 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopological Mapping for Manhattan-like Repetitive Environments
Mar 10, 2020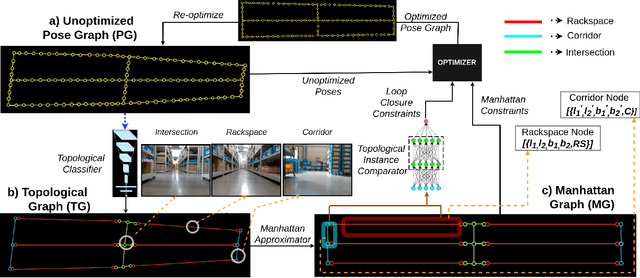

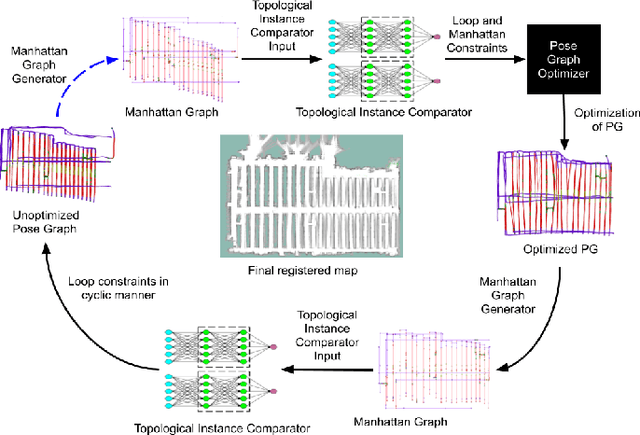
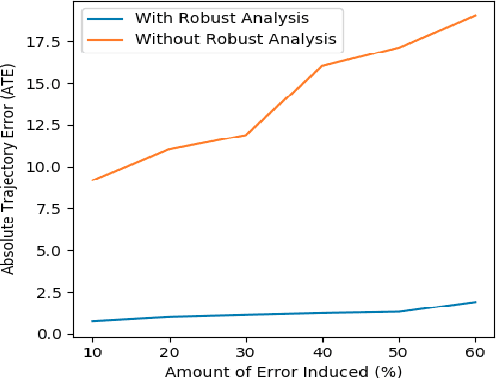
We showcase a topological mapping framework for a challenging indoor warehouse setting. At the most abstract level, the warehouse is represented as a Topological Graph where the nodes of the graph represent a particular warehouse topological construct (e.g. rackspace, corridor) and the edges denote the existence of a path between two neighbouring nodes or topologies. At the intermediate level, the map is represented as a Manhattan Graph where the nodes and edges are characterized by Manhattan properties and as a Pose Graph at the lower-most level of detail. The topological constructs are learned via a Deep Convolutional Network while the relational properties between topological instances are learnt via a Siamese-style Neural Network. In the paper, we show that maintaining abstractions such as Topological Graph and Manhattan Graph help in recovering an accurate Pose Graph starting from a highly erroneous and unoptimized Pose Graph. We show how this is achieved by embedding topological and Manhattan relations as well as Manhattan Graph aided loop closure relations as constraints in the backend Pose Graph optimization framework. The recovery of near ground-truth Pose Graph on real-world indoor warehouse scenes vindicate the efficacy of the proposed framework.
