 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Trustworthy Healthcare AI: Attention-Based Feature Learning for COVID-19 Screening With Chest Radiography
Jul 19, 2022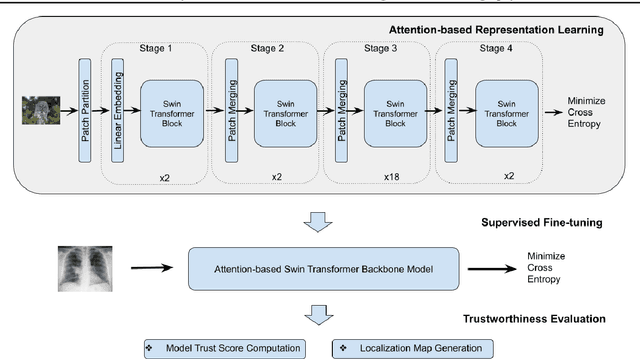
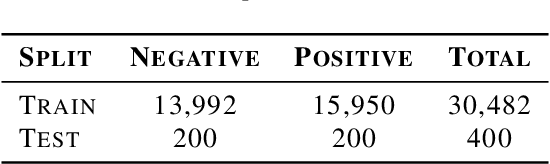

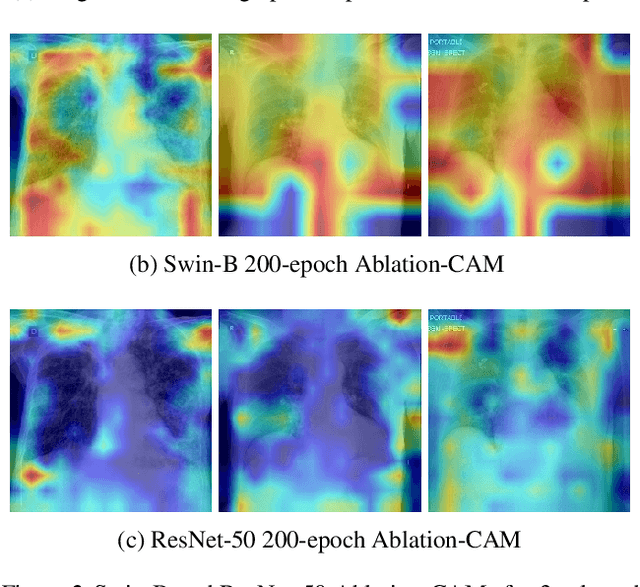
Building AI models with trustworthiness is important especially in regulated areas such as healthcare. In tackling COVID-19, previous work uses convolutional neural networks as the backbone architecture, which has shown to be prone to over-caution and overconfidence in making decisions, rendering them less trustworthy -- a crucial flaw in the context of medical imaging. In this study, we propose a feature learning approach using Vision Transformers, which use an attention-based mechanism, and examine the representation learning capability of Transformers as a new backbone architecture for medical imaging. Through the task of classifying COVID-19 chest radiographs, we investigate into whether generalization capabilities benefit solely from Vision Transformers' architectural advances. Quantitative and qualitative evaluations are conducted on the trustworthiness of the models, through the use of "trust score" computation and a visual explainability technique. We conclude that the attention-based feature learning approach is promising in building trustworthy deep learning models for healthcare.
