 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymmetric Volume Maps
Feb 05, 2022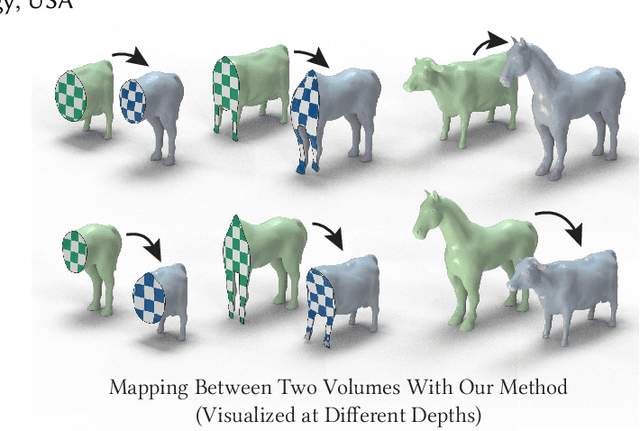

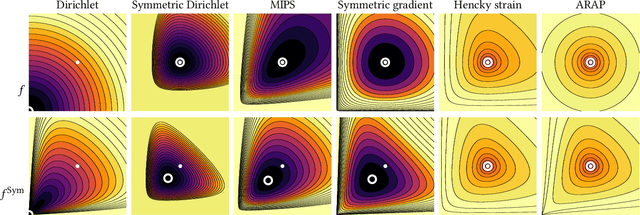
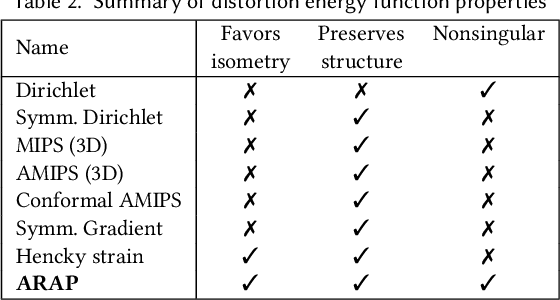
Although shape correspondence is a central problem in geometry processing, most methods for this task apply only to two-dimensional surfaces. The neglected task of volumetric correspondence--a natural extension relevant to shapes extracted from simulation, medical imaging, volume rendering, and even improving surface maps of boundary representations--presents unique challenges that do not appear in the two-dimensional case. In this work, we propose a method for mapping between volumes represented as tetrahedral meshes. Our formulation minimizes a distortion energy designed to extract maps symmetrically, i.e., without dependence on the ordering of the source and target domains. We accompany our method with theoretical discussion describing the consequences of this symmetry assumption, leading us to select a symmetrized ARAP energy that favors isometric correspondences. Our final formulation optimizes for near-isometry while matching the boundary. We demonstrate our method on a diverse geometric dataset, producing low-distortion matchings that align to the boundary.
Log-Euclidean Signatures for Intrinsic Distances Between Unaligned Datasets
Feb 03, 2022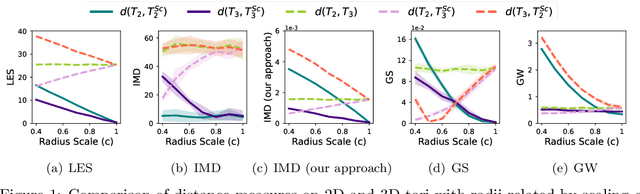

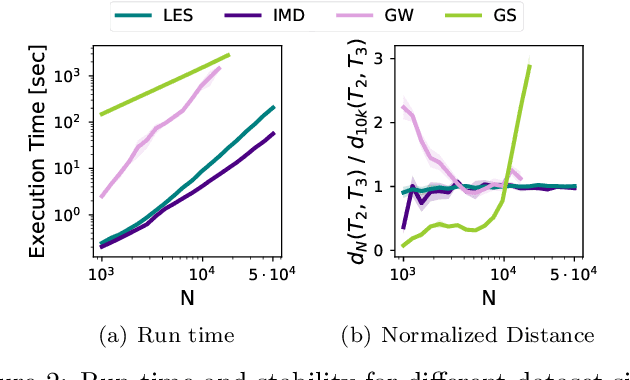

The need for efficiently comparing and representing datasets with unknown alignment spans various fields, from model analysis and comparison in machine learning to trend discovery in collections of medical datasets. We use manifold learning to compare the intrinsic geometric structures of different datasets by comparing their diffusion operators, symmetric positive-definite (SPD) matrices that relate to approximations of the continuous Laplace-Beltrami operator from discrete samples. Existing methods typically compare such operators in a pointwise manner or assume known data alignment. Instead, we exploit the Riemannian geometry of SPD matrices to compare these operators and define a new theoretically-motivated distance based on a lower bound of the log-Euclidean metric. Our framework facilitates comparison of data manifolds expressed in datasets with different sizes, numbers of features, and measurement modalities. Our log-Euclidean signature (LES) distance recovers meaningful structural differences, outperforming competing methods in various application domains.
