 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Thought of Search: A Journey Towards Soundness and Completeness
Aug 21, 2024



Planning remains one of the last standing bastions for large language models (LLMs), which now turn their attention to search. Most of the literature uses the language models as world models to define the search space, forgoing soundness for the sake of flexibility. A recent work, Thought of Search (ToS), proposed defining the search space with code, having the language models produce that code. ToS requires a human in the loop, collaboratively producing a sound successor function and goal test. The result, however, is worth the effort: all the tested datasets were solved with 100% accuracy. At the same time LLMs have demonstrated significant progress in code generation and refinement for complex reasoning tasks. In this work, we automate ToS (AutoToS), completely taking the human out of the loop of solving planning problems. AutoToS guides the language model step by step towards the generation of sound and complete search components, through feedback from both generic and domain specific unit tests. We achieve 100% accuracy, with minimal feedback iterations, using LLMs of various sizes on all evaluated domains.
TabSketchFM: Sketch-based Tabular Representation Learning for Data Discovery over Data Lakes
Jun 28, 2024



Enterprises have a growing need to identify relevant tables in data lakes; e.g. tables that are unionable, joinable, or subsets of each other. Tabular neural models can be helpful for such data discovery tasks. In this paper, we present TabSketchFM, a neural tabular model for data discovery over data lakes. First, we propose a novel pre-training sketch-based approach to enhance the effectiveness of data discovery techniques in neural tabular models. Second, to further finetune the pretrained model for several downstream tasks, we develop LakeBench, a collection of 8 benchmarks to help with different data discovery tasks such as finding tasks that are unionable, joinable, or subsets of each other. We then show on these finetuning tasks that TabSketchFM achieves state-of-the art performance compared to existing neural models. Third, we use these finetuned models to search for tables that are unionable, joinable, or can be subsets of each other. Our results demonstrate improvements in F1 scores for search compared to state-of-the-art techniques (even up to 70% improvement in a joinable search benchmark). Finally, we show significant transfer across datasets and tasks establishing that our model can generalize across different tasks over different data lakes
Out of style: Misadventures with LLMs and code style transfer
Jun 14, 2024



Like text, programs have styles, and certain programming styles are more desirable than others for program readability, maintainability, and performance. Code style transfer, however, is difficult to automate except for trivial style guidelines such as limits on line length. Inspired by the success of using language models for text style transfer, we investigate if code language models can perform code style transfer. Code style transfer, unlike text transfer, has rigorous requirements: the system needs to identify lines of code to change, change them correctly, and leave the rest of the program untouched. We designed CSB (Code Style Benchmark), a benchmark suite of code style transfer tasks across five categories including converting for-loops to list comprehensions, eliminating duplication in code, adding decorators to methods, etc. We then used these tests to see if large pre-trained code language models or fine-tuned models perform style transfer correctly, based on rigorous metrics to test that the transfer did occur, and the code still passes functional tests. Surprisingly, language models failed to perform all of the tasks, suggesting that they perform poorly on tasks that require code understanding. We will make available the large-scale corpora to help the community build better code models.
Planning with Language Models Through The Lens of Efficiency
Apr 18, 2024We analyse the cost of using LLMs for planning and highlight that recent trends are profoundly uneconomical. We propose a significantly more efficient approach and argue for a responsible use of compute resources; urging research community to investigate LLM-based approaches that upholds efficiency.
Improving Neural Ranking Models with Traditional IR Methods
Aug 29, 2023
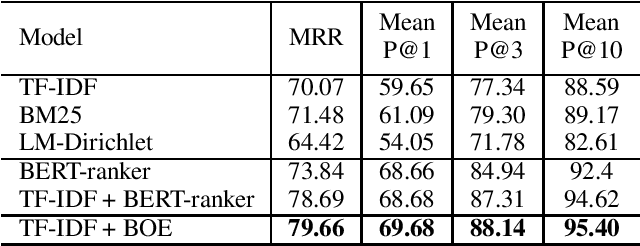


Neural ranking methods based on large transformer models have recently gained significant attention in the information retrieval community, and have been adopted by major commercial solutions. Nevertheless, they are computationally expensive to create, and require a great deal of labeled data for specialized corpora. In this paper, we explore a low resource alternative which is a bag-of-embedding model for document retrieval and find that it is competitive with large transformer models fine tuned on information retrieval tasks. Our results show that a simple combination of TF-IDF, a traditional keyword matching method, with a shallow embedding model provides a low cost path to compete well with the performance of complex neural ranking models on 3 datasets. Furthermore, adding TF-IDF measures improves the performance of large-scale fine tuned models on these tasks.
A Cross-Domain Evaluation of Approaches for Causal Knowledge Extraction
Aug 07, 2023