Dense Cross-Query-and-Support Attention Weighted Mask Aggregation for Few-Shot Segmentation
Jul 18, 2022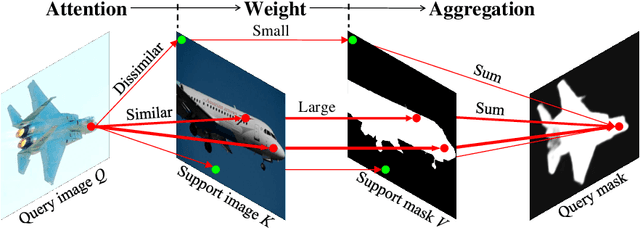
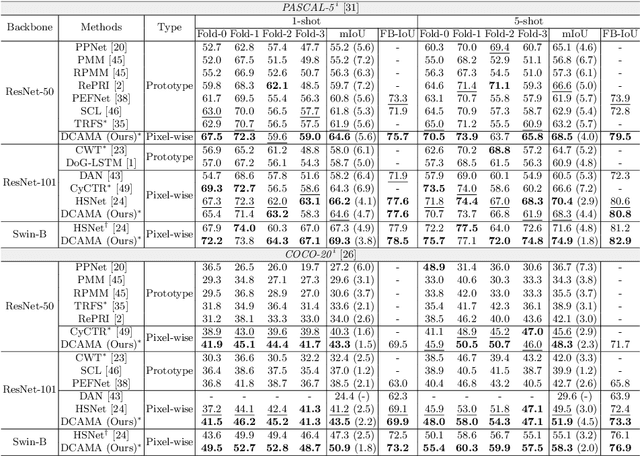
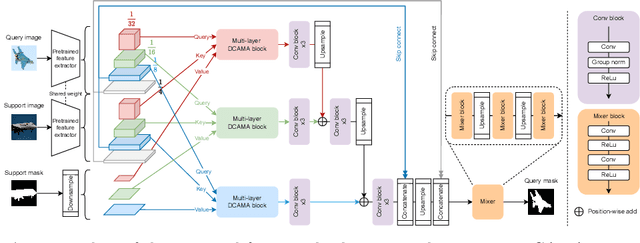
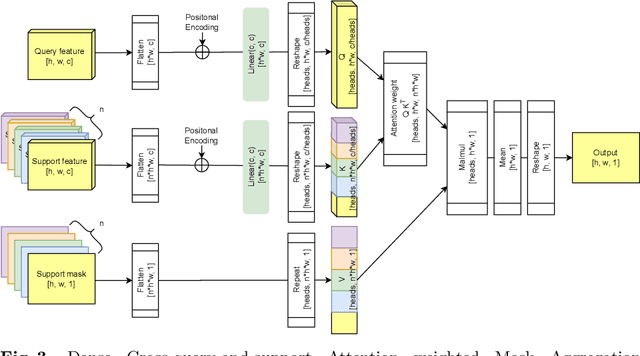
Research into Few-shot Semantic Segmentation (FSS) has attracted great attention, with the goal to segment target objects in a query image given only a few annotated support images of the target class. A key to this challenging task is to fully utilize the information in the support images by exploiting fine-grained correlations between the query and support images. However, most existing approaches either compressed the support information into a few class-wise prototypes, or used partial support information (e.g., only foreground) at the pixel level, causing non-negligible information loss. In this paper, we propose Dense pixel-wise Cross-query-and-support Attention weighted Mask Aggregation (DCAMA), where both foreground and background support information are fully exploited via multi-level pixel-wise correlations between paired query and support features. Implemented with the scaled dot-product attention in the Transformer architecture, DCAMA treats every query pixel as a token, computes its similarities with all support pixels, and predicts its segmentation label as an additive aggregation of all the support pixels' labels -- weighted by the similarities. Based on the unique formulation of DCAMA, we further propose efficient and effective one-pass inference for n-shot segmentation, where pixels of all support images are collected for the mask aggregation at once. Experiments show that our DCAMA significantly advances the state of the art on standard FSS benchmarks of PASCAL-5i, COCO-20i, and FSS-1000, e.g., with 3.1%, 9.7%, and 3.6% absolute improvements in 1-shot mIoU over previous best records. Ablative studies also verify the design DCAMA.
