 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistractor-Aware Neuron Intrinsic Learning for Generic 2D Medical Image Classifications
Jul 21, 2020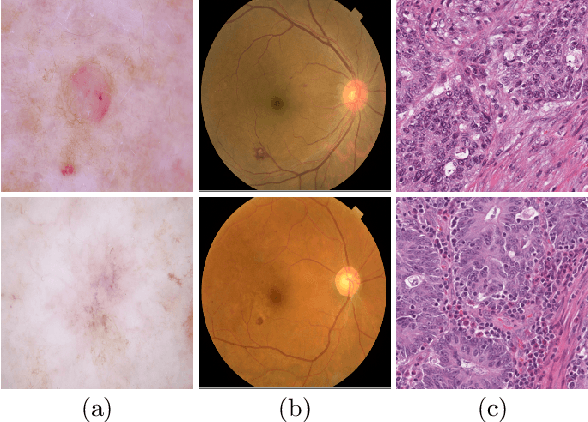
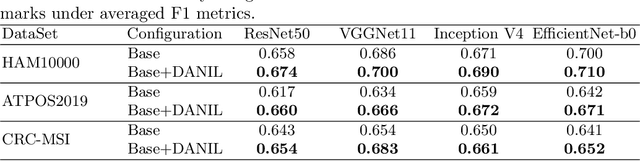
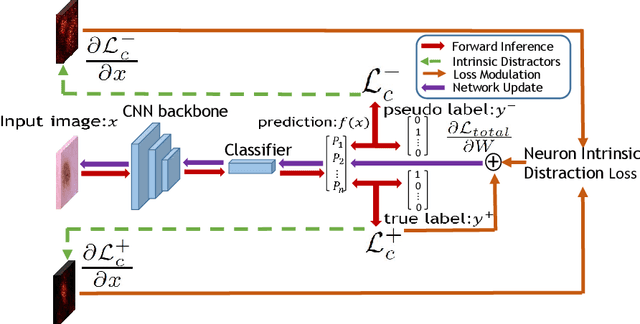
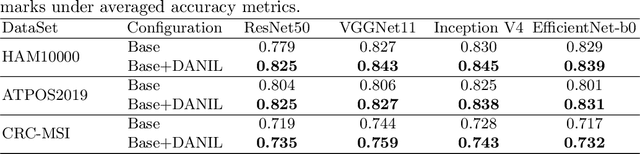
Medical image analysis benefits Computer Aided Diagnosis (CADx). A fundamental analyzing approach is the classification of medical images, which serves for skin lesion diagnosis, diabetic retinopathy grading, and cancer classification on histological images. When learning these discriminative classifiers, we observe that the convolutional neural networks (CNNs) are vulnerable to distractor interference. This is due to the similar sample appearances from different categories (i.e., small inter-class distance). Existing attempts select distractors from input images by empirically estimating their potential effects to the classifier. The essences of how these distractors affect CNN classification are not known. In this paper, we explore distractors from the CNN feature space via proposing a neuron intrinsic learning method. We formulate a novel distractor-aware loss that encourages large distance between the original image and its distractor in the feature space. The novel loss is combined with the original classification loss to update network parameters by back-propagation. Neuron intrinsic learning first explores distractors crucial to the deep classifier and then uses them to robustify CNN inherently. Extensive experiments on medical image benchmark datasets indicate that the proposed method performs favorably against the state-of-the-art approaches.
