 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Agnostic Graph Regularization for Few-Shot Learning
Feb 14, 2021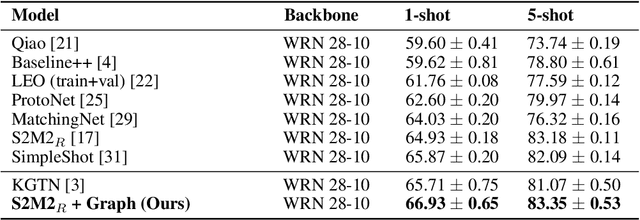
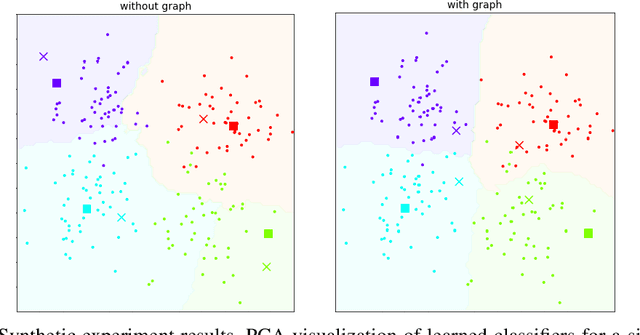
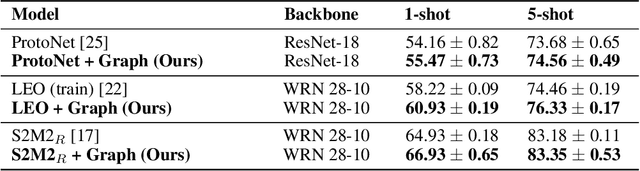
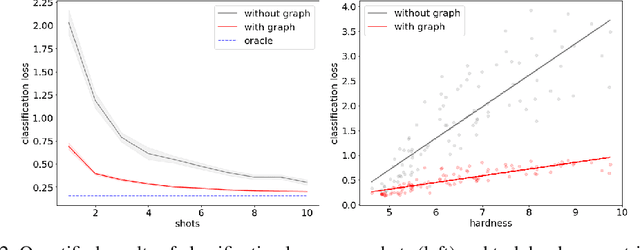
In many domains, relationships between categories are encoded in the knowledge graph. Recently, promising results have been achieved by incorporating knowledge graph as side information in hard classification tasks with severely limited data. However, prior models consist of highly complex architectures with many sub-components that all seem to impact performance. In this paper, we present a comprehensive empirical study on graph embedded few-shot learning. We introduce a graph regularization approach that allows a deeper understanding of the impact of incorporating graph information between labels. Our proposed regularization is widely applicable and model-agnostic, and boosts the performance of any few-shot learning model, including fine-tuning, metric-based, and optimization-based meta-learning. Our approach improves the performance of strong base learners by up to 2% on Mini-ImageNet and 6.7% on ImageNet-FS, outperforming state-of-the-art graph embedded methods. Additional analyses reveal that graph regularizing models result in a lower loss for more difficult tasks, such as those with fewer shots and less informative support examples.
