 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Video Multi-Frame Interpolation and Deblurring under Unknown Exposure Time
Mar 27, 2023



Natural videos captured by consumer cameras often suffer from low framerate and motion blur due to the combination of dynamic scene complexity, lens and sensor imperfection, and less than ideal exposure setting. As a result, computational methods that jointly perform video frame interpolation and deblurring begin to emerge with the unrealistic assumption that the exposure time is known and fixed. In this work, we aim ambitiously for a more realistic and challenging task - joint video multi-frame interpolation and deblurring under unknown exposure time. Toward this goal, we first adopt a variant of supervised contrastive learning to construct an exposure-aware representation from input blurred frames. We then train two U-Nets for intra-motion and inter-motion analysis, respectively, adapting to the learned exposure representation via gain tuning. We finally build our video reconstruction network upon the exposure and motion representation by progressive exposure-adaptive convolution and motion refinement. Extensive experiments on both simulated and real-world datasets show that our optimized method achieves notable performance gains over the state-of-the-art on the joint video x8 interpolation and deblurring task. Moreover, on the seemingly implausible x16 interpolation task, our method outperforms existing methods by more than 1.5 dB in terms of PSNR.
Hiding Images in Deep Probabilistic Models
Oct 05, 2022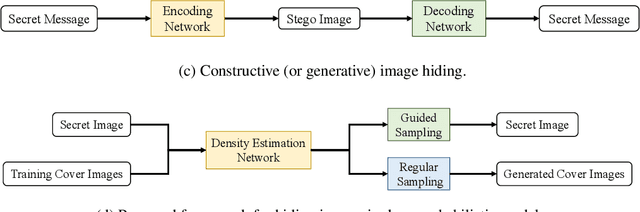

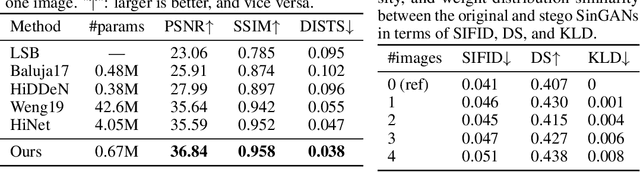

Data hiding with deep neural networks (DNNs) has experienced impressive successes in recent years. A prevailing scheme is to train an autoencoder, consisting of an encoding network to embed (or transform) secret messages in (or into) a carrier, and a decoding network to extract the hidden messages. This scheme may suffer from several limitations regarding practicability, security, and embedding capacity. In this work, we describe a different computational framework to hide images in deep probabilistic models. Specifically, we use a DNN to model the probability density of cover images, and hide a secret image in one particular location of the learned distribution. As an instantiation, we adopt a SinGAN, a pyramid of generative adversarial networks (GANs), to learn the patch distribution of one cover image. We hide the secret image by fitting a deterministic mapping from a fixed set of noise maps (generated by an embedding key) to the secret image during patch distribution learning. The stego SinGAN, behaving as the original SinGAN, is publicly communicated; only the receiver with the embedding key is able to extract the secret image. We demonstrate the feasibility of our SinGAN approach in terms of extraction accuracy and model security. Moreover, we show the flexibility of the proposed method in terms of hiding multiple images for different receivers and obfuscating the secret image.
