 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopological Autoencoders
Jun 03, 2019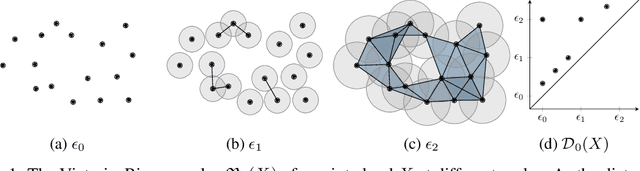
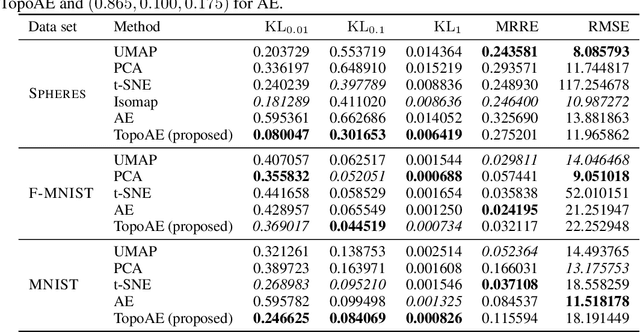
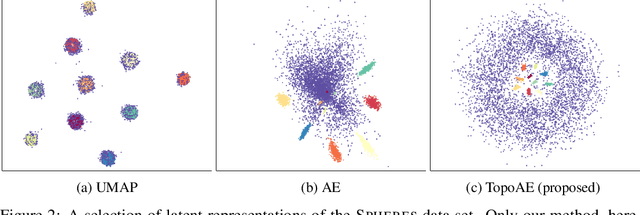

We propose a novel approach for preserving topological structures of the input space in latent representations of autoencoders. Using persistent homology, a technique from topological data analysis, we calculate topological signatures of both the input and latent space to derive a topological loss term. Under weak theoretical assumptions, we can construct this loss in a differentiable manner, such that the encoding learns to retain multi-scale connectivity information. We show that our approach is theoretically well-founded, while exhibiting favourable latent representations on synthetic manifold data sets. Moreover, on real-world data sets, introducing our topological loss leads to more meaningful latent representations while preserving low reconstruction errors.