Driver2vec: Driver Identification from Automotive Data
Feb 10, 2021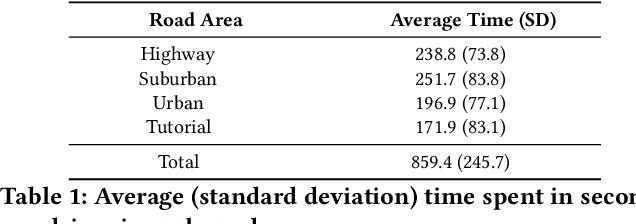
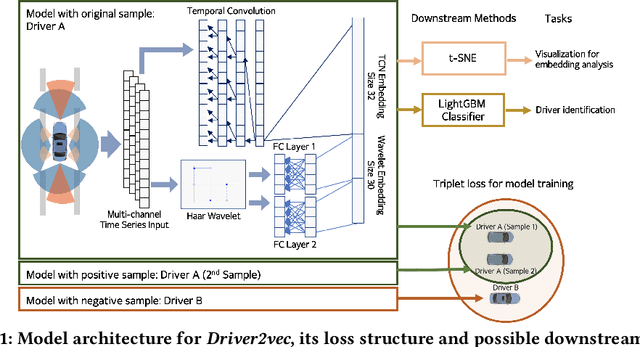


With increasing focus on privacy protection, alternative methods to identify vehicle operator without the use of biometric identifiers have gained traction for automotive data analysis. The wide variety of sensors installed on modern vehicles enable autonomous driving, reduce accidents and improve vehicle handling. On the other hand, the data these sensors collect reflect drivers' habit. Drivers' use of turn indicators, following distance, rate of acceleration, etc. can be transformed to an embedding that is representative of their behavior and identity. In this paper, we develop a deep learning architecture (Driver2vec) to map a short interval of driving data into an embedding space that represents the driver's behavior to assist in driver identification. We develop a custom model that leverages performance gains of temporal convolutional networks, embedding separation power of triplet loss and classification accuracy of gradient boosting decision trees. Trained on a dataset of 51 drivers provided by Nervtech, Driver2vec is able to accurately identify the driver from a short 10-second interval of sensor data, achieving an average pairwise driver identification accuracy of 83.1% from this 10-second interval, which is remarkably higher than performance obtained in previous studies. We then analyzed performance of Driver2vec to show that its performance is consistent across scenarios and that modeling choices are sound.
Open-World Semi-Supervised Learning
Feb 06, 2021
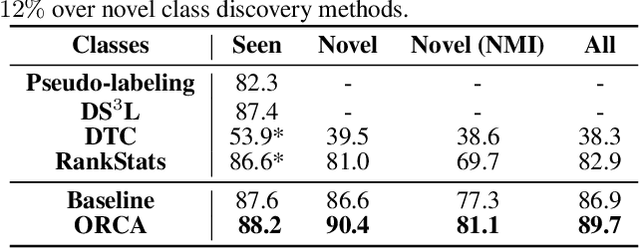
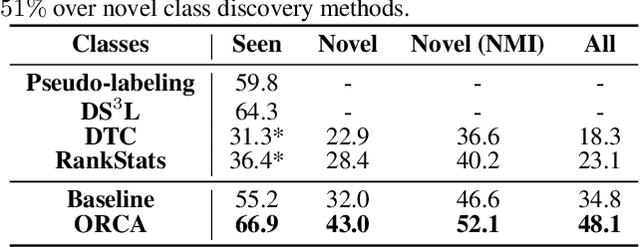
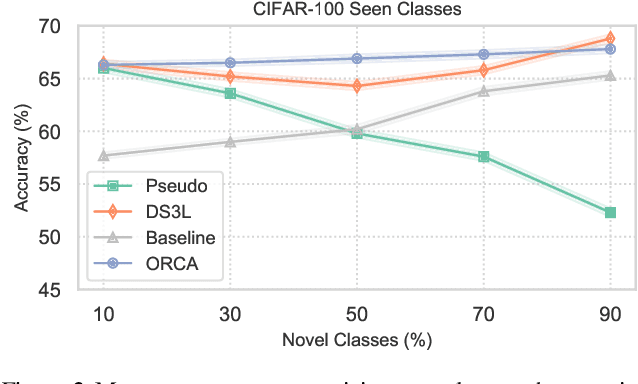
Supervised and semi-supervised learning methods have been traditionally designed for the closed-world setting based on the assumption that unlabeled test data contains only classes previously encountered in the labeled training data. However, the real world is inherently open and dynamic, and thus novel, previously unseen classes may appear in the test data or during the model deployment. Here, we introduce a new open-world semi-supervised learning setting in which the model is required to recognize previously seen classes, as well as to discover novel classes never seen in the labeled dataset. To tackle the problem, we propose ORCA, an approach that learns to simultaneously classify and cluster the data. ORCA classifies examples from the unlabeled dataset to previously seen classes, or forms a novel class by grouping similar examples together. The key idea in ORCA is in introducing uncertainty based adaptive margin that effectively circumvents the bias caused by the imbalance of variance between seen and novel classes/clusters. We demonstrate that ORCA accurately discovers novel classes and assigns samples to previously seen classes on benchmark image classification datasets, including CIFAR and ImageNet. Remarkably, despite solving the harder task ORCA outperforms semi-supervised methods on seen classes, as well as novel class discovery methods on novel classes, achieving 7% and 151% improvements on seen and novel classes in the ImageNet dataset.
