 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrapheme or phoneme? An Analysis of Tacotron's Embedded Representations
Oct 21, 2020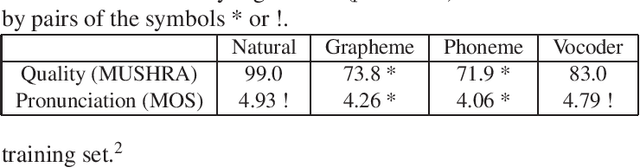
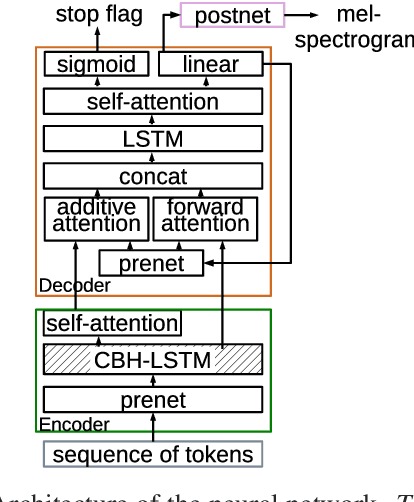
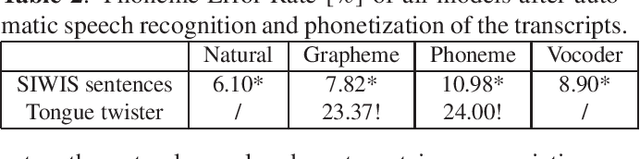
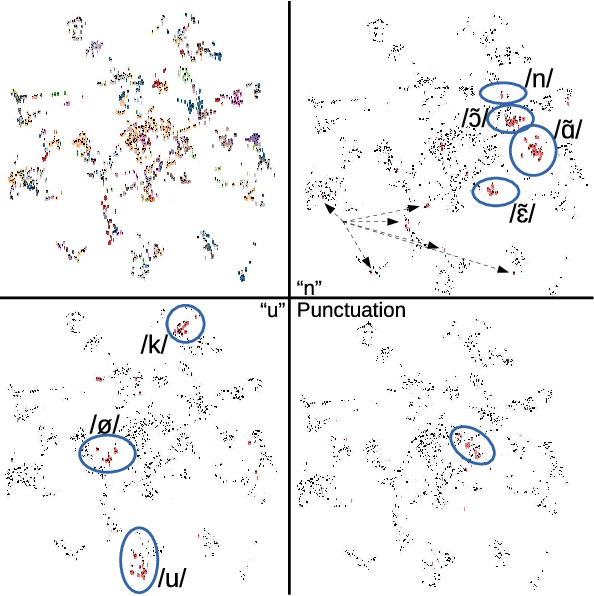
End-to-end models, particularly Tacotron-based ones, are currently a popular solution for text-to-speech synthesis. They allow the production of high-quality synthesized speech with little to no text preprocessing. Phoneme inputs are usually preferred over graphemes in order to limit the amount of pronunciation errors. In this work we show that, in the case of a well-curated French dataset, graphemes can be used as input without increasing the amount of pronunciation errors. Furthermore, we perform an analysis of the representation learned by the Tacotron model and show that the contextual grapheme embeddings encode phoneme information, and that they can be used for grapheme-to-phoneme conversion and phoneme control of synthetic speech.
