 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Long Videos in One Multimodal Language Model Pass
Mar 25, 2024



Large Language Models (LLMs), known to contain a strong awareness of world knowledge, have allowed recent approaches to achieve excellent performance on Long-Video Understanding benchmarks, but at high inference costs. In this work, we first propose Likelihood Selection, a simple technique that unlocks faster inference in autoregressive LLMs for multiple-choice tasks common in long-video benchmarks. In addition to faster inference, we discover the resulting models to yield surprisingly good accuracy on long-video tasks, even with no video specific information. Building on this, we inject video-specific object-centric information extracted from off-the-shelf pre-trained models and utilize natural language as a medium for information fusion. Our resulting Multimodal Video Understanding (MVU) framework demonstrates state-of-the-art performance across long-video and fine-grained action recognition benchmarks. Code available at: https://github.com/kahnchana/mvu
Hierarchical Text-to-Vision Self Supervised Alignment for Improved Histopathology Representation Learning
Mar 21, 2024



Self-supervised representation learning has been highly promising for histopathology image analysis with numerous approaches leveraging their patient-slide-patch hierarchy to learn better representations. In this paper, we explore how the combination of domain specific natural language information with such hierarchical visual representations can benefit rich representation learning for medical image tasks. Building on automated language description generation for features visible in histopathology images, we present a novel language-tied self-supervised learning framework, Hierarchical Language-tied Self-Supervision (HLSS) for histopathology images. We explore contrastive objectives and granular language description based text alignment at multiple hierarchies to inject language modality information into the visual representations. Our resulting model achieves state-of-the-art performance on two medical imaging benchmarks, OpenSRH and TCGA datasets. Our framework also provides better interpretability with our language aligned representation space. Code is available at https://github.com/Hasindri/HLSS.
Language Repository for Long Video Understanding
Mar 21, 2024



Language has become a prominent modality in computer vision with the rise of multi-modal LLMs. Despite supporting long context-lengths, their effectiveness in handling long-term information gradually declines with input length. This becomes critical, especially in applications such as long-form video understanding. In this paper, we introduce a Language Repository (LangRepo) for LLMs, that maintains concise and structured information as an interpretable (i.e., all-textual) representation. Our repository is updated iteratively based on multi-scale video chunks. We introduce write and read operations that focus on pruning redundancies in text, and extracting information at various temporal scales. The proposed framework is evaluated on zero-shot visual question-answering benchmarks including EgoSchema, NExT-QA, IntentQA and NExT-GQA, showing state-of-the-art performance at its scale. Our code is available at https://github.com/kkahatapitiya/LangRepo.
Diffusion Illusions: Hiding Images in Plain Sight
Dec 06, 2023



We explore the problem of computationally generating special `prime' images that produce optical illusions when physically arranged and viewed in a certain way. First, we propose a formal definition for this problem. Next, we introduce Diffusion Illusions, the first comprehensive pipeline designed to automatically generate a wide range of these illusions. Specifically, we both adapt the existing `score distillation loss' and propose a new `dream target loss' to optimize a group of differentially parametrized prime images, using a frozen text-to-image diffusion model. We study three types of illusions, each where the prime images are arranged in different ways and optimized using the aforementioned losses such that images derived from them align with user-chosen text prompts or images. We conduct comprehensive experiments on these illusions and verify the effectiveness of our proposed method qualitatively and quantitatively. Additionally, we showcase the successful physical fabrication of our illusions -- as they are all designed to work in the real world. Our code and examples are publicly available at our interactive project website: https://diffusionillusions.com
Language-based Action Concept Spaces Improve Video Self-Supervised Learning
Jul 20, 2023Recent contrastive language image pre-training has led to learning highly transferable and robust image representations. However, adapting these models to video domains with minimal supervision remains an open problem. We explore a simple step in that direction, using language tied self-supervised learning to adapt an image CLIP model to the video domain. A backbone modified for temporal modeling is trained under self-distillation settings with train objectives operating in an action concept space. Feature vectors of various action concepts extracted from a language encoder using relevant textual prompts construct this space. We introduce two train objectives, concept distillation and concept alignment, that retain generality of original representations while enforcing relations between actions and their attributes. Our approach improves zero-shot and linear probing performance on three action recognition benchmarks.