Machine learning for early prediction of circulatory failure in the intensive care unit
Apr 19, 2019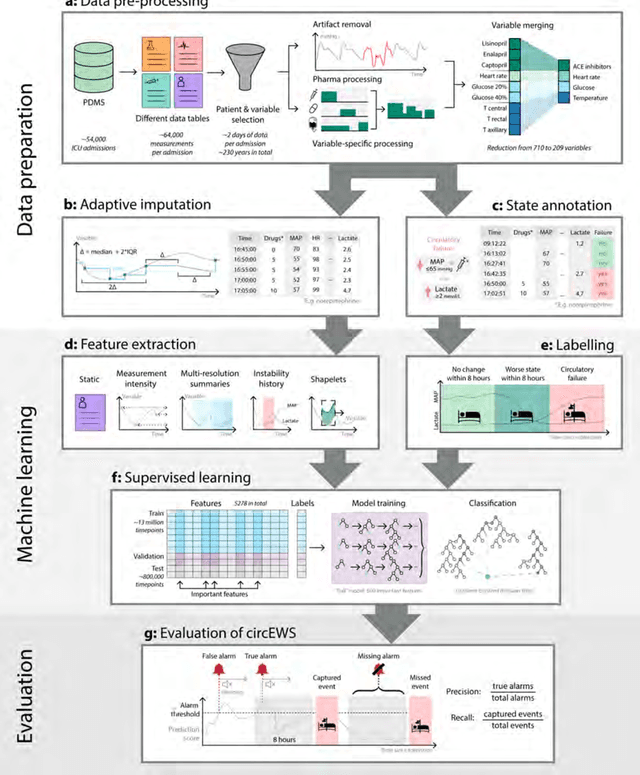
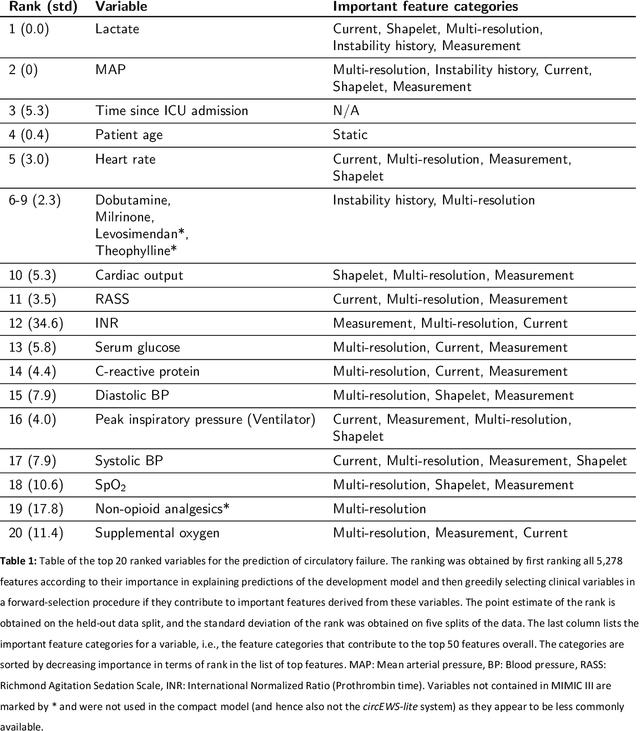
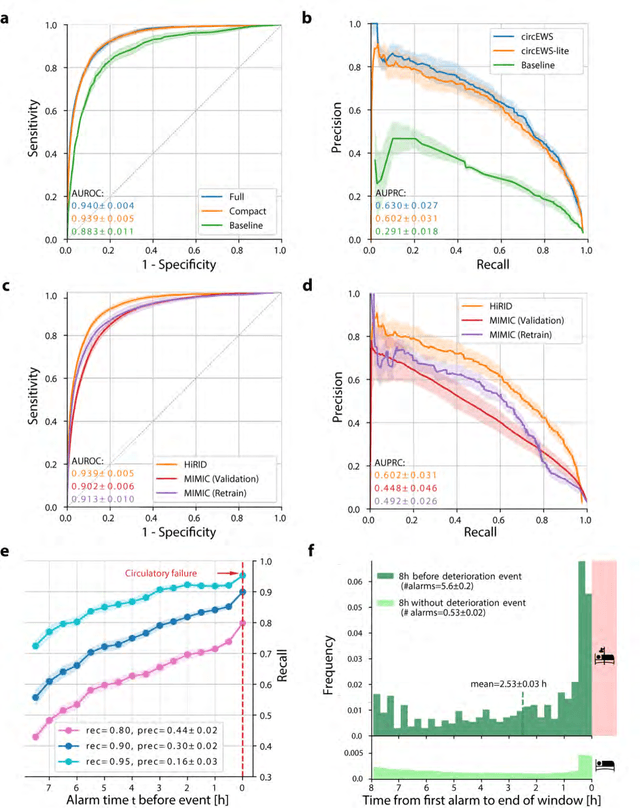
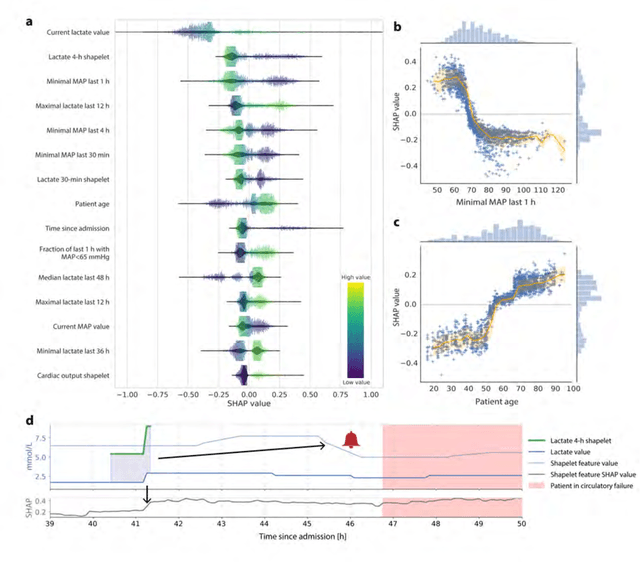
Intensive care clinicians are presented with large quantities of patient information and measurements from a multitude of monitoring systems. The limited ability of humans to process such complex information hinders physicians to readily recognize and act on early signs of patient deterioration. We used machine learning to develop an early warning system for circulatory failure based on a high-resolution ICU database with 240 patient years of data. This automatic system predicts 90.0% of circulatory failure events (prevalence 3.1%), with 81.8% identified more than two hours in advance, resulting in an area under the receiver operating characteristic curve of 94.0% and area under the precision-recall curve of 63.0%. The model was externally validated in a large independent patient cohort.
