 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-Geometric Set Embeddings (IGSE): From Sets to Probability Distributions
Dec 11, 2019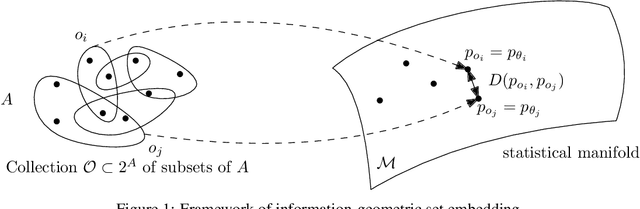
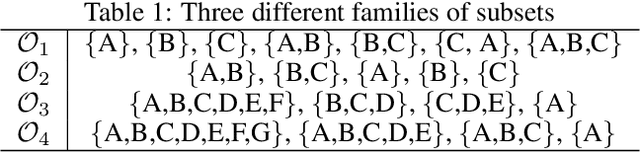
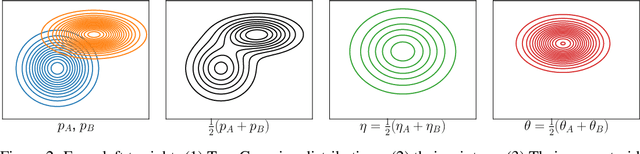
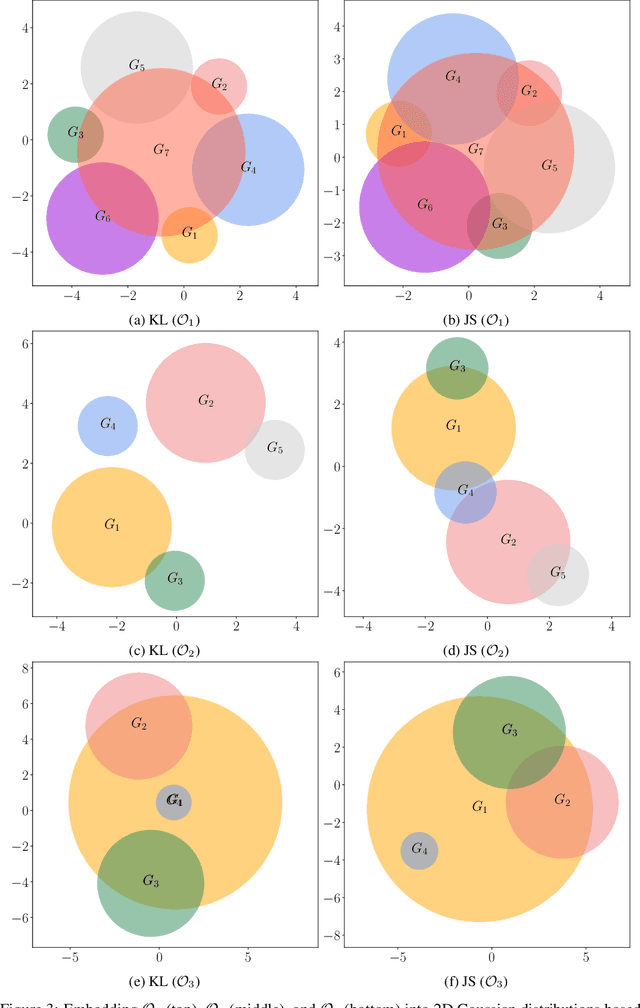
This letter introduces an abstract learning problem called the "set embedding": The objective is to map sets into probability distributions so as to lose less information. We relate set union and intersection operations with corresponding interpolations of probability distributions. We also demonstrate a preliminary solution with experimental results on toy set embedding examples.
