 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Graph Completion Models are Few-shot Learners: An Empirical Study of Relation Labeling in E-commerce with LLMs
May 17, 2023Knowledge Graphs (KGs) play a crucial role in enhancing e-commerce system performance by providing structured information about entities and their relationships, such as complementary or substitutable relations between products or product types, which can be utilized in recommender systems. However, relation labeling in KGs remains a challenging task due to the dynamic nature of e-commerce domains and the associated cost of human labor. Recently, breakthroughs in Large Language Models (LLMs) have shown surprising results in numerous natural language processing tasks. In this paper, we conduct an empirical study of LLMs for relation labeling in e-commerce KGs, investigating their powerful learning capabilities in natural language and effectiveness in predicting relations between product types with limited labeled data. We evaluate various LLMs, including PaLM and GPT-3.5, on benchmark datasets, demonstrating their ability to achieve competitive performance compared to humans on relation labeling tasks using just 1 to 5 labeled examples per relation. Additionally, we experiment with different prompt engineering techniques to examine their impact on model performance. Our results show that LLMs significantly outperform existing KG completion models in relation labeling for e-commerce KGs and exhibit performance strong enough to replace human labeling.
Mitigating Frequency Bias in Next-Basket Recommendation via Deconfounders
Nov 16, 2022



Recent studies on Next-basket Recommendation (NBR) have achieved much progress by leveraging Personalized Item Frequency (PIF) as one of the main features, which measures the frequency of the user's interactions with the item. However, taking the PIF as an explicit feature incurs bias towards frequent items. Items that a user purchases frequently are assigned higher weights in the PIF-based recommender system and appear more frequently in the personalized recommendation list. As a result, the system will lose the fairness and balance between items that the user frequently purchases and items that the user never purchases. We refer to this systematic bias on personalized recommendation lists as frequency bias, which narrows users' browsing scope and reduces the system utility. We adopt causal inference theory to address this issue. Considering the influence of historical purchases on users' future interests, the user and item representations can be viewed as unobserved confounders in the causal diagram. In this paper, we propose a deconfounder model named FENDER (Frequency-aware Deconfounder for Next-basket Recommendation) to mitigate the frequency bias. With the deconfounder theory and the causal diagram we propose, FENDER decomposes PIF with