Temporal Convolutional Networks and Dynamic Time Warping can Drastically Improve the Early Prediction of Sepsis
Feb 07, 2019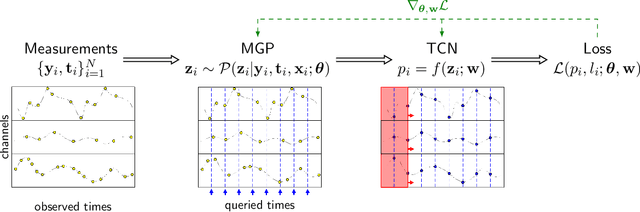
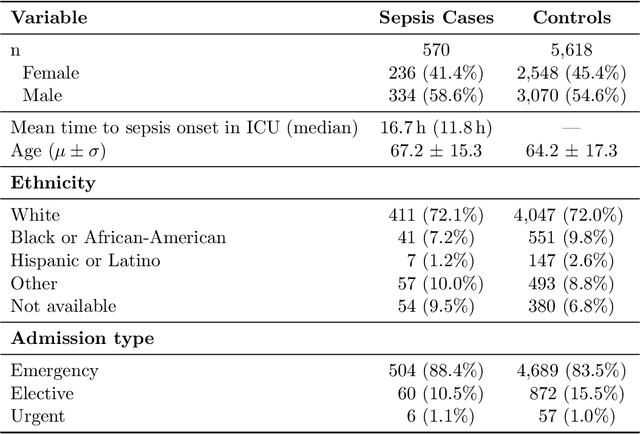
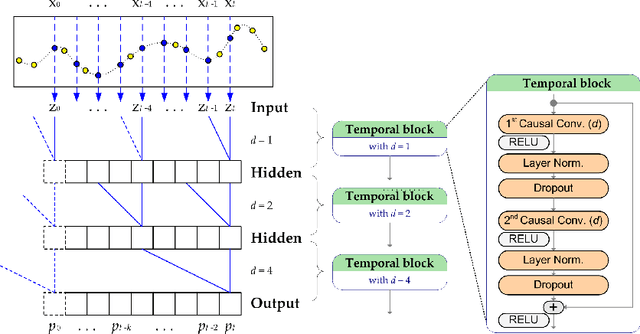
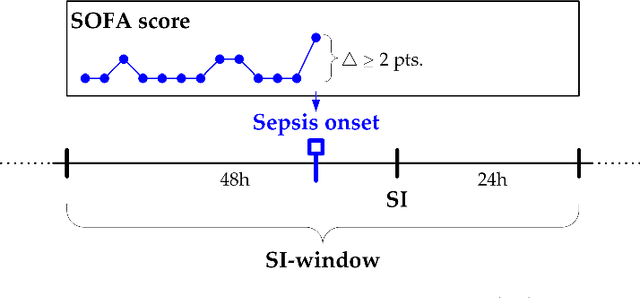
Motivation: Sepsis is a life-threatening host response to infection associated with high mortality, morbidity and health costs. Its management is highly time-sensitive since each hour of delayed treatment increases mortality due to irreversible organ damage. Meanwhile, despite decades of clinical research robust biomarkers for sepsis are missing. Therefore, detecting sepsis early by utilizing the affluence of high-resolution intensive care records has become a challenging machine learning problem. Recent advances in deep learning and data mining promise a powerful set of tools to efficiently address this task. Results: This paper proposes two approaches for the early detection of sepsis: a new deep learning model (MGP-TCN) and a data mining model (DTW-KNN). MGP-TCN employs a temporal convolutional network as embedded in a Multitask Gaussian Process Adapter framework, making it directly applicable to irregularly spaced time series data. Our DTW-KNN is an ensemble approach that employs dynamic time warping. We then frame the timely detection of sepsis as a supervised time series classification task. For this, we derive the most recent sepsis definition in an hourly resolution to provide the first fully accessible early sepsis detection environment. Seven hours before sepsis onset, our methods MGP-TCN/DTW-KNN improve area under the precision--recall curve from 0.25 to 0.35/0.40 over the state of the art. This demonstrates that they are well-suited for detecting sepsis in the crucial earlier stages when management is most effective.