Learning Shape Priors by Pairwise Comparison for Robust Semantic Segmentation
Apr 23, 2022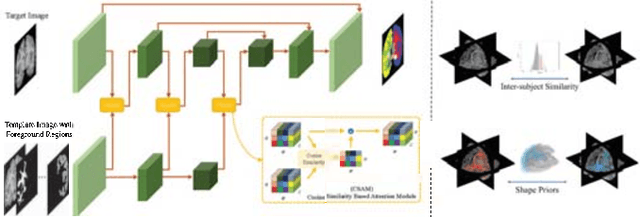
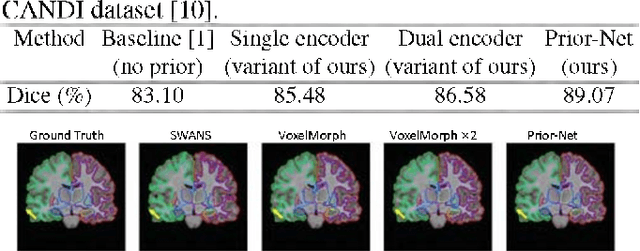
Semantic segmentation is important in medical image analysis. Inspired by the strong ability of traditional image analysis techniques in capturing shape priors and inter-subject similarity, many deep learning (DL) models have been recently proposed to exploit such prior information and achieved robust performance. However, these two types of important prior information are usually studied separately in existing models. In this paper, we propose a novel DL model to model both type of priors within a single framework. Specifically, we introduce an extra encoder into the classic encoder-decoder structure to form a Siamese structure for the encoders, where one of them takes a target image as input (the image-encoder), and the other concatenates a template image and its foreground regions as input (the template-encoder). The template-encoder encodes the shape priors and appearance characteristics of each foreground class in the template image. A cosine similarity based attention module is proposed to fuse the information from both encoders, to utilize both types of prior information encoded by the template-encoder and model the inter-subject similarity for each foreground class. Extensive experiments on two public datasets demonstrate that our proposed method can produce superior performance to competing methods.
DFTR: Depth-supervised Fusion Transformer for Salient Object Detection
Apr 11, 2022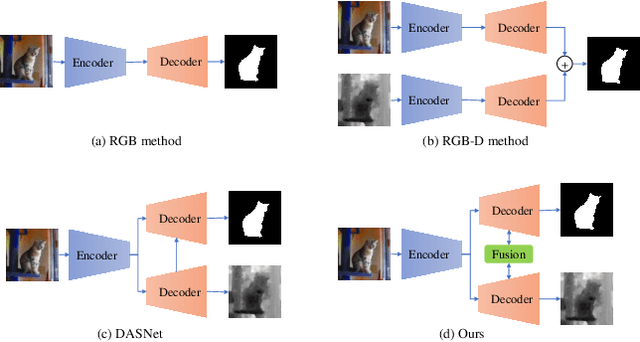
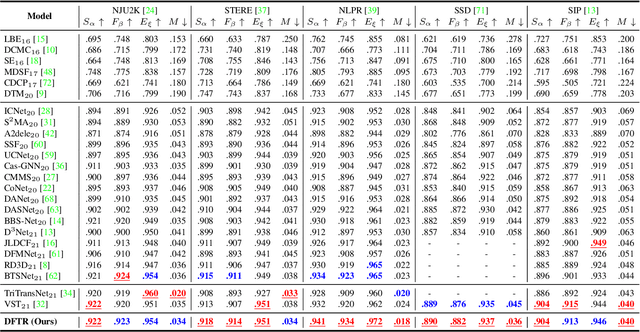
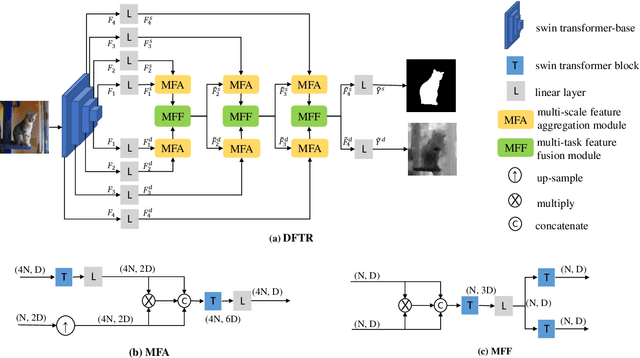
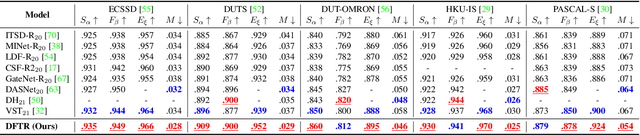
Automated salient object detection (SOD) plays an increasingly crucial role in many computer vision applications. By reformulating the depth information as supervision rather than as input, depth-supervised convolutional neural networks (CNN) have achieved promising results on both RGB and RGB-D SOD scenarios with the merits of no requirements for extra depth networks and depth inputs in the inference stage. This paper, for the first time, seeks to expand the applicability of depth supervision to the Transformer architecture. Specifically, we develop a Depth-supervised Fusion TRansformer (DFTR), to further improve the accuracy of both RGB and RGB-D SOD. The proposed DFTR involves three primary features: 1) DFTR, to the best of our knowledge, is the first pure Transformer-based model for depth-supervised SOD; 2) A multi-scale feature aggregation (MFA) module is proposed to fully exploit the multi-scale features encoded by the Swin Transformer in a coarse-to-fine manner; 3) To enable bidirectional information flow across different streams of features, a novel multi-stage feature fusion (MFF) module is further integrated into our DFTR with the emphasis on salient regions at different network learning stages. We extensively evaluate the proposed DFTR on ten benchmarking datasets. Experimental results show that our DFTR consistently outperforms the existing state-of-the-art methods for both RGB and RGB-D SOD tasks. The code and model will be made publicly available.