Rewiring with Positional Encodings for Graph Neural Networks
Feb 02, 2022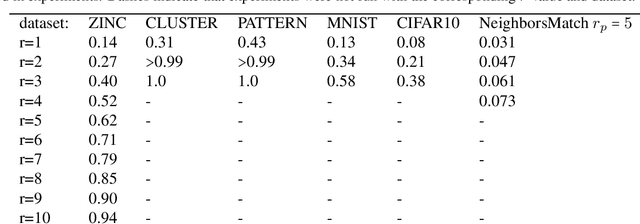
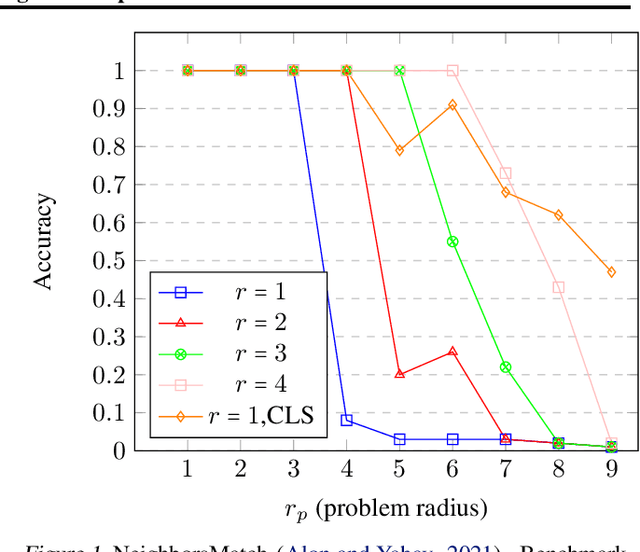
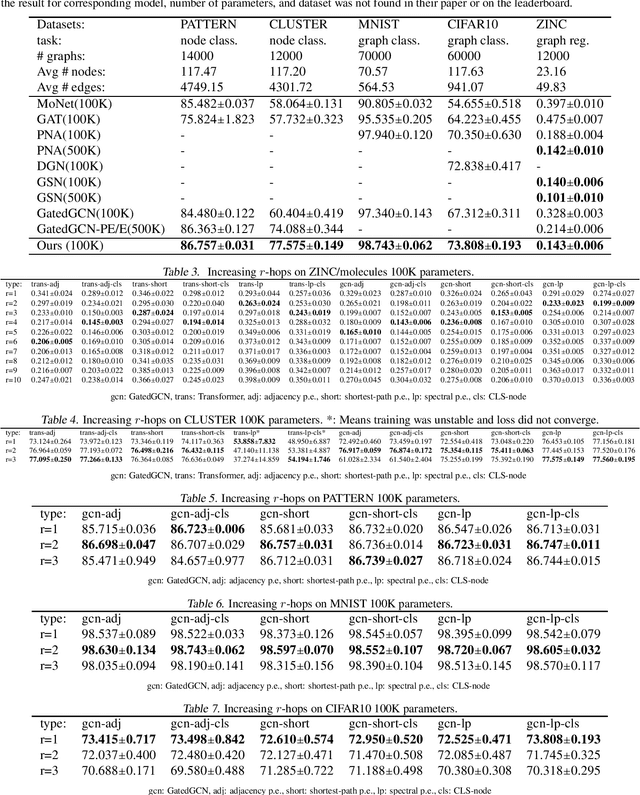
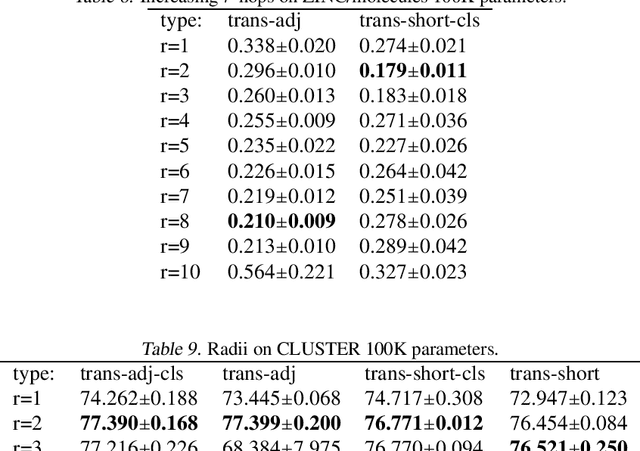
Several recent works use positional encodings to extend the receptive fields of graph neural network (GNN) layers equipped with attention mechanisms. These techniques, however, extend receptive fields to the complete graph, at substantial computational cost and risking a change in the inductive biases of conventional GNNs, or require complex architecture adjustments. As a conservative alternative, we use positional encodings to expand receptive fields to any r-ring. Our method augments the input graph with additional nodes/edges and uses positional encodings as node and/or edge features. Thus, it is compatible with many existing GNN architectures. We also provide examples of positional encodings that are non-invasive, i.e., there is a one-to-one map between the original and the modified graphs. Our experiments demonstrate that extending receptive fields via positional encodings and a virtual fully-connected node significantly improves GNN performance and alleviates over-squashing using small r. We obtain improvements across models, showing state-of-the-art performance even using older architectures than recent Transformer models adapted to graphs.
Learning Proximal Operators to Discover Multiple Optima
Jan 28, 2022

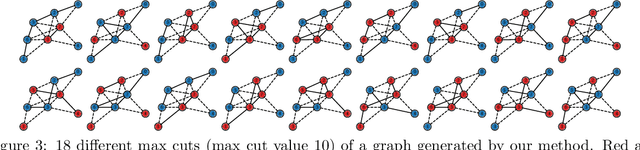