A Macro-Micro Weakly-supervised Framework for AS-OCT Tissue Segmentation
Jul 20, 2020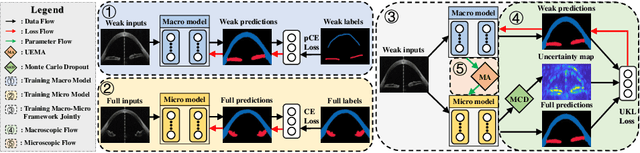
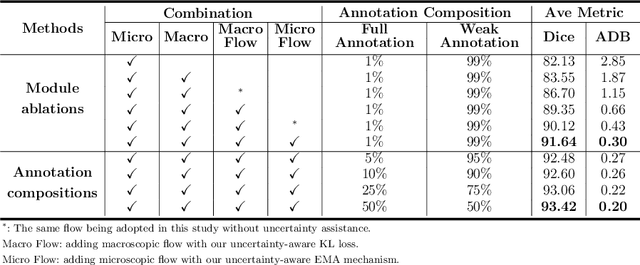
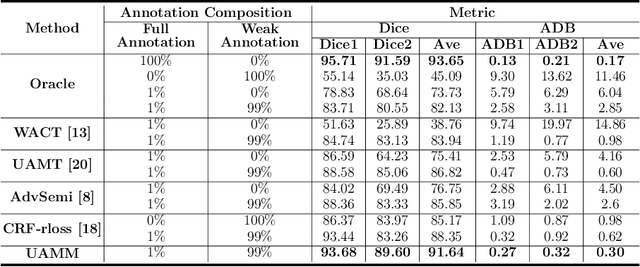
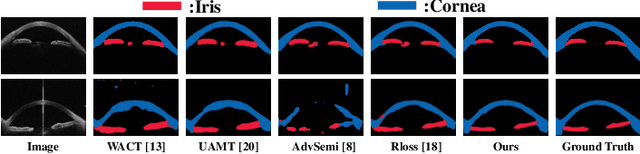
Primary angle closure glaucoma (PACG) is the leading cause of irreversible blindness among Asian people. Early detection of PACG is essential, so as to provide timely treatment and minimize the vision loss. In the clinical practice, PACG is diagnosed by analyzing the angle between the cornea and iris with anterior segment optical coherence tomography (AS-OCT). The rapid development of deep learning technologies provides the feasibility of building a computer-aided system for the fast and accurate segmentation of cornea and iris tissues. However, the application of deep learning methods in the medical imaging field is still restricted by the lack of enough fully-annotated samples. In this paper, we propose a novel framework to segment the target tissues accurately for the AS-OCT images, by using the combination of weakly-annotated images (majority) and fully-annotated images (minority). The proposed framework consists of two models which provide reliable guidance for each other. In addition, uncertainty guided strategies are adopted to increase the accuracy and stability of the guidance. Detailed experiments on the publicly available AGE dataset demonstrate that the proposed framework outperforms the state-of-the-art semi-/weakly-supervised methods and has a comparable performance as the fully-supervised method. Therefore, the proposed method is demonstrated to be effective in exploiting information contained in the weakly-annotated images and has the capability to substantively relieve the annotation workload.
Deep Image Clustering with Category-Style Representation
Jul 20, 2020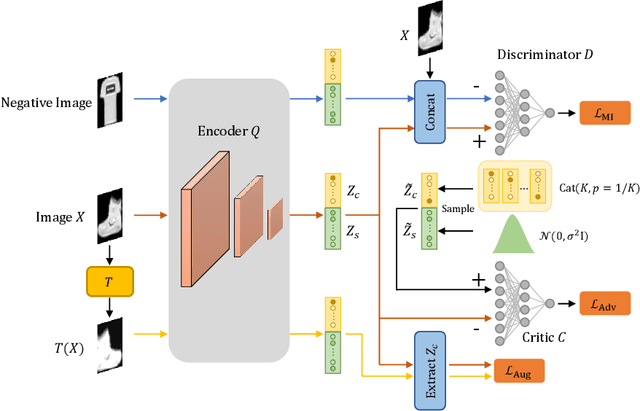

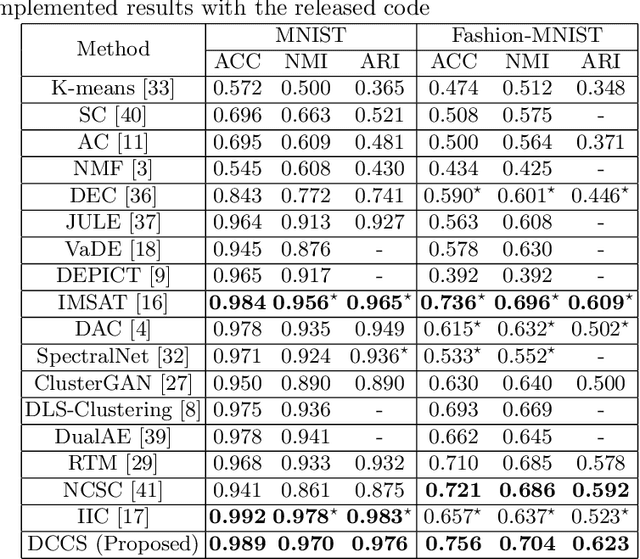