a neural tensor layer to obtain substitute confounders for users and items. Then, FENDER performs unbiased recommendations considering the effect of these substitute confounders. Experimental results demonstrate that FENDER has derived diverse and fair results compared to ten baseline models on three datasets while achieving competitive performance. Further experiments illustrate how FENDER balances users' historical purchases and potential interests.
Causal Structure Learning with Recommendation System
Oct 19, 2022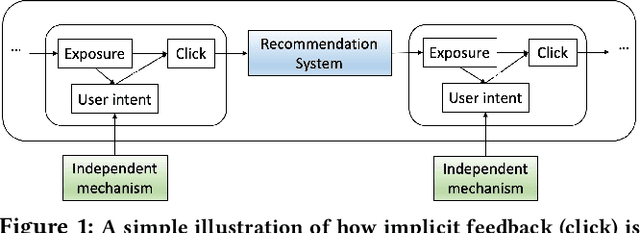
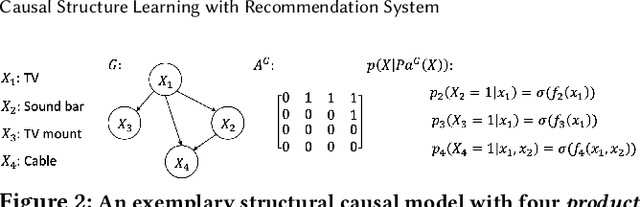
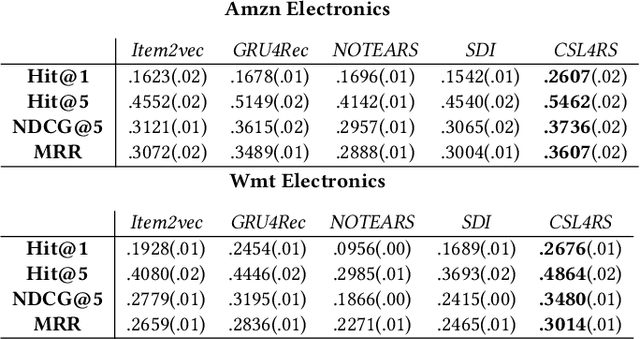
A fundamental challenge of recommendation systems (RS) is understanding the causal dynamics underlying users' decision making. Most existing literature addresses this problem by using causal structures inferred from domain knowledge. However, there are numerous phenomenons where domain knowledge is insufficient, and the causal mechanisms must be learnt from the feedback data. Discovering the causal mechanism from RS feedback data is both novel and challenging, since RS itself is a source of intervention that can influence both the users' exposure and their willingness to interact. Also for this reason, most existing solutions become inappropriate since they require data collected free from any RS. In this paper, we first formulate the underlying causal mechanism as a causal structural model and describe a general causal structure learning framework grounded in the real-world working mechanism of RS. The essence of our approach is to acknowledge the unknown nature of RS intervention. We then derive the learning objective from our framework and propose an augmented Lagrangian solver for efficient optimization. We conduct both simulation and real-world experiments to demonstrate how our approach compares favorably to existing solutions, together with the empirical analysis from sensitivity and ablation studies.
NEAT: A Label Noise-resistant Complementary Item Recommender System with Trustworthy Evaluation
Feb 11, 2022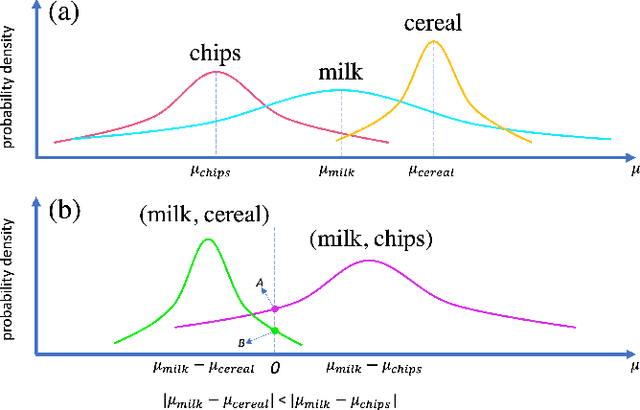
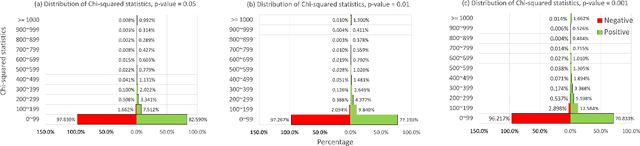
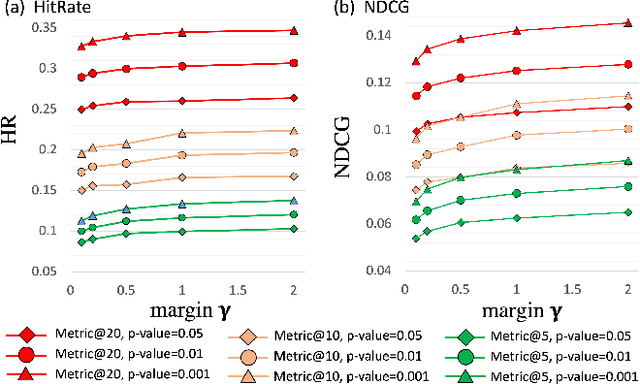
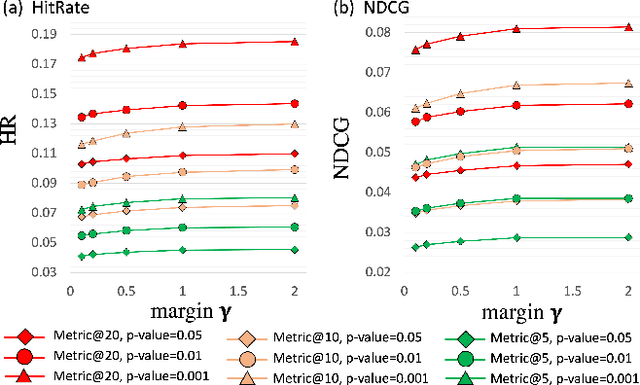
The complementary item recommender system (CIRS) recommends the complementary items for a given query item. Existing CIRS models consider the item co-purchase signal as a proxy of the complementary relationship due to the lack of human-curated labels from the huge transaction records. These methods represent items in a complementary embedding space and model the complementary relationship as a point estimation of the similarity between items vectors. However, co-purchased items are not necessarily complementary to each other. For example, customers may frequently purchase bananas and bottled water within the same transaction, but these two items