Perceptual Attacks of No-Reference Image Quality Models with Human-in-the-Loop
Oct 03, 2022


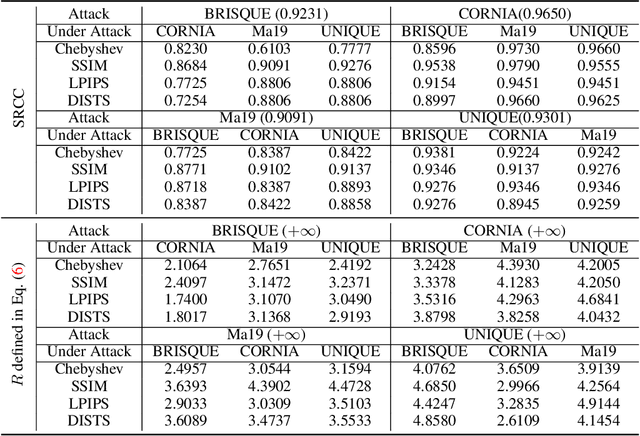
No-reference image quality assessment (NR-IQA) aims to quantify how humans perceive visual distortions of digital images without access to their undistorted references. NR-IQA models are extensively studied in computational vision, and are widely used for performance evaluation and perceptual optimization of man-made vision systems. Here we make one of the first attempts to examine the perceptual robustness of NR-IQA models. Under a Lagrangian formulation, we identify insightful connections of the proposed perceptual attack to previous beautiful ideas in computer vision and machine learning. We test one knowledge-driven and three data-driven NR-IQA methods under four full-reference IQA models (as approximations to human perception of just-noticeable differences). Through carefully designed psychophysical experiments, we find that all four NR-IQA models are vulnerable to the proposed perceptual attack. More interestingly, we observe that the generated counterexamples are not transferable, manifesting themselves as distinct design flows of respective NR-IQA methods.
Image Quality Assessment: Integrating Model-Centric and Data-Centric Approaches
Jul 29, 2022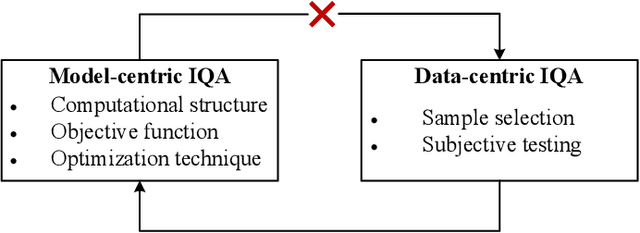
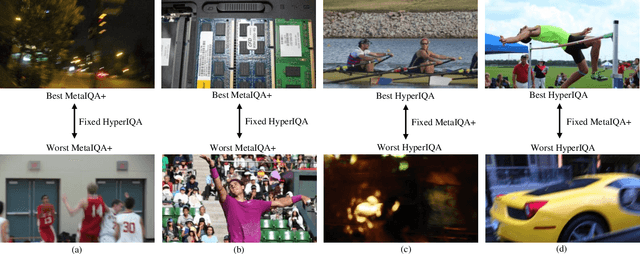
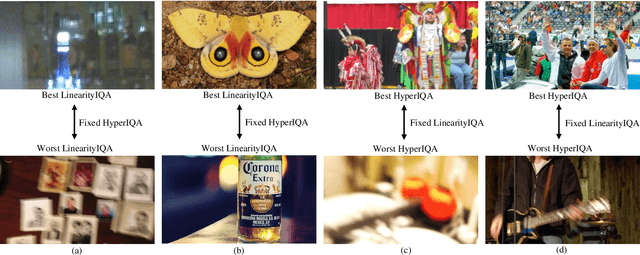

Learning-based image quality assessment (IQA) has made remarkable progress in the past decade, but nearly all consider the two key components - model and data - in relative isolation. Specifically, model-centric IQA focuses on developing "better" objective quality methods on fixed and extensively reused datasets, with a great danger of overfitting. Data-centric IQA involves conducting psychophysical experiments to construct "better" human-annotated datasets, which unfortunately ignores current IQA models during dataset creation. In this paper, we first design a series of experiments to probe computationally that such isolation of model and data impedes further progress of IQA. We then describe a computational framework that integrates model-centric and data-centric IQA. As a specific example, we design computational modules to quantify the sampling-worthiness of candidate images based on blind IQA (BIQA) model predictions and deep content-aware features. Experimental results show that the proposed sampling-worthiness module successfully spots diverse failures of the examined BIQA models, which are indeed worthy samples to be included in next-generation datasets.