Deep clustering which adopts deep neural networks to obtain optimal representations for clustering has been widely studied recently. In this paper, we propose a novel deep image clustering framework to learn a category-style latent representation in which the category information is disentangled from image style and can be directly used as the cluster assignment. To achieve this goal, mutual information maximization is applied to embed relevant information in the latent representation. Moreover, augmentation-invariant loss is employed to disentangle the representation into category part and style part. Last but not least, a prior distribution is imposed on the latent representation to ensure the elements of the category vector can be used as the probabilities over clusters. Comprehensive experiments demonstrate that the proposed approach outperforms state-of-the-art methods significantly on five public datasets.
Self-Loop Uncertainty: A Novel Pseudo-Label for Semi-Supervised Medical Image Segmentation
Jul 20, 2020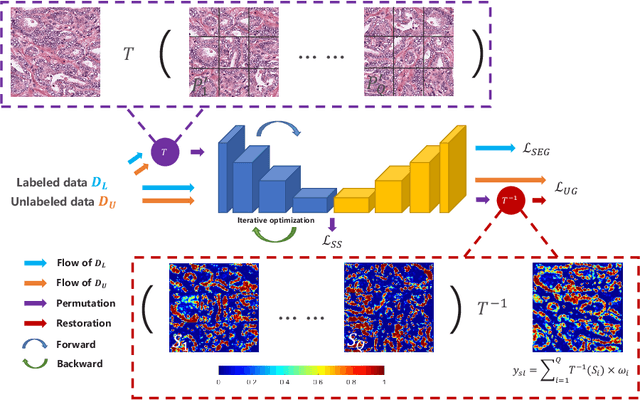

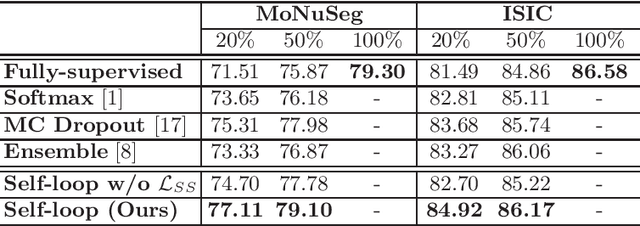
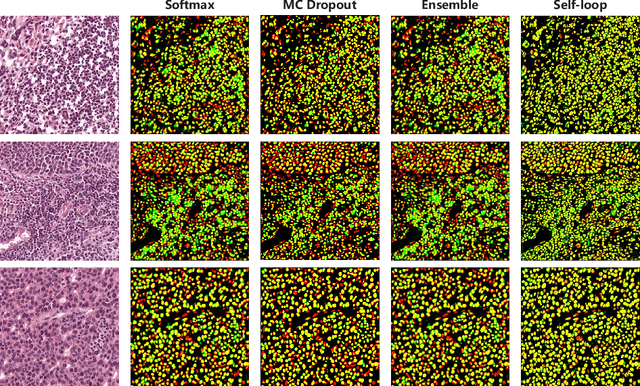
Witnessing the success of deep learning neural networks in natural image processing, an increasing number of studies have been proposed to develop deep-learning-based frameworks for medical image segmentation. However, since the pixel-wise annotation of medical images is laborious and expensive, the amount of annotated data is usually deficient to well-train a neural network. In this paper, we propose a semi-supervised approach to train neural networks with limited labeled data and a large quantity of unlabeled images for medical image segmentation. A novel pseudo-label (namely self-loop uncertainty), generated by recurrently optimizing the neural network with a self-supervised task, is adopted as the ground-truth for the unlabeled images to augment the training set and boost the segmentation accuracy. The proposed self-loop uncertainty can be seen as an approximation of the uncertainty estimation yielded by ensembling multiple models with a significant reduction of inference time. Experimental results on two publicly available datasets demonstrate the effectiveness of our semi-supervied approach.