are not complementary. Hence, using co-purchase signals directly as labels will aggravate the model performance. On the other hand, the model evaluation will not be trustworthy if the labels for evaluation are not reflecting the true complementary relatedness. To address the above challenges from noisy labeling of the copurchase data, we model the co-purchases of two items as a Gaussian distribution, where the mean denotes the co-purchases from the complementary relatedness, and covariance denotes the co-purchases from the noise. To do so, we represent each item as a Gaussian embedding and parameterize the Gaussian distribution of co-purchases by the means and covariances from item Gaussian embedding. To reduce the impact of the noisy labels during evaluation, we propose an independence test-based method to generate a trustworthy label set with certain confidence. Our extensive experiments on both the publicly available dataset and the large-scale real-world dataset justify the effectiveness of our proposed model in complementary item recommendations compared with the state-of-the-art models.
Generating Rich Product Descriptions for Conversational E-commerce Systems
Nov 30, 2021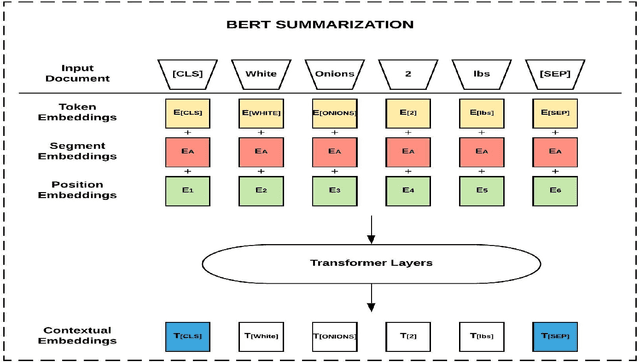

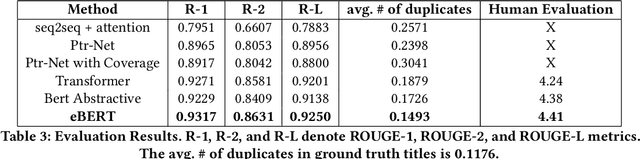
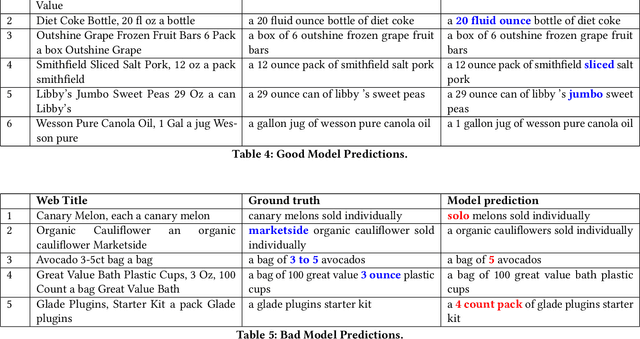
Through recent advancements in speech technologies and introduction of smart assistants, such as Amazon Alexa, Apple Siri and Google Home, increasing number of users are interacting with various applications through voice commands. E-commerce companies typically display short product titles on their webpages, either human-curated or algorithmically generated, when brevity is required. However, these titles are dissimilar from natural spoken language. For example, "Lucky Charms Gluten Free Break-fast Cereal, 20.5 oz a box Lucky Charms Gluten Free" is acceptable to display on a webpage, while a similar title cannot be used in a voice based text-to-speech application. In such conversational systems, an easy to comprehend sentence, such as "a 20.5 ounce box of lucky charms gluten free cereal" is preferred. Compared to display devices, where images and detailed product information can be presented to users, short titles for products which convey the most important information, are necessary when interfacing with voice assistants. We propose eBERT, a sequence-to-sequence approach by further pre-training the BERT embeddings on an e-commerce product description corpus, and then fine-tuning the resulting model to generate short, natural, spoken language titles from input web titles. Our extensive experiments on a real-world industry dataset, as well as human evaluation of model output, demonstrate that eBERT summarization outperforms comparable baseline models. Owing to the efficacy of the model, a version of this model has been deployed in real-world setting.
