 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion-level Active Learning for Cluttered Scenes
Aug 20, 2021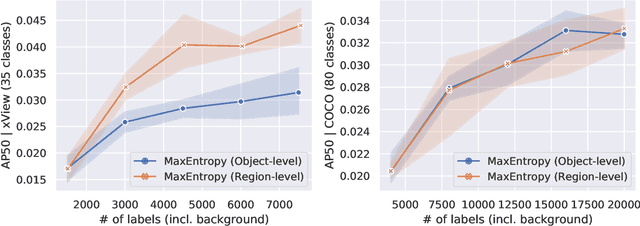
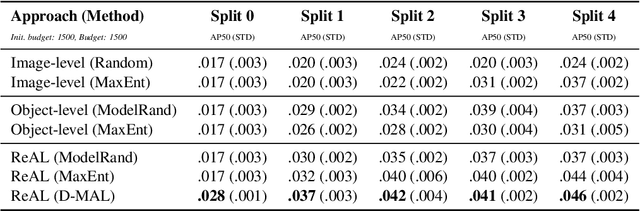
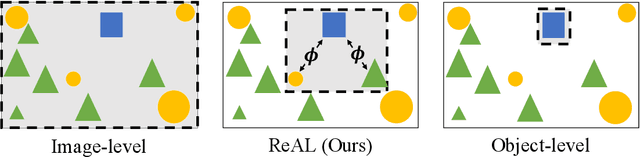
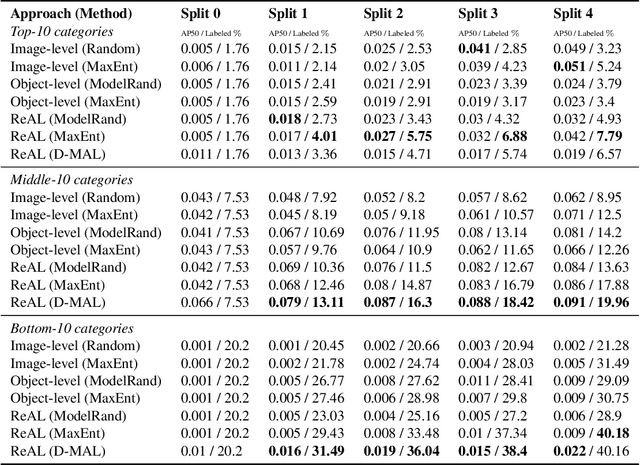
Active learning for object detection is conventionally achieved by applying techniques developed for classification in a way that aggregates individual detections into image-level selection criteria. This is typically coupled with the costly assumption that every image selected for labelling must be exhaustively annotated. This yields incremental improvements on well-curated vision datasets and struggles in the presence of data imbalance and visual clutter that occurs in real-world imagery. Alternatives to the image-level approach are surprisingly under-explored in the literature. In this work, we introduce a new strategy that subsumes previous Image-level and Object-level approaches into a generalized, Region-level approach that promotes spatial-diversity by avoiding nearby redundant queries from the same image and minimizes context-switching for the labeler. We show that this approach significantly decreases labeling effort and improves rare object search on realistic data with inherent class-imbalance and cluttered scenes.
Overhead Detection: Beyond 8-bits and RGB
Aug 07, 2018
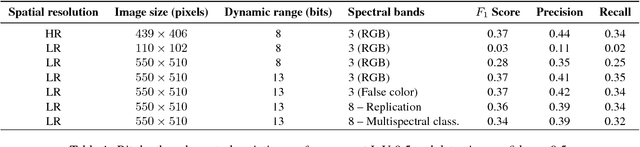
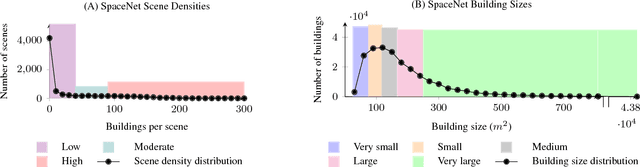
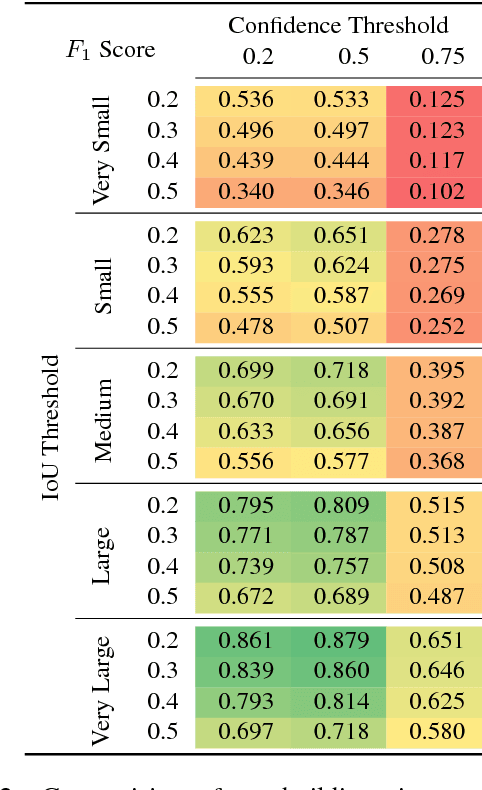
This study uses the challenging and publicly available SpaceNet dataset to establish a performance baseline for a state-of-the-art object detector in satellite imagery. Specifically, we examine how various features of the data affect building detection accuracy with respect to the Intersection over Union metric. We demonstrate that the performance of the R-FCN detection algorithm on imagery with a 1.5 meter ground sample distance and three spectral bands increases by over 32% by using 13-bit data, as opposed to 8-bit data at the same spatial and spectral resolution. We also establish accuracy trends with respect to building size and scene density. Finally, we propose and evaluate multiple methods for integrating additional spectral information into off-the-shelf deep learning architectures. Interestingly, our methods are robust to the choice of spectral bands and we note no significant performance improvement when adding additional bands.