Multi-Task Neural Networks with Spatial Activation for Retinal Vessel Segmentation and Artery/Vein Classification
Jul 18, 2020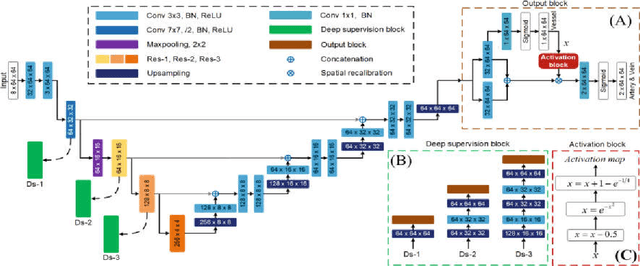
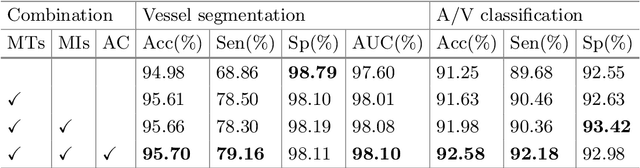
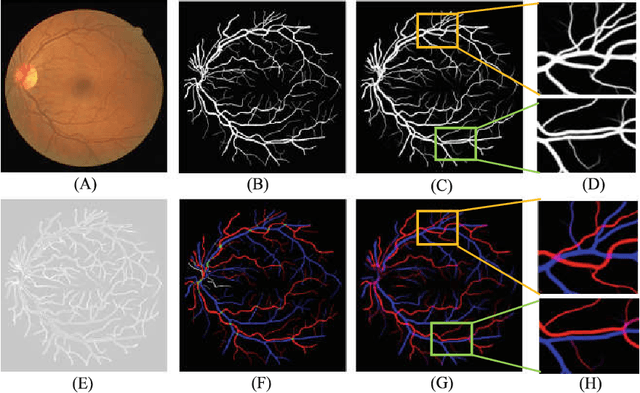
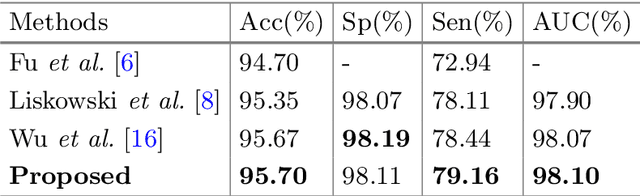
Retinal artery/vein (A/V) classification plays a critical role in the clinical biomarker study of how various systemic and cardiovascular diseases affect the retinal vessels. Conventional methods of automated A/V classification are generally complicated and heavily depend on the accurate vessel segmentation. In this paper, we propose a multi-task deep neural network with spatial activation mechanism that is able to segment full retinal vessel, artery and vein simultaneously, without the pre-requirement of vessel segmentation. The input module of the network integrates the domain knowledge of widely used retinal preprocessing and vessel enhancement techniques. We specially customize the output block of the network with a spatial activation mechanism, which takes advantage of a relatively easier task of vessel segmentation and exploits it to boost the performance of A/V classification. In addition, deep supervision is introduced to the network to assist the low level layers to extract more semantic information. The proposed network achieves pixel-wise accuracy of 95.70% for vessel segmentation, and A/V classification accuracy of 94.50%, which is the state-of-the-art performance for both tasks on the AV-DRIVE dataset. Furthermore, we have also tested the model performance on INSPIRE-AVR dataset, which achieves a skeletal A/V classification accuracy of 91.6%.
