 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolMem: A Cognitive-Driven Benchmark for Multi-Session Dialogue Memory
Jan 07, 2026Despite recent advances in understanding and leveraging long-range conversational memory, existing benchmarks still lack systematic evaluation of large language models(LLMs) across diverse memory dimensions, particularly in multi-session settings. In this work, we propose EvolMem, a new benchmark for assessing multi-session memory capabilities of LLMs and agent systems. EvolMem is grounded in cognitive psychology and encompasses both declarative and non-declarative memory, further decomposed into multiple fine-grained abilities. To construct the benchmark, we introduce a hybrid data synthesis framework that consists of topic-initiated generation and narrative-inspired transformations. This framework enables scalable generation of multi-session conversations with controllable complexity, accompanied by sample-specific evaluation guidelines. Extensive evaluation reveals that no LLM consistently outperforms others across all memory dimensions. Moreover, agent memory mechanisms do not necessarily enhance LLMs' capabilities and often exhibit notable efficiency limitations. Data and code will be released at https://github.com/shenye7436/EvolMem.
DGH: Dynamic Gaussian Hair
Dec 18, 2025The creation of photorealistic dynamic hair remains a major challenge in digital human modeling because of the complex motions, occlusions, and light scattering. Existing methods often resort to static capture and physics-based models that do not scale as they require manual parameter fine-tuning to handle the diversity of hairstyles and motions, and heavy computation to obtain high-quality appearance. In this paper, we present Dynamic Gaussian Hair (DGH), a novel framework that efficiently learns hair dynamics and appearance. We propose: (1) a coarse-to-fine model that learns temporally coherent hair motion dynamics across diverse hairstyles; (2) a strand-guided optimization module that learns a dynamic 3D Gaussian representation for hair appearance with support for differentiable rendering, enabling gradient-based learning of view-consistent appearance under motion. Unlike prior simulation-based pipelines, our approach is fully data-driven, scales with training data, and generalizes across various hairstyles and head motion sequences. Additionally, DGH can be seamlessly integrated into a 3D Gaussian avatar framework, enabling realistic, animatable hair for high-fidelity avatar representation. DGH achieves promising geometry and appearance results, providing a scalable, data-driven alternative to physics-based simulation and rendering.
A Multi-To-One Interview Paradigm for Efficient MLLM Evaluation
Sep 18, 2025The rapid progress of Multi-Modal Large Language Models (MLLMs) has spurred the creation of numerous benchmarks. However, conventional full-coverage Question-Answering evaluations suffer from high redundancy and low efficiency. Inspired by human interview processes, we propose a multi-to-one interview paradigm for efficient MLLM evaluation. Our framework consists of (i) a two-stage interview strategy with pre-interview and formal interview phases, (ii) dynamic adjustment of interviewer weights to ensure fairness, and (iii) an adaptive mechanism for question difficulty-level chosen. Experiments on different benchmarks show that the proposed paradigm achieves significantly higher correlation with full-coverage results than random sampling, with improvements of up to 17.6% in PLCC and 16.7% in SRCC, while reducing the number of required questions. These findings demonstrate that the proposed paradigm provides a reliable and efficient alternative for large-scale MLLM benchmarking.
The Ever-Evolving Science Exam
Jul 22, 2025



As foundation models grow rapidly in capability and deployment, evaluating their scientific understanding becomes increasingly critical. Existing science benchmarks have made progress towards broad **Range**, wide **Reach**, and high **Rigor**, yet they often face two major challenges: **data leakage risks** that compromise benchmarking validity, and **evaluation inefficiency** due to large-scale testing. To address these issues, we introduce the **Ever-Evolving Science Exam (EESE)**, a dynamic benchmark designed to reliably assess scientific capabilities in foundation models. Our approach consists of two components: 1) a non-public **EESE-Pool** with over 100K expertly constructed science instances (question-answer pairs) across 5 disciplines and 500+ subfields, built through a multi-stage pipeline ensuring **Range**, **Reach**, and **Rigor**, 2) a periodically updated 500-instance subset **EESE**, sampled and validated to enable leakage-resilient, low-overhead evaluations. Experiments on 32 open- and closed-source models demonstrate that EESE effectively differentiates the strengths and weaknesses of models in scientific fields and cognitive dimensions. Overall, EESE provides a robust, scalable, and forward-compatible solution for science benchmark design, offering a realistic measure of how well foundation models handle science questions. The project page is at: https://github.com/aiben-ch/EESE.