End-to-End Text-to-Speech using Latent Duration based on VQ-VAE
Oct 20, 2020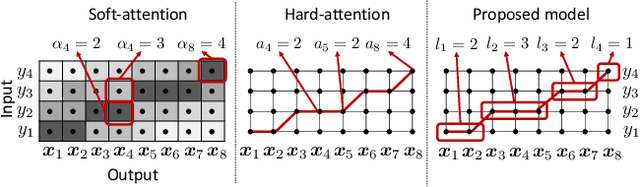
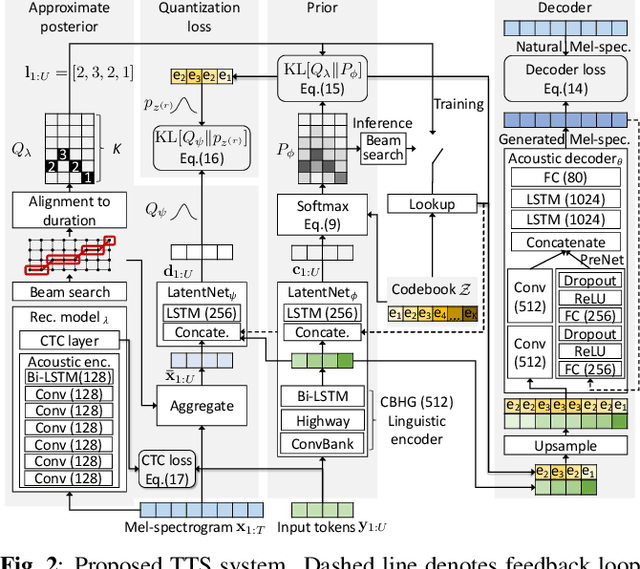
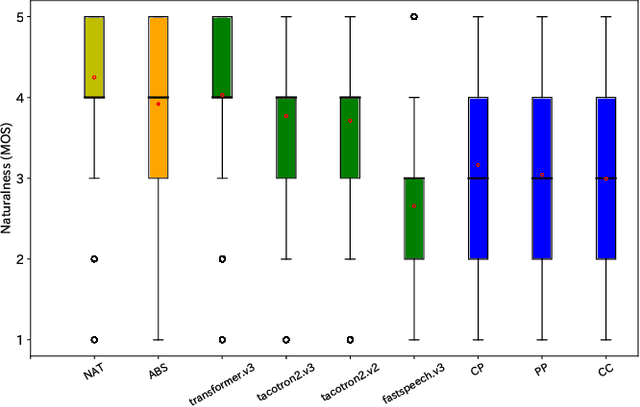
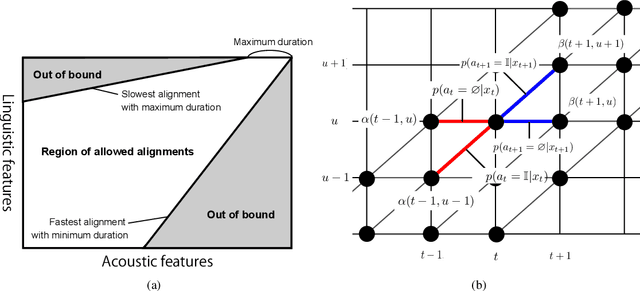
Explicit duration modeling is a key to achieving robust and efficient alignment in text-to-speech synthesis (TTS). We propose a new TTS framework using explicit duration modeling that incorporates duration as a discrete latent variable to TTS and enables joint optimization of whole modules from scratch. We formulate our method based on conditional VQ-VAE to handle discrete duration in a variational autoencoder and provide a theoretical explanation to justify our method. In our framework, a connectionist temporal classification (CTC) -based force aligner acts as the approximate posterior, and text-to-duration works as the prior in the variational autoencoder. We evaluated our proposed method with a listening test and compared it with other TTS methods based on soft-attention or explicit duration modeling. The results showed that our systems rated between soft-attention-based methods (Transformer-TTS, Tacotron2) and explicit duration modeling-based methods (Fastspeech).