Patch-level Neighborhood Interpolation: A General and Effective Graph-based Regularization Strategy
Nov 21, 2019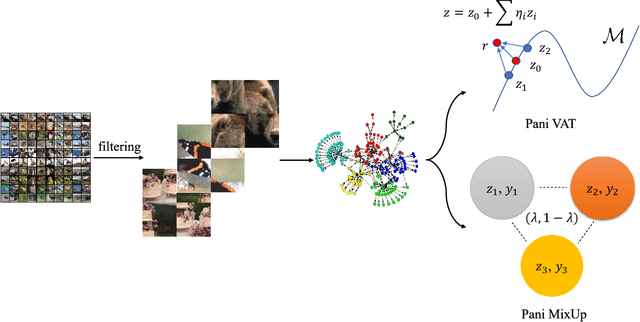

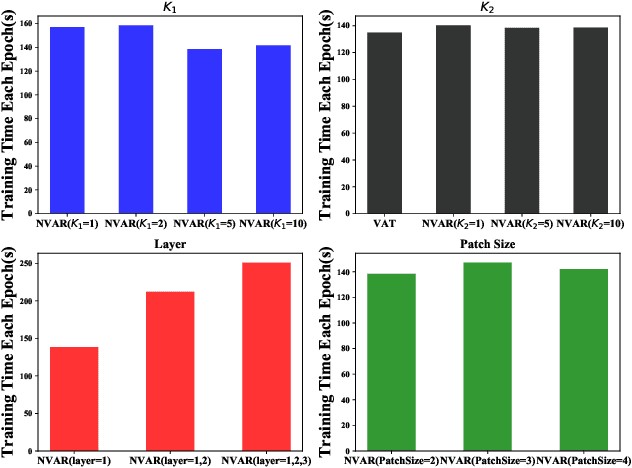
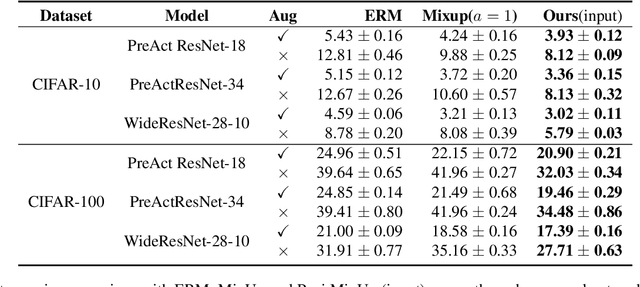
Regularization plays a crucial role in machine learning models, especially for deep neural networks. The existing regularization techniques mainly reply on the i.i.d. assumption and only employ the information of the current sample, without the leverage of neighboring information between samples. In this work, we propose a general regularizer called Patch-level Neighborhood Interpolation~(\textbf{Pani}) that fully exploits the relationship between samples. Furthermore, by explicitly constructing a patch-level graph in the different network layers and interpolating the neighborhood features to refine the representation of the current sample, our Patch-level Neighborhood Interpolation can then be applied to enhance two popular regularization strategies, namely Virtual Adversarial Training (VAT) and MixUp, yielding their neighborhood versions. The first derived \textbf{Pani VAT} presents a novel way to construct non-local adversarial smoothness by incorporating patch-level interpolated perturbations. In addition, the \textbf{Pani MixUp} method extends the original MixUp regularization to the patch level and then can be developed to MixMatch, achieving the state-of-the-art performance. Finally, extensive experiments are conducted to verify the effectiveness of the Patch-level Neighborhood Interpolation in both supervised and semi-supervised settings.
A Note on Our Submission to Track 4 of iDASH 2019
Oct 24, 2019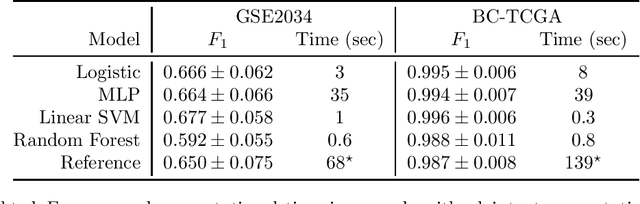
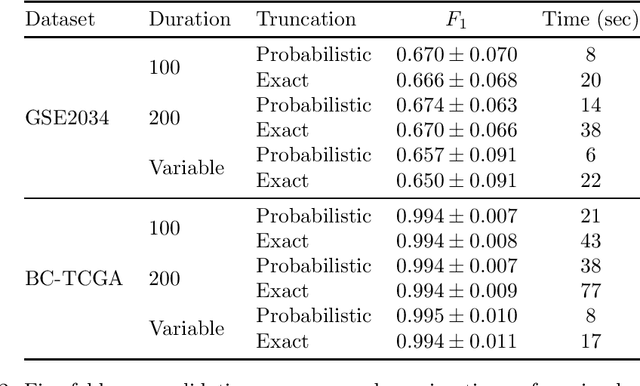
iDASH is a competition soliciting implementations of cryptographic schemes of interest in the context of biology. In 2019, one track asked for multi-party computation implementations of training of a machine learning model suitable for two datasets from cancer research. In this note, we describe our solution submitted to the competition. We found that the training can be run on three AWS c5.9xlarge instances in less then one minute using MPC tolerating one semi-honest corruption, and less than ten seconds at a slightly lower accuracy.