Neural Persistence: A Complexity Measure for Deep Neural Networks Using Algebraic Topology
Dec 23, 2018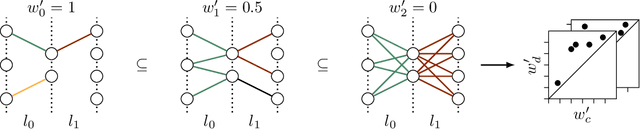
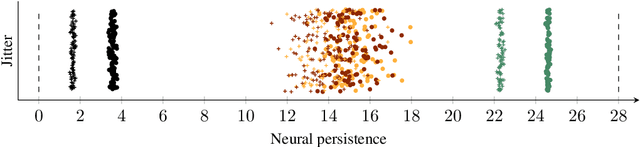

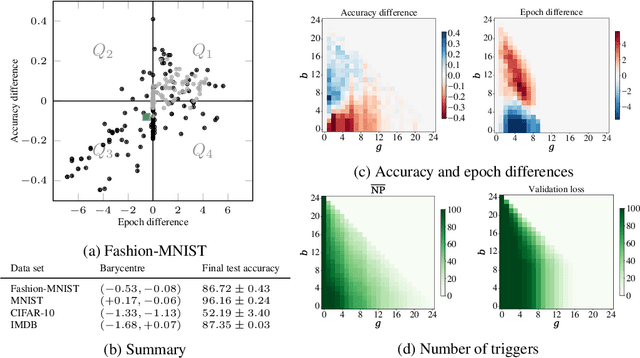
While many approaches to make neural networks more fathomable have been proposed, they are restricted to interrogating the network with input data. Measures for characterizing and monitoring structural properties, however, have not been developed. In this work, we propose neural persistence, a complexity measure for neural network architectures based on topological data analysis on weighted stratified graphs. To demonstrate the usefulness of our approach, we show that neural persistence reflects best practices developed in the deep learning community such as dropout and batch normalization. Moreover, we derive a neural persistence-based stopping criterion that shortens the training process while achieving comparable accuracies as early stopping based on validation loss.
Searching for significant patterns in stratified data
Aug 24, 2015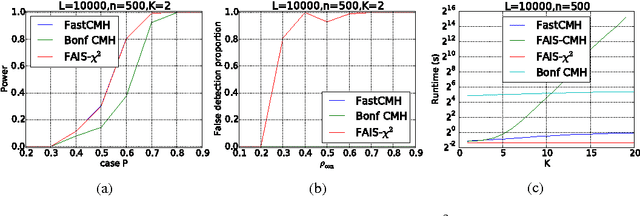
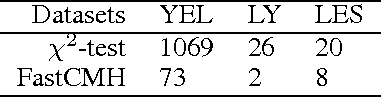
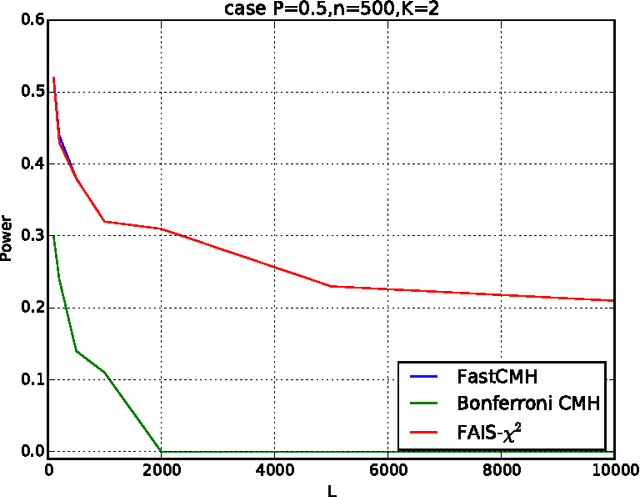
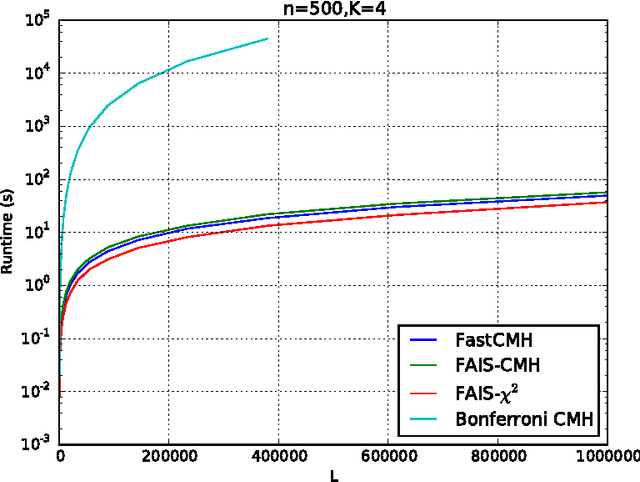
Significant pattern mining, the problem of finding itemsets that are significantly enriched in one class of objects, is statistically challenging, as the large space of candidate patterns leads to an enormous multiple testing problem. Recently, the concept of testability was proposed as one approach to correct for multiple testing in pattern mining while retaining statistical power. Still, these strategies based on testability do not allow one to condition the test of significance on the observed covariates, which severely limits its utility in biomedical applications. Here we propose a strategy and an efficient algorithm to perform significant pattern mining in the presence of categorical covariates with K states.