Finding multiple solutions of non-convex optimization problems is a ubiquitous yet challenging task. Typical existing solutions either apply single-solution optimization methods from multiple random initial guesses or search in the vicinity of found solutions using ad hoc heuristics. We present an end-to-end method to learn the proximal operator across a family of non-convex problems, which can then be used to recover multiple solutions for unseen problems at test time. Our method only requires access to the objectives without needing the supervision of ground truth solutions. Notably, the added proximal regularization term elevates the convexity of our formulation: by applying recent theoretical results, we show that for weakly-convex objectives and under mild regularity conditions, training of the proximal operator converges globally in the over-parameterized setting. We further present a benchmark for multi-solution optimization including a wide range of applications and evaluate our method to demonstrate its effectiveness.
Wassersplines for Stylized Neural Animation
Jan 28, 2022
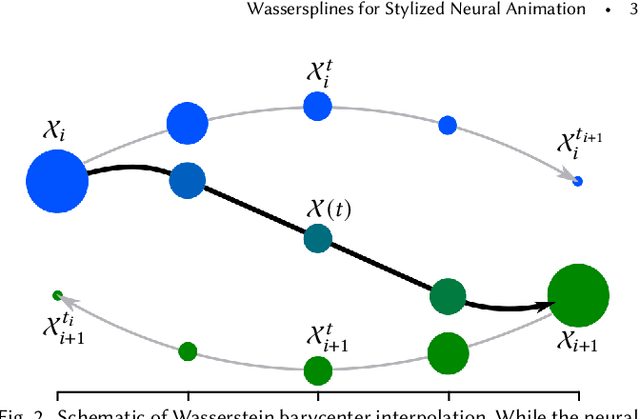
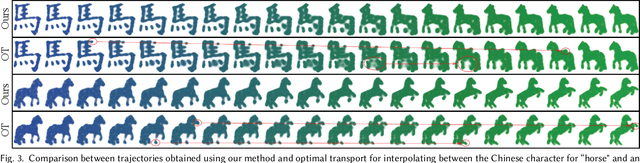
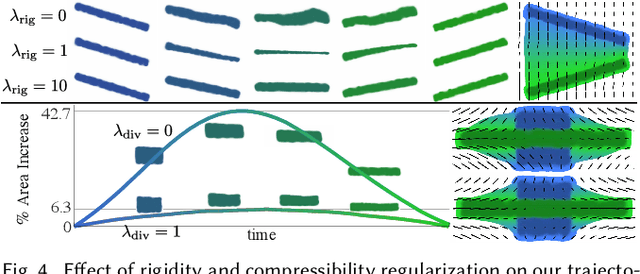
Much of computer-generated animation is created by manipulating meshes with rigs. While this approach works well for animating articulated objects like animals, it has limited flexibility for animating less structured creatures such as the Drunn in "Raya and the Last Dragon." We introduce Wassersplines, a novel trajectory inference method for animating unstructured densities based on recent advances in continuous normalizing flows and optimal transport. The key idea is to train a neurally-parameterized