 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRackLay: Multi-Layer Layout Estimation for Warehouse Racks
Mar 17, 2021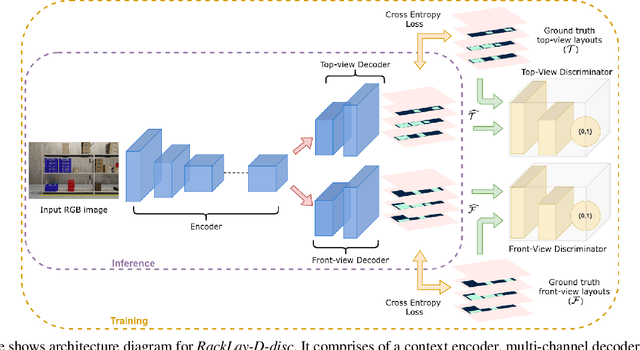

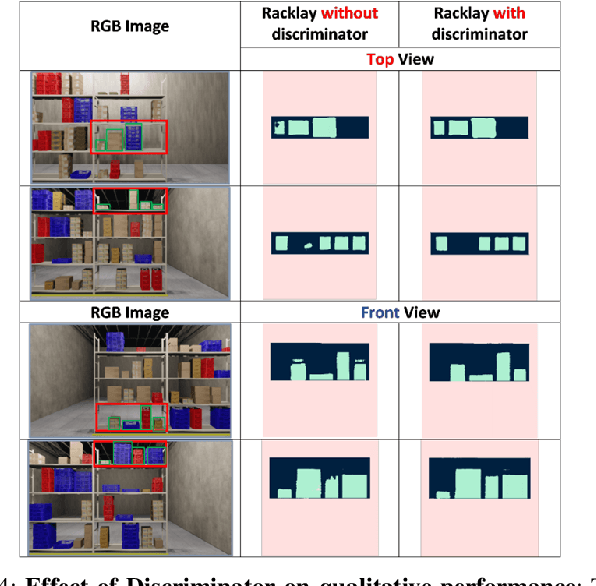

Given a monocular colour image of a warehouse rack, we aim to predict the bird's-eye view layout for each shelf in the rack, which we term as multi-layer layout prediction. To this end, we present RackLay, a deep neural network for real-time shelf layout estimation from a single image. Unlike previous layout estimation methods, which provide a single layout for the dominant ground plane alone, RackLay estimates the top-view and front-view layout for each shelf in the considered rack populated with objects. RackLay's architecture and its variants are versatile and estimate accurate layouts for diverse scenes characterized by varying number of visible shelves in an image, large range in shelf occupancy factor and varied background clutter. Given the extreme paucity of datasets in this space and the difficulty involved in acquiring real data from warehouses, we additionally release a flexible synthetic dataset generation pipeline WareSynth which allows users to control the generation process and tailor the dataset according to contingent application. The ablations across architectural variants and comparison with strong prior baselines vindicate the efficacy of RackLay as an apt architecture for the novel problem of multi-layered layout estimation. We also show that fusing the top-view and front-view enables 3D reasoning applications such as metric free space estimation for the considered rack.