DFVS: Deep Flow Guided Scene Agnostic Image Based Visual Servoing
Mar 08, 2020

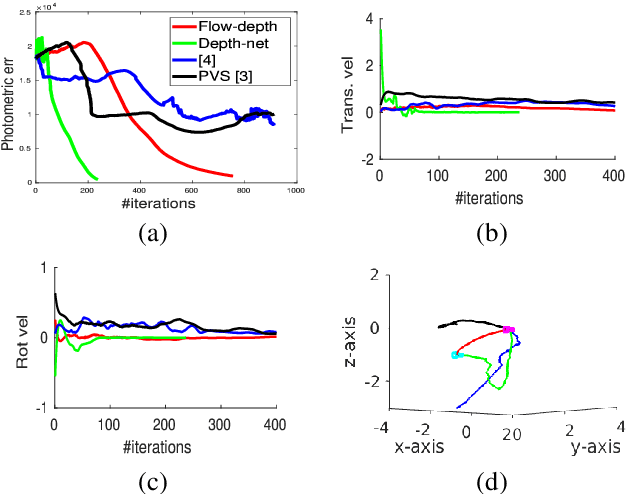
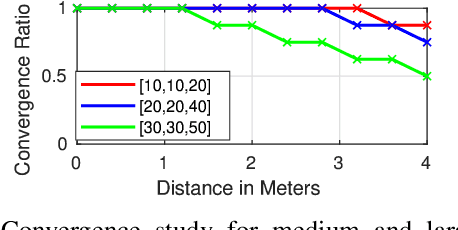
Existing deep learning based visual servoing approaches regress the relative camera pose between a pair of images. Therefore, they require a huge amount of training data and sometimes fine-tuning for adaptation to a novel scene. Furthermore, current approaches do not consider underlying geometry of the scene and rely on direct estimation of camera pose. Thus, inaccuracies in prediction of the camera pose, especially for distant goals, lead to a degradation in the servoing performance. In this paper, we propose a two-fold solution: (i) We consider optical flow as our visual features, which are predicted using a deep neural network. (ii) These flow features are then systematically integrated with depth estimates provided by another neural network using interaction matrix. We further present an extensive benchmark in a photo-realistic 3D simulation across diverse scenes to study the convergence and generalisation of visual servoing approaches. We show convergence for over 3m and 40 degrees while maintaining precise positioning of under 2cm and 1 degree on our challenging benchmark where the existing approaches that are unable to converge for majority of scenarios for over 1.5m and 20 degrees. Furthermore, we also evaluate our approach for a real scenario on an aerial robot. Our approach generalizes to novel scenarios producing precise and robust servoing performance for 6 degrees of freedom positioning tasks with even large camera transformations without any retraining or fine-tuning.
MonoLayout: Amodal scene layout from a single image
Feb 19, 2020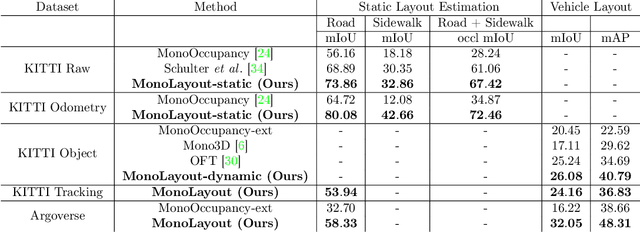
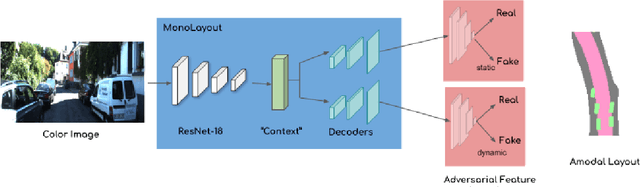
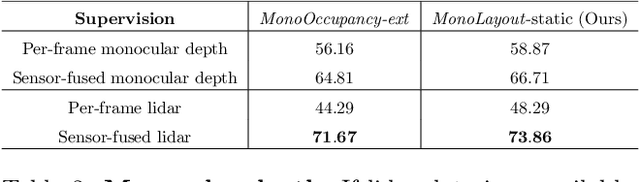
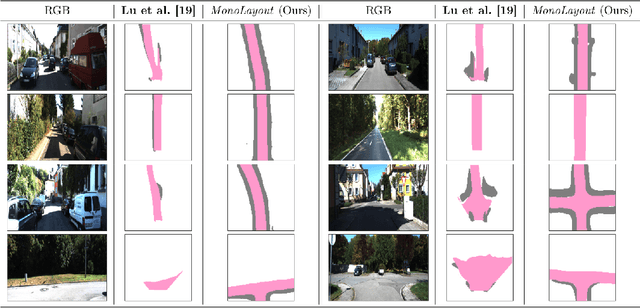
In this paper, we address the novel, highly challenging problem of estimating the layout of a complex urban driving scenario. Given a single color image captured from a driving platform, we aim to predict the bird's-eye view layout of the road and other traffic participants. The estimated layout should reason beyond what is visible in the image, and compensate for the loss of 3D information due to projection. We dub this problem amodal scene layout estimation, which involves "hallucinating" scene layout for even parts of the world that are occluded in the image. To this end, we present MonoLayout, a deep neural network for real-time amodal scene layout estimation from a single image. We represent scene layout as a multi-channel semantic occupancy grid, and leverage adversarial feature learning to hallucinate plausible completions for occluded image parts. Due to the lack of fair baseline methods, we extend several state-of-the-art approaches for road-layout estimation and vehicle occupancy estimation in bird's-eye view to the amodal setup for rigorous evaluation. By leveraging temporal sensor fusion to generate training labels, we significantly outperform current art over a number of datasets. On the KITTI and Argoverse datasets, we outperform all baselines by a significant margin. We also make all our annotations, and code publicly available. A video abstract of this paper is available https://www.youtube.com/watch?v=HcroGyo6yRQ .