Identity-aware Graph Neural Networks
Feb 05, 2021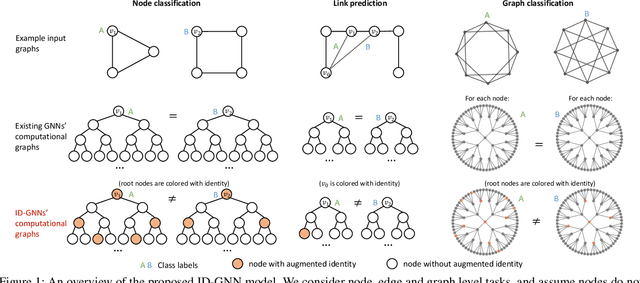

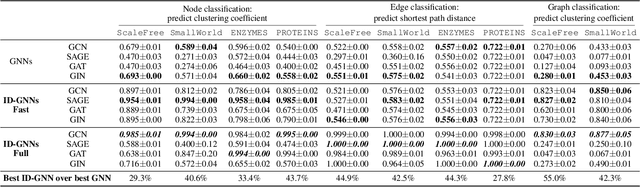
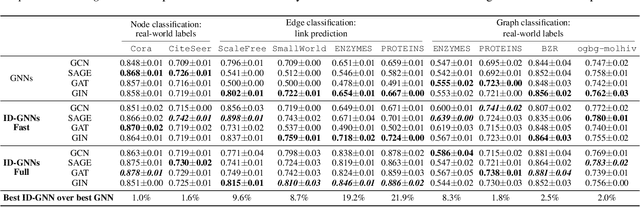
Message passing Graph Neural Networks (GNNs) provide a powerful modeling framework for relational data. However, the expressive power of existing GNNs is upper-bounded by the 1-Weisfeiler-Lehman (1-WL) graph isomorphism test, which means GNNs that are not able to predict node clustering coefficients and shortest path distances, and cannot differentiate between different d-regular graphs. Here we develop a class of message passing GNNs, named Identity-aware Graph Neural Networks (ID-GNNs), with greater expressive power than the 1-WL test. ID-GNN offers a minimal but powerful solution to limitations of existing GNNs. ID-GNN extends existing GNN architectures by inductively considering nodes' identities during message passing. To embed a given node, ID-GNN first extracts the ego network centered at the node, then conducts rounds of heterogeneous message passing, where different sets of parameters are applied to the center node than to other surrounding nodes in the ego network. We further propose a simplified but faster version of ID-GNN that injects node identity information as augmented node features. Altogether, both versions of ID-GNN represent general extensions of message passing GNNs, where experiments show that transforming existing GNNs to ID-GNNs yields on average 40% accuracy improvement on challenging node, edge, and graph property prediction tasks; 3% accuracy improvement on node and graph classification benchmarks; and 15% ROC AUC improvement on real-world link prediction tasks. Additionally, ID-GNNs demonstrate improved or comparable performance over other task-specific graph networks.