* 10 pages, 8 figures, 2 tables
xView: Objects in Context in Overhead Imagery
Feb 22, 2018
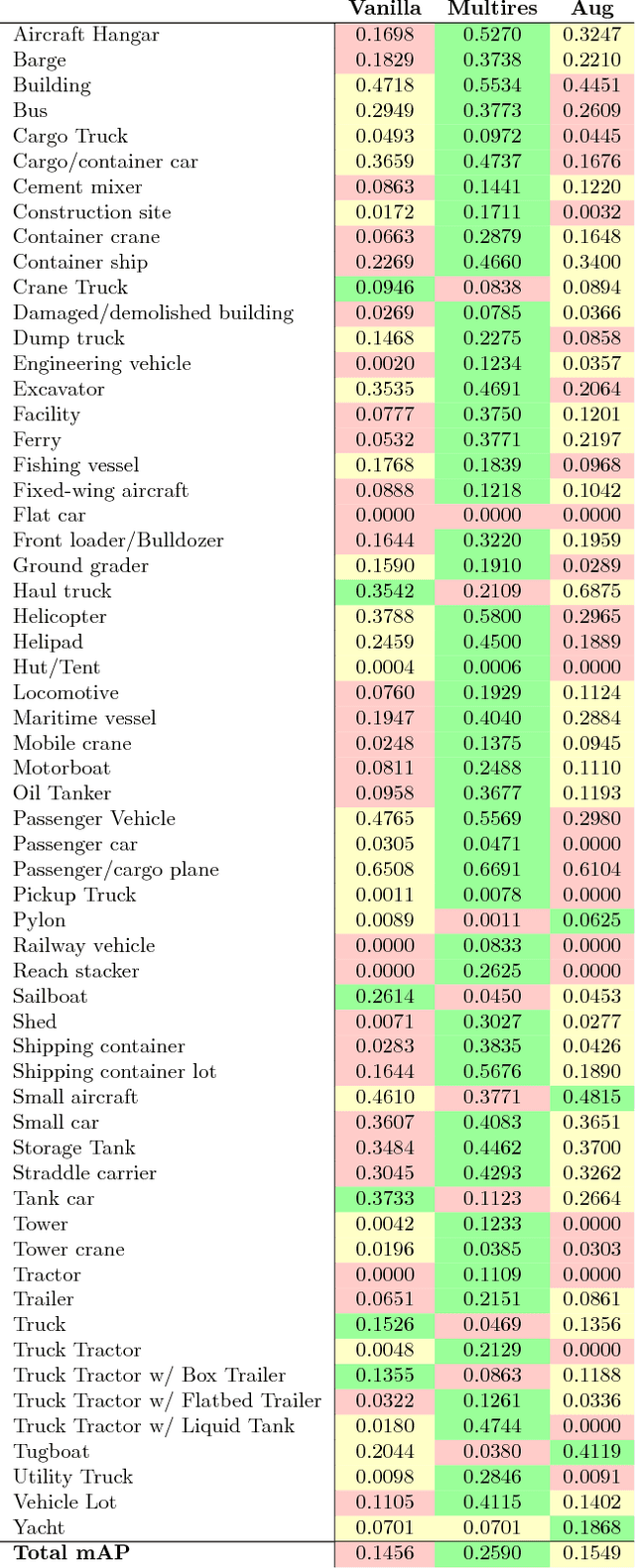


We introduce a new large-scale dataset for the advancement of object detection techniques and overhead object detection research. This satellite imagery dataset enables research progress pertaining to four key computer vision frontiers. We utilize a novel process for geospatial category detection and bounding box annotation with three stages of quality control. Our data is collected from WorldView-3 satellites at 0.3m ground sample distance, providing higher resolution imagery than most public satellite imagery datasets. We compare xView to other object detection datasets in both natural and overhead imagery domains and then provide a baseline analysis using the Single Shot MultiBox Detector. xView is one of the largest and most diverse publicly available object-detection datasets to date, with over 1 million objects across 60 classes in over 1,400 km^2 of imagery.