Multi-object Monocular SLAM for Dynamic Environments
Feb 10, 2020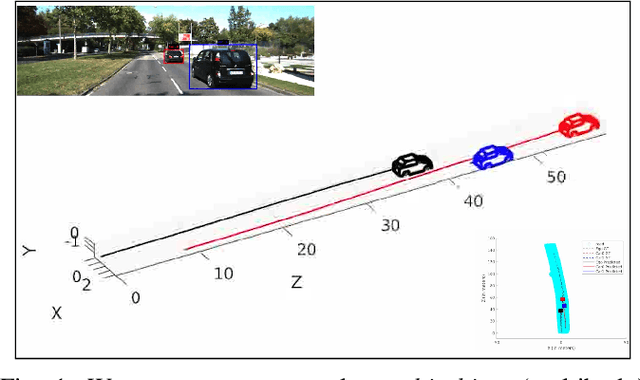
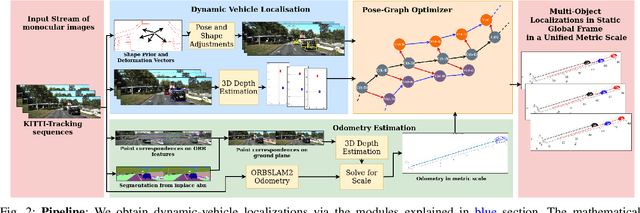
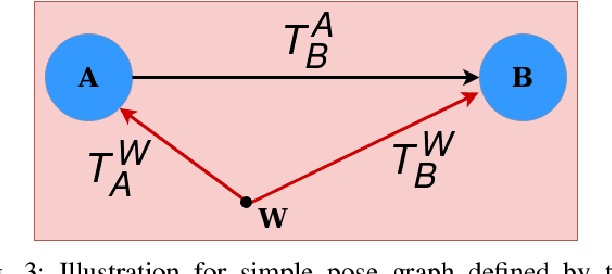
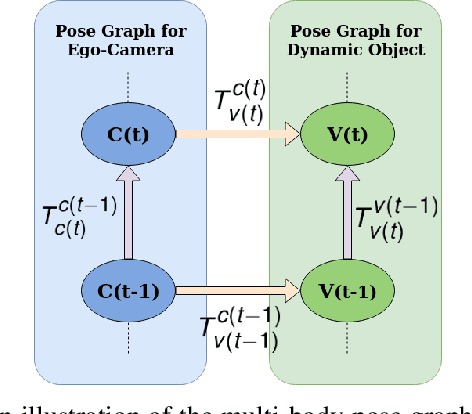
Multibody monocular SLAM in dynamic environments remains a long-standing challenge in terms of perception and state estimation. Although theoretical solutions exist, practice lags behind, predominantly due to the lack of robust perceptual and predictive models of dynamic participants. The quintessential challenge in Multi-body monocular SLAM in dynamic scenes stems from the problem of unobservability as it is not possible to triangulate a moving object from a moving monocular camera. Under restrictions of object motion the problem can be solved, however even here one is entailed to solve for the single family solution to the relative scale problem. The relative scale problem exists since the dynamic objects that get reconstructed with the monocular camera have a different scale vis a vis the scale space in which the stationary scene is reconstructed. We solve this rather intractable problem by reconstructing dynamic vehicles/participants in single view in metric scale through an object SLAM pipeline. Further, we lift the ego vehicle trajectory obtained from Monocular ORB-SLAM also into metric scales making use of ground plane features thereby resolving the relative scale problem. We present a multi pose-graph optimization formulation to estimate the pose and track dynamic objects in the environment. This optimization helps us reduce the average error in trajectories of multiple bodies in KITTI Tracking sequences. To the best of our knowledge, our method is the first practical monocular multi-body SLAM system to perform dynamic multi-object and ego localization in a unified framework in metric scale.