RoRD: Rotation-Robust Descriptors and Orthographic Views for Local Feature Matching
Mar 15, 2021


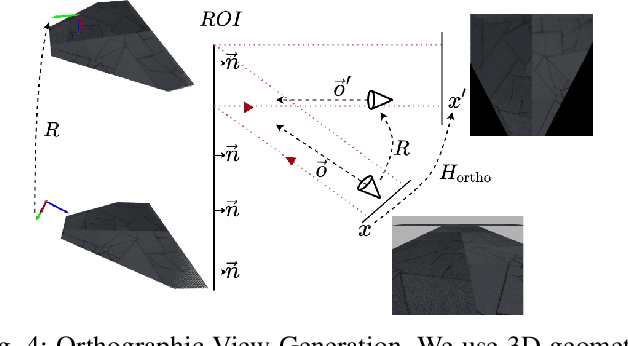
The use of local detectors and descriptors in typical computer vision pipelines work well until variations in viewpoint and appearance change become extreme. Past research in this area has typically focused on one of two approaches to this challenge: the use of projections into spaces more suitable for feature matching under extreme viewpoint changes, and attempting to learn features that are inherently more robust to viewpoint change. In this paper, we present a novel framework that combines learning of invariant descriptors through data augmentation and orthographic viewpoint projection. We propose rotation-robust local descriptors, learnt through training data augmentation based on rotation homographies, and a correspondence ensemble technique that combines vanilla feature correspondences with those obtained through rotation-robust features. Using a range of benchmark datasets as well as contributing a new bespoke dataset for this research domain, we evaluate the effectiveness of the proposed approach on key tasks including pose estimation and visual place recognition. Our system outperforms a range of baseline and state-of-the-art techniques, including enabling higher levels of place recognition precision across opposing place viewpoints and achieves practically-useful performance levels even under extreme viewpoint changes.
DRACO: Weakly Supervised Dense Reconstruction And Canonicalization of Objects
Nov 25, 2020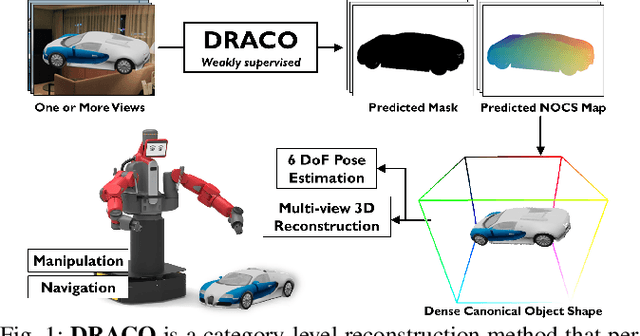
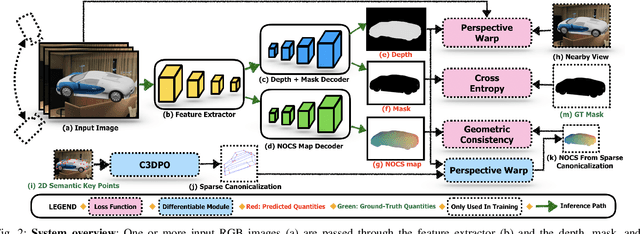
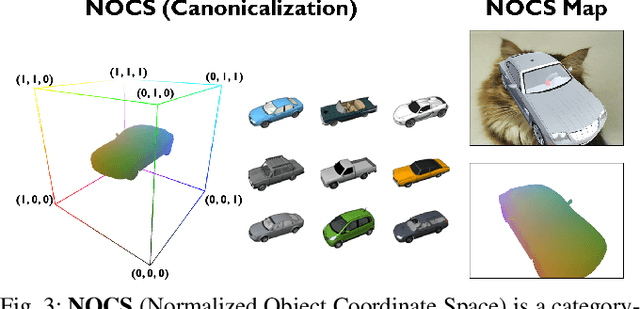

We present DRACO, a method for Dense Reconstruction And Canonicalization of Object shape from one or more RGB images. Canonical shape reconstruction, estimating 3D object shape in a coordinate space canonicalized for scale, rotation, and translation parameters, is an emerging paradigm that holds promise for a multitude of robotic applications. Prior approaches either rely on painstakingly gathered dense 3D supervision, or produce only sparse canonical representations, limiting real-world applicability. DRACO performs dense canonicalization using only weak supervision in the form of camera poses and semantic keypoints at train time. During inference, DRACO predicts dense object-centric depth maps in a canonical coordinate-space, solely using one or more RGB images of an object. Extensive experiments on canonical shape reconstruction and pose estimation show that DRACO is competitive or superior to fully-supervised methods.