Superpixel-Guided Label Softening for Medical Image Segmentation
Jul 17, 2020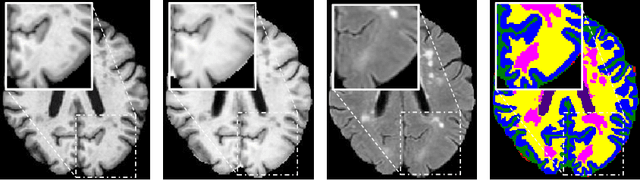
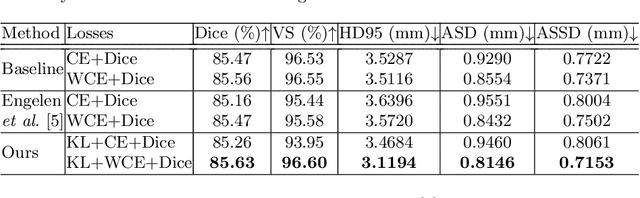
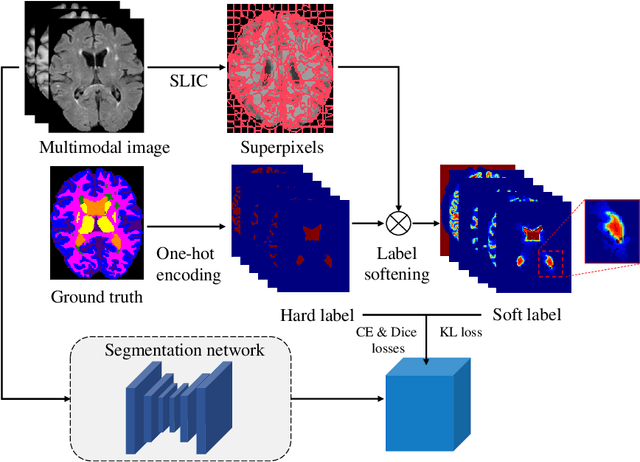
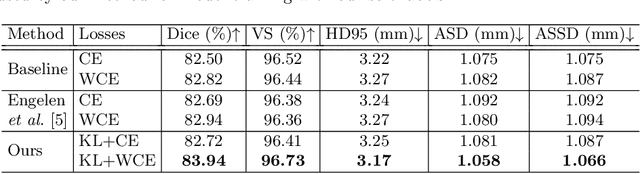
Segmentation of objects of interest is one of the central tasks in medical image analysis, which is indispensable for quantitative analysis. When developing machine-learning based methods for automated segmentation, manual annotations are usually used as the ground truth toward which the models learn to mimic. While the bulky parts of the segmentation targets are relatively easy to label, the peripheral areas are often difficult to handle due to ambiguous boundaries and the partial volume effect, etc., and are likely to be labeled with uncertainty. This uncertainty in labeling may, in turn, result in unsatisfactory performance of the trained models. In this paper, we propose superpixel-based label softening to tackle the above issue. Generated by unsupervised over-segmentation, each superpixel is expected to represent a locally homogeneous area. If a superpixel intersects with the annotation boundary, we consider a high probability of uncertain labeling within this area. Driven by this intuition, we soften labels in this area based on signed distances to the annotation boundary and assign probability values within [0, 1] to them, in comparison with the original "hard", binary labels of either 0 or 1. The softened labels are then used to train the segmentation models together with the hard labels. Experimental results on a brain MRI dataset and an optical coherence tomography dataset demonstrate that this conceptually simple and implementation-wise easy method achieves overall superior segmentation performances to baseline and comparison methods for both 3D and 2D medical images.