* 8 pages, 1 figure. arXiv admin note: substantial text overlap with arXiv:2007.11768
Pre-training Recommender Systems via Reinforced Attentive Multi-relational Graph Neural Network
Nov 28, 2021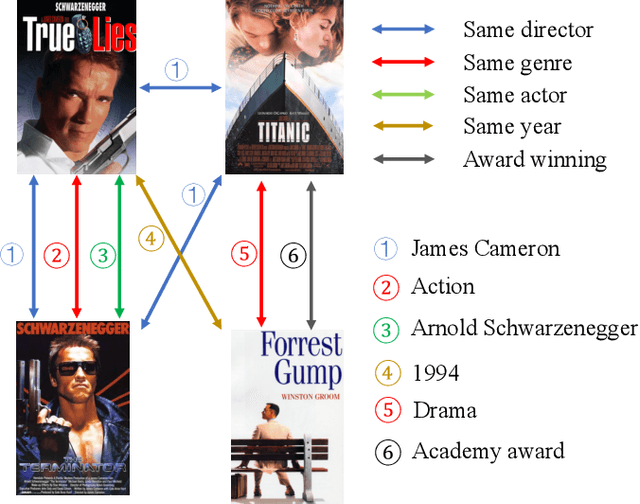
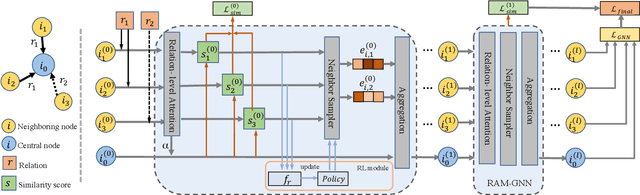
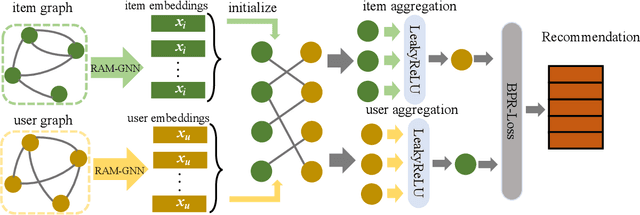
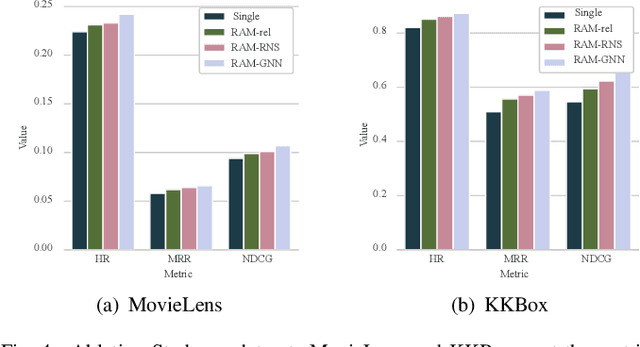
Recently, Graph Neural Networks (GNNs) have proven their effectiveness for recommender systems. Existing studies have applied GNNs to capture collaborative relations in the data. However, in real-world scenarios, the relations in a recommendation graph can be of various kinds. For example, two movies may be associated either by the same genre or by the same director/actor. If we use a single graph to elaborate all these relations, the graph can be too complex to process. To address this issue, we bring the idea of pre-training to process the complex graph step by step. Based on the idea of divide-and-conquer, we separate the large graph into three sub-graphs: user graph, item graph, and user-item interaction graph. Then the user and item embeddings are pre-trained from user and item graphs, respectively. To conduct pre-training, we construct the multi-relational user graph and item graph, respectively, based on their attributes. In this paper, we propose a novel Reinforced Attentive Multi-relational Graph Neural Network (RAM-GNN) to the pre-train user and item embeddings on the user and item graph prior to the recommendation step. Specifically, we design a relation-level attention layer to learn the importance of different relations. Next, a Reinforced Neighbor Sampler (RNS) is applied to search the optimal filtering threshold for sampling