2026Recent advances in reasoning and tool-calling capabilities of large language models (LLMs) have enabled increasingly capable agentic systems. However, existing benchmarks remain limited in task complexity, realism, and domain diversity, and often fail to capture interactions that span multiple domains, limiting their ability to evaluate agents in realistic multi-step settings that require sustained reasoning and coordination. To address these limitations, we introduce T1-Bench, a high-fidelity, comprehensive benchmark for evaluating agentic systems in realistic customer-facing, multi-domain environments, featuring interleaved scenarios that require structured reasoning across multi-turn user-assistant interactions and substantially increasing both compositional complexity and evaluative rigor across 25 domains of varying difficulty. We evaluate T1-Bench using 12 proprietary and open-weight models, providing a reproducible and standardized framework for assessing agent behavior, tool utilization, and conversational quality in complex, multi-step environments. We further complement automatic evaluation with human judgments to strengthen the assessment of qualitative performance. Overall, T1-Bench substantially advances prior benchmarks by increasing task complexity, interaction depth, and domain coverage in simulated multi-domain environments. To facilitate future research on agentic systems, we will publicly release data and evaluation code as open source.
T1: A Tool-Oriented Conversational Dataset for Multi-Turn Agentic Planning
May 22, 2025



Large Language Models (LLMs) have demonstrated impressive capabilities as intelligent agents capable of solving complex problems. However, effective planning in scenarios involving dependencies between API or tool calls-particularly in multi-turn conversations-remains a significant challenge. To address this, we introduce T1, a tool-augmented, multi-domain, multi-turn conversational dataset specifically designed to capture and manage inter-tool dependencies across diverse domains. T1 enables rigorous evaluation of agents' ability to coordinate tool use across nine distinct domains (4 single domain and 5 multi-domain) with the help of an integrated caching mechanism for both short- and long-term memory, while supporting dynamic replanning-such as deciding whether to recompute or reuse cached results. Beyond facilitating research on tool use and planning, T1 also serves as a benchmark for evaluating the performance of open-source language models. We present results powered by T1-Agent, highlighting their ability to plan and reason in complex, tool-dependent scenarios.
APRICOT: A Dataset of Physical Adversarial Attacks on Object Detection
Dec 17, 2019
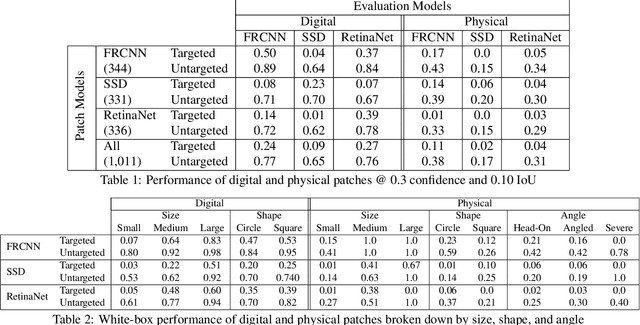

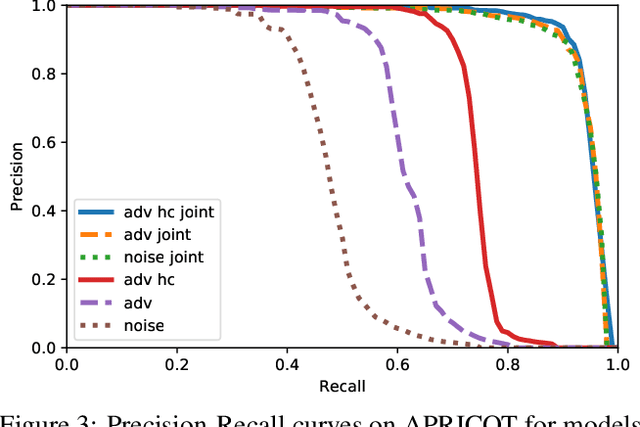
Physical adversarial attacks threaten to fool object detection systems, but reproducible research on the real-world effectiveness of physical patches and how to defend against them requires a publicly available benchmark dataset. We present APRICOT, a collection of over 1,000 annotated photographs of printed adversarial patches in public locations. The patches target several object categories for three COCO-trained detection models, and the photos represent natural variation in position, distance, lighting conditions, and viewing angle. Our analysis suggests that maintaining adversarial robustness in uncontrolled settings is highly challenging, but it is still possible to produce targeted detections under white-box and sometimes black-box settings. We establish baselines for defending against adversarial patches through several methods, including a detector supervised with synthetic data and unsupervised methods such as kernel density estimation, Bayesian uncertainty, and reconstruction error. Our results suggest that adversarial patches can be effectively flagged, both in a high-knowledge, attack-specific scenario, and in an unsupervised setting where patches are detected as anomalies in natural images. This dataset and the described experiments provide a benchmark for future research on the effectiveness of and defenses against physical adversarial objects in the wild.