Revisiting Rubik's Cube: Self-supervised Learning with Volume-wise Transformation for 3D Medical Image Segmentation
Jul 17, 2020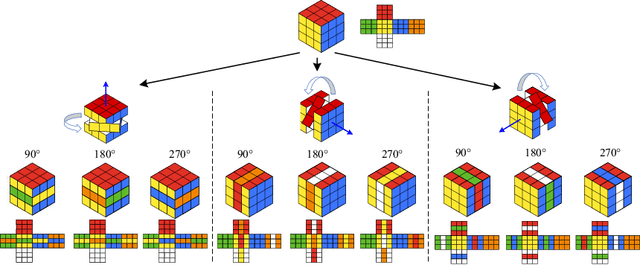
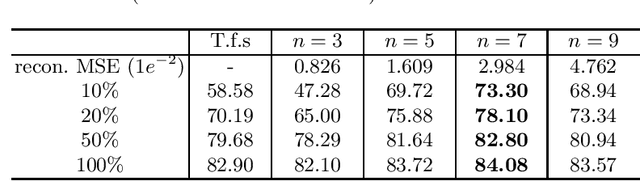
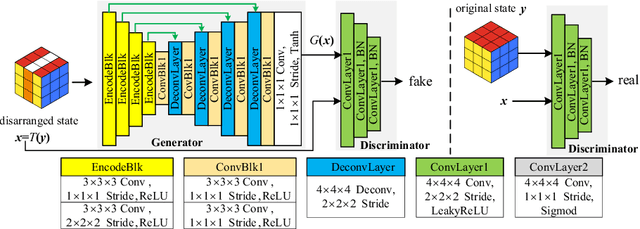
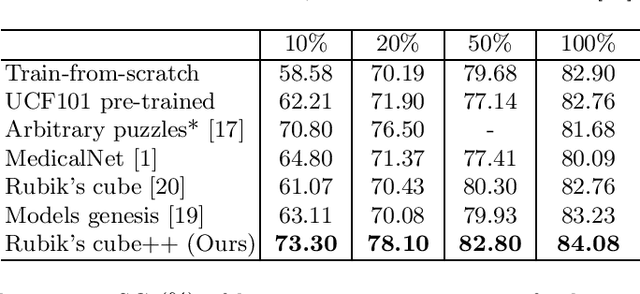
Deep learning highly relies on the quantity of annotated data. However, the annotations for 3D volumetric medical data require experienced physicians to spend hours or even days for investigation. Self-supervised learning is a potential solution to get rid of the strong requirement of training data by deeply exploiting raw data information. In this paper, we propose a novel self-supervised learning framework for volumetric medical images. Specifically, we propose a context restoration task, i.e., Rubik's cube++, to pre-train 3D neural networks. Different from the existing context-restoration-based approaches, we adopt a volume-wise transformation for context permutation, which encourages network to better exploit the inherent 3D anatomical information of organs. Compared to the strategy of training from scratch, fine-tuning from the Rubik's cube++ pre-trained weight can achieve better performance in various tasks such as pancreas segmentation and brain tissue segmentation. The experimental results show that our self-supervised learning method can significantly improve the accuracy of 3D deep learning networks on volumetric medical datasets without the use of extra data.