top-k similar neighbors in the graph, which avoids the over-smoothing issue. We initialize the recommendation model with the pre-trained user/item embeddings. Finally, an aggregation-based GNN model is utilized to learn from the collaborative relations in the user-item interaction graph and provide recommendations. Our experiments demonstrate that RAM-GNN outperforms other state-of-the-art graph-based recommendation models and multi-relational graph neural networks.
Rethinking Neural vs. Matrix-Factorization Collaborative Filtering: the Theoretical Perspectives
Oct 23, 2021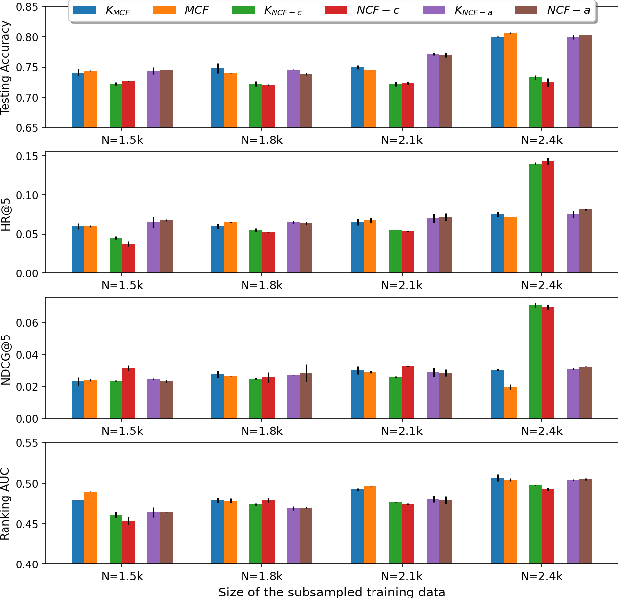
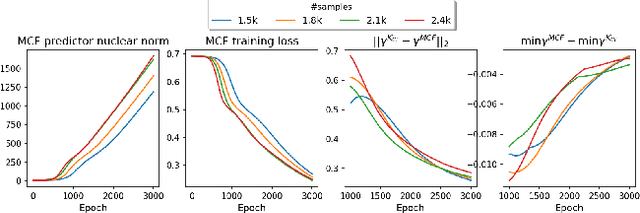
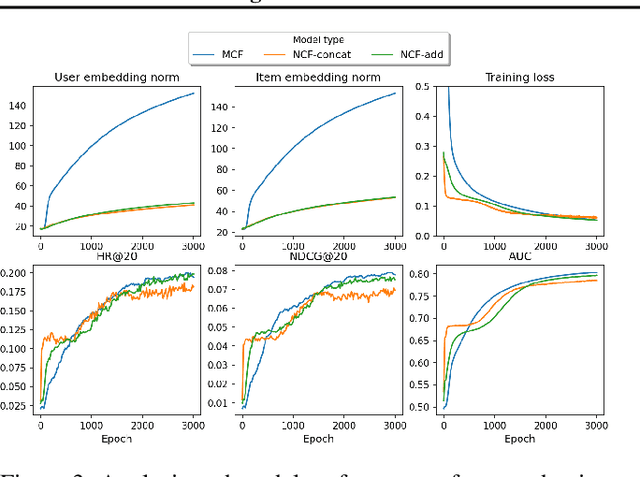
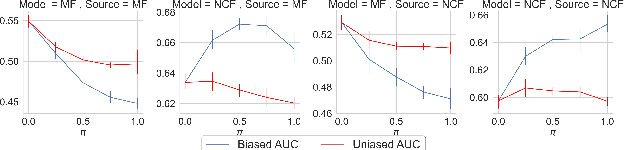
The recent work by Rendle et al. (2020), based on empirical observations, argues that matrix-factorization collaborative filtering (MCF) compares favorably to neural collaborative filtering (NCF), and conjectures the dot product's superiority over the feed-forward neural network as similarity function. In this paper, we address the comparison rigorously by answering the following questions: 1. what is the limiting expressivity of each model; 2. under the practical gradient descent, to which solution does each optimization path converge; 3. how would the models generalize under the inductive and transductive learning setting. Our results highlight the similar expressivity for the overparameterized NCF and MCF as kernelized predictors, and reveal the relation between their optimization paths. We further show their different generalization behaviors, where MCF and NCF experience specific tradeoff and comparison in the transductive and inductive collaborative filtering