Latent linguistic embedding for cross-lingual text-to-speech and voice conversion
Oct 08, 2020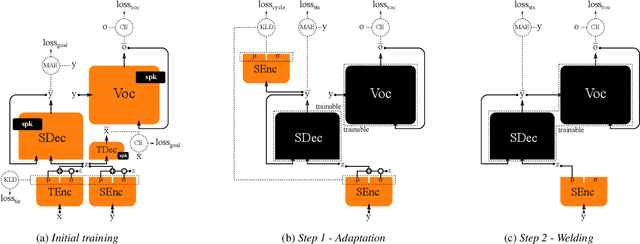
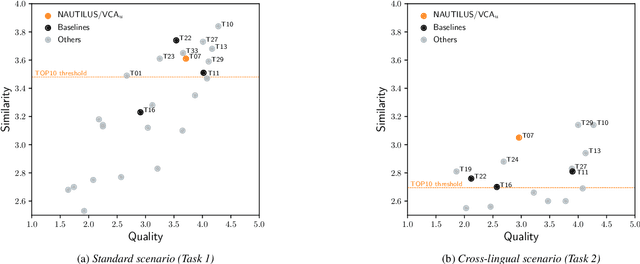
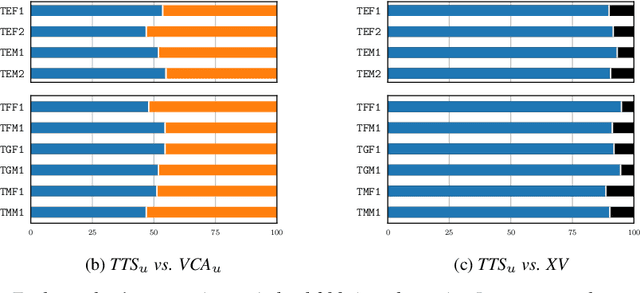
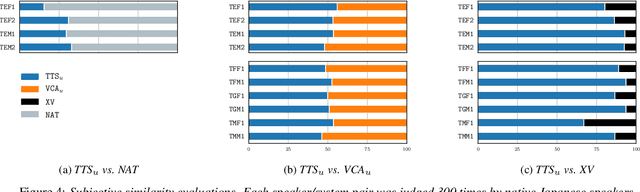
As the recently proposed voice cloning system, NAUTILUS, is capable of cloning unseen voices using untranscribed speech, we investigate the feasibility of using it to develop a unified cross-lingual TTS/VC system. Cross-lingual speech generation is the scenario in which speech utterances are generated with the voices of target speakers in a language not spoken by them originally. This type of system is not simply cloning the voice of the target speaker, but essentially creating a new voice that can be considered better than the original under a specific framing. By using a well-trained English latent linguistic embedding to create a cross-lingual TTS and VC system for several German, Finnish, and Mandarin speakers included in the Voice Conversion Challenge 2020, we show that our method not only creates cross-lingual VC with high speaker similarity but also can be seamlessly used for cross-lingual TTS without having to perform any extra steps. However, the subjective evaluations of perceived naturalness seemed to vary between target speakers, which is one aspect for future improvement.
Viable Threat on News Reading: Generating Biased News Using Natural Language Models
Oct 05, 2020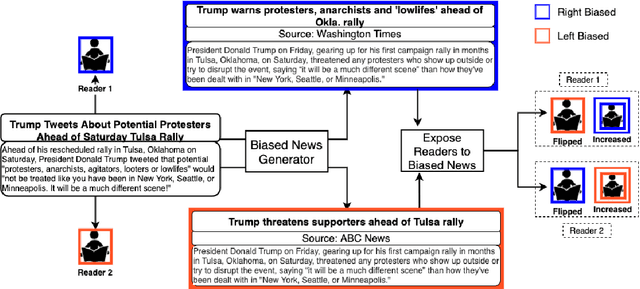
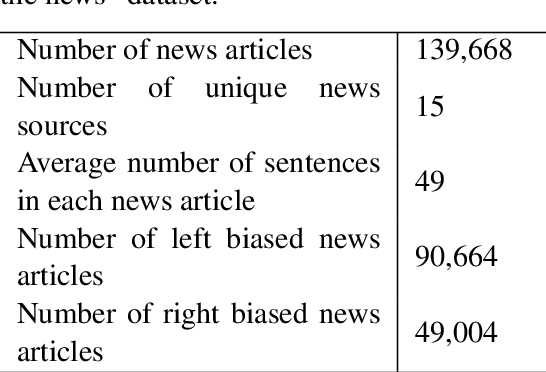
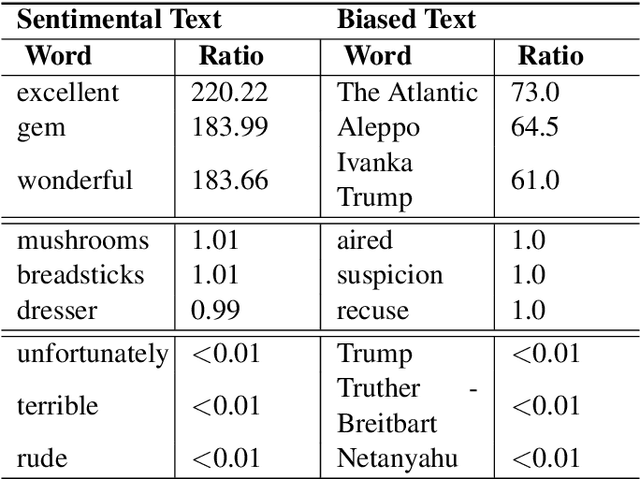
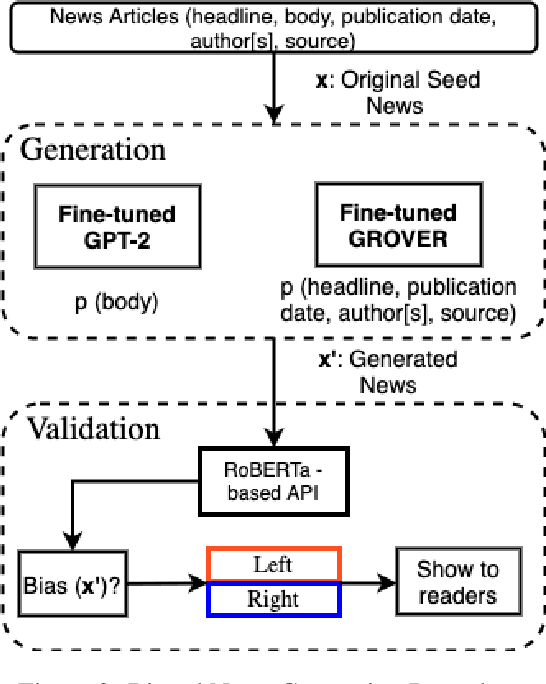