Deep High-Resolution Representation Learning for Visual Recognition
Aug 20, 2019
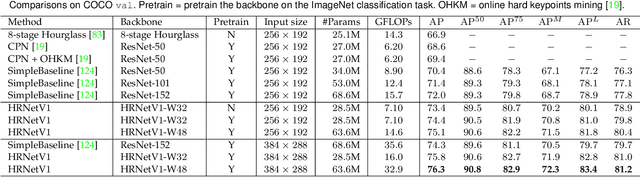

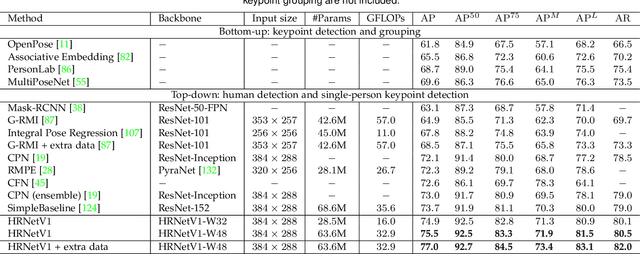
High-resolution representations are essential for position-sensitive vision problems, such as human pose estimation, semantic segmentation, and object detection. Existing state-of-the-art frameworks first encode the input image as a low-resolution representation through a subnetwork that is formed by connecting high-to-low resolution convolutions \emph{in series} (e.g., ResNet, VGGNet), and then recover the high-resolution representation from the encoded low-resolution representation. Instead, our proposed network, named as High-Resolution Network (HRNet), maintains high-resolution representations through the whole process. There are two key characteristics: (i) Connect the high-to-low resolution convolution streams \emph{in parallel}; (ii) Repeatedly exchange the information across resolutions. The benefit is that the resulting representation is semantically richer and spatially more precise. We show the superiority of the proposed HRNet in a wide range of applications, including human pose estimation, semantic segmentation, and object detection, suggesting that the HRNet is a stronger backbone for computer vision problems. All the codes are available at~{\url{https://github.com/HRNet}}.
AdaGCN: Adaboosting Graph Convolutional Networks into Deep Models
Aug 14, 2019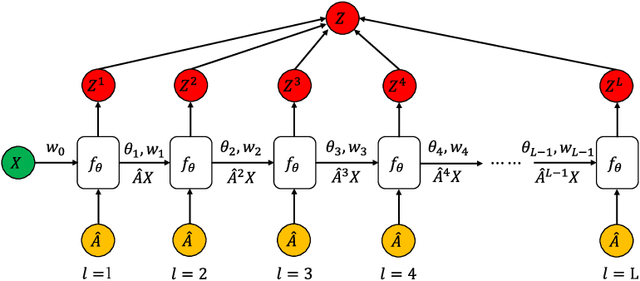

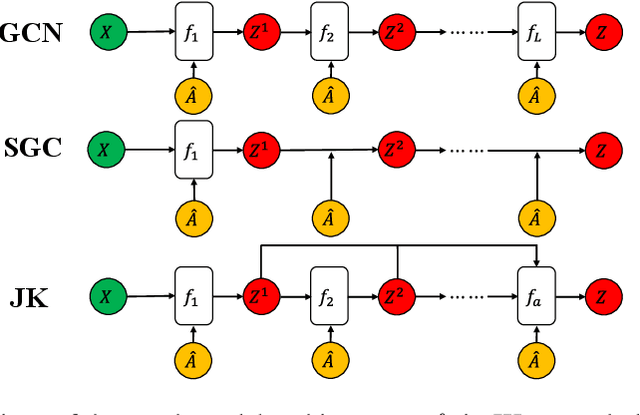
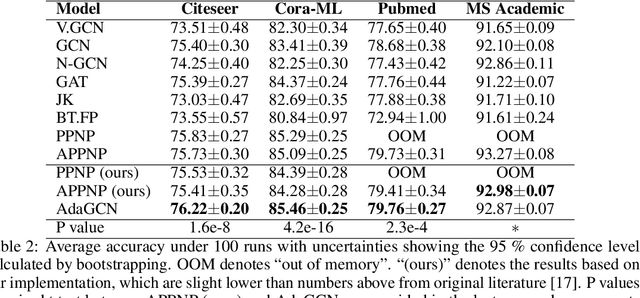
The design of deep graph models still remains to be investigated and the crucial part is how to explore and exploit the knowledge from different hops of neighbors in an efficient way. In this paper, we propose a novel RNN-like deep graph neural network architecture by incorporating AdaBoost into the computation of network; and the proposed graph convolutional network called AdaGCN~(AdaBoosting Graph