setting. Lastly, by showing a novel generalization result, we reveal the critical role of correcting exposure bias for model evaluation in the inductive setting. Our results explain some of the previously observed conflicts, and we provide synthetic and real-data experiments to shed further insights to this topic.
Towards the D-Optimal Online Experiment Design for Recommender Selection
Oct 23, 2021
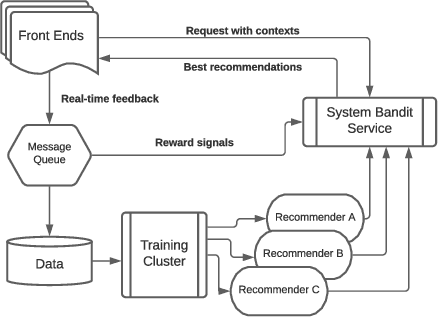
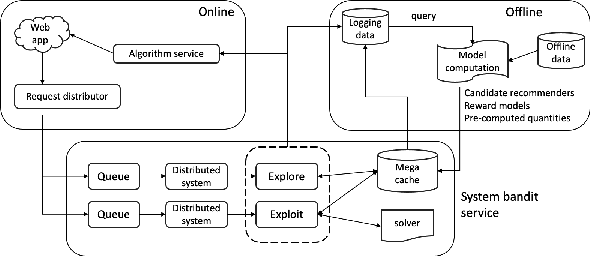
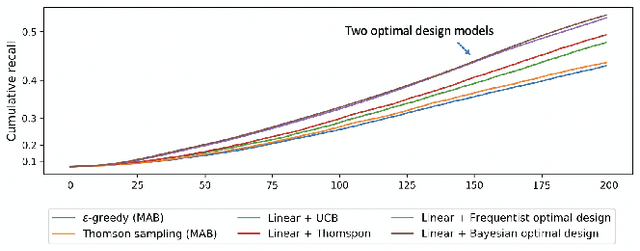
Selecting the optimal recommender via online exploration-exploitation is catching increasing attention where the traditional A/B testing can be slow and costly, and offline evaluations are prone to the bias of history data. Finding the optimal online experiment is nontrivial since both the users and displayed recommendations carry contextual features that are informative to the reward. While the problem can be formalized via the lens of multi-armed bandits, the existing solutions are found less satisfactorily because the general methodologies do not account for the case-specific structures, particularly for the e-commerce recommendation we study. To fill in the gap, we leverage the \emph{D-optimal design} from the classical statistics literature to achieve the maximum information gain during exploration, and reveal how it fits seamlessly with the modern infrastructure of online inference. To demonstrate the effectiveness of the optimal designs, we provide semi-synthetic simulation studies with published code and data for reproducibility purposes. We then use our deployment example on Walmart.com to fully illustrate the practical insights and effectiveness of the proposed methods.