BirdSLAM: Monocular Multibody SLAM in Bird's-Eye View
Nov 15, 2020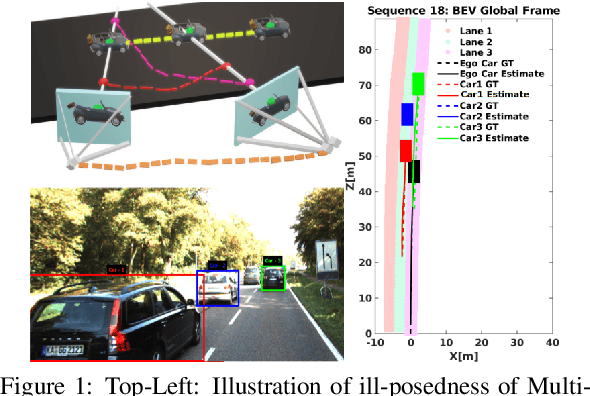
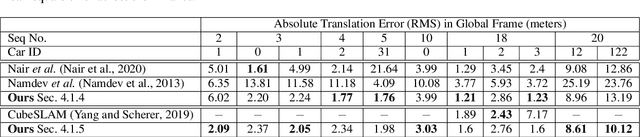
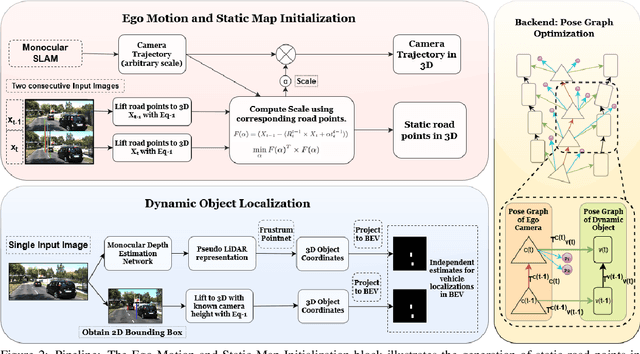
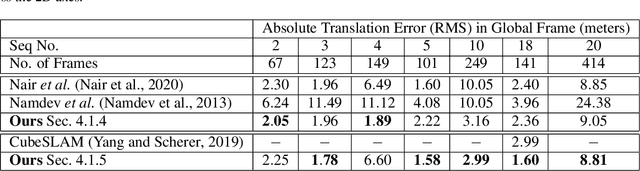
In this paper, we present BirdSLAM, a novel simultaneous localization and mapping (SLAM) system for the challenging scenario of autonomous driving platforms equipped with only a monocular camera. BirdSLAM tackles challenges faced by other monocular SLAM systems (such as scale ambiguity in monocular reconstruction, dynamic object localization, and uncertainty in feature representation) by using an orthographic (bird's-eye) view as the configuration space in which localization and mapping are performed. By assuming only the height of the ego-camera above the ground, BirdSLAM leverages single-view metrology cues to accurately localize the ego-vehicle and all other traffic participants in bird's-eye view. We demonstrate that our system outperforms prior work that uses strictly greater information, and highlight the relevance of each design decision via an ablation analysis.