Convolutional Network) has the ability to efficiently extract knowledge from high-order neighbors and integrate knowledge from different hops of neighbors into the network in an AdaBoost way. We also present the architectural difference between AdaGCN and existing graph convolutional methods to show the benefits of our proposal. Finally, extensive experiments demonstrate the state-of-the-art prediction performance and the computational advantage of our approach AdaGCN.
Learning Deep Image Priors for Blind Image Denoising
Jun 04, 2019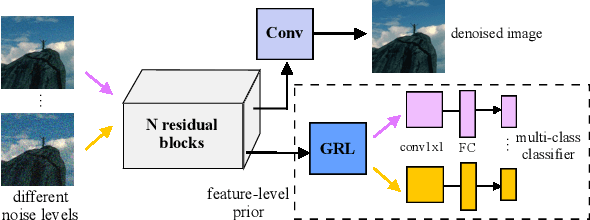
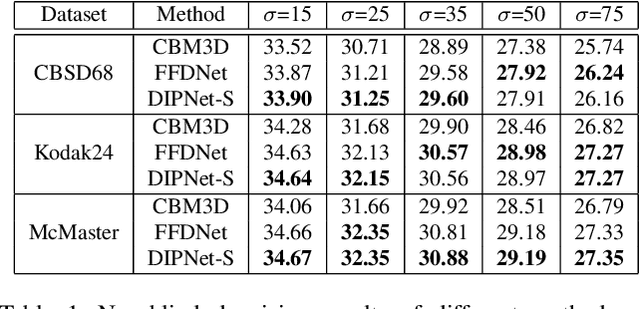
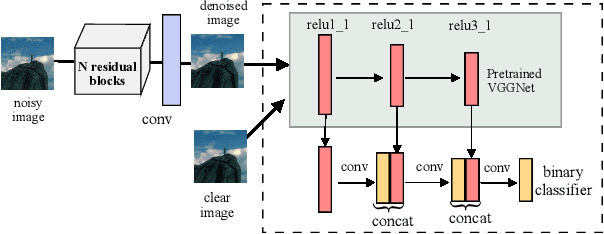
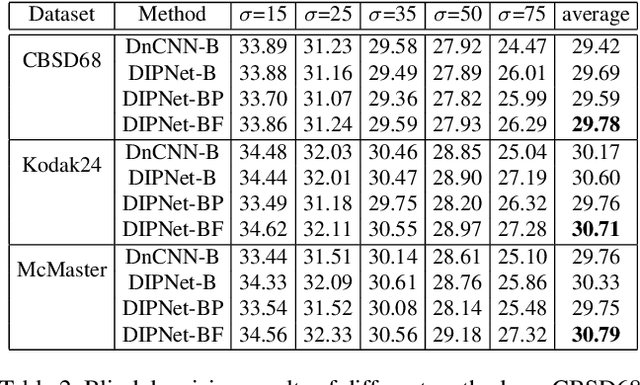
Image denoising is the process of removing noise from noisy images, which is an image domain transferring task, i.e., from a single or several noise level domains to a photo-realistic domain. In this paper, we propose an effective image denoising method by learning two image priors from the perspective of domain alignment. We tackle the domain alignment on two levels. 1) the feature-level prior is to learn domain-invariant features for corrupted images with different level noise; 2) the pixel-level prior is used to push the denoised images to the natural image manifold. The two image priors are based on $\mathcal{H}$-divergence theory and implemented by learning classifiers in adversarial training manners. We evaluate our approach on multiple datasets. The results demonstrate the effectiveness of our approach for robust image denoising on both synthetic and real-world noisy images. Furthermore, we show that the feature-level prior is capable of alleviating the discrepancy between different level noise. It can be used to improve the blind denoising performance in terms of distortion measures (PSNR and SSIM), while pixel-level prior can effectively improve the perceptual quality to ensure the realistic outputs, which is further validated by subjective evaluation.