Learning and Exploiting Interclass Visual Correlations for Medical Image Classification
Jul 13, 2020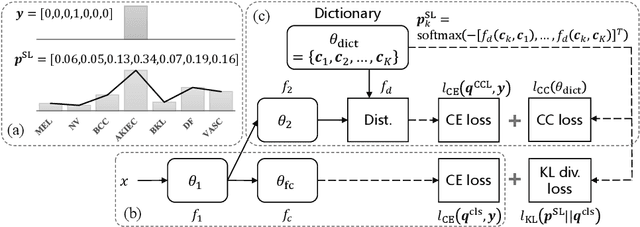
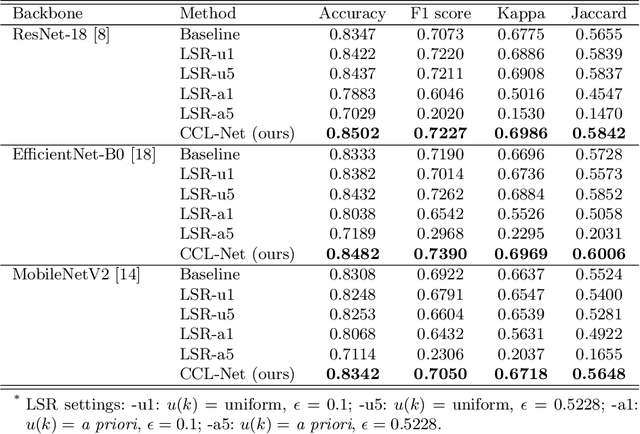

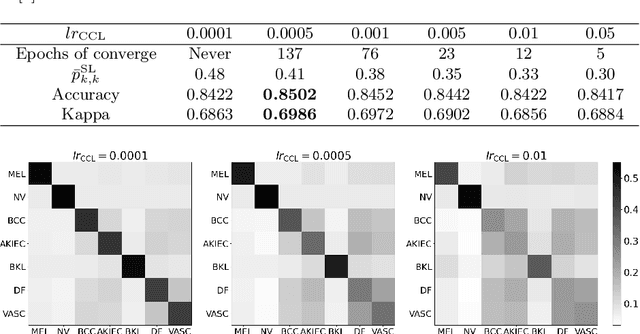
Deep neural network-based medical image classifications often use "hard" labels for training, where the probability of the correct category is 1 and those of others are 0. However, these hard targets can drive the networks over-confident about their predictions and prone to overfit the training data, affecting model generalization and adaption. Studies have shown that label smoothing and softening can improve classification performance. Nevertheless, existing approaches are either non-data-driven or limited in applicability. In this paper, we present the Class-Correlation Learning Network (CCL-Net) to learn interclass visual correlations from given training data, and produce soft labels to help with classification tasks. Instead of letting the network directly learn the desired correlations, we propose to learn them implicitly via distance metric learning of class-specific embeddings with a lightweight plugin CCL block. An intuitive loss based on a geometrical explanation of correlation is designed for bolstering learning of the interclass correlations. We further present end-to-end training of the proposed CCL block as a plugin head together with the classification backbone while generating soft labels on the fly. Our experimental results on the International Skin Imaging Collaboration 2018 dataset demonstrate effective learning of the interclass correlations from training data, as well as consistent improvements in performance upon several widely used modern network structures with the CCL block.
Cross-denoising Network against Corrupted Labels in Medical Image Segmentation with Domain Shift
Jun 19, 2020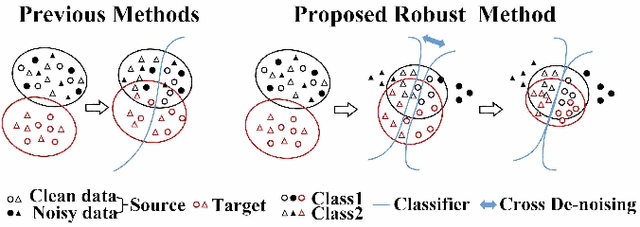
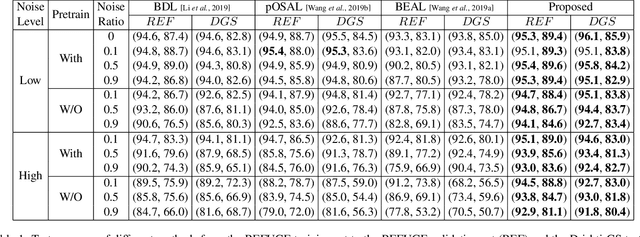
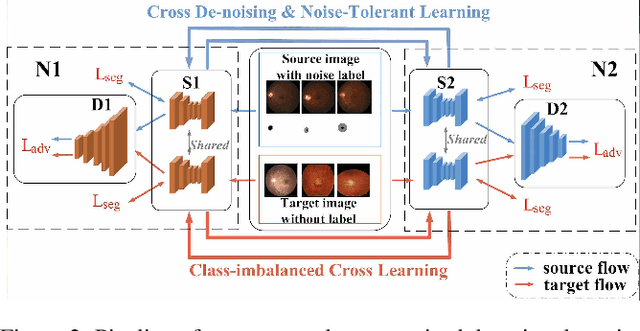
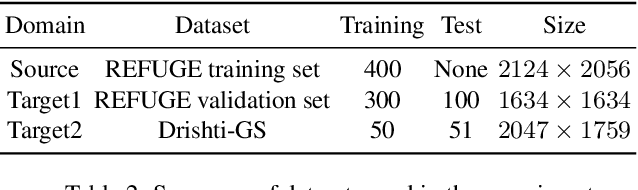
Deep convolutional neural networks (DCNNs) have contributed many breakthroughs in segmentation tasks, especially in the field of medical imaging. However, \textit{domain shift} and \textit{corrupted annotations}, which are two common problems in medical imaging, dramatically degrade the performance of DCNNs in practice. In this paper, we propose a novel robust cross-denoising