Peekaboo: Text to Image Diffusion Models are Zero-Shot Segmentors
Nov 23, 2022



Recent diffusion-based generative models combined with vision-language models are capable of creating realistic images from natural language prompts. While these models are trained on large internet-scale datasets, such pre-trained models are not directly introduced to any semantic localization or grounding. Most current approaches for localization or grounding rely on human-annotated localization information in the form of bounding boxes or segmentation masks. The exceptions are a few unsupervised methods that utilize architectures or loss functions geared towards localization, but they need to be trained separately. In this work, we explore how off-the-shelf diffusion models, trained with no exposure to such localization information, are capable of grounding various semantic phrases with no segmentation-specific re-training. An inference time optimization process is introduced, that is capable of generating segmentation masks conditioned on natural language. We evaluate our proposal Peekaboo for unsupervised semantic segmentation on the Pascal VOC dataset. In addition, we evaluate for referring segmentation on the RefCOCO dataset. In summary, we present a first zero-shot, open-vocabulary, unsupervised (no localization information), semantic grounding technique leveraging diffusion-based generative models with no re-training. Our code will be released publicly.
Perceptual Grouping in Vision-Language Models
Oct 18, 2022
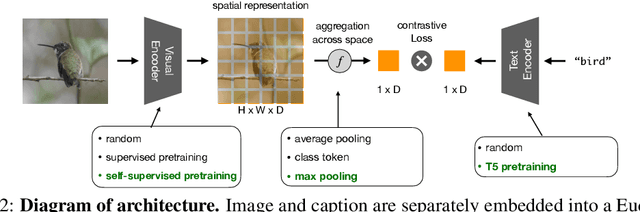
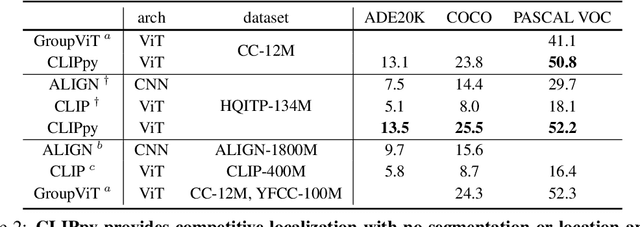
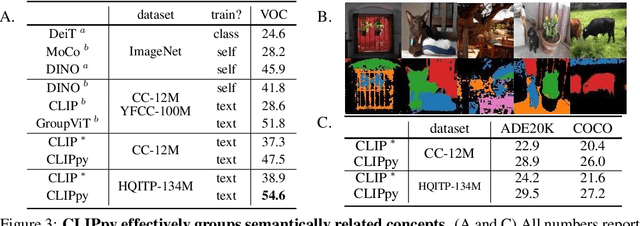
Recent advances in zero-shot image recognition suggest that vision-language models learn generic visual representations with a high degree of semantic information that may be arbitrarily probed with natural language phrases. Understanding an image, however, is not just about understanding what content resides within an image, but importantly, where that content resides. In this work we examine how well vision-language models are able to understand where objects reside within an image and group together visually related parts of the imagery. We demonstrate how contemporary vision and language representation learning models based on contrastive losses and large web-based data capture limited object localization information. We propose a minimal set of modifications that results in models that uniquely learn both semantic and spatial information. We measure this performance in terms of zero-shot image recognition, unsupervised bottom-up and top-down semantic segmentations, as well as robustness analyses. We find that the resulting model achieves state-of-the-art results in terms of unsupervised segmentation, and demonstrate that the learned representations are uniquely robust to spurious correlations in datasets designed to probe the causal behavior of vision models.