Causal knowledge extraction is the task of extracting relevant causes and effects from text by detecting the causal relation. Although this task is important for language understanding and knowledge discovery, recent works in this domain have largely focused on binary classification of a text segment as causal or non-causal. In this regard, we perform a thorough analysis of three sequence tagging models for causal knowledge extraction and compare it with a span based approach to causality extraction. Our experiments show that embeddings from pre-trained language models (e.g. BERT) provide a significant performance boost on this task compared to previous state-of-the-art models with complex architectures. We observe that span based models perform better than simple sequence tagging models based on BERT across all 4 data sets from diverse domains with different types of cause-effect phrases.
LakeBench: Benchmarks for Data Discovery over Data Lakes
Jul 09, 2023



Within enterprises, there is a growing need to intelligently navigate data lakes, specifically focusing on data discovery. Of particular importance to enterprises is the ability to find related tables in data repositories. These tables can be unionable, joinable, or subsets of each other. There is a dearth of benchmarks for these tasks in the public domain, with related work targeting private datasets. In LakeBench, we develop multiple benchmarks for these tasks by using the tables that are drawn from a diverse set of data sources such as government data from CKAN, Socrata, and the European Central Bank. We compare the performance of 4 publicly available tabular foundational models on these tasks. None of the existing models had been trained on the data discovery tasks that we developed for this benchmark; not surprisingly, their performance shows significant room for improvement. The results suggest that the establishment of such benchmarks may be useful to the community to build tabular models usable for data discovery in data lakes.
Generalized Planning in PDDL Domains with Pretrained Large Language Models
May 18, 2023



Recent work has considered whether large language models (LLMs) can function as planners: given a task, generate a plan. We investigate whether LLMs can serve as generalized planners: given a domain and training tasks, generate a program that efficiently produces plans for other tasks in the domain. In particular, we consider PDDL domains and use GPT-4 to synthesize Python programs. We also consider (1) Chain-of-Thought (CoT) summarization, where the LLM is prompted to summarize the domain and propose a strategy in words before synthesizing the program; and (2) automated debugging, where the program is validated with respect to the training tasks, and in case of errors, the LLM is re-prompted with four types of feedback. We evaluate this approach in seven PDDL domains and compare it to four ablations and four baselines. Overall, we find that GPT-4 is a surprisingly powerful generalized planner. We also conclude that automated debugging is very important, that CoT summarization has non-uniform impact, that GPT-4 is far superior to GPT-3.5, and that just two training tasks are often sufficient for strong generalization.
A Vision for Semantically Enriched Data Science
Mar 02, 2023The recent efforts in automation of machine learning or data science has achieved success in various tasks such as hyper-parameter optimization or model selection. However, key areas such as utilizing domain knowledge and data semantics are areas where we have seen little automation. Data Scientists have long leveraged common sense reasoning and domain knowledge to understand and enrich data for building predictive models. In this paper we discuss important shortcomings of current data science and machine learning solutions. We then envision how leveraging "semantic" understanding and reasoning on data in combination with novel tools for data science automation can help with consistent and explainable data augmentation and transformation. Additionally, we discuss how semantics can assist data scientists in a new manner by helping with challenges related to trust, bias, and explainability in machine learning. Semantic annotation can also help better explore and organize large data sources.
Serenity: Library Based Python Code Analysis for Code Completion and Automated Machine Learning
Jan 05, 2023



Dynamically typed languages such as Python have become very popular. Among other strengths, Python's dynamic nature and its straightforward linking to native code have made it the de-facto language for many research areas such as Artificial Intelligence. This flexibility, however, makes static analysis very hard. While creating a sound, or a soundy, analysis for Python remains an open problem, we present in this work Serenity, a framework for static analysis of Python that turns out to be sufficient for some tasks. The Serenity framework exploits two basic mechanisms: (a) reliance on dynamic dispatch at the core of language translation, and (b) extreme abstraction of libraries, to generate an abstraction of the code. We demonstrate the efficiency and usefulness of Serenity's analysis in two applications: code completion and automated machine learning. In these two applications, we demonstrate that such analysis has a strong signal, and can be leveraged to establish state-of-the-art performance, comparable to neural models and dynamic analysis respectively.