Inductive Representation Learning in Temporal Networks via Causal Anonymous Walks
Jan 15, 2021

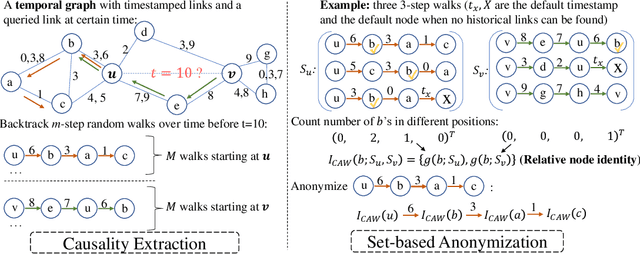
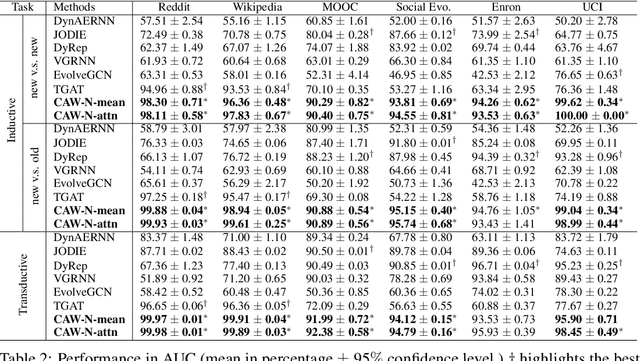
Temporal networks serve as abstractions of many real-world dynamic systems. These networks typically evolve according to certain laws, such as the law of triadic closure, which is universal in social networks. Inductive representation learning of temporal networks should be able to capture such laws and further be applied to systems that follow the same laws but have not been unseen during the training stage. Previous works in this area depend on either network node identities or rich edge attributes and typically fail to extract these laws. Here, we propose Causal Anonymous Walks (CAWs) to inductively represent a temporal network. CAWs are extracted by temporal random walks and work as automatic retrieval of temporal network motifs to represent network dynamics while avoiding the time-consuming selection and counting of those motifs. CAWs adopt a novel anonymization strategy that replaces node identities with the hitting counts of the nodes based on a set of sampled walks to keep the method inductive, and simultaneously establish the correlation between motifs. We further propose a neural-network model CAW-N to encode CAWs, and pair it with a CAW sampling strategy with constant memory and time cost to support online training and inference. CAW-N is evaluated to predict links over 6 real temporal networks and uniformly outperforms previous SOTA methods by averaged 15% AUC gain in the inductive setting. CAW-N also outperforms previous methods in 5 out of the 6 networks in the transductive setting.
WILDS: A Benchmark of in-the-Wild Distribution Shifts
Dec 14, 2020
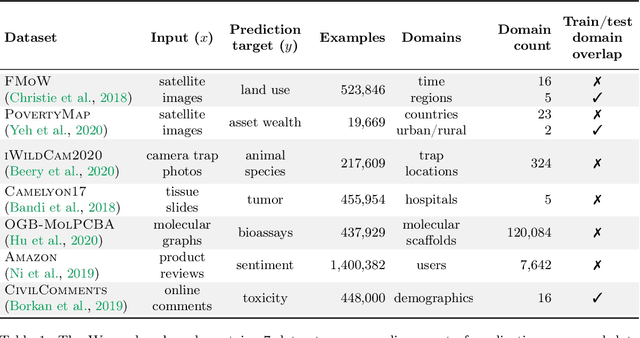

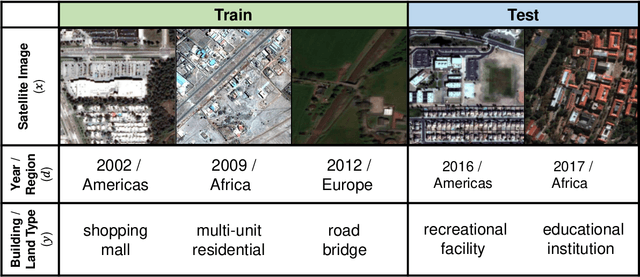
Distribution shifts can cause significant degradation in a broad range of machine learning (ML) systems deployed in the wild. However, many widely-used datasets in the ML community today were not designed for evaluating distribution shifts. These datasets typically have training and test sets drawn from the same distribution, and prior work on retrofitting them with distribution shifts has generally relied on artificial shifts that need not represent the kinds of shifts encountered in the wild. In this paper, we present WILDS, a benchmark of in-the-wild distribution shifts spanning diverse data modalities and applications, from tumor identification to wildlife monitoring to poverty mapping. WILDS builds on top of recent data collection efforts by domain experts in these applications and provides a unified collection of datasets with evaluation metrics and train/test splits that are representative of real-world distribution shifts. These datasets reflect distribution shifts arising from training and testing on different