Self-supervised Video Transformer
Dec 02, 2021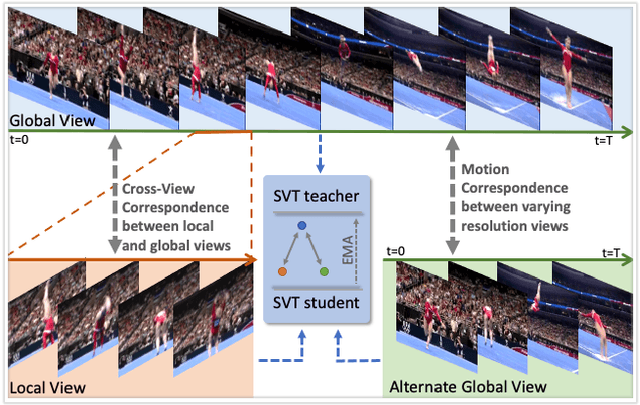
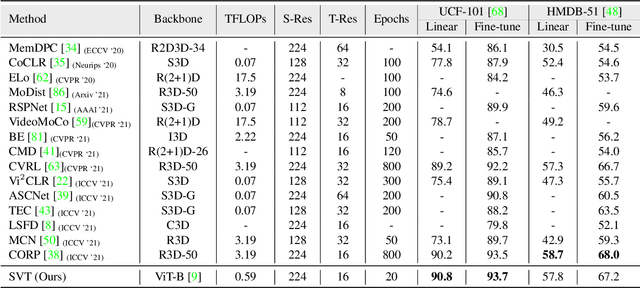
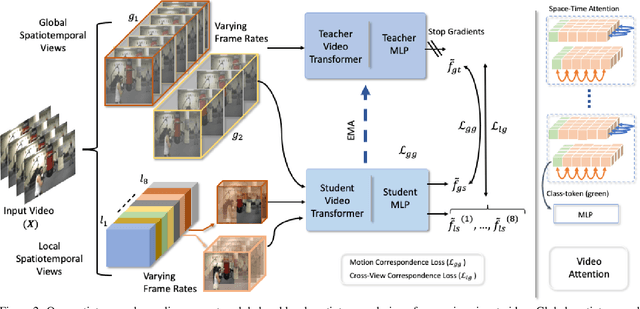
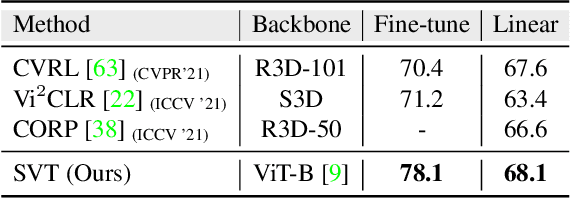
In this paper, we propose self-supervised training for video transformers using unlabelled video data. From a given video, we create local and global spatiotemporal views with varying spatial sizes and frame rates. Our self-supervised objective seeks to match the features of these different views representing the same video, to be invariant to spatiotemporal variations in actions. To the best of our knowledge, the proposed approach is the first to alleviate the dependency on negative samples or dedicated memory banks in Self-supervised Video Transformer (SVT). Further, owing to the flexibility of Transformer models, SVT supports slow-fast video processing within a single architecture using dynamically adjusted positional encodings and supports long-term relationship modeling along spatiotemporal dimensions. Our approach performs well on four action recognition benchmarks (Kinetics-400, UCF-101, HMDB-51, and SSv2) and converges faster with small batch sizes. Code: https://git.io/J1juJ
Intriguing Properties of Vision Transformers
Jun 08, 2021



Vision transformers (ViT) have demonstrated impressive performance across various machine vision problems. These models are based on multi-head self-attention mechanisms that can flexibly attend to a sequence of image patches to encode contextual cues. An important question is how such flexibility in attending image-wide context conditioned on a given patch can facilitate handling nuisances in natural images e.g., severe occlusions, domain shifts, spatial permutations, adversarial and natural perturbations. We systematically study this question via an extensive set of experiments encompassing three ViT families and comparisons with a high-performing convolutional neural network (CNN). We show and analyze the following intriguing properties of ViT: (a) Transformers are highly robust to severe occlusions, perturbations and domain shifts, e.g., retain as high as 60% top-1 accuracy on ImageNet even after randomly occluding 80% of the image content. (b) The robust performance to occlusions is not due to a bias towards local textures, and ViTs are significantly less biased towards textures compared to CNNs. When properly trained to encode shape-based features, ViTs demonstrate shape recognition capability comparable to that of human visual system, previously unmatched in the literature. (c) Using ViTs to encode shape representation leads to an interesting consequence of accurate semantic segmentation without pixel-level supervision. (d) Off-the-shelf features from a single ViT model can be combined to create a feature ensemble, leading to high accuracy rates across a range of classification datasets in both traditional and few-shot learning paradigms. We show effective features of ViTs are due to flexible and dynamic receptive fields possible via the self-attention mechanism.
