 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Remote Sensing Foundation Models: Data Domain Tradeoffs at the Peta-Scale
Dec 29, 2025We explore the scaling behaviors of artificial intelligence to establish practical techniques for training foundation models on high-resolution electro-optical (EO) datasets that exceed the current state-of-the-art scale by orders of magnitude. Modern multimodal machine learning (ML) applications, such as generative artificial intelligence (GenAI) systems for image captioning, search, and reasoning, depend on robust, domain-specialized encoders for non-text modalities. In natural-image domains where internet-scale data is plentiful, well-established scaling laws help optimize the joint scaling of model capacity, training compute, and dataset size. Unfortunately, these relationships are much less well-understood in high-value domains like remote sensing (RS). Using over a quadrillion pixels of commercial satellite EO data and the MITRE Federal AI Sandbox, we train progressively larger vision transformer (ViT) backbones, report success and failure modes observed at petascale, and analyze implications for bridging domain gaps across additional RS modalities. We observe that even at this scale, performance is consistent with a data limited regime rather than a model parameter-limited one. These practical insights are intended to inform data-collection strategies, compute budgets, and optimization schedules that advance the future development of frontier-scale RS foundation models.
Benchmarking Image Similarity Metrics for Novel View Synthesis Applications
Jun 14, 2025



Traditional image similarity metrics are ineffective at evaluating the similarity between a real image of a scene and an artificially generated version of that viewpoint [6, 9, 13, 14]. Our research evaluates the effectiveness of a new, perceptual-based similarity metric, DreamSim [2], and three popular image similarity metrics: Structural Similarity (SSIM), Peak Signal-to-Noise Ratio (PSNR), and Learned Perceptual Image Patch Similarity (LPIPS) [18, 19] in novel view synthesis (NVS) applications. We create a corpus of artificially corrupted images to quantify the sensitivity and discriminative power of each of the image similarity metrics. These tests reveal that traditional metrics are unable to effectively differentiate between images with minor pixel-level changes and those with substantial corruption, whereas DreamSim is more robust to minor defects and can effectively evaluate the high-level similarity of the image. Additionally, our results demonstrate that DreamSim provides a more effective and useful evaluation of render quality, especially for evaluating NVS renders in real-world use cases where slight rendering corruptions are common, but do not affect image utility for human tasks.
Overhead Detection: Beyond 8-bits and RGB
Aug 07, 2018
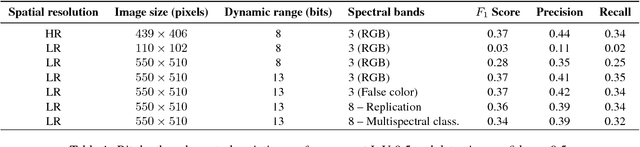
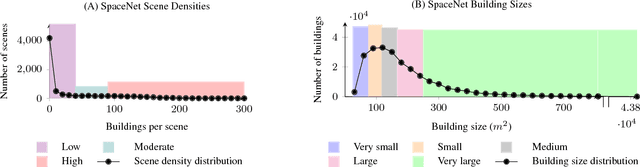
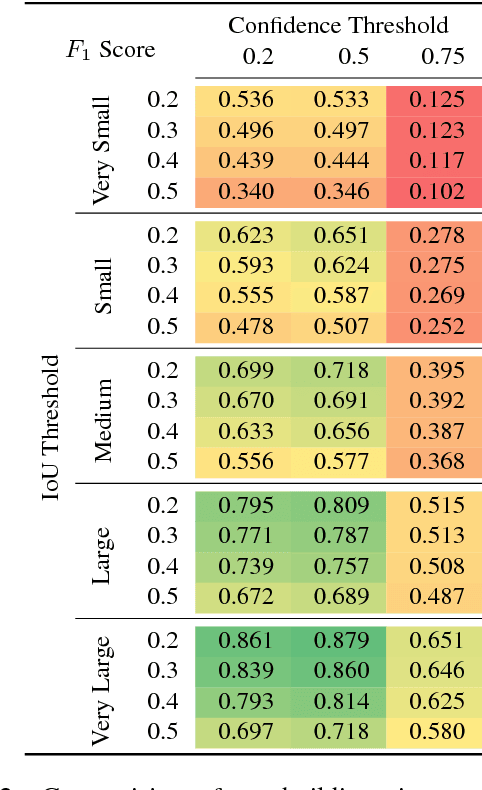
This study uses the challenging and publicly available SpaceNet dataset to establish a performance baseline for a state-of-the-art object detector in satellite imagery. Specifically, we examine how various features of the data affect building detection accuracy with respect to the Intersection over Union metric. We demonstrate that the performance of the R-FCN detection algorithm on imagery with a 1.5 meter ground sample distance and three spectral bands increases by over 32% by using 13-bit data, as opposed to 8-bit data at the same spatial and spectral resolution. We also establish accuracy trends with respect to building size and scene density. Finally, we propose and evaluate multiple methods for integrating additional spectral information into off-the-shelf deep learning architectures. Interestingly, our methods are robust to the choice of spectral bands and we note no significant performance improvement when adding additional bands.
* 10 pages, 8 figures, 2 tables