velocity field that represents the motion between keyframes. Trajectories are then computed by pushing keyframes through the velocity field. We solve an additional Wasserstein barycenter interpolation problem to guarantee strict adherence to keyframes. Our tool can stylize trajectories through a variety of PDE-based regularizers to create different visual effects. We demonstrate our tool on various keyframe interpolation problems to produce temporally-coherent animations without meshing or rigging.
DeepCurrents: Learning Implicit Representations of Shapes with Boundaries
Nov 17, 2021
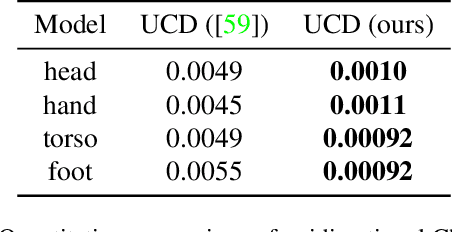
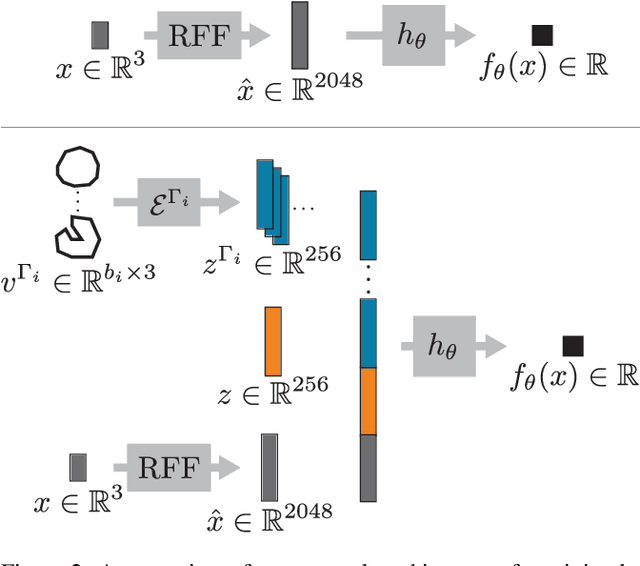
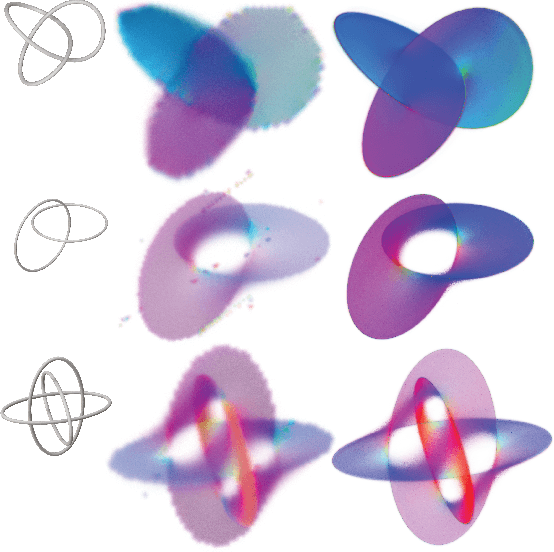
Recent techniques have been successful in reconstructing surfaces as level sets of learned functions (such as signed distance fields) parameterized by deep neural networks. Many of these methods, however, learn only closed surfaces and are unable to reconstruct shapes with boundary curves. We propose a hybrid shape representation that combines explicit boundary curves with implicit learned interiors. Using machinery from geometric measure theory, we parameterize currents using deep networks and use stochastic gradient descent to solve a minimal surface problem. By modifying the metric according to target geometry coming, e.g., from a mesh or point cloud, we can use this approach to represent arbitrary surfaces, learning implicitly defined shapes with explicitly defined boundary curves. We further demonstrate learning families of shapes jointly parameterized by boundary curves and latent codes.