Reactive Navigation under Non-Parametric Uncertainty through Hilbert Space Embedding of Probabilistic Velocity Obstacles
Jan 21, 2020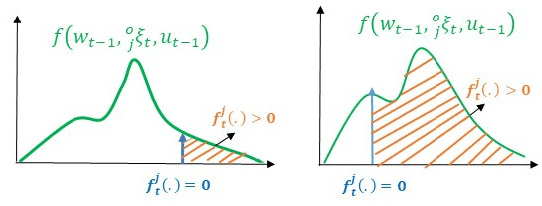
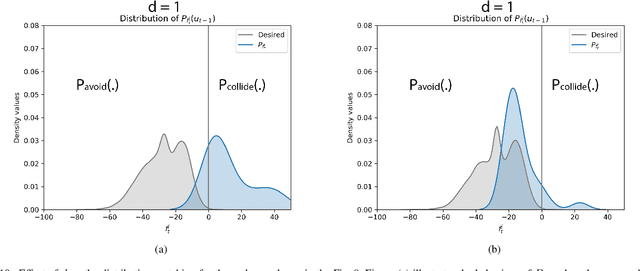
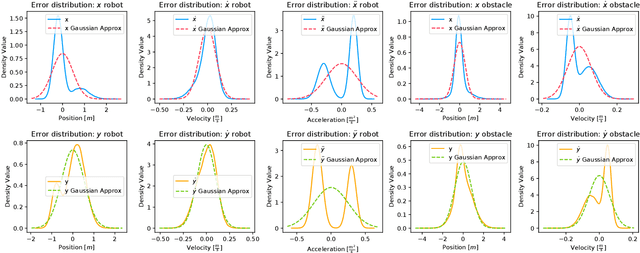
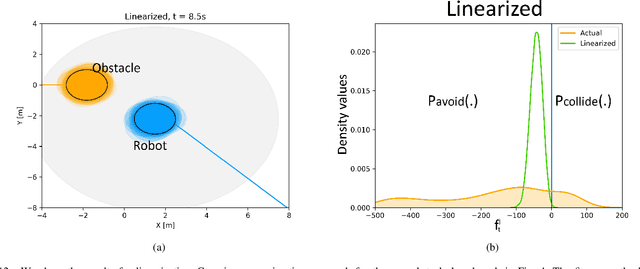
The probabilistic velocity obstacle (PVO) extends the concept of velocity obstacle (VO) to work in uncertain dynamic environments. In this paper, we show how a robust model predictive control (MPC) with PVO constraints under non-parametric uncertainty can be made computationally tractable. At the core of our formulation is a novel yet simple interpretation of our robust MPC as a problem of matching the distribution of PVO with a certain desired distribution. To this end, we propose two methods. Our first baseline method is based on approximating the distribution of PVO with a Gaussian Mixture Model (GMM) and subsequently performing distribution matching using Kullback Leibler (KL) divergence metric. Our second formulation is based on the possibility of representing arbitrary distributions as functions in Reproducing Kernel Hilbert Space (RKHS). We use this foundation to interpret our robust MPC as a problem of minimizing the distance between the desired distribution and the distribution of the PVO in the RKHS. Both the RKHS and GMM based formulation can work with any uncertainty distribution and thus allowing us to relax the prevalent Gaussian assumption in the existing works. We validate our formulation by taking an example of 2D navigation of quadrotors with a realistic noise model for perception and ego-motion uncertainty. In particular, we present a systematic comparison between the GMM and the RKHS approach and show that while both approaches can produce safe trajectories, the former is highly conservative and leads to poor tracking and control costs. Furthermore, RKHS based approach gives better computational times that are up to one order of magnitude lesser than the computation time of the GMM based approach.