Recent advancements in natural language generation has raised serious concerns. High-performance language models are widely used for language generation tasks because they are able to produce fluent and meaningful sentences. These models are already being used to create fake news. They can also be exploited to generate biased news, which can then be used to attack news aggregators to change their reader's behavior and influence their bias. In this paper, we use a threat model to demonstrate that the publicly available language models can reliably generate biased news content based on an input original news. We also show that a large number of high-quality biased news articles can be generated using controllable text generation. A subjective evaluation with 80 participants demonstrated that the generated biased news is generally fluent, and a bias evaluation with 24 participants demonstrated that the bias (left or right) is usually evident in the generated articles and can be easily identified.
Tandem Assessment of Spoofing Countermeasures and Automatic Speaker Verification: Fundamentals
Jul 12, 2020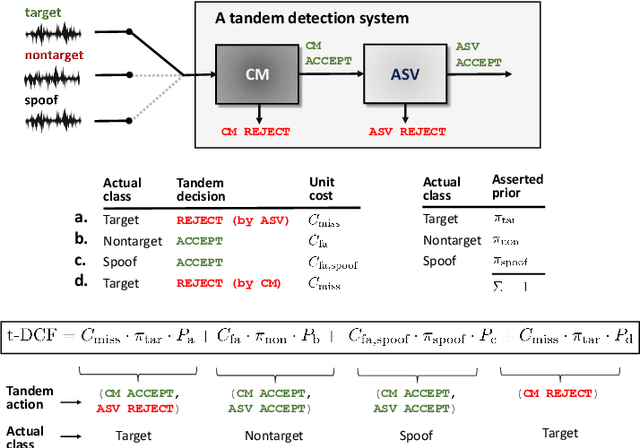
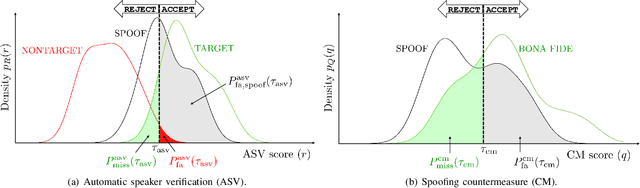
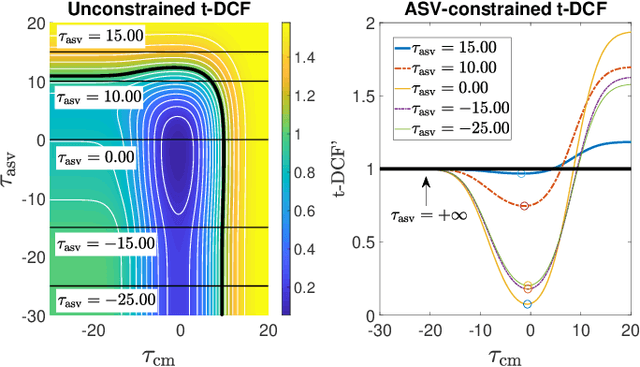
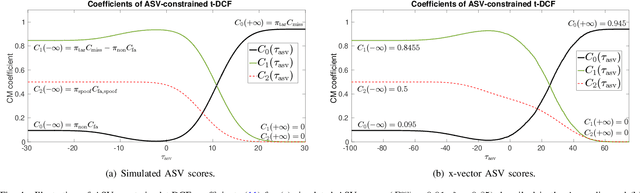
Recent years have seen growing efforts to develop spoofing countermeasures (CMs) to protect automatic speaker verification (ASV) systems from being deceived by manipulated or artificial inputs. The reliability of spoofing CMs is typically gauged using the equal error rate (EER) metric. The primitive EER fails to reflect application requirements and the impact of spoofing and CMs upon ASV and its use as a primary metric in traditional ASV research has long been abandoned in favour of risk-based approaches to assessment. This paper presents several new extensions to the tandem detection cost function (t-DCF), a recent risk-based approach to assess the reliability of spoofing CMs deployed in tandem with an ASV