Geometric tree kernels: Classification of COPD from airway tree geometry
Apr 08, 2013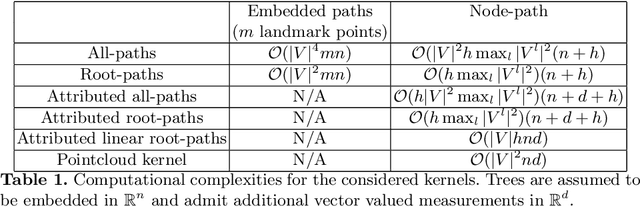

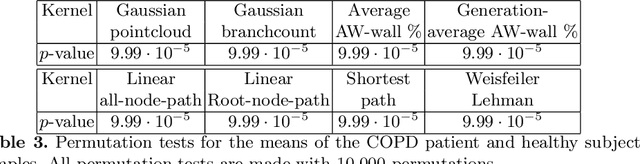
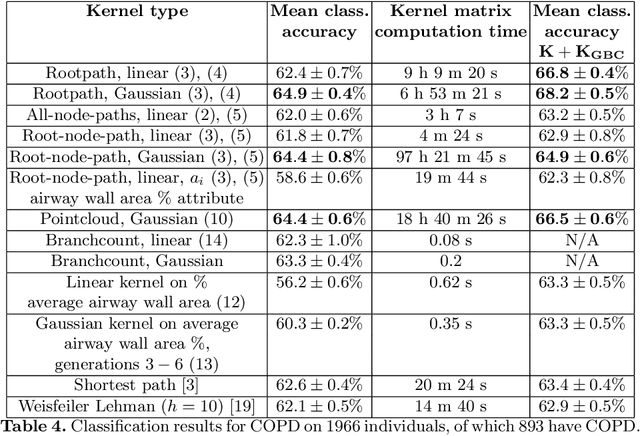
Methodological contributions: This paper introduces a family of kernels for analyzing (anatomical) trees endowed with vector valued measurements made along the tree. While state-of-the-art graph and tree kernels use combinatorial tree/graph structure with discrete node and edge labels, the kernels presented in this paper can include geometric information such as branch shape, branch radius or other vector valued properties. In addition to being flexible in their ability to model different types of attributes, the presented kernels are computationally efficient and some of them can easily be computed for large datasets (N of the order 10.000) of trees with 30-600 branches. Combining the kernels with standard machine learning tools enables us to analyze the relation between disease and anatomical tree structure and geometry. Experimental results: The kernels are used to compare airway trees segmented from low-dose CT, endowed with branch shape descriptors and airway wall area percentage measurements made along the tree. Using kernelized hypothesis testing we show that the geometric airway trees are significantly differently distributed in patients with Chronic Obstructive Pulmonary Disease (COPD) than in healthy individuals. The geometric tree kernels also give a significant increase in the classification accuracy of COPD from geometric tree structure endowed with airway wall thickness measurements in comparison with state-of-the-art methods, giving further insight into the relationship between airway wall thickness and COPD. Software: Software for computing kernels and statistical tests is available at http://image.diku.dk/aasa/software.php.