A Hierarchical Network for Diverse Trajectory Proposals
Jun 09, 2019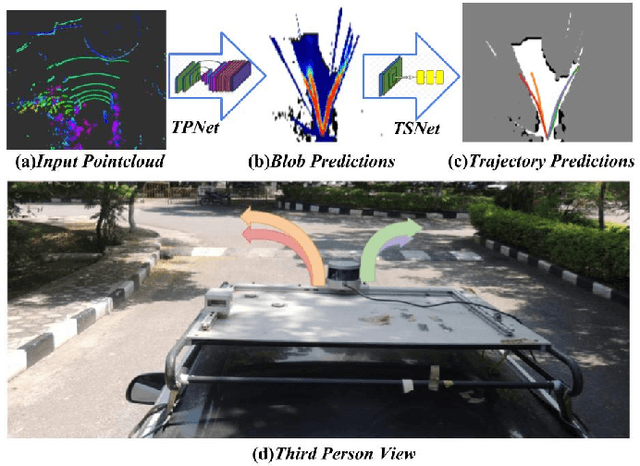
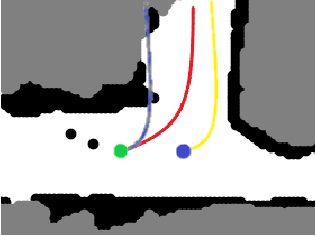
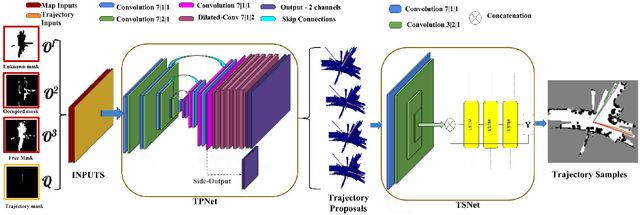

Autonomous explorative robots frequently encounter scenarios where multiple future trajectories can be pursued. Often these are cases with multiple paths around an obstacle or trajectory options towards various frontiers. Humans in such situations can inherently perceive and reason about the surrounding environment to identify several possibilities of either manoeuvring around the obstacles or moving towards various frontiers. In this work, we propose a 2 stage Convolutional Neural Network architecture which mimics such an ability to map the perceived surroundings to multiple trajectories that a robot can choose to traverse. The first stage is a Trajectory Proposal Network which suggests diverse regions in the environment which can be occupied in the future. The second stage is a Trajectory Sampling network which provides a finegrained trajectory over the regions proposed by Trajectory Proposal Network. We evaluate our framework in diverse and complicated real life settings. For the outdoor case, we use the KITTI dataset and our own outdoor driving dataset. In the indoor setting, we use an autonomous drone to navigate various scenarios and also a ground robot which can explore the environment using the trajectories proposed by our framework. Our