system. Extensions include a simplified version of the t-DCF with fewer parameters, an analysis of a special case for a fixed ASV system, simulations which give original insights into its interpretation and new analyses using the ASVspoof 2019 database. It is hoped that adoption of the t-DCF for the CM assessment will help to foster closer collaboration between the anti-spoofing and ASV research communities.
Generating Master Faces for Use in Performing Wolf Attacks on Face Recognition Systems
Jun 15, 2020
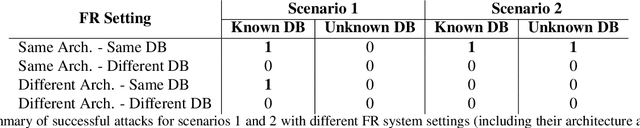
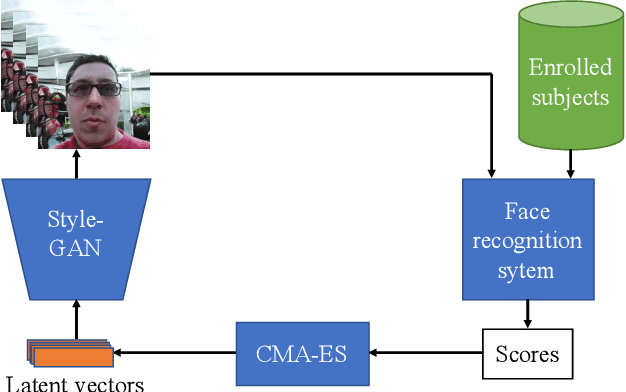
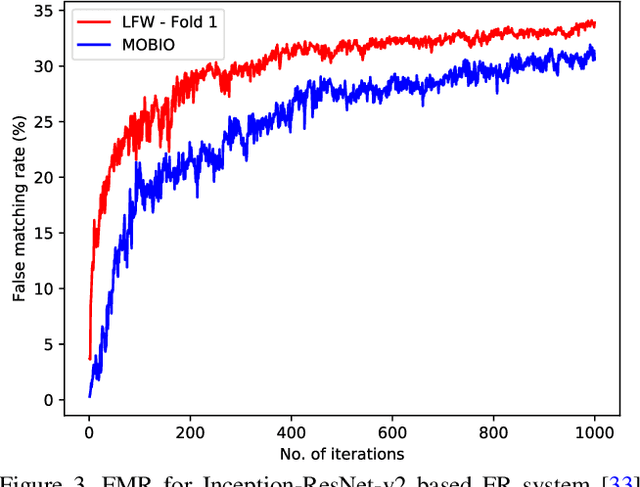
Due to its convenience, biometric authentication, especial face authentication, has become increasingly mainstream and thus is now a prime target for attackers. Presentation attacks and face morphing are typical types of attack. Previous research has shown that finger-vein- and fingerprint-based authentication methods are susceptible to wolf attacks, in which a wolf sample matches many enrolled user templates. In this work, we demonstrated that wolf (generic) faces, which we call "master faces," can also compromise face recognition systems and that the master face concept can be generalized in some cases. Motivated by recent similar work in the fingerprint domain, we generated high-quality master faces by using the state-of-the-art face generator StyleGAN in a process called latent variable evolution. Experiments demonstrated that even attackers with limited resources using only pre-trained models available on the Internet can initiate master face attacks. The results, in addition to demonstrating performance from the attacker's point of view, can also be used to clarify and improve the performance of face recognition systems and harden face authentication systems.