Volumetric Parameterization of the Placenta to a Flattened Template
Nov 15, 2021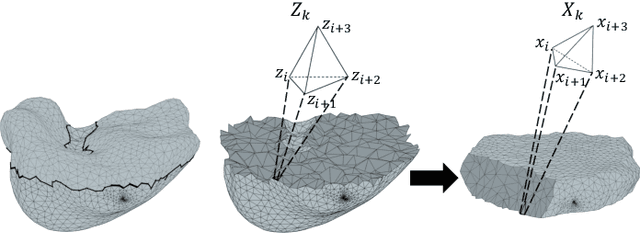

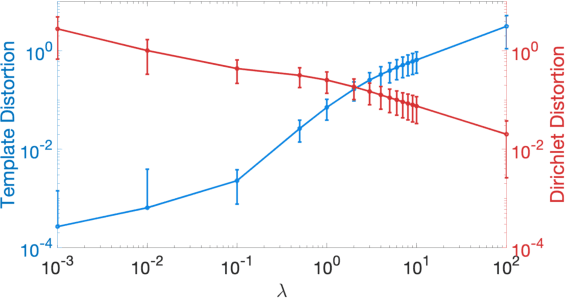
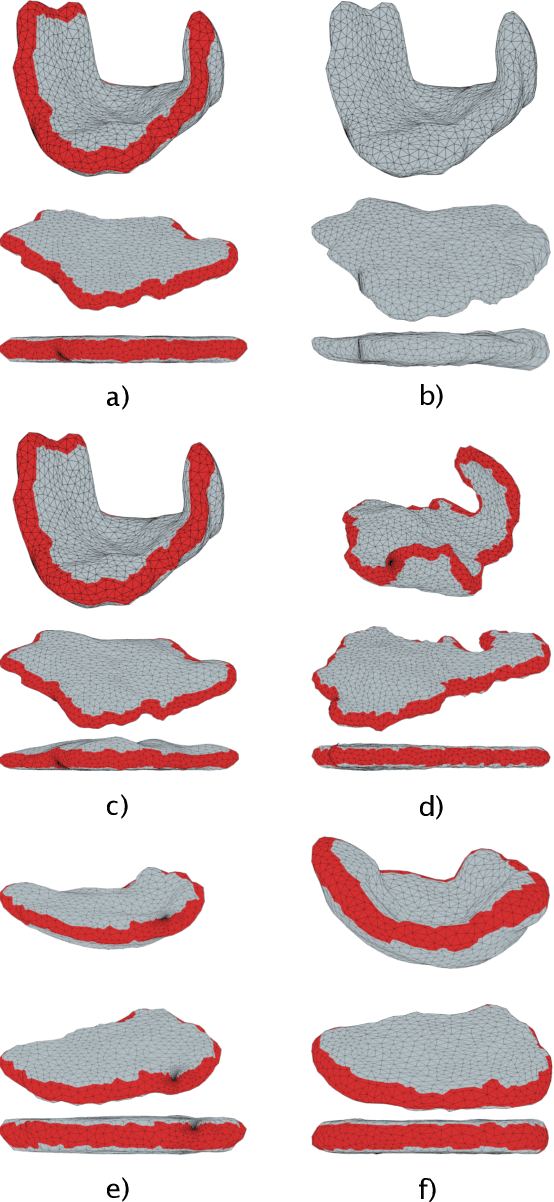
We present a volumetric mesh-based algorithm for parameterizing the placenta to a flattened template to enable effective visualization of local anatomy and function. MRI shows potential as a research tool as it provides signals directly related to placental function. However, due to the curved and highly variable in vivo shape of the placenta, interpreting and visualizing these images is difficult. We address interpretation challenges by mapping the placenta so that it resembles the familiar ex vivo shape. We formulate the parameterization as an optimization problem for mapping the placental shape represented by a volumetric mesh to a flattened template. We employ the symmetric Dirichlet energy to control local distortion throughout the volume. Local injectivity in the mapping is enforced by a constrained line search during the gradient descent optimization. We validate our method using a research study of 111 placental shapes extracted from BOLD MRI images. Our mapping achieves sub-voxel accuracy in matching the template while maintaining low distortion throughout the volume. We demonstrate how the resulting flattening of the placenta improves visualization of anatomy and function. Our code is freely available at https://github.com/mabulnaga/placenta-flattening .