Variational Inference for Category Recommendation in E-Commerce platforms
Apr 19, 2021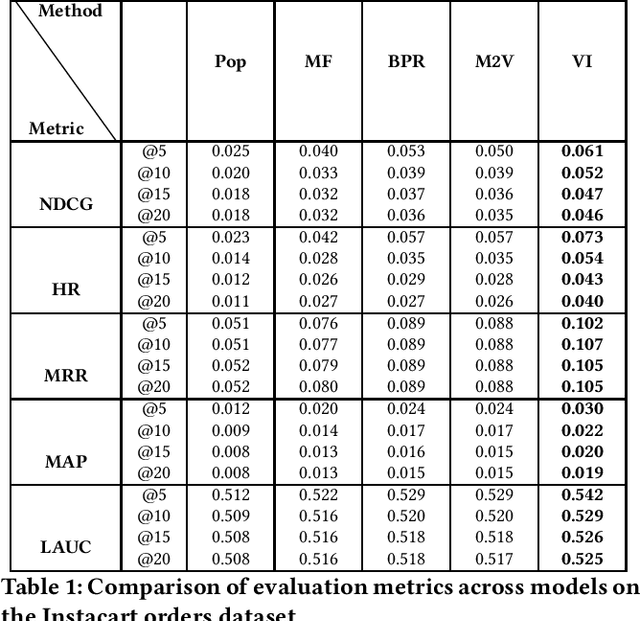
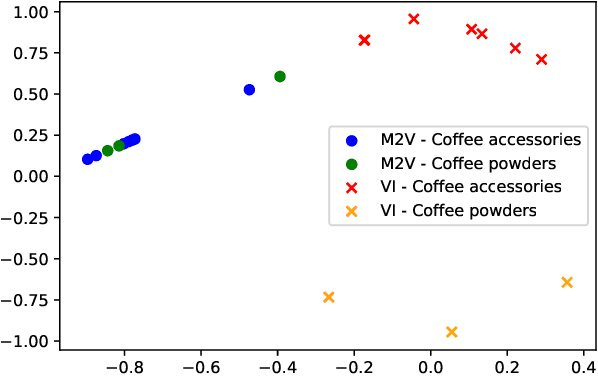
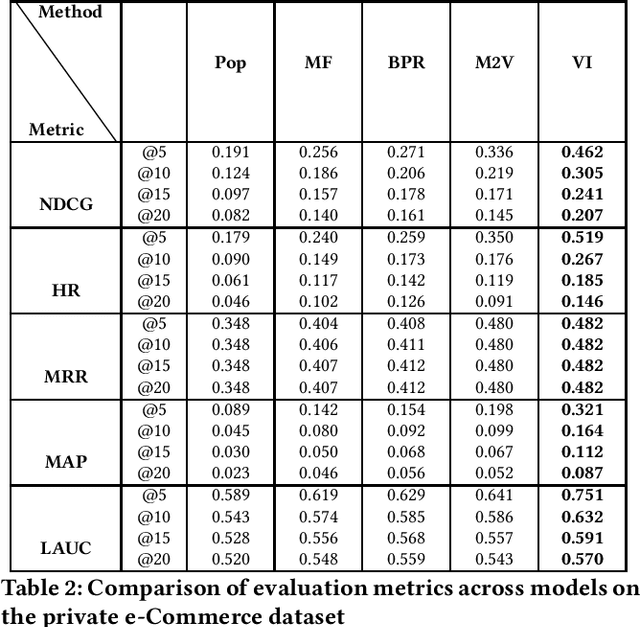
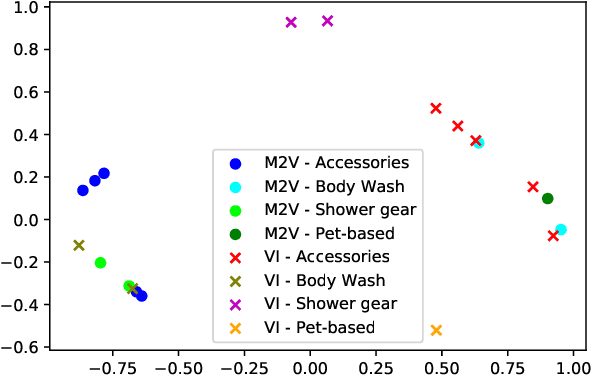
Category recommendation for users on an e-Commerce platform is an important task as it dictates the flow of traffic through the website. It is therefore important to surface precise and diverse category recommendations to aid the users' journey through the platform and to help them discover new groups of items. An often understated part in category recommendation is users' proclivity to repeat purchases. The structure of this temporal behavior can be harvested for better category recommendations and in this work, we attempt to harness this through variational inference. Further, to enhance the variational inference based optimization, we initialize the optimizer at better starting points through the well known Metapath2Vec algorithm. We demonstrate our results on two real-world datasets and show that our model outperforms standard baseline methods.