NAUTILUS: a Versatile Voice Cloning System
May 22, 2020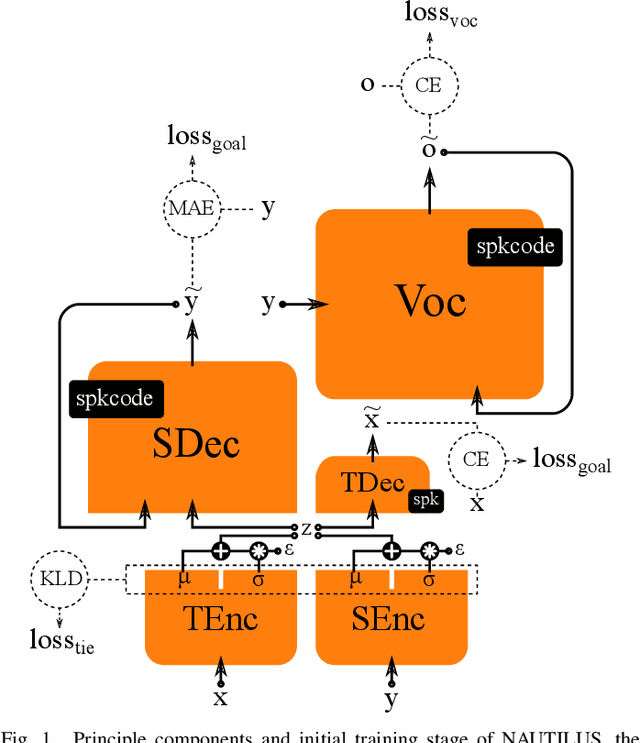
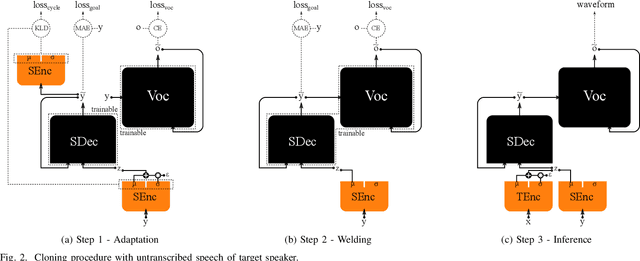
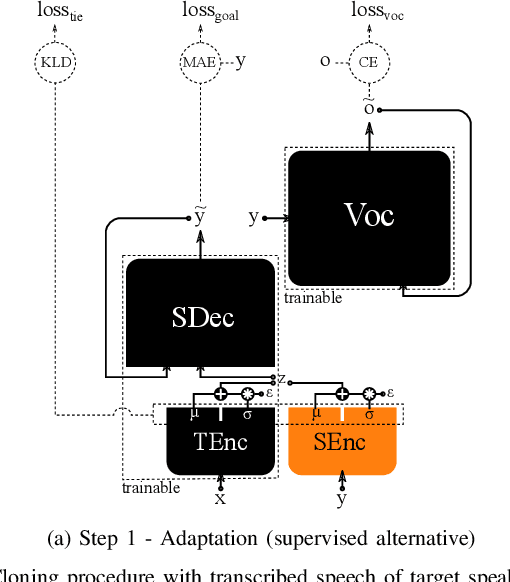
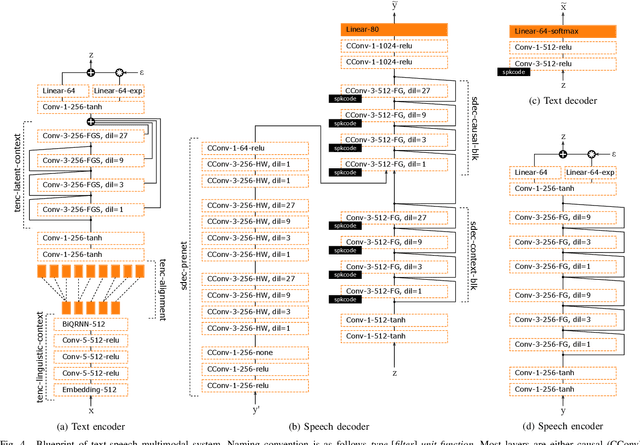
We introduce a novel speech synthesis system, called NAUTILUS, that can generate speech with a target voice either from a text input or a reference utterance of an arbitrary source speaker. By using a multi-speaker speech corpus to train all requisite encoders and decoders in the initial training stage, our system can clone unseen voices using untranscribed speech of target speakers on the basis of the backpropagation algorithm. Moreover, depending on the data circumstance of the target speaker, the cloning strategy can be adjusted to take advantage of additional data and modify the behaviors of text-to-speech (TTS) and/or voice conversion (VC) systems to accommodate the situation. We test the performance of the proposed framework by using deep convolution layers to model the encoders, decoders and WaveNet vocoder. Evaluations show that it achieves comparable quality with state-of-the-art TTS and VC systems when cloning with just five minutes of untranscribed