Domain Adaptation Meets Zero-Shot Learning: An Annotation-Efficient Approach to Multi-Modality Medical Image Segmentation
Mar 19, 2022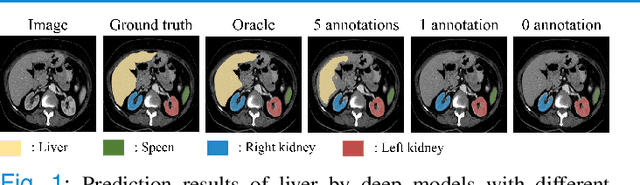
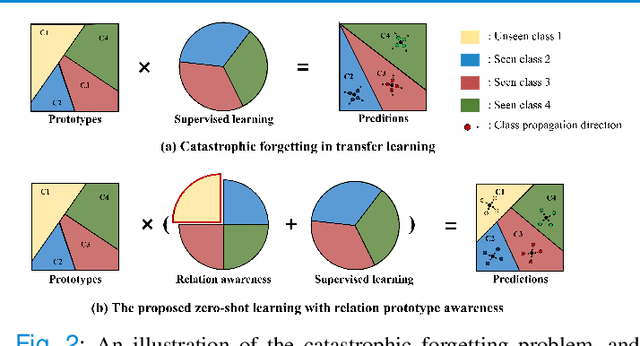
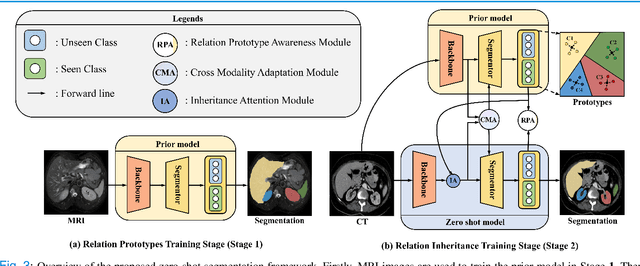
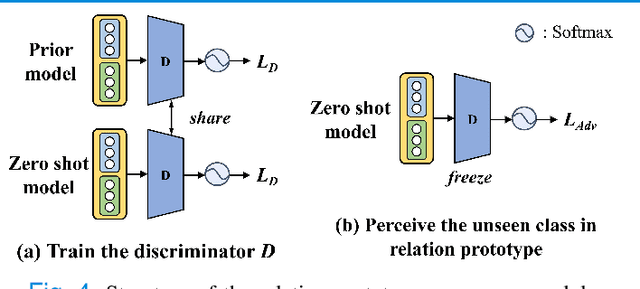
Due to the lack of properly annotated medical data, exploring the generalization capability of the deep model is becoming a public concern. Zero-shot learning (ZSL) has emerged in recent years to equip the deep model with the ability to recognize unseen classes. However, existing studies mainly focus on natural images, which utilize linguistic models to extract auxiliary information for ZSL. It is impractical to apply the natural image ZSL solutions directly to medical images, since the medical terminology is very domain-specific, and it is not easy to acquire linguistic models for the medical terminology. In this work, we propose a new paradigm of ZSL specifically for medical images utilizing cross-modality information. We make three main contributions with the proposed paradigm. First, we extract the prior knowledge about the segmentation targets, called relation prototypes, from the prior model and then propose a cross-modality adaptation module to inherit the prototypes to the zero-shot model. Second, we propose a relation prototype awareness module to make the zero-shot model aware of information contained in the prototypes. Last but not least, we develop an inheritance attention module to recalibrate the relation prototypes to enhance the inheritance process. The proposed framework is evaluated on two public cross-modality datasets including a cardiac dataset and an abdominal dataset. Extensive experiments show that the proposed framework significantly outperforms the state of the arts.