hospitals, cameras, countries, time periods, demographics, molecular scaffolds, etc., all of which cause substantial performance drops in our baseline models. Finally, we survey other applications that would be promising additions to the benchmark but for which we did not manage to find appropriate datasets; we discuss their associated challenges and detail datasets and shifts where we did not see an appreciable performance drop. By unifying datasets from a variety of application areas and making them accessible to the ML community, we hope to encourage the development of general-purpose methods that are anchored to real-world distribution shifts and that work well across different applications and problem settings. Data loaders, default models, and leaderboards are available at https://wilds.stanford.edu.
Design Space for Graph Neural Networks
Nov 17, 2020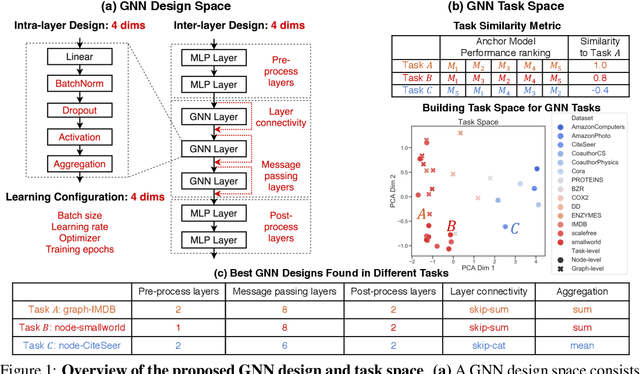

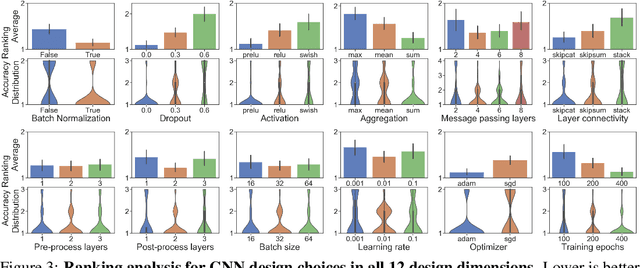
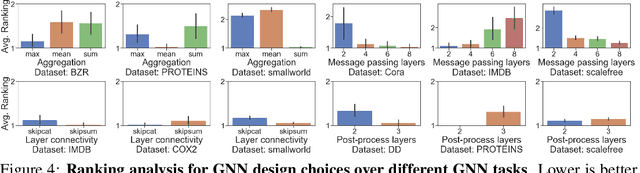
The rapid evolution of Graph Neural Networks (GNNs) has led to a growing number of new architectures as well as novel applications. However, current research focuses on proposing and evaluating specific architectural designs of GNNs, as opposed to studying the more general design space of GNNs that consists of a Cartesian product of different design dimensions, such as the number of layers or the type of the aggregation function. Additionally, GNN designs are often specialized to a single task, yet few efforts have been made to understand how to quickly find the best GNN design for a novel task or a novel dataset. Here we define and systematically study the architectural design space for GNNs which consists of 315,000 different designs over 32 different predictive tasks. Our approach features three key innovations: (1) A general GNN design space; (2) a GNN task space with a similarity metric, so that for a given novel task/dataset, we can quickly identify/transfer the best performing architecture; (3) an efficient and effective design space evaluation method which allows insights to be distilled from a huge number of model-task combinations. Our key results include: (1) A comprehensive set of guidelines for designing well-performing GNNs; (2) while best GNN designs for different tasks vary significantly, the GNN task space allows for transferring the best designs across different tasks; (3) models discovered using our design space achieve state-of-the-art performance. Overall, our work offers a principled and scalable approach to transition from studying individual GNN designs for specific tasks, to systematically studying the GNN design space and the task space. Finally, we release GraphGym, a powerful platform for exploring different GNN designs and tasks. GraphGym features modularized GNN implementation, standardized GNN evaluation, and reproducible and scalable experiment management.