speech. Moreover, it is demonstrated that the proposed framework has the ability to switch between TTS and VC with high speaker consistency, which will be useful for many applications.
Investigation of learning abilities on linguistic features in sequence-to-sequence text-to-speech synthesis
May 20, 2020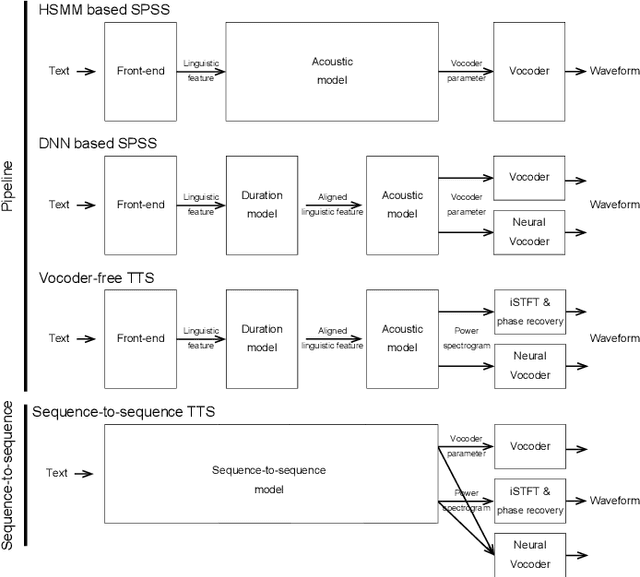
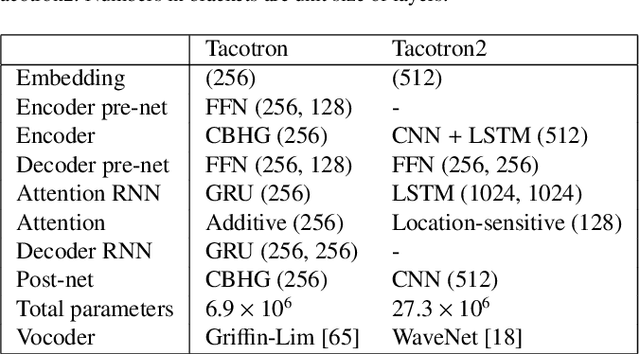
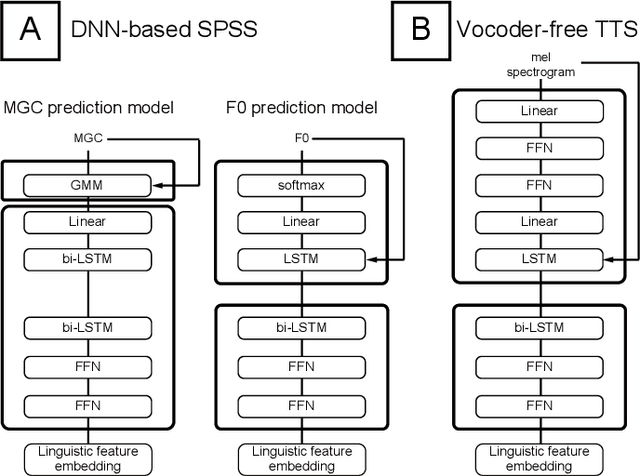
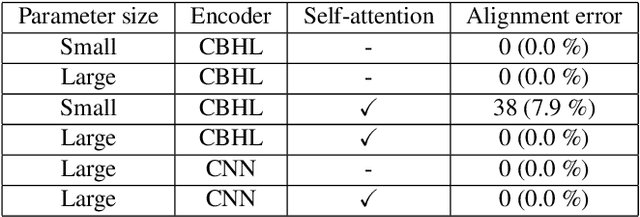
Neural sequence-to-sequence text-to-speech synthesis (TTS) can produce high-quality speech directly from text or simple linguistic features such as phonemes. Unlike traditional pipeline TTS, the neural sequence-to-sequence TTS does not require manually annotated and complicated linguistic features such as part-of-speech tags and syntactic structures for system training. However, it must be carefully designed and well optimized so that it can implicitly extract useful linguistic features from the input features. In this paper we investigate under what conditions the neural sequence-to-sequence TTS can work well in Japanese and English along with comparisons with deep neural network (DNN) based pipeline TTS