experiments suggest that the framework is able to develop a semantic understanding of the obstacles, open regions and identify diverse trajectories that a robot can traverse. Our comparisons portray the performance gain of the proposed architecture over a diverse set of methods against which it is compared.
IVO: Inverse Velocity Obstacles for Real Time Navigation
May 04, 2019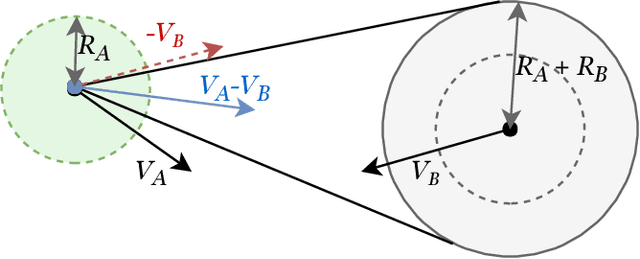
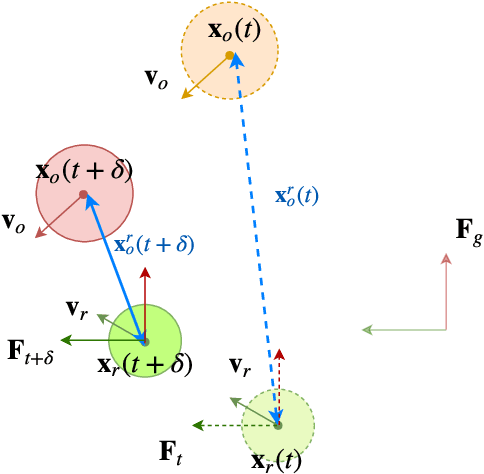
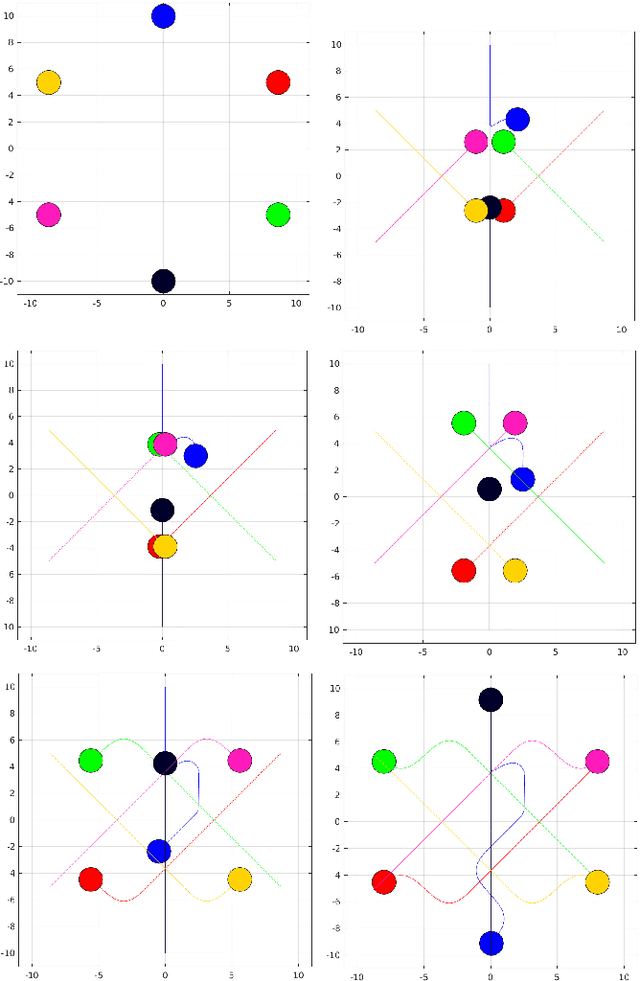
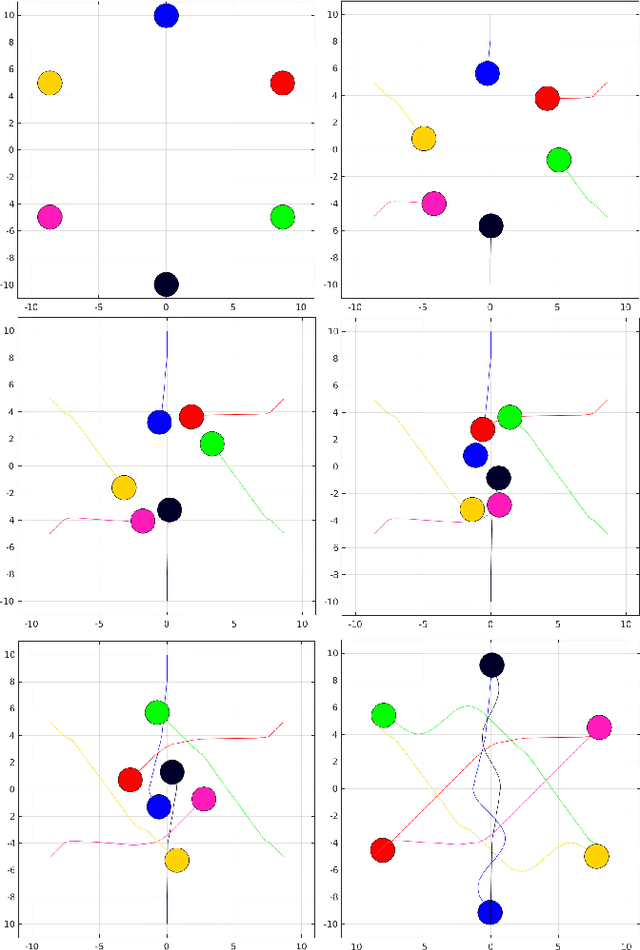
In this paper, we present "IVO: Inverse Velocity Obstacles" an ego-centric framework that improves the real time implementation. The proposed method stems from the concept of velocity obstacle and can be applied for both single agent and multi-agent system. It focuses on computing collision free maneuvers without any knowledge or assumption on the pose and the velocity of the robot. This is primarily achieved by reformulating the velocity obstacle to adapt to an ego-centric framework. This is a significant step towards improving real time implementations of collision avoidance in dynamic environments as there is no dependency on state estimation techniques to infer the robot pose and velocity. We evaluate IVO for both single agent and multi-agent in different scenarios and show it's efficacy over the existing formulations. We also show the real time scalability of the proposed methodology.