Perceptual Optimization of a Biologically-Inspired Tone Mapping Operator
Jun 18, 2022

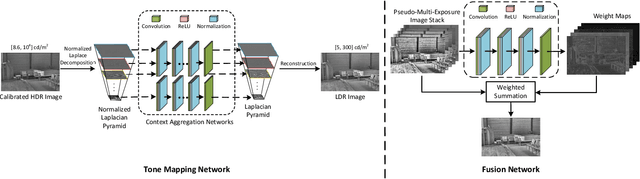
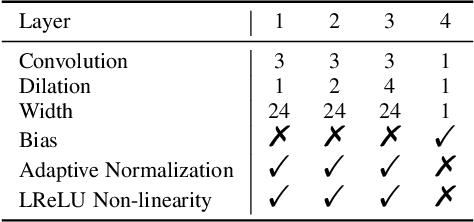
With the increasing popularity and accessibility of high dynamic range (HDR) photography, tone mapping operators (TMOs) for dynamic range compression and medium presentation are practically demanding. In this paper, we develop a two-stage neural network-based HDR image TMO that is biologically-inspired, computationally efficient, and perceptually optimized. In Stage one, motivated by the physiology of the early stages of the human visual system (HVS), we first decompose an HDR image into a normalized Laplacian pyramid. We then use two lightweight deep neural networks (DNNs) that take this normalized representation as input and estimate the Laplacian pyramid of the corresponding LDR image. We optimize the tone mapping network by minimizing the normalized Laplacian pyramid distance (NLPD), a perceptual metric calibrated against human judgments of tone-mapped image quality. In Stage two, we generate a pseudo-multi-exposure image stack with different color saturation and detail visibility by inputting an HDR image ``calibrated'' with different maximum luminances to the learned tone mapping network. We then train another lightweight DNN to fuse the LDR image stack into a desired LDR image by maximizing a variant of MEF-SSIM, another perceptually calibrated metric for image fusion. By doing so, the proposed TMO is fully automatic to tone map uncalibrated HDR images. Across an independent set of HDR images, we find that our method produces images with consistently better visual quality, and is among the fastest local TMOs.
A Database for Perceived Quality Assessment of User-Generated VR Videos
Jun 13, 2022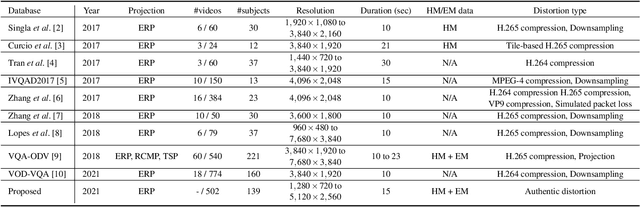

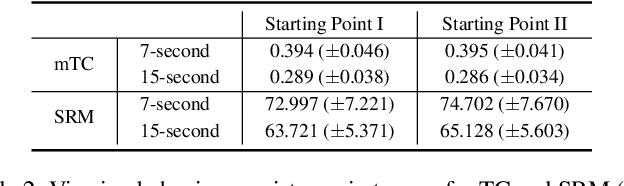
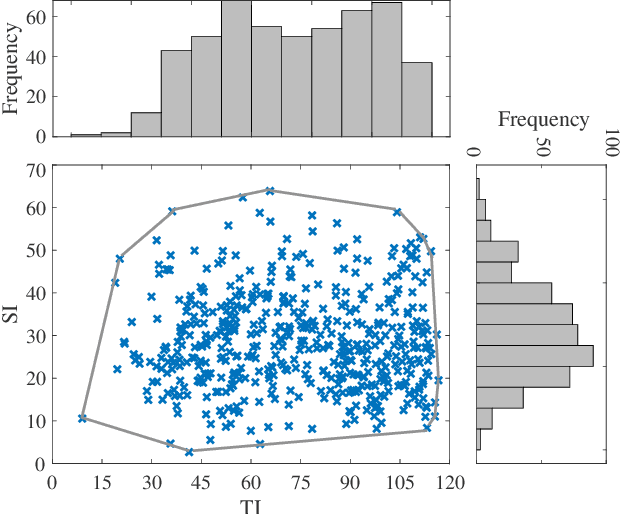
Virtual reality (VR) videos (typically in the form of 360$^\circ$ videos) have gained increasing attention due to the fast development of VR technologies and the remarkable popularization of consumer-grade 360$^\circ$ cameras and displays. Thus it is pivotal to understand how people perceive user-generated VR videos, which may suffer from commingled authentic distortions, often localized in space and time. In this paper, we establish one of the largest 360$^\circ$ video databases, containing 502 user-generated videos with rich content and distortion diversities. We capture viewing behaviors (i.e., scanpaths) of 139 users, and collect their opinion scores of perceived quality under four different viewing conditions (two starting points $\times$ two exploration times). We provide a thorough statistical analysis of recorded data, resulting in several interesting observations, such as the significant impact of viewing conditions on viewing behaviors and perceived quality. Besides, we explore other usage of our data and analysis, including evaluation of computational models for quality assessment and saliency detection of 360$^\circ$ videos. We have made the dataset and code available at https://github.com/Yao-Yiru/VR-Video-Database.