framework using two peer networks to address domain shift and corrupted label problems with a peer-review strategy. Specifically, each network performs as a mentor, mutually supervised to learn from reliable samples selected by the peer network to combat with corrupted labels. In addition, a noise-tolerant loss is proposed to encourage the network to capture the key location and filter the discrepancy under various noise-contaminant labels. To further reduce the accumulated error, we introduce a class-imbalanced cross learning using most confident predictions at the class-level. Experimental results on REFUGE and Drishti-GS datasets for optic disc (OD) and optic cup (OC) segmentation demonstrate the superior performance of our proposed approach to the state-of-the-art methods.
Generative Adversarial Networks for Video-to-Video Domain Adaptation
Apr 17, 2020

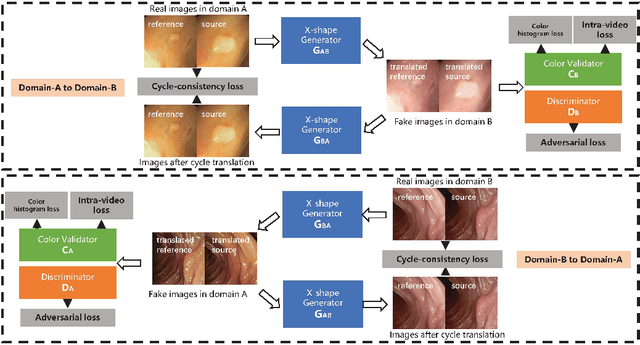
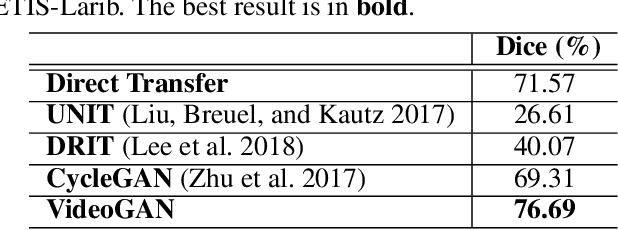
Endoscopic videos from multicentres often have different imaging conditions, e.g., color and illumination, which make the models trained on one domain usually fail to generalize well to another. Domain adaptation is one of the potential solutions to address the problem. However, few of existing works focused on the translation of video-based data. In this work, we propose a novel generative adversarial network (GAN), namely VideoGAN, to transfer the video-based data across different domains. As the frames of a video may have similar content and imaging conditions, the proposed VideoGAN has an X-shape generator to preserve the intra-video consistency during translation. Furthermore, a loss function, namely color histogram loss, is proposed to tune the color distribution of each translated frame. Two colonoscopic datasets from different centres, i.e., CVC-Clinic and ETIS-Larib, are adopted to evaluate the performance of domain adaptation of our VideoGAN. Experimental results demonstrate that the adapted colonoscopic video generated by our VideoGAN can significantly boost the segmentation accuracy, i.e., an improvement of 5%, of colorectal polyps on multicentre datasets. As our VideoGAN is a general network architecture, we also evaluate its performance with the CamVid driving video dataset on the cloudy-to-sunny translation task. Comprehensive experiments show that the domain gap could be substantially narrowed down by our VideoGAN.