Learning to Prevent Monocular SLAM Failure using Reinforcement Learning
Dec 23, 2018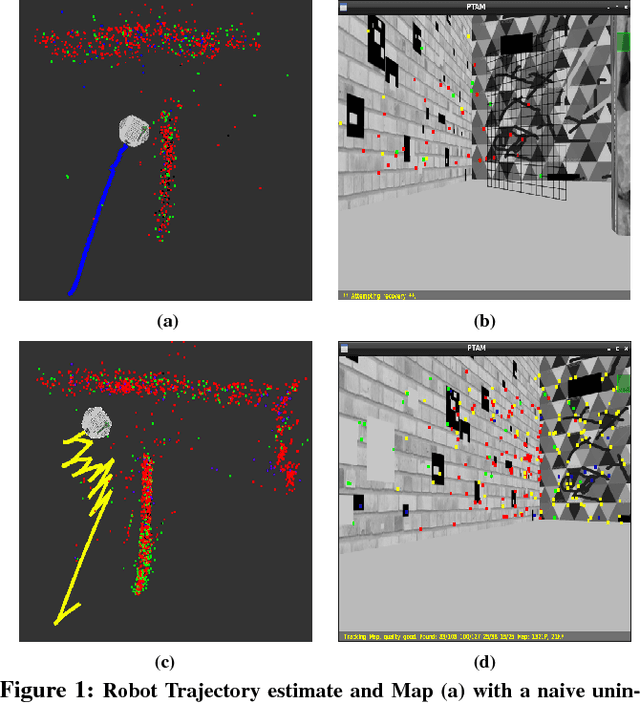

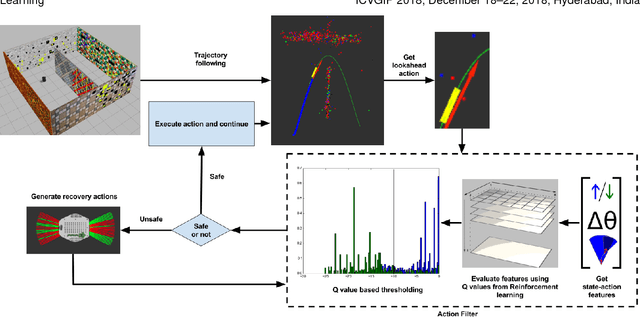
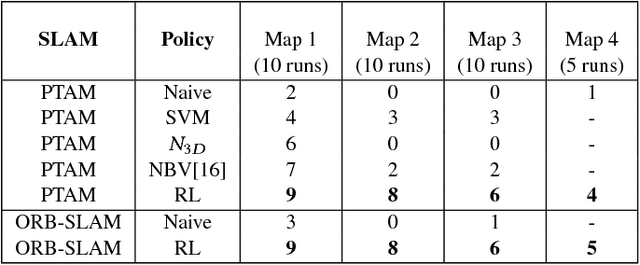
Monocular SLAM refers to using a single camera to estimate robot ego motion while building a map of the environment. While Monocular SLAM is a well studied problem, automating Monocular SLAM by integrating it with trajectory planning frameworks is particularly challenging. This paper presents a novel formulation based on Reinforcement Learning (RL) that generates fail safe trajectories wherein the SLAM generated outputs do not deviate largely from their true values. Quintessentially, the RL framework successfully learns the otherwise complex relation between perceptual inputs and motor actions and uses this knowledge to generate trajectories that do not cause failure of SLAM. We show systematically in simulations how the quality of the SLAM dramatically improves when trajectories are computed using RL. Our method scales effectively across Monocular SLAM frameworks in both simulation and in real world experiments with a mobile robot.
Solving Chance Constrained Optimization under Non-Parametric Uncertainty Through Hilbert Space Embedding
Nov 22, 2018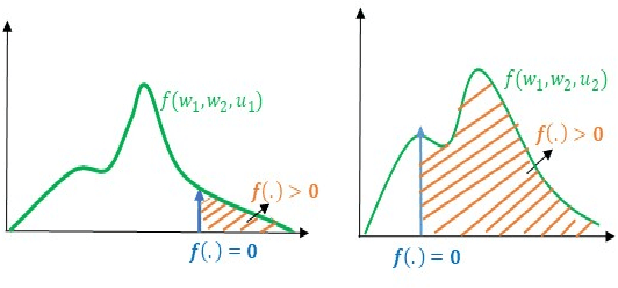
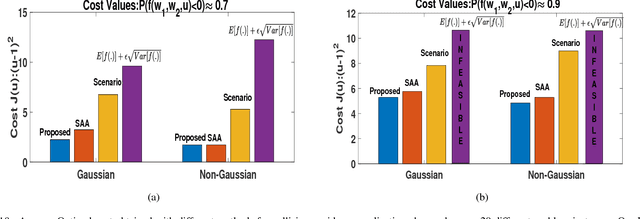
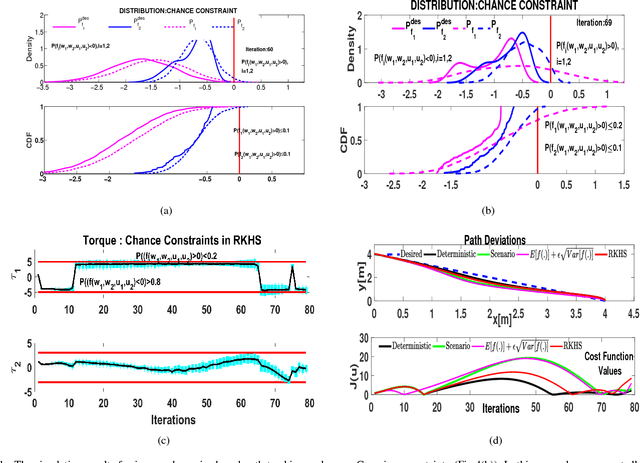
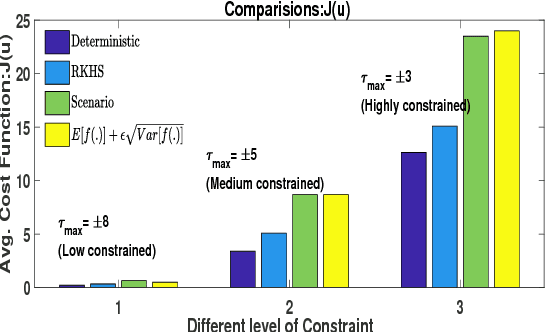
In this paper, we present an efficient algorithm for solving a class of chance constrained optimization under non-parametric uncertainty. Our algorithm is built on the possibility of representing arbitrary distributions as functions in Reproducing Kernel Hilbert Space (RKHS). We use this foundation to formulate chance constrained optimization as one of minimizing the distance between a desired distribution and the distribution of the constraint functions in the RKHS. We provide a systematic way of constructing the desired distribution based on a notion of scenario