On Improving Adversarial Transferability of Vision Transformers
Jun 08, 2021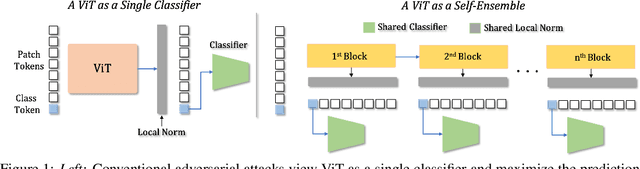
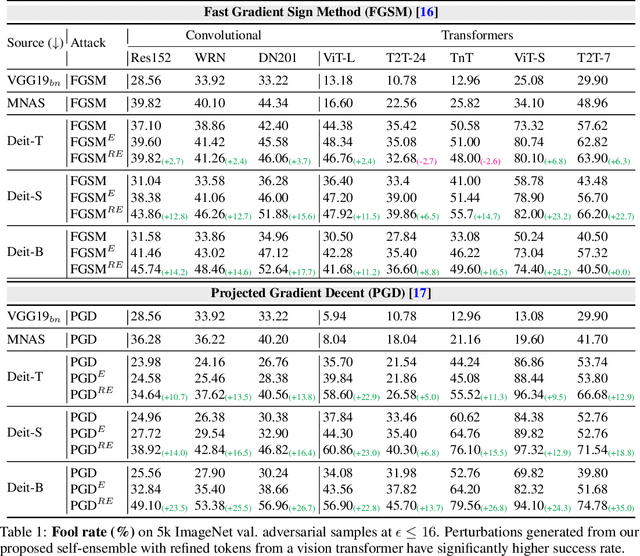
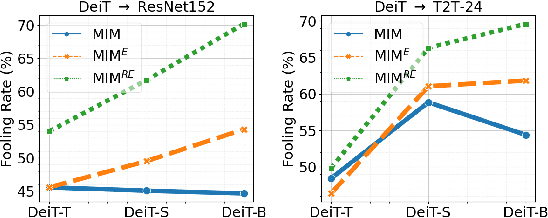
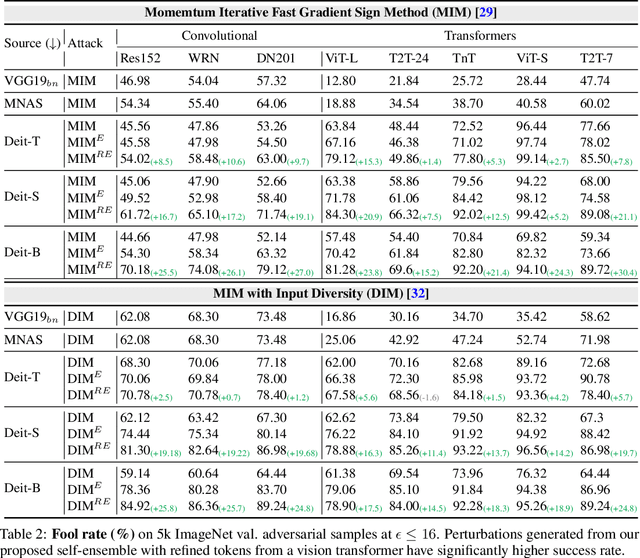
Vision transformers (ViTs) process input images as sequences of patches via self-attention; a radically different architecture than convolutional neural networks (CNNs). This makes it interesting to study the adversarial feature space of ViT models and their transferability. In particular, we observe that adversarial patterns found via conventional adversarial attacks show very low black-box transferability even for large ViT models. However, we show that this phenomenon is only due to the sub-optimal attack procedures that do not leverage the true representation potential of ViTs. A deep ViT is composed of multiple blocks, with a consistent architecture comprising of self-attention and feed-forward layers, where each block is capable of independently producing a class token. Formulating an attack using only the last class token (conventional approach) does not directly leverage the discriminative information stored in the earlier tokens, leading to poor adversarial transferability of ViTs. Using the compositional nature of ViT models, we enhance the transferability of existing attacks by introducing two novel strategies specific to the architecture of ViT models. (i) Self-Ensemble: We propose a method to find multiple discriminative pathways by dissecting a single ViT model into an ensemble of networks. This allows explicitly utilizing class-specific information at each ViT block. (ii) Token Refinement: We then propose to refine the tokens to further enhance the discriminative capacity at each block of ViT. Our token refinement systematically combines the class tokens with structural information preserved within the patch tokens. An adversarial attack, when applied to such refined tokens within the ensemble of classifiers found in a single vision transformer, has significantly higher transferability.