Coresets for Robust Training of Neural Networks against Noisy Labels
Nov 15, 2020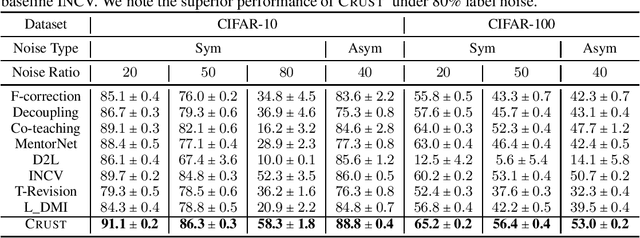
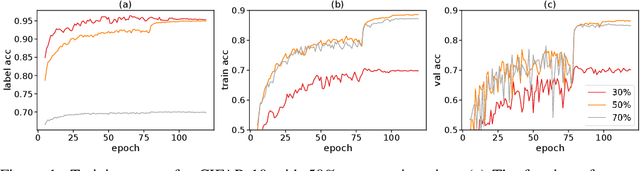


Modern neural networks have the capacity to overfit noisy labels frequently found in real-world datasets. Although great progress has been made, existing techniques are limited in providing theoretical guarantees for the performance of the neural networks trained with noisy labels. Here we propose a novel approach with strong theoretical guarantees for robust training of deep networks trained with noisy labels. The key idea behind our method is to select weighted subsets (coresets) of clean data points that provide an approximately low-rank Jacobian matrix. We then prove that gradient descent applied to the subsets do not overfit the noisy labels. Our extensive experiments corroborate our theory and demonstrate that deep networks trained on our subsets achieve a significantly superior performance compared to state-of-the art, e.g., 6% increase in accuracy on CIFAR-10 with 80% noisy labels, and 7% increase in accuracy on mini Webvision.
F-FADE: Frequency Factorization for Anomaly Detection in Edge Streams
Nov 09, 2020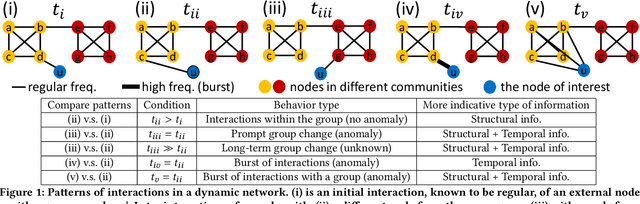

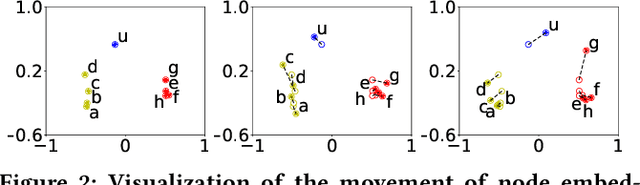

Edge streams are commonly used to capture interactions in dynamic networks, such as email, social, or computer networks. The problem of detecting anomalies or rare events in edge streams has a wide range of applications. However, it presents many challenges due to lack of labels, a highly dynamic nature of interactions, and the entanglement of temporal and structural changes in the network. Current methods are limited in their ability to address the above challenges and to efficiently process a large number of interactions. Here, we propose F-FADE, a new approach for detection of anomalies in edge streams, which uses a novel frequency-factorization technique to efficiently model the time-evolving distributions of frequencies of interactions between node-pairs. The anomalies are then determined based on the likelihood of the observed frequency of each incoming interaction. F-FADE is able to handle in an online streaming setting a broad variety of anomalies with temporal and structural changes, while requiring only constant memory. Our experiments on one synthetic and six real-world dynamic networks show that F-FADE achieves state of the art performance and may detect anomalies that previous methods are unable to find.