approximation. Furthermore, we use the kernel trick to show that the computational complexity of our reformulated optimization problem is comparable to solving a deterministic variant of the chance-constrained optimization. We validate our formulation on two important robotic/control applications: (i) reactive collision avoidance of mobile robots in uncertain dynamic environments and (ii) inverse dynamics based path tracking of manipulators under perception uncertainty. In both these applications, the underlying chance constraints are defined over highly non-linear and non-convex functions of the uncertain parameters and possibly also decision variables. We also benchmark our formulation with the existing approaches in terms of sample complexity and the achieved optimal cost highlighting significant improvements in both these metrics.
Parameter Sharing Reinforcement Learning Architecture for Multi Agent Driving Behaviors
Nov 17, 2018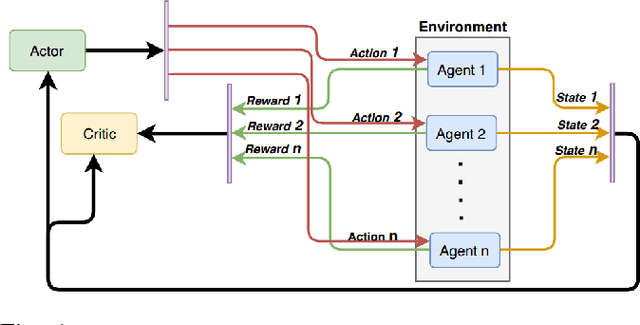

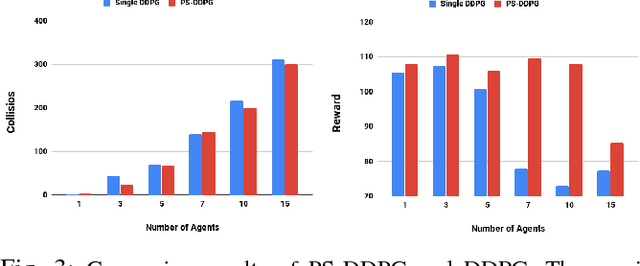

Multi-agent learning provides a potential framework for learning and simulating traffic behaviors. This paper proposes a novel architecture to learn multiple driving behaviors in a traffic scenario. The proposed architecture can learn multiple behaviors independently as well as simultaneously. We take advantage of the homogeneity of agents and learn in a parameter sharing paradigm. To further speed up the training process asynchronous updates are employed into the architecture. While learning different behaviors simultaneously, the given framework was also able to learn cooperation between the agents, without any explicit communication. We applied this framework to learn two important behaviors in driving: 1) Lane-Keeping and 2) Over-Taking. Results indicate faster convergence and learning of a more generic behavior, that is scalable to any number of agents. When compared the results with existing approaches, our results indicate equal and even better performance in some cases.