Improving Variational Autoencoder with Deep Feature Consistent and Generative Adversarial Training
Jun 04, 2019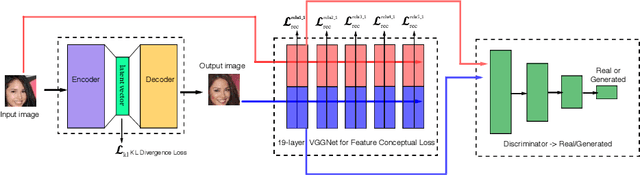
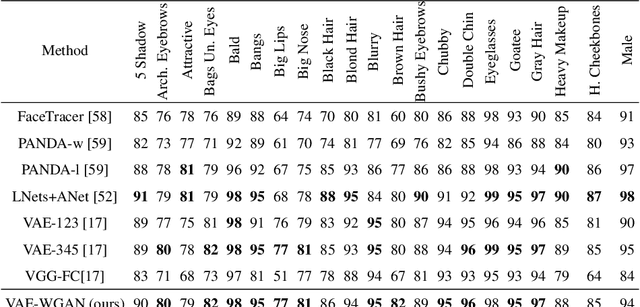
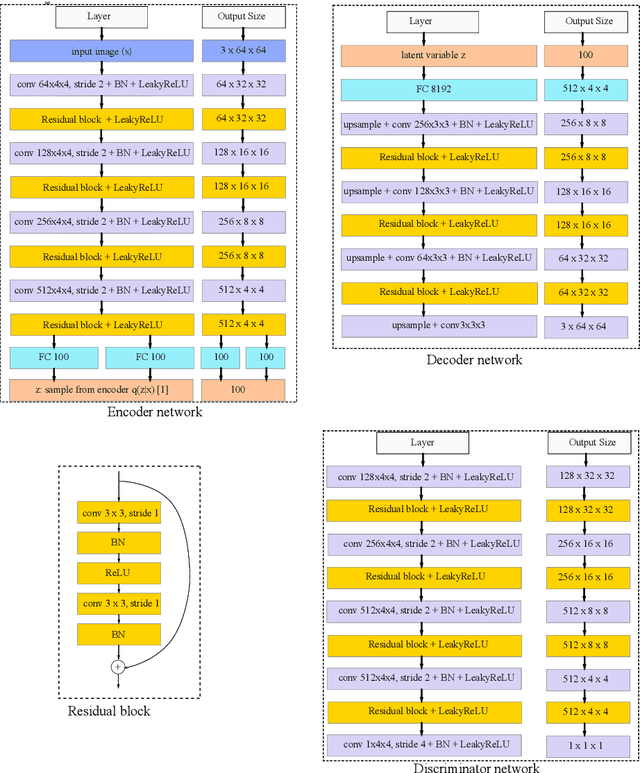

We present a new method for improving the performances of variational autoencoder (VAE). In addition to enforcing the deep feature consistent principle thus ensuring the VAE output and its corresponding input images to have similar deep features, we also implement a generative adversarial training mechanism to force the VAE to output realistic and natural images. We present experimental results to show that the VAE trained with our new method outperforms state of the art in generating face images with much clearer and more natural noses, eyes, teeth, hair textures as well as reasonable backgrounds. We also show that our method can learn powerful embeddings of input face images, which can be used to achieve facial attribute manipulation. Moreover we propose a multi-view feature extraction strategy to extract effective image representations, which can be used to achieve state of the art performance in facial attribute prediction.