Conquering Data Variations in Resolution: A Slice-Aware Multi-Branch Decoder Network
Mar 07, 2022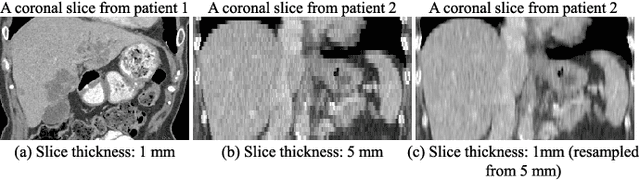
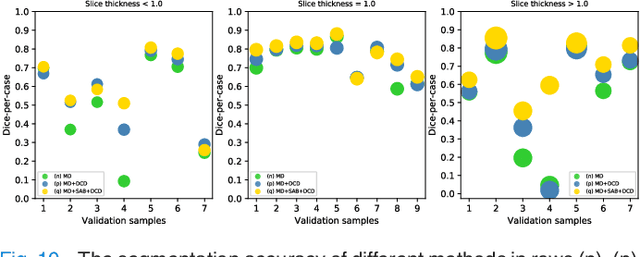
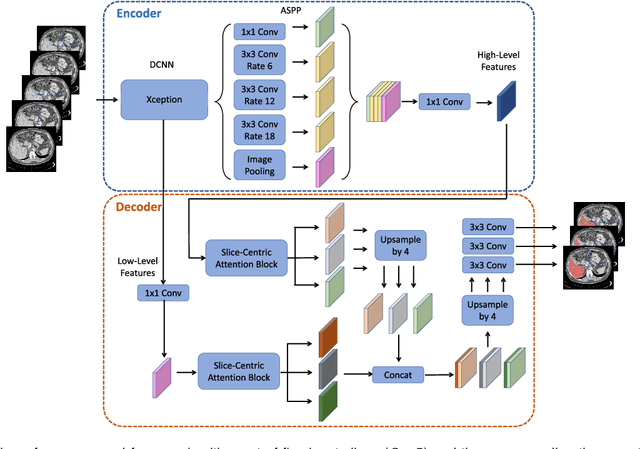
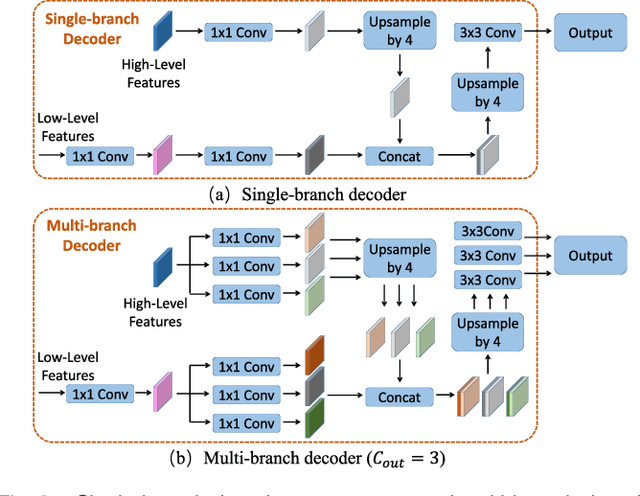
Fully convolutional neural networks have made promising progress in joint liver and liver tumor segmentation. Instead of following the debates over 2D versus 3D networks (for example, pursuing the balance between large-scale 2D pretraining and 3D context), in this paper, we novelly identify the wide variation in the ratio between intra- and inter-slice resolutions as a crucial obstacle to the performance. To tackle the mismatch between the intra- and inter-slice information, we propose a slice-aware 2.5D network that emphasizes extracting discriminative features utilizing not only in-plane semantics but also out-of-plane coherence for each separate slice. Specifically, we present a slice-wise multi-input multi-output architecture to instantiate such a design paradigm, which contains a Multi-Branch Decoder (MD) with a Slice-centric Attention Block (SAB) for learning slice-specific features and a Densely Connected Dice (DCD) loss to regularize the inter-slice predictions to be coherent and continuous. Based on the aforementioned innovations, we achieve state-of-the-art results on the MICCAI 2017 Liver Tumor Segmentation (LiTS) dataset. Besides, we also test our model on the ISBI 2019 Segmentation of THoracic Organs at Risk (SegTHOR) dataset, and the result proves the robustness and generalizability of the proposed method in other segmentation tasks.