Fast Adaptation of Manipulator Trajectories to Task Perturbation By Differentiating through the Optimal Solution
Nov 01, 2020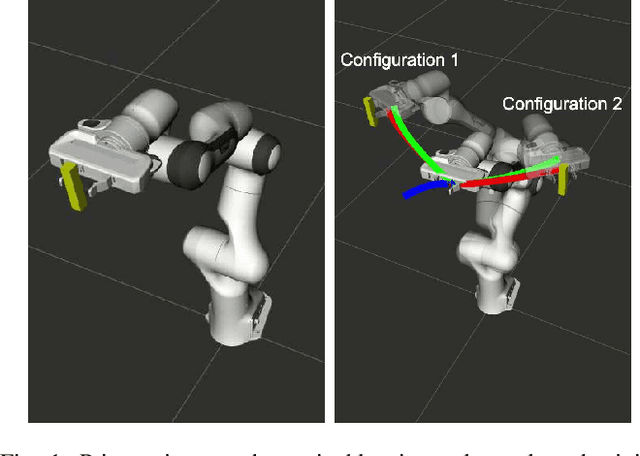
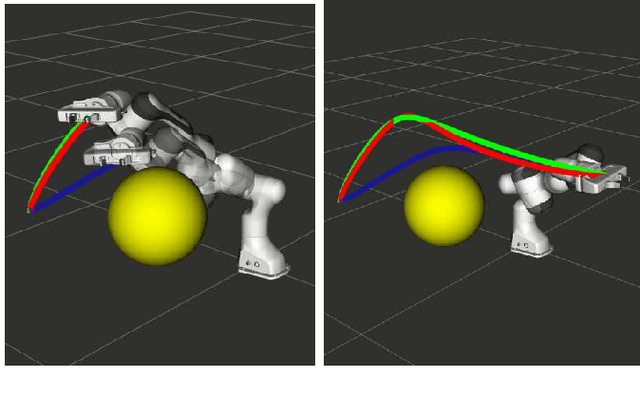
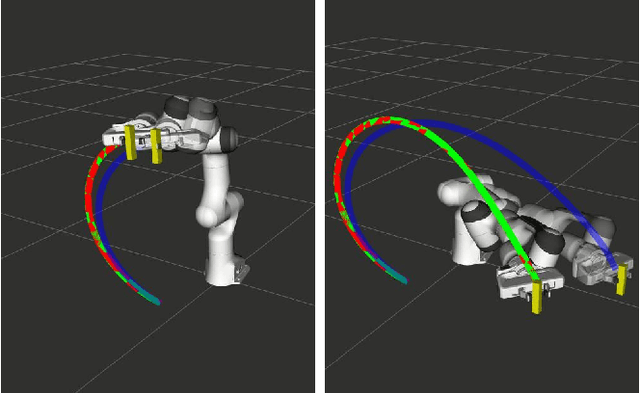
Joint space trajectory optimization under end-effector task constraints leads to a challenging non-convex problem. Thus, a real-time adaptation of prior computed trajectories to perturbation in task constraints often becomes intractable. Existing works use the so-called warm-starting of trajectory optimization to improve computational performance. We present a fundamentally different approach that relies on deriving analytical gradients of the optimal solution with respect to the task constraint parameters. This gradient map characterizes the direction in which the prior computed joint trajectories need to be deformed to comply with the new task constraints. Subsequently, we develop an iterative line-search algorithm for computing the scale of deformation. Our algorithm provides near real-time adaptation of joint trajectories for a diverse class of task perturbations such as (i) changes in initial and final joint configurations of end-effector orientation-constrained trajectories and (ii) changes in end-effector goal or way-points under end-effector orientation constraints. We relate each of these examples to real-world applications ranging from learning from demonstration to obstacle avoidance. We also show that our algorithm produces trajectories with quality similar to what one would obtain by solving the trajectory optimization from scratch with warm-start initialization. But most importantly, our algorithm achieves a worst-case speed-up of 160x over the latter approach.