Lightlike Neuromanifolds, Occam's Razor and Deep Learning
May 27, 2019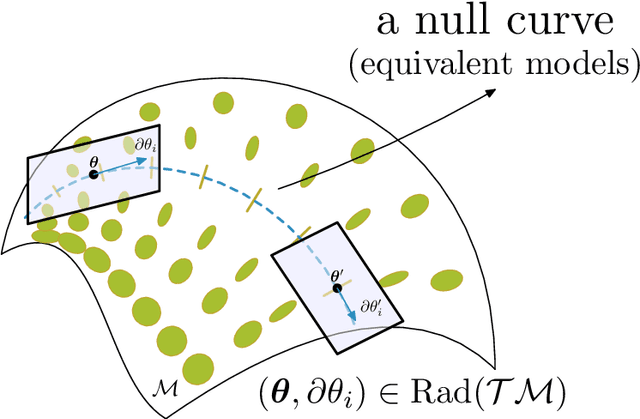
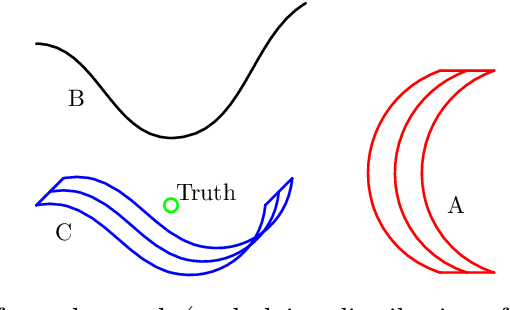
Why do deep neural networks generalize with a very high dimensional parameter space? We took an information theoretic approach. We find that the dimensionality of the parameter space can be studied by singular semi-Riemannian geometry and is upper-bounded by the sample size. We adapt Fisher information to this singular neuromanifold. We use random matrix theory to derive a minimum description length of a deep learning model, where the spectrum of the Fisher information matrix plays a key role to improve generalisation.
High-Resolution Representations for Labeling Pixels and Regions
Apr 09, 2019
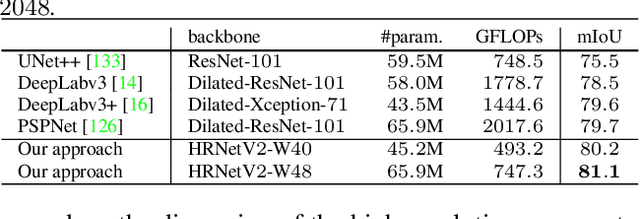
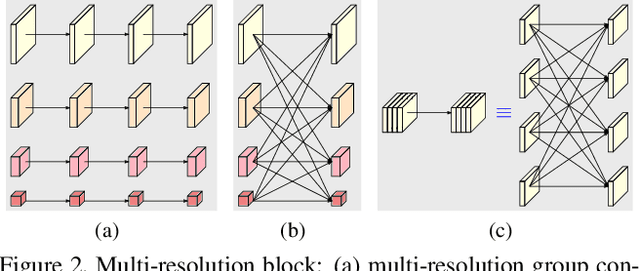
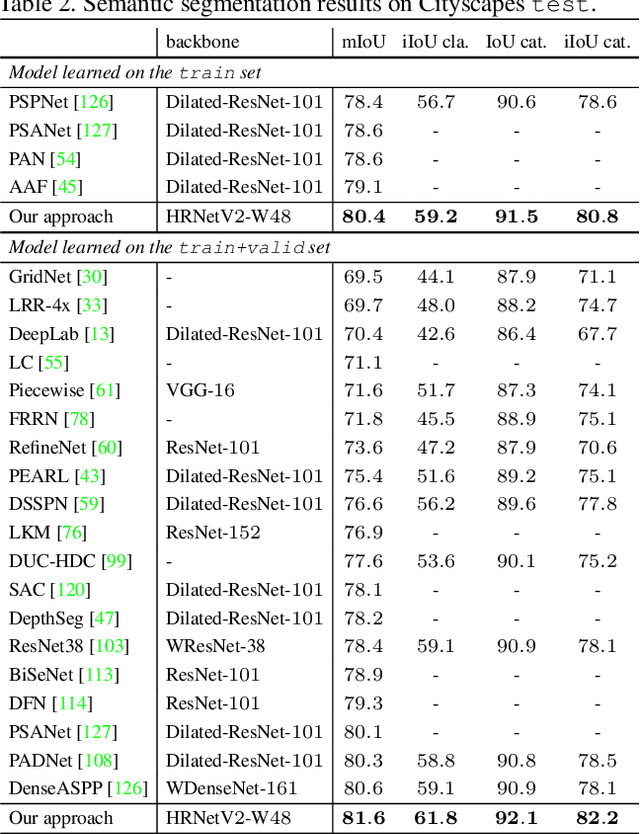
High-resolution representation learning plays an essential role in many vision problems, e.g., pose estimation and semantic segmentation. The high-resolution network (HRNet)~\cite{SunXLW19}, recently developed for human pose estimation, maintains high-resolution representations through the whole process by connecting high-to-low resolution convolutions in \emph{parallel} and produces strong high-resolution representations by repeatedly conducting fusions across parallel convolutions. In this paper, we conduct a further study on high-resolution representations by introducing a simple yet effective modification and apply it to a wide range of vision tasks. We augment the high-resolution representation by aggregating the (upsampled) representations from all the parallel convolutions rather than only the representation from the high-resolution convolution as