systems. Unlike past comparative studies, the pipeline systems also use autoregressive probabilistic modeling and a neural vocoder. We investigated systems from three aspects: a) model architecture, b) model parameter size, and c) language. For the model architecture aspect, we adopt modified Tacotron systems that we previously proposed and their variants using an encoder from Tacotron or Tacotron2. For the model parameter size aspect, we investigate two model parameter sizes. For the language aspect, we conduct listening tests in both Japanese and English to see if our findings can be generalized across languages. Our experiments suggest that a) a neural sequence-to-sequence TTS system should have a sufficient number of model parameters to produce high quality speech, b) it should also use a powerful encoder when it takes characters as inputs, and c) the encoder still has a room for improvement and needs to have an improved architecture to learn supra-segmental features more appropriately.
Design Choices for X-vector Based Speaker Anonymization
May 18, 2020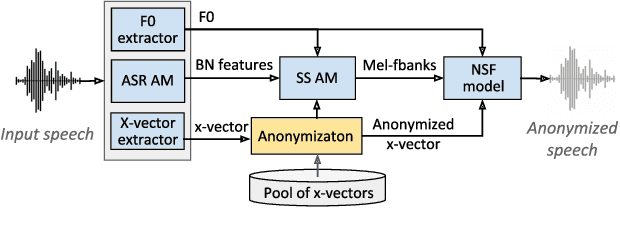
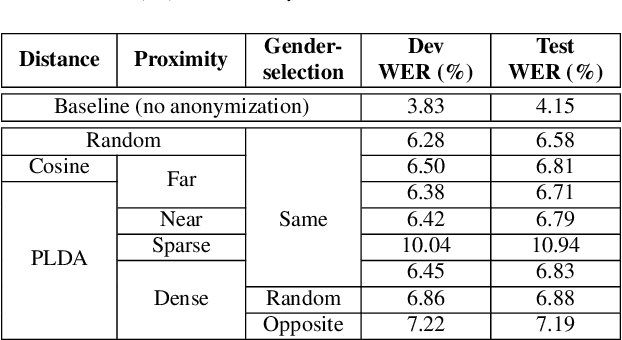
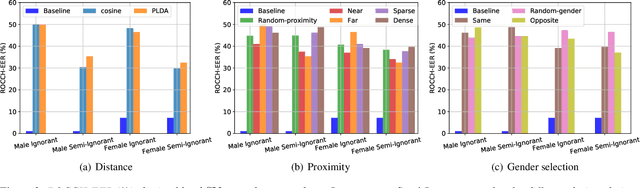