Early Bird: Loop Closures from Opposing Viewpoints for Perceptually-Aliased Indoor Environments
Oct 03, 2020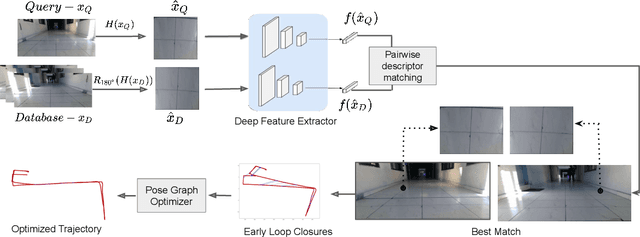


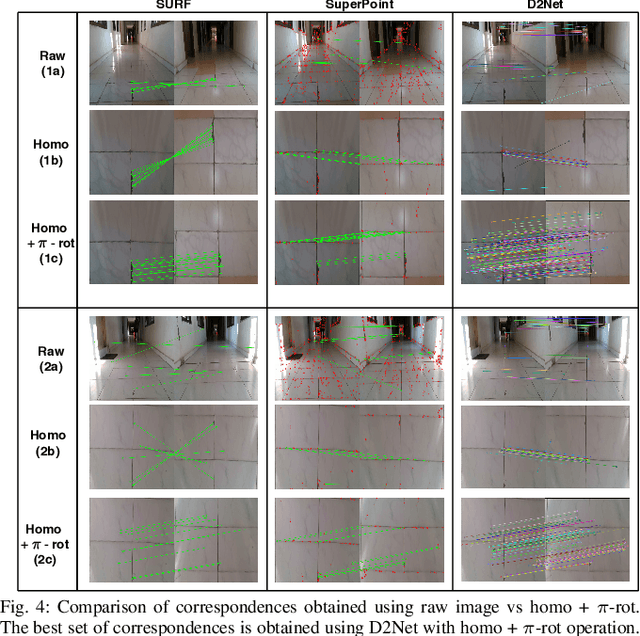
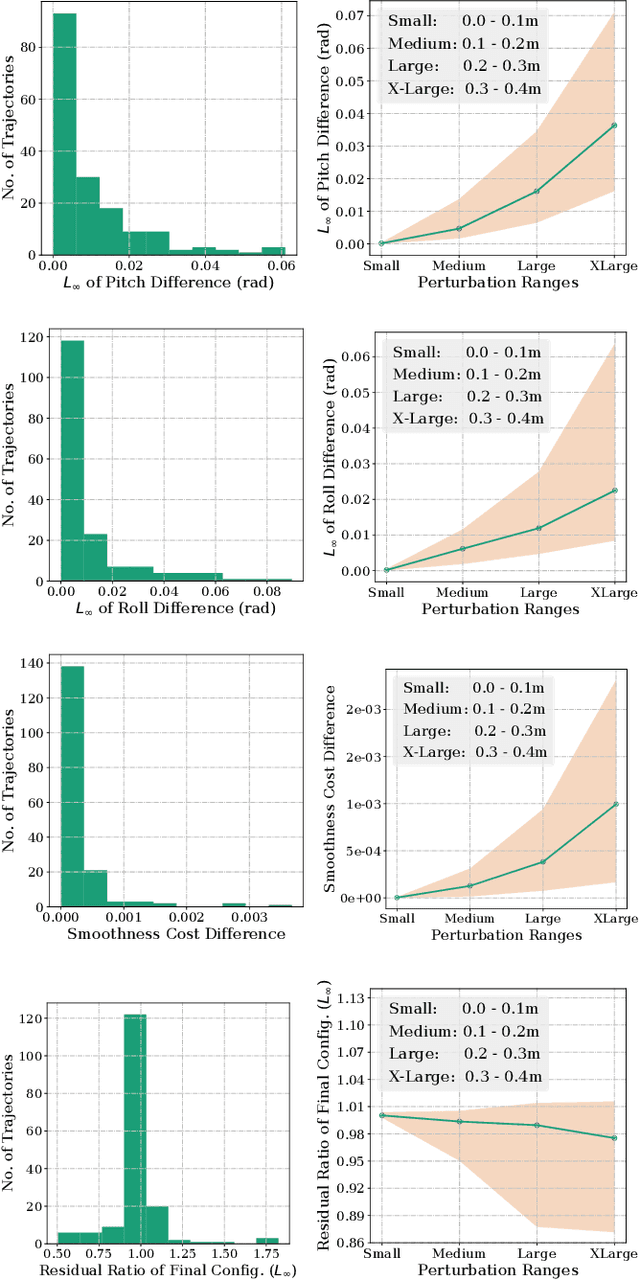
Significant advances have been made recently in Visual Place Recognition (VPR), feature correspondence, and localization due to the proliferation of deep-learning-based methods. However, existing approaches tend to address, partially or fully, only one of two key challenges: viewpoint change and perceptual aliasing. In this paper, we present novel research that simultaneously addresses both challenges by combining deep-learned features with geometric transformations based on reasonable domain assumptions about navigation on a ground-plane, whilst also removing the requirement for specialized hardware setup (e.g. lighting, downwards facing cameras). In particular, our integration of VPR with SLAM by leveraging the robustness of deep-learned features and our homography-based extreme viewpoint invariance significantly boosts the performance of VPR, feature correspondence, and pose graph submodules of the SLAM pipeline. For the first time, we demonstrate a localization system capable of state-of-the-art performance despite perceptual aliasing and extreme 180-degree-rotated viewpoint change in a range of real-world and simulated experiments. Our system is able to achieve early loop closures that prevent significant drifts in SLAM trajectories. We also compare extensively several deep architectures for VPR and descriptor matching. We also show that superior place recognition and descriptor matching across opposite views results in a similar performance gain in back-end pose graph optimization.