Measuring Perceptual Color Differences of Smartphone Photography
May 26, 2022

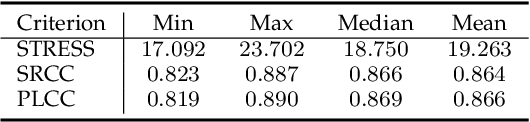

Measuring perceptual color differences (CDs) is of great importance in modern smartphone photography. Despite the long history, most CD measures have been constrained by psychophysical data of homogeneous color patches or a limited number of simplistic natural images. It is thus questionable whether existing CD measures generalize in the age of smartphone photography characterized by greater content complexities and learning-based image signal processors. In this paper, we put together so far the largest image dataset for perceptual CD assessment, in which the natural images are 1) captured by six flagship smartphones, 2) altered by Photoshop, 3) post-processed by built-in filters of the smartphones, and 4) reproduced with incorrect color profiles. We then conduct a large-scale psychophysical experiment to gather perceptual CDs of 30,000 image pairs in a carefully controlled laboratory environment. Based on the newly established dataset, we make one of the first attempts to construct an end-to-end learnable CD formula based on a lightweight neural network, as a generalization of several previous metrics. Extensive experiments demonstrate that the optimized formula outperforms 28 existing CD measures by a large margin, offers reasonable local CD maps without the use of dense supervision, generalizes well to color patch data, and empirically behaves as a proper metric in the mathematical sense.
Steerable Pyramid Transform Enables Robust Left Ventricle Quantification
Jan 20, 2022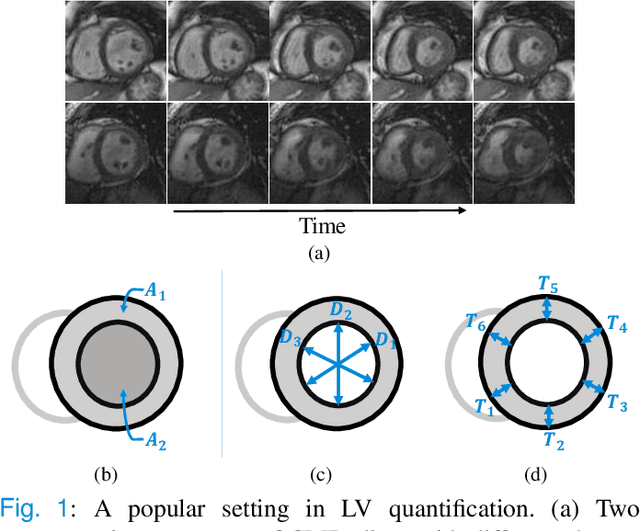