Handling Missing Data with Graph Representation Learning
Oct 30, 2020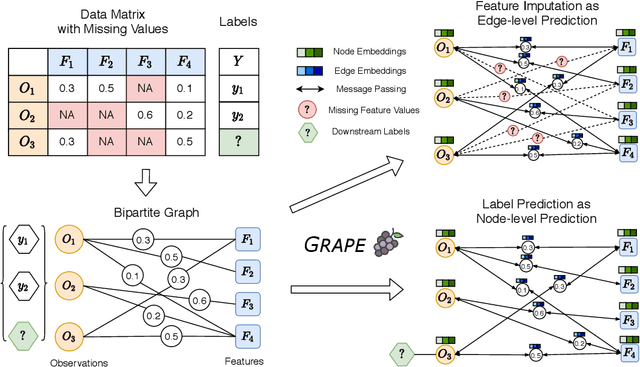
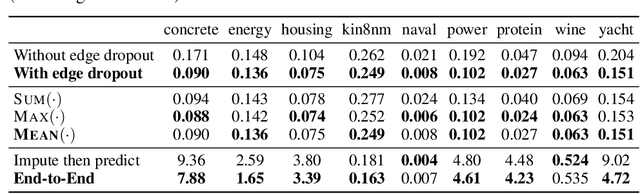
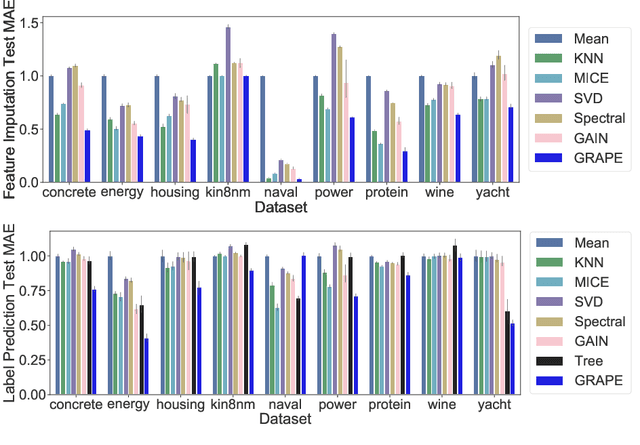
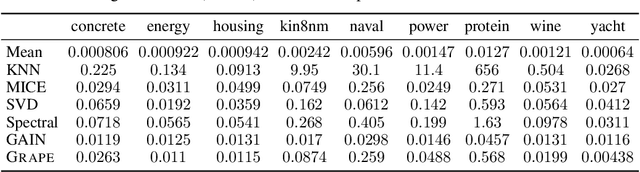
Machine learning with missing data has been approached in two different ways, including feature imputation where missing feature values are estimated based on observed values, and label prediction where downstream labels are learned directly from incomplete data. However, existing imputation models tend to have strong prior assumptions and cannot learn from downstream tasks, while models targeting label prediction often involve heuristics and can encounter scalability issues. Here we propose GRAPE, a graph-based framework for feature imputation as well as label prediction. GRAPE tackles the missing data problem using a graph representation, where the observations and features are viewed as two types of nodes in a bipartite graph, and the observed feature values as edges. Under the GRAPE framework, the feature imputation is formulated as an edge-level prediction task and the label prediction as a node-level prediction task. These tasks are then solved with Graph Neural Networks. Experimental results on nine benchmark datasets show that GRAPE yields 20% lower mean absolute error for imputation tasks and 10% lower for label prediction tasks, compared with existing state-of-the-art methods.