done in~\cite{SunXLW19}. This simple modification leads to stronger representations, evidenced by superior results. We show top results in semantic segmentation on Cityscapes, LIP, and PASCAL Context, and facial landmark detection on AFLW, COFW, $300$W, and WFLW. In addition, we build a multi-level representation from the high-resolution representation and apply it to the Faster R-CNN object detection framework and the extended frameworks. The proposed approach achieves superior results to existing single-model networks on COCO object detection. The code and models have been publicly available at \url{https://github.com/HRNet}.
Fisher-Bures Adversary Graph Convolutional Networks
Mar 11, 2019
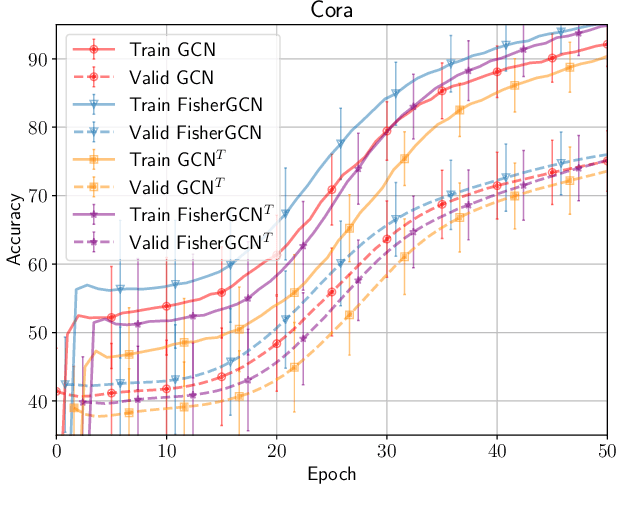

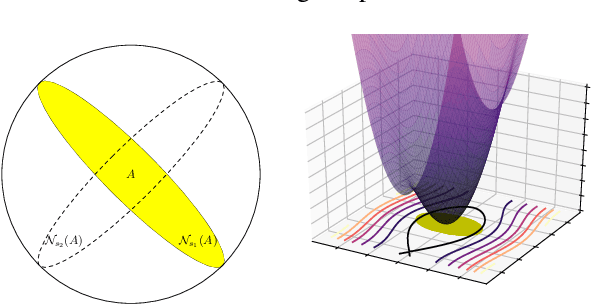
In a graph convolutional network, we assume that the graph $G$ is generated with respect to some observation noise. We make small random perturbations $\Delta{}G$ of the graph and try to improve generalization. Based on quantum information geometry, we can have quantitative measurements on the scale of $\Delta{}G$. We try to maximize the intrinsic scale of the permutation with a small budget while minimizing the loss based on the perturbed $G+\Delta{G}$. Our proposed model can consistently improve graph convolutional networks on semi-supervised node classification tasks with reasonable computational overhead. We present two different types of geometry on the manifold of graphs: one is for measuring the intrinsic change of a graph; the other is for measuring how such changes can affect externally a graph neural network. These new analytical tools will be useful in developing a good understanding of graph neural networks and fostering new techniques.