Adv-CPG: A Customized Portrait Generation Framework with Facial Adversarial Attacks
Mar 11, 2025Recent Customized Portrait Generation (CPG) methods, taking a facial image and a textual prompt as inputs, have attracted substantial attention. Although these methods generate high-fidelity portraits, they fail to prevent the generated portraits from being tracked and misused by malicious face recognition systems. To address this, this paper proposes a Customized Portrait Generation framework with facial Adversarial attacks (Adv-CPG). Specifically, to achieve facial privacy protection, we devise a lightweight local ID encryptor and an encryption enhancer. They implement progressive double-layer encryption protection by directly injecting the target identity and adding additional identity guidance, respectively. Furthermore, to accomplish fine-grained and personalized portrait generation, we develop a multi-modal image customizer capable of generating controlled fine-grained facial features. To the best of our knowledge, Adv-CPG is the first study that introduces facial adversarial attacks into CPG. Extensive experiments demonstrate the superiority of Adv-CPG, e.g., the average attack success rate of the proposed Adv-CPG is 28.1% and 2.86% higher compared to the SOTA noise-based attack methods and unconstrained attack methods, respectively.
Boosting Generalizability towards Zero-Shot Cross-Dataset Single-Image Indoor Depth by Meta-Initialization
Sep 04, 2024Indoor robots rely on depth to perform tasks like navigation or obstacle detection, and single-image depth estimation is widely used to assist perception. Most indoor single-image depth prediction focuses less on model generalizability to unseen datasets, concerned with in-the-wild robustness for system deployment. This work leverages gradient-based meta-learning to gain higher generalizability on zero-shot cross-dataset inference. Unlike the most-studied meta-learning of image classification associated with explicit class labels, no explicit task boundaries exist for continuous depth values tied to highly varying indoor environments regarding object arrangement and scene composition. We propose fine-grained task that treats each RGB-D mini-batch as a task in our meta-learning formulation. We first show that our method on limited data induces a much better prior (max 27.8% in RMSE). Then, finetuning on meta-learned initialization consistently outperforms baselines without the meta approach. Aiming at generalization, we propose zero-shot cross-dataset protocols and validate higher generalizability induced by our meta-initialization, as a simple and useful plugin to many existing depth estimation methods. The work at the intersection of depth and meta-learning potentially drives both research to step closer to practical robotic and machine perception usage.
Meta-Optimization for Higher Model Generalizability in Single-Image Depth Prediction
May 12, 2023