A Kernel Method for the Two-Sample Problem
May 15, 2008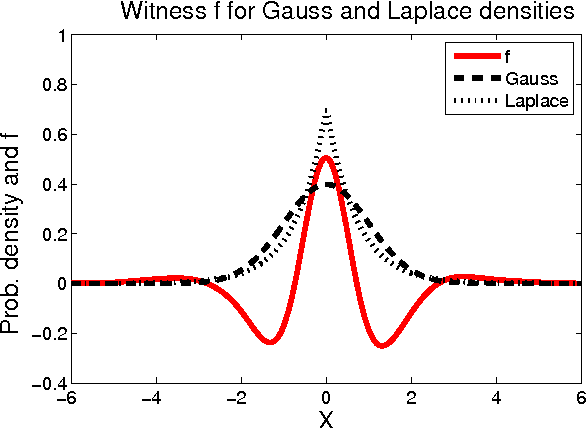
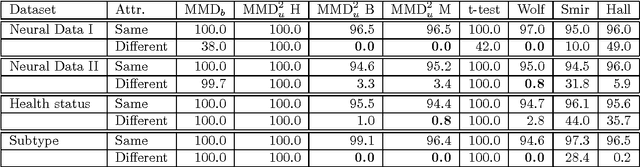
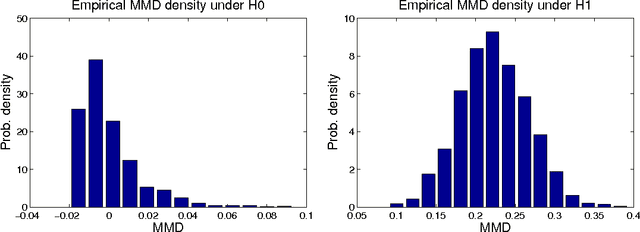
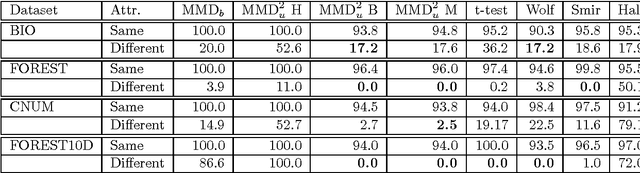
We propose a framework for analyzing and comparing distributions, allowing us to design statistical tests to determine if two samples are drawn from different distributions. Our test statistic is the largest difference in expectations over functions in the unit ball of a reproducing kernel Hilbert space (RKHS). We present two tests based on large deviation bounds for the test statistic, while a third is based on the asymptotic distribution of this statistic. The test statistic can be computed in quadratic time, although efficient linear time approximations are available. Several classical metrics on distributions are recovered when the function space used to compute the difference in expectations is allowed to be more general (eg. a Banach space). We apply our two-sample tests to a variety of problems, including attribute matching for databases using the Hungarian marriage method, where they perform strongly. Excellent performance is also obtained when comparing distributions over graphs, for which these are the first such tests.
Supervised Feature Selection via Dependence Estimation
Apr 20, 2007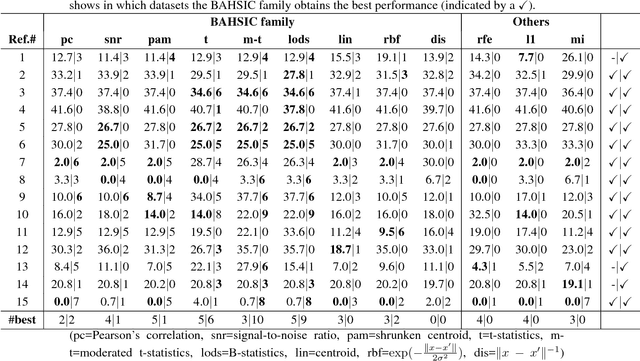
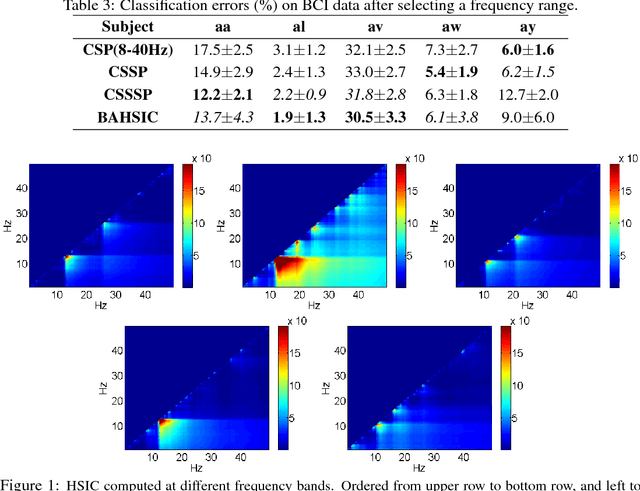


We introduce a framework for filtering features that employs the Hilbert-Schmidt Independence Criterion (HSIC) as a measure of dependence between the features and the labels. The key idea is that good features should maximise such dependence. Feature selection for various supervised learning problems (including classification and regression) is unified under this framework, and the solutions can be approximated using a backward-elimination algorithm. We demonstrate the usefulness of our method on both artificial and real world datasets.