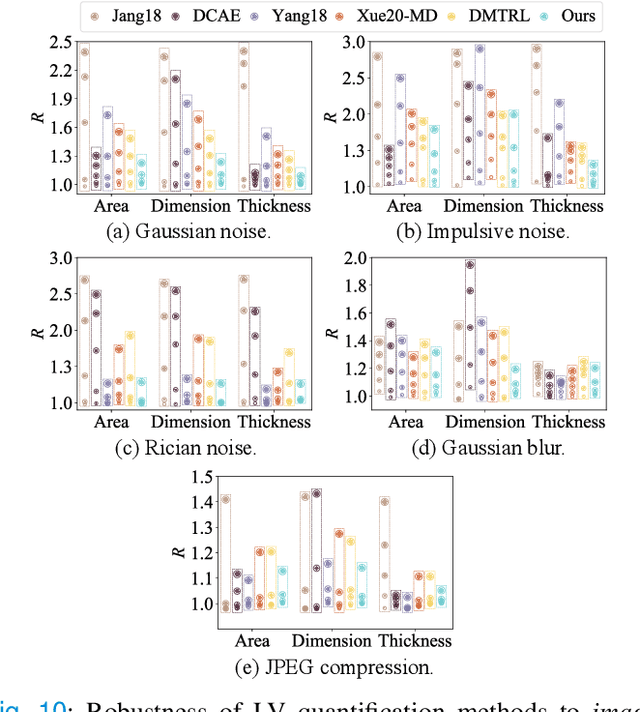
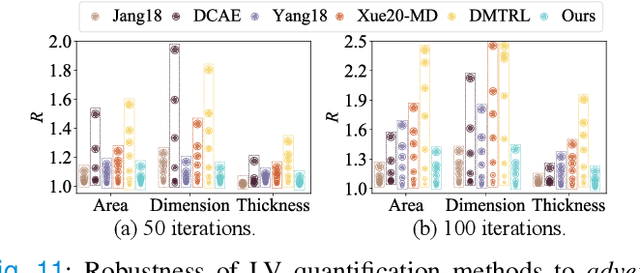
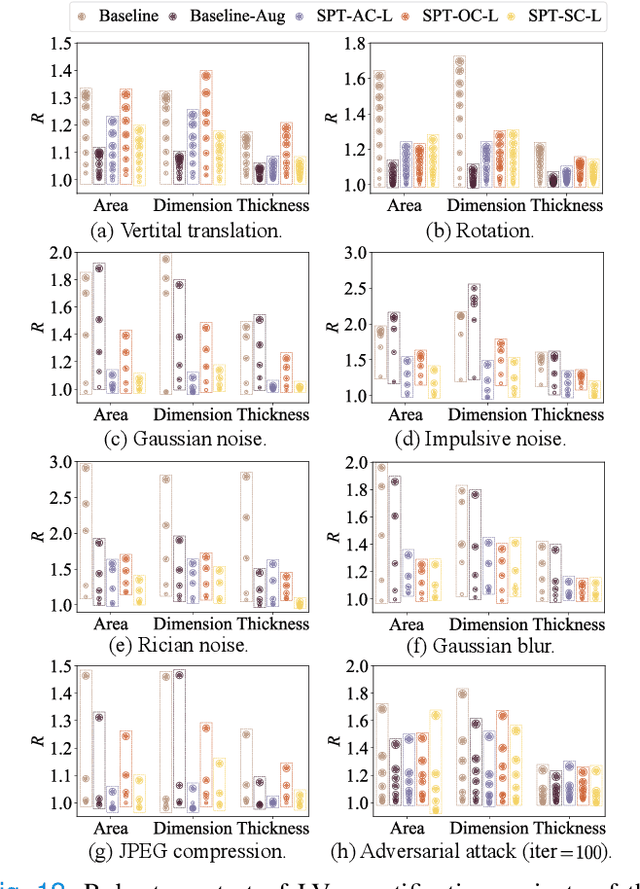
Although multifarious variants of convolutional neural networks (CNNs) have proved successful in cardiac index quantification, they seem vulnerable to mild input perturbations, e.g., spatial transformations, image distortions, and adversarial attacks. Such brittleness erodes our trust in CNN-based automated diagnosis of various cardiovascular diseases. In this work, we describe a simple and effective method to learn robust CNNs for left ventricle (LV) quantification, including cavity and myocardium areas, directional dimensions, and regional wall thicknesses. The key to the success of our approach is the use of the biologically-inspired steerable pyramid transform (SPT) as fixed front-end processing, which brings three computational advantages to LV quantification. First, the basis functions of SPT match the anatomical structure of the LV as well as the geometric characteristics of the estimated indices. Second, SPT enables sharing a CNN across different orientations as a form of parameter regularization, and explicitly captures the scale variations of the LV in a natural way. Third, the residual highpass subband can be conveniently discarded to further encourage robust feature learning. A concise and effective metric, named Robustness Ratio, is proposed to evaluate the robustness under various input perturbations. Extensive experiments on 145 cardiac sequences show that our SPT-augmented method performs favorably against state-of-the-art algorithms in terms of prediction accuracy, but is significantly more robust under input perturbations.