Simultaneous Alignment and Surface Regression Using Hybrid 2D-3D Networks for 3D Coherent Layer Segmentation of Retina OCT Images
Mar 04, 2022

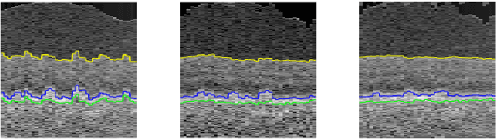
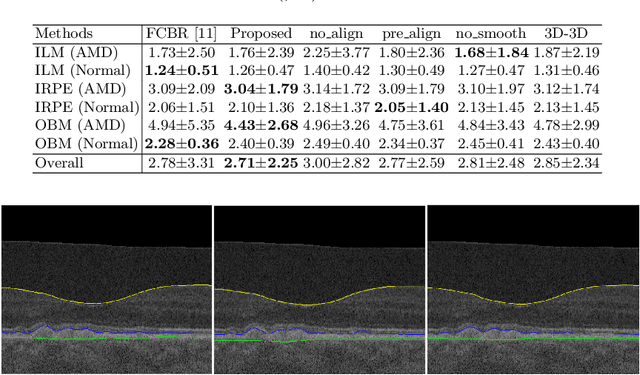
Automated surface segmentation of retinal layer is important and challenging in analyzing optical coherence tomography (OCT). Recently, many deep learning based methods have been developed for this task and yield remarkable performance. However, due to large spatial gap and potential mismatch between the B-scans of OCT data, all of them are based on 2D segmentation of individual B-scans, which may loss the continuity information across the B-scans. In addition, 3D surface of the retina layers can provide more diagnostic information, which is crucial in quantitative image analysis. In this study, a novel framework based on hybrid 2D-3D convolutional neural networks (CNNs) is proposed to obtain continuous 3D retinal layer surfaces from OCT. The 2D features of individual B-scans are extracted by an encoder consisting of 2D convolutions. These 2D features are then used to produce the alignment displacement field and layer segmentation by two 3D decoders, which are coupled via a spatial transformer module. The entire framework is trained end-to-end. To the best of our knowledge, this is the first study that attempts 3D retinal layer segmentation in volumetric OCT images based on CNNs. Experiments on a publicly available dataset show that our framework achieves superior results to state-of-the-art 2D methods in terms of both layer segmentation accuracy and cross-B-scan 3D continuity, thus offering more clinical values than previous works.
Bidirectional Pricing and Demand Response for Nanogrids with HVAC Systems
Mar 01, 2022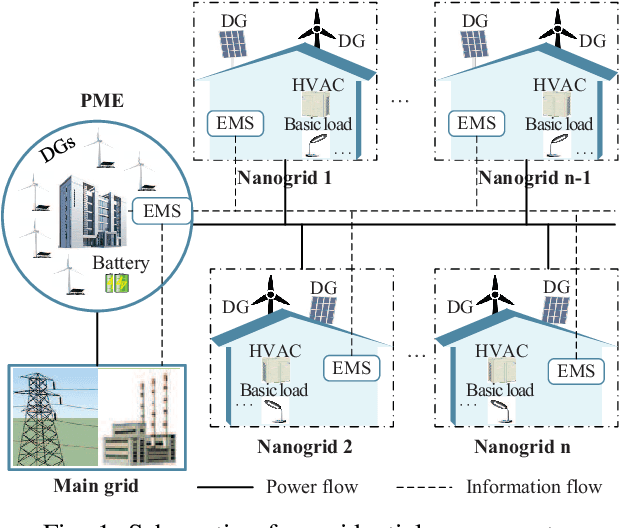

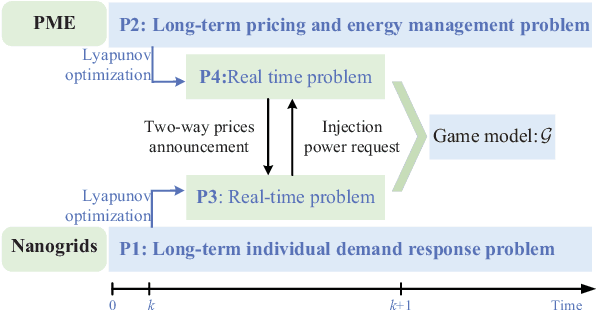
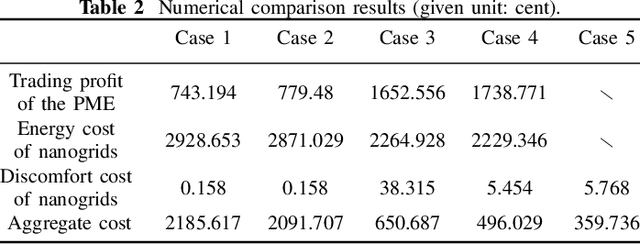
Owing to the fluctuant renewable generation and power demand, the energy surplus or deficit in each nanogrid is embodied differently across time. To stimulate local renewable energy consumption and minimize the long-term energy cost, some issues still remain to be explored: when and how the energy demand and bidirectional trading prices are scheduled considering personal comfort preferences and environmental factors. For this purpose, the demand response and two-way pricing problems concurrently for nanogrids and a public monitoring entity (PME) are studied with exploiting the large potential thermal elastic ability of heating, ventilation and air-conditioning (HVAC) units. Different from nanogrids, in terms of minimizing