A Temporal Kernel Approach for Deep Learning with Continuous-time Information
Mar 28, 2021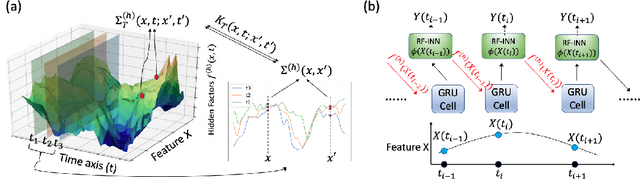
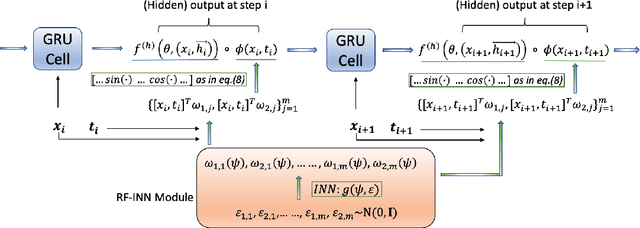
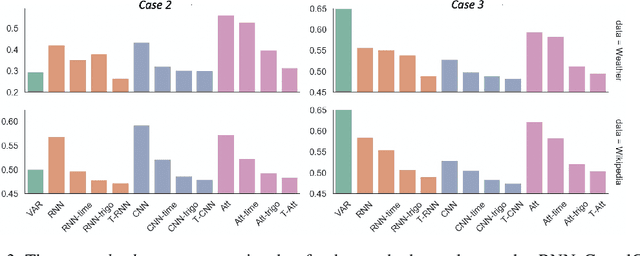
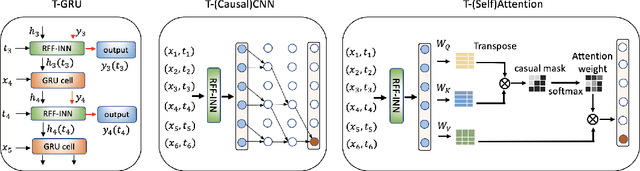
Sequential deep learning models such as RNN, causal CNN and attention mechanism do not readily consume continuous-time information. Discretizing the temporal data, as we show, causes inconsistency even for simple continuous-time processes. Current approaches often handle time in a heuristic manner to be consistent with the existing deep learning architectures and implementations. In this paper, we provide a principled way to characterize continuous-time systems using deep learning tools. Notably, the proposed approach applies to all the major deep learning architectures and requires little modifications to the implementation. The critical insight is to represent the continuous-time system by composing neural networks with a temporal kernel, where we gain our intuition from the recent advancements in understanding deep learning with Gaussian process and neural tangent kernel. To represent the temporal kernel, we introduce the random feature approach and convert the kernel learning problem to spectral density estimation under reparameterization. We further prove the convergence and consistency results even when the temporal kernel is non-stationary, and the spectral density is misspecified. The simulations and real-data experiments demonstrate the empirical effectiveness of our temporal kernel approach in a broad range of settings.