Pseudocylindrical Convolutions for Learned Omnidirectional Image Compression
Dec 25, 2021
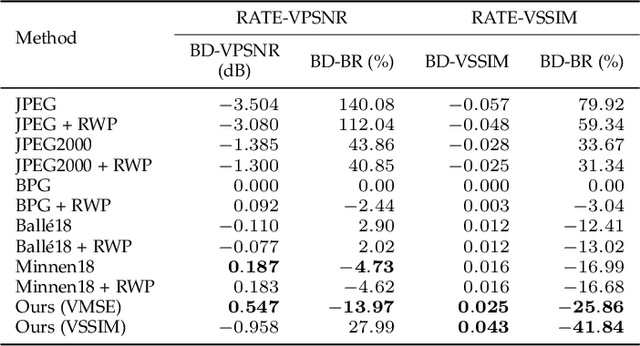
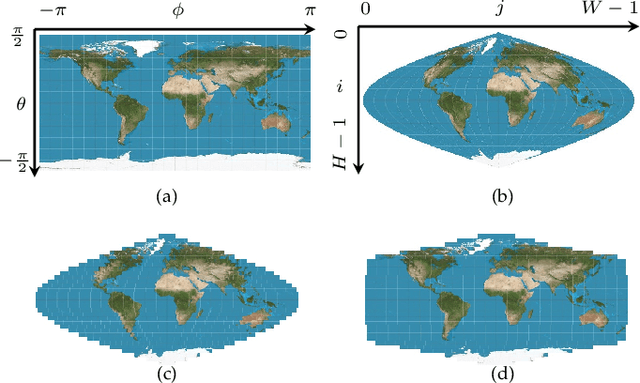

Although equirectangular projection (ERP) is a convenient form to store omnidirectional images (also known as 360-degree images), it is neither equal-area nor conformal, thus not friendly to subsequent visual communication. In the context of image compression, ERP will over-sample and deform things and stuff near the poles, making it difficult for perceptually optimal bit allocation. In conventional 360-degree image compression, techniques such as region-wise packing and tiled representation are introduced to alleviate the over-sampling problem, achieving limited success. In this paper, we make one of the first attempts to learn deep neural networks for omnidirectional image compression. We first describe parametric pseudocylindrical representation as a generalization of common pseudocylindrical map projections. A computationally tractable greedy method is presented to determine the (sub)-optimal configuration of the pseudocylindrical representation in terms of a novel proxy objective for rate-distortion performance. We then propose pseudocylindrical convolutions for 360-degree image compression. Under reasonable constraints on the parametric representation, the pseudocylindrical convolution can be efficiently implemented by standard convolution with the so-called pseudocylindrical padding. To demonstrate the feasibility of our idea, we implement an end-to-end 360-degree image compression system, consisting of the learned pseudocylindrical representation, an analysis transform, a non-uniform quantizer, a synthesis transform, and an entropy model. Experimental results on $19,790$ omnidirectional images show that our method achieves consistently better rate-distortion performance than the competing methods. Moreover, the visual quality by our method is significantly improved for all images at all bitrates.
Image Quality Assessment in the Modern Age
Oct 19, 2021This tutorial provides the audience with the basic theories, methodologies, and current progresses of image quality assessment (IQA). From an actionable perspective, we will first revisit several subjective quality assessment methodologies, with emphasis on how to properly select visual stimuli. We will then present in detail the design principles of objective quality assessment models, supplemented by an in-depth analysis of their advantages and disadvantages. Both hand-engineered and (deep) learning-based methods will be covered. Moreover, the limitations with the conventional model comparison methodology for objective quality models will be pointed out, and novel comparison methodologies such as those based on the theory of "analysis by synthesis" will be introduced. We will last discuss the real-world multimedia applications of IQA, and give a list of open challenging problems, in the hope of encouraging more and more talented researchers and engineers devoting to this exciting and rewarding research field.