time-average costs, PME aims to set reasonable prices and optimize profits by trading with nanogrids and the main grid bi-directionally. In particular, such bilevel energy management problem is formulated as a stochastic form in a long-term horizon. Since there are uncertain system parameters, time-coupled queue constraints and the interplay of bilevel decision-making, it is challenging to solve the formulated problems. To this end, we derive a form of relaxation based on Lyapunov optimization technique to make the energy management problem tractable without forecasting the related system parameters. The transaction between nanogrids and PME is captured by a one-leader and multi-follower Stackelberg game framework. Then, theoretical analysis of the existence and uniqueness of Stackelberg equilibrium (SE) is developed based on the proposed game property. Following that, we devise an optimization algorithm to reach the SE with less information exchange. Numerical experiments validate the effectiveness of the proposed approach.
Asynchronous Decentralized Federated Learning for Collaborative Fault Diagnosis of PV Stations
Feb 28, 2022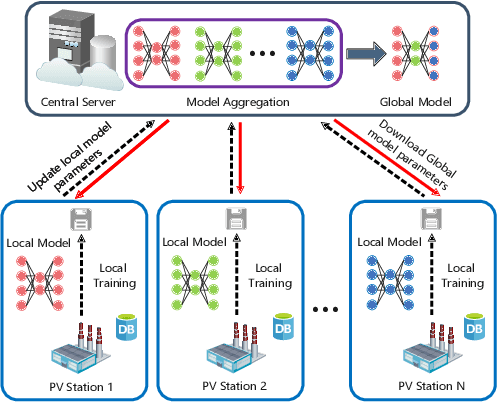
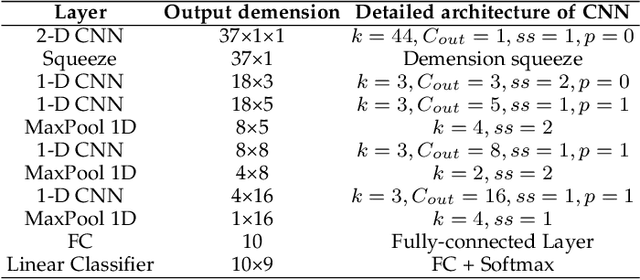
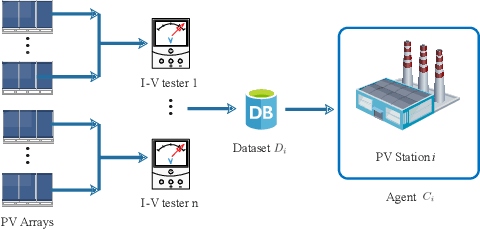

Due to the different losses caused by various photovoltaic (PV) array faults, accurate diagnosis of fault types is becoming increasingly important. Compared with a single one, multiple PV stations collect sufficient fault samples, but their data is not allowed to be shared directly due to potential conflicts of interest. Therefore, federated learning can be exploited to train a collaborative fault diagnosis model. However, the modeling efficiency is seriously affected by the model update mechanism since each PV station has a different computing capability and amount of data. Moreover, for the safe and stable operation of the PV system, the robustness of collaborative modeling must be guaranteed rather than simply being processed on a central server. To address these challenges, a novel asynchronous decentralized federated learning (ADFL) framework is proposed. Each PV station not only trains its local model but also participates in collaborative fault diagnosis by exchanging model parameters to improve the generalization without losing accuracy. The global model is aggregated distributedly to avoid central node failure. By designing the asynchronous update scheme, the communication overhead and training time are greatly reduced. Both the experiments and numerical simulations are carried out to verify the effectiveness of the proposed method.
