 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultivariate Spearman's rho for aggregating ranks using copulas
Dec 02, 2016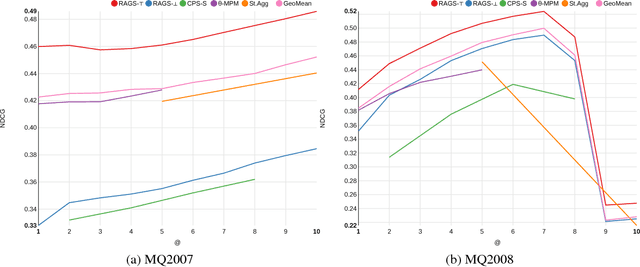
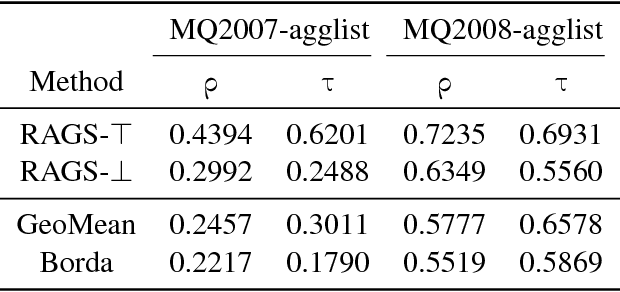
We study the problem of rank aggregation: given a set of ranked lists, we want to form a consensus ranking. Furthermore, we consider the case of extreme lists: i.e., only the rank of the best or worst elements are known. We impute missing ranks by the average value and generalise Spearman's \rho to extreme ranks. Our main contribution is the derivation of a non-parametric estimator for rank aggregation based on multivariate extensions of Spearman's \rho, which measures correlation between a set of ranked lists. Multivariate Spearman's \rho is defined using copulas, and we show that the geometric mean of normalised ranks maximises multivariate correlation. Motivated by this, we propose a weighted geometric mean approach for learning to rank which has a closed form least squares solution. When only the best or worst elements of a ranked list are known, we impute the missing ranks by the average value, allowing us to apply Spearman's \rho. Finally, we demonstrate good performance on the rank aggregation benchmarks MQ2007 and MQ2008.
Supervised Feature Selection via Dependence Estimation
Apr 20, 2007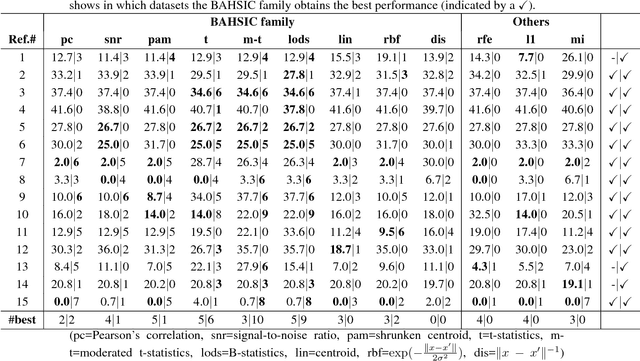
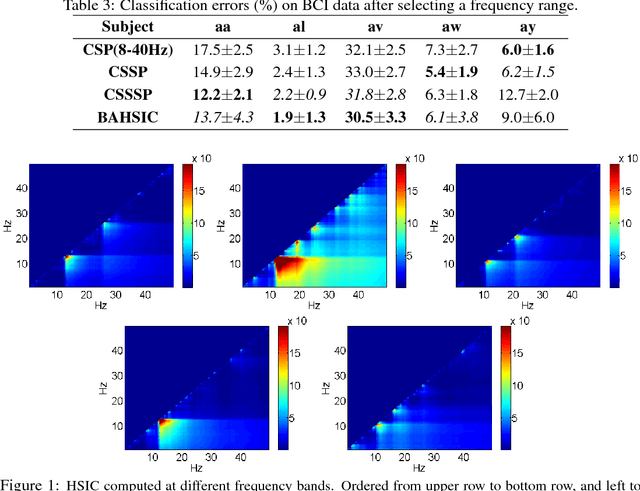


We introduce a framework for filtering features that employs the Hilbert-Schmidt Independence Criterion (HSIC) as a measure of dependence between the features and the labels. The key idea is that good features should maximise such dependence. Feature selection for various supervised learning problems (including classification and regression) is unified under this framework, and the solutions can be approximated using a backward-elimination algorithm. We demonstrate the usefulness of our method on both artificial and real world datasets.