Cosine meets Softmax: A tough-to-beat baseline for visual grounding
Sep 13, 2020
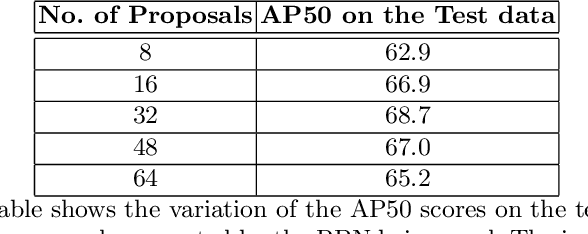

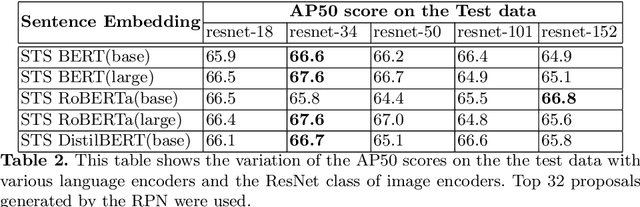
In this paper, we present a simple baseline for visual grounding for autonomous driving which outperforms the state of the art methods, while retaining minimal design choices. Our framework minimizes the cross-entropy loss over the cosine distance between multiple image ROI features with a text embedding (representing the give sentence/phrase). We use pre-trained networks for obtaining the initial embeddings and learn a transformation layer on top of the text embedding. We perform experiments on the Talk2Car dataset and achieve 68.7% AP50 accuracy, improving upon the previous state of the art by 8.6%. Our investigation suggests reconsideration towards more approaches employing sophisticated attention mechanisms or multi-stage reasoning or complex metric learning loss functions by showing promise in simpler alternatives.
Student Mixture Model Based Visual Servoing
Jun 19, 2020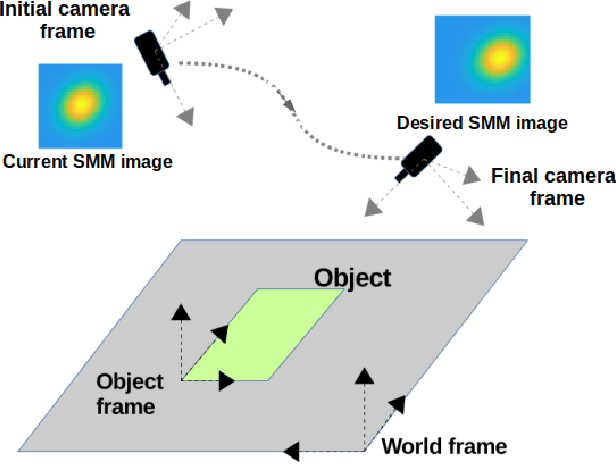
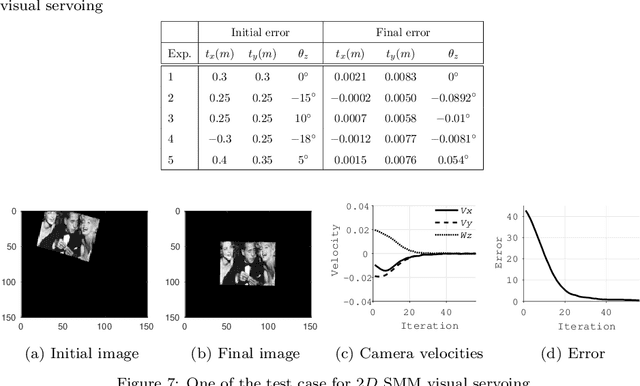
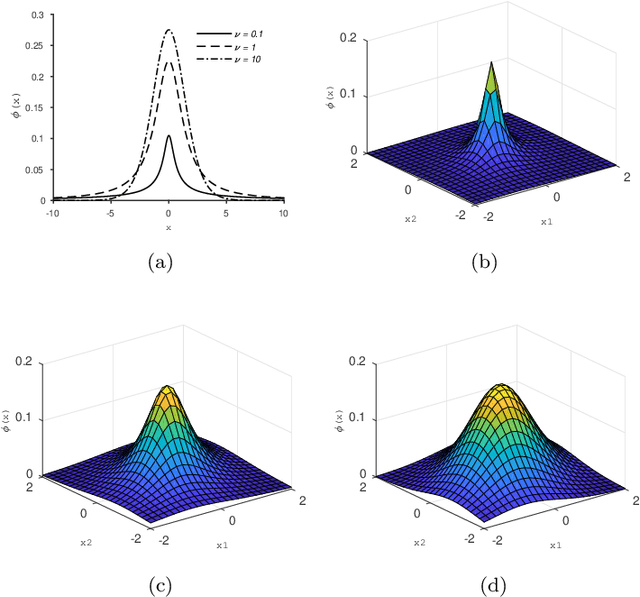
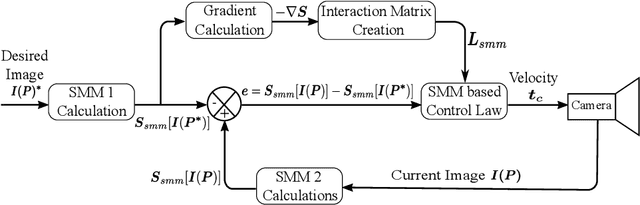
Classical Image-Based Visual Servoing (IBVS) makes use of geometric image features like point, straight line and image moments to control a robotic system. Robust extraction and real-time tracking of these features are crucial to the performance of the IBVS. Moreover, such features can be unsuitable for real world applications where it might not be easy to distinguish a target from the rest of the environment. Alternatively, an approach based on complete photometric data can avoid the requirement of feature extraction, tracking and object detection. In this work, we propose one such probabilistic model based approach which uses entire photometric data for the purpose of visual servoing. A novel image modelling method has been proposed using Student Mixture Model (SMM), which is based on Multivariate Student's t-Distribution. Consequently, a vision-based control law is formulated as a least squares minimisation problem. Efficacy of the proposed framework is demonstrated for 2D and 3D positioning tasks showing favourable error convergence and acceptable camera trajectories. Numerical experiments are also carried out to show robustness to distinct image scenes and partial occlusion.