Label Propagation for Annotation-Efficient Nuclei Segmentation from Pathology Images
Feb 16, 2022
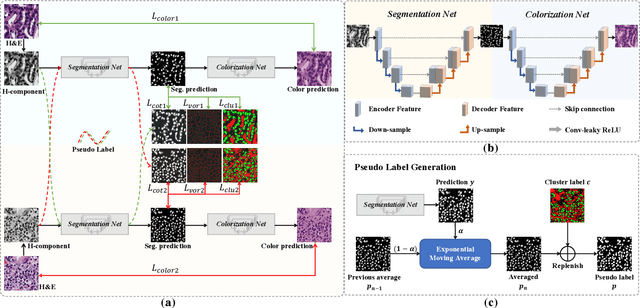
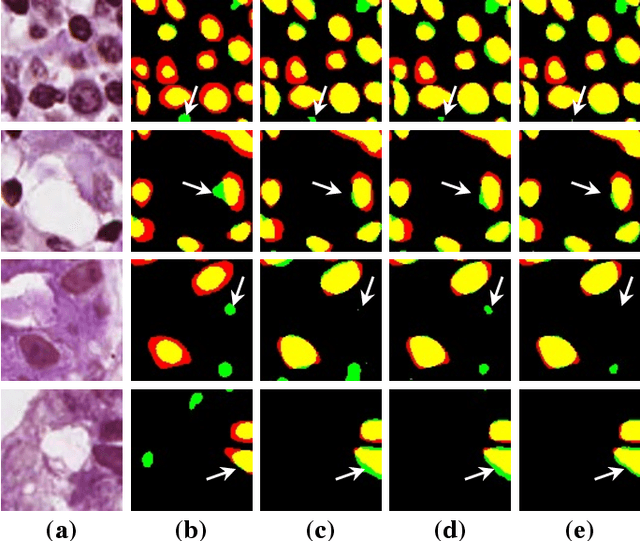

Nuclei segmentation is a crucial task for whole slide image analysis in digital pathology. Generally, the segmentation performance of fully-supervised learning heavily depends on the amount and quality of the annotated data. However, it is time-consuming and expensive for professional pathologists to provide accurate pixel-level ground truth, while it is much easier to get coarse labels such as point annotations. In this paper, we propose a weakly-supervised learning method for nuclei segmentation that only requires point annotations for training. The proposed method achieves label propagation in a coarse-to-fine manner as follows. First, coarse pixel-level labels are derived from the point annotations based on the Voronoi diagram and the k-means clustering method to avoid overfitting. Second, a co-training strategy with an exponential moving average method is designed to refine the incomplete supervision of the coarse labels. Third, a self-supervised visual representation learning method is tailored for nuclei segmentation of pathology images that transforms the hematoxylin component images into the H\&E stained images to gain better understanding of the relationship between the nuclei and cytoplasm. We comprehensively evaluate the proposed method using two public datasets. Both visual and quantitative results demonstrate the superiority of our method to the state-of-the-art methods, and its competitive performance compared to the fully-supervised methods. The source codes for implementing the experiments will be released after acceptance.