Model generalizability to unseen datasets, concerned with in-the-wild robustness, is less studied for indoor single-image depth prediction. We leverage gradient-based meta-learning for higher generalizability on zero-shot cross-dataset inference. Unlike the most-studied image classification in meta-learning, depth is pixel-level continuous range values, and mappings from each image to depth vary widely across environments. Thus no explicit task boundaries exist. We instead propose fine-grained task that treats each RGB-D pair as a task in our meta-optimization. We first show meta-learning on limited data induces much better prior (max +29.4\%). Using meta-learned weights as initialization for following supervised learning, without involving extra data or information, it consistently outperforms baselines without the method. Compared to most indoor-depth methods that only train/ test on a single dataset, we propose zero-shot cross-dataset protocols, closely evaluate robustness, and show consistently higher generalizability and accuracy by our meta-initialization. The work at the intersection of depth and meta-learning potentially drives both research streams to step closer to practical use.
Tournament selection in zeroth-level classifier systems based on average reward reinforcement learning
Apr 26, 2016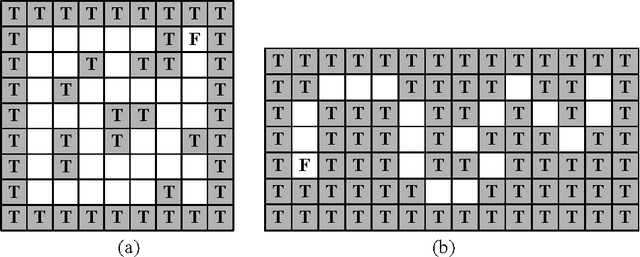
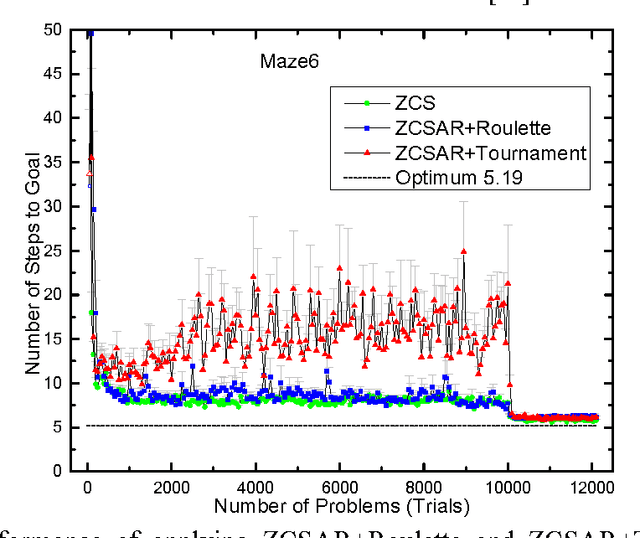
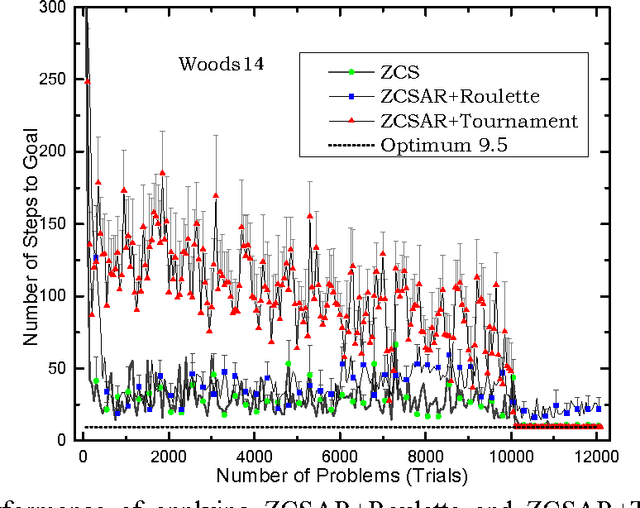
As a genetics-based machine learning technique, zeroth-level classifier system (ZCS) is based on a discounted reward reinforcement learning algorithm, bucket-brigade algorithm, which optimizes the discounted total reward received by an agent but is not suitable for all multi-step problems, especially large-size ones. There are some undiscounted reinforcement learning methods available, such as R-learning, which optimize the average reward per time step. In this paper, R-learning is used as the reinforcement learning employed by ZCS, to replace its discounted reward reinforcement learning approach, and tournament selection is used to replace roulette wheel selection in ZCS. The modification results in classifier systems that can support long action chains, and thus is able to solve large multi-step problems.
Learning classifier systems with memory condition to solve non-Markov problems
Nov 02, 2012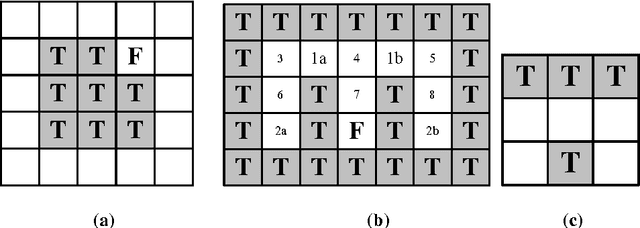
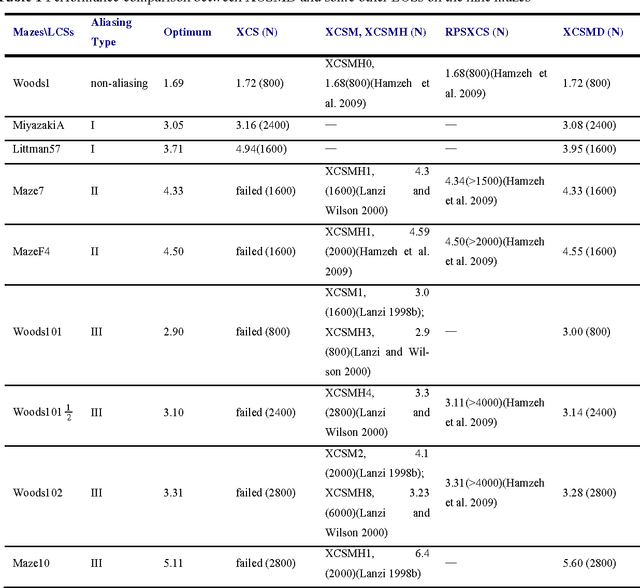
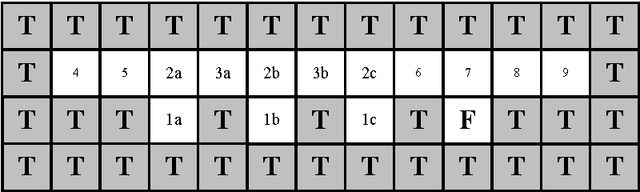

In the family of Learning Classifier Systems, the classifier system XCS has been successfully used for many applications. However, the standard XCS has no memory mechanism and can only learn optimal policy in Markov environments, where the optimal action is determined solely by the state of current sensory input. In practice, most environments are partially observable environments on agent's sensation, which are also known as non-Markov environments. Within these environments, XCS either fails, or only develops a suboptimal policy, since it has no memory. In this work, we develop a new classifier system based on XCS to tackle this problem. It adds an internal message list to XCS as the memory list to record input sensation history, and extends a small number of classifiers with memory conditions. The classifier's memory condition, as a foothold to disambiguate non-Markov states, is used to sense a specified element in the memory list. Besides, a detection method is employed to recognize non-Markov states in environments, to avoid these states controlling over classifiers' memory conditions. Furthermore, four sets of different complex maze environments have been tested by the proposed method. Experimental results show that our system is one of the best techniques to solve partially observable environments, compared with some well-known classifier systems proposed for these environments.