SROM: Simple Real-time Odometry and Mapping using LiDAR data for Autonomous Vehicles
May 07, 2020
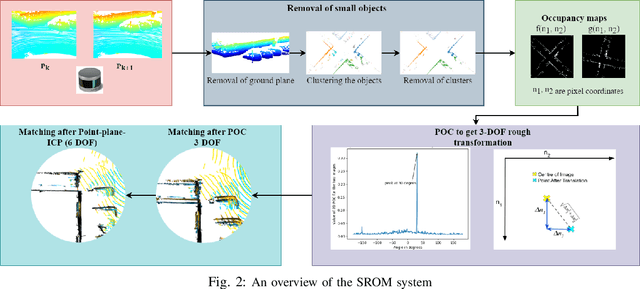
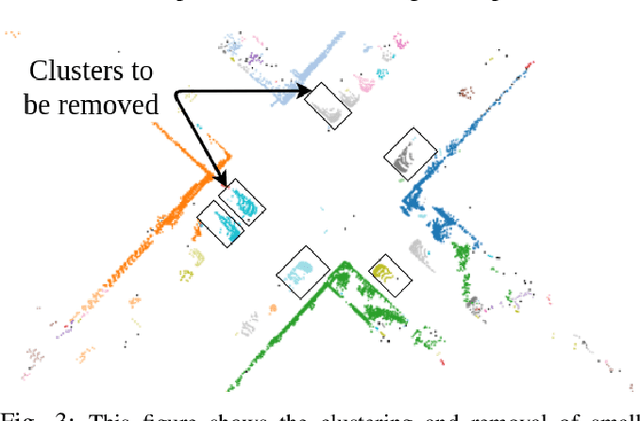

In this paper, we present SROM, a novel real-time Simultaneous Localization and Mapping (SLAM) system for autonomous vehicles. The keynote of the paper showcases SROM's ability to maintain localization at low sampling rates or at high linear or angular velocities where most popular LiDAR based localization approaches get degraded fast. We also demonstrate SROM to be computationally efficient and capable of handling high-speed maneuvers. It also achieves low drifts without the need for any other sensors like IMU and/or GPS. Our method has a two-layer structure wherein first, an approximate estimate of the rotation angle and translation parameters are calculated using a Phase Only Correlation (POC) method. Next, we use this estimate as an initialization for a point-to-plane ICP algorithm to obtain fine matching and registration. Another key feature of the proposed algorithm is the removal of dynamic objects before matching the scans. This improves the performance of our system as the dynamic objects can corrupt the matching scheme and derail localization. Our SLAM system can build reliable maps at the same time generating high-quality odometry. We exhaustively evaluated the proposed method in many challenging highways/country/urban sequences from the KITTI dataset and the results demonstrate better accuracy in comparisons to other state-of-the-art methods with reduced computational expense aiding in real-time realizations. We have also integrated our SROM system with our in-house autonomous vehicle and compared it with the state-of-the-art methods like LOAM and LeGO-LOAM.
Reconstruct, Rasterize and Backprop: Dense shape and pose estimation from a single image
Apr 25, 2020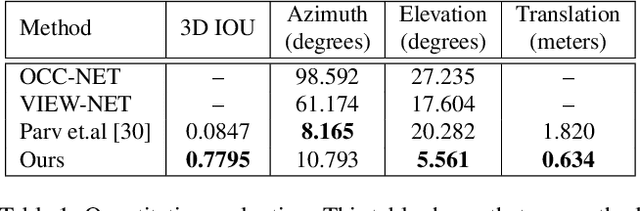

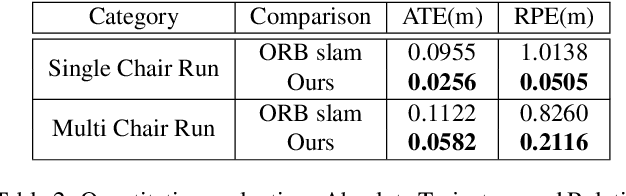

This paper presents a new system to obtain dense object reconstructions along with 6-DoF poses from a single image. Geared towards high fidelity reconstruction, several recent approaches leverage implicit surface representations and deep neural networks to estimate a 3D mesh of an object, given a single image. However, all such approaches recover only the shape of an object; the reconstruction is often in a canonical frame, unsuitable for downstream robotics tasks. To this end, we leverage recent advances in differentiable rendering (in particular, rasterization) to close the loop with 3D reconstruction in camera frame. We demonstrate that our approach---dubbed reconstruct, rasterize and backprop (RRB) achieves significantly lower pose estimation errors compared to prior art, and is able to recover dense object shapes and poses from imagery. We further extend our results to an (offline) setup, where we demonstrate a dense monocular object-centric egomotion estimation system.