Object DGCNN: 3D Object Detection using Dynamic Graphs
Oct 13, 2021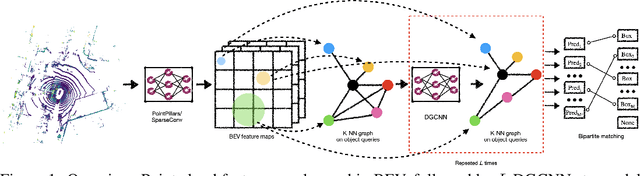
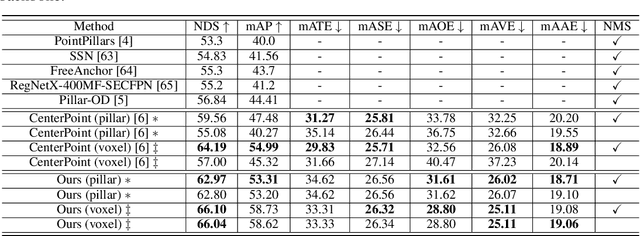
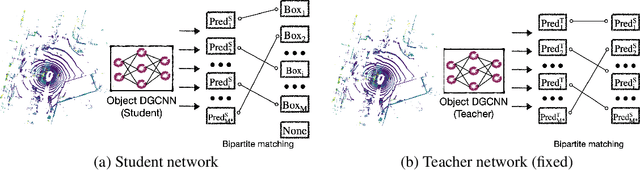

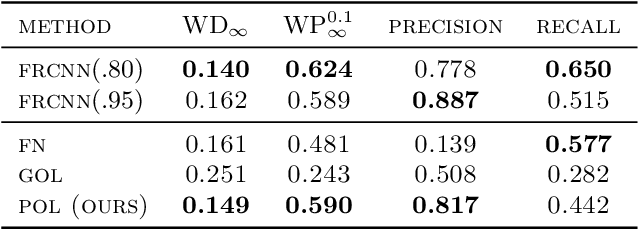
3D object detection often involves complicated training and testing pipelines, which require substantial domain knowledge about individual datasets. Inspired by recent non-maximum suppression-free 2D object detection models, we propose a 3D object detection architecture on point clouds. Our method models 3D object detection as message passing on a dynamic graph, generalizing the DGCNN framework to predict a set of objects. In our construction, we remove the necessity of post-processing via object confidence aggregation or non-maximum suppression. To facilitate object detection from sparse point clouds, we also propose a set-to-set distillation approach customized to 3D detection. This approach aligns the outputs of the teacher model and the student model in a permutation-invariant fashion, significantly simplifying knowledge distillation for the 3D detection task. Our method achieves state-of-the-art performance on autonomous driving benchmarks. We also provide abundant analysis of the detection model and distillation framework.
DETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queries
Oct 13, 2021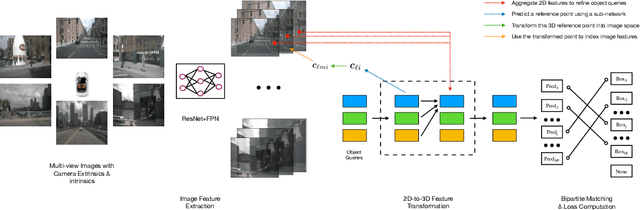
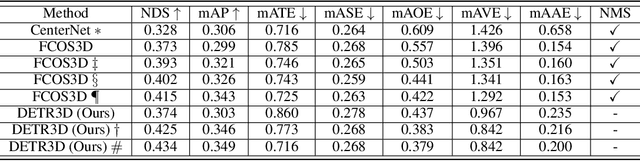
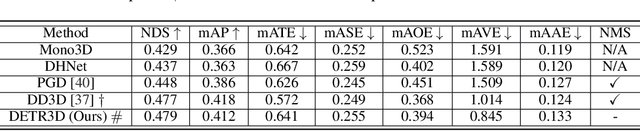
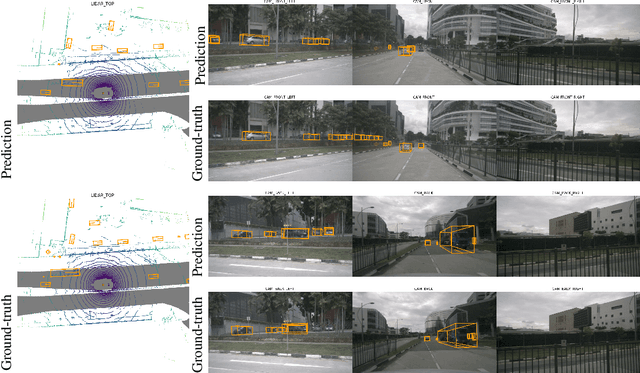
We introduce a framework for multi-camera 3D object detection. In contrast to existing works, which estimate 3D bounding boxes directly from monocular images or use depth prediction networks to generate input for 3D object detection from 2D information, our method manipulates predictions directly in 3D space. Our architecture extracts 2D features from multiple camera images and then uses a sparse set of 3D object queries to index into these 2D features, linking 3D positions to multi-view images using camera transformation matrices. Finally, our model makes a bounding box prediction per object query, using a set-to-set loss to measure the discrepancy between the ground-truth and the prediction. This top-down approach outperforms its bottom-up counterpart in which object bounding box prediction follows per-pixel depth estimation, since it does not suffer from the compounding error introduced by a depth prediction model. Moreover, our method does not require post-processing such as non-maximum suppression, dramatically improving inference speed. We achieve state-of-the-art performance on the nuScenes autonomous driving benchmark.
k-Mixup Regularization for Deep Learning via Optimal Transport
Jun 05, 2021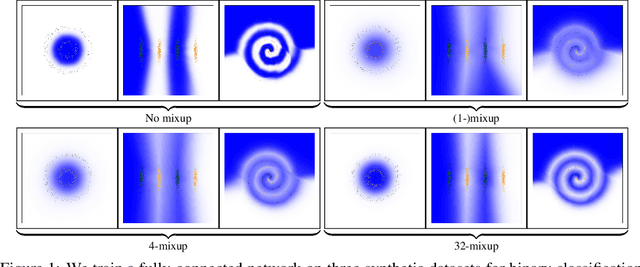
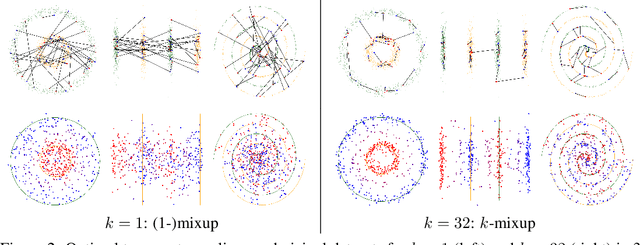

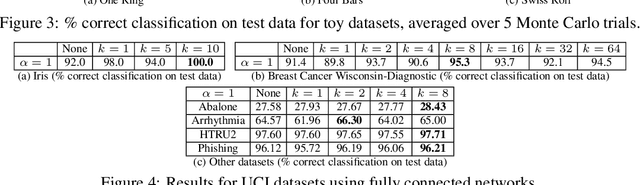
Mixup is a popular regularization technique for training deep neural networks that can improve generalization and increase adversarial robustness. It perturbs input training data in the direction of other randomly-chosen instances in the training set. To better leverage the structure of the data, we extend mixup to \emph{$k$-mixup} by perturbing $k$-batches of training points in the direction of other $k$-batches using displacement interpolation, interpolation under the Wasserstein metric. We demonstrate theoretically and in simulations that $k$-mixup preserves cluster and manifold structures, and we extend theory studying efficacy of standard mixup. Our empirical results show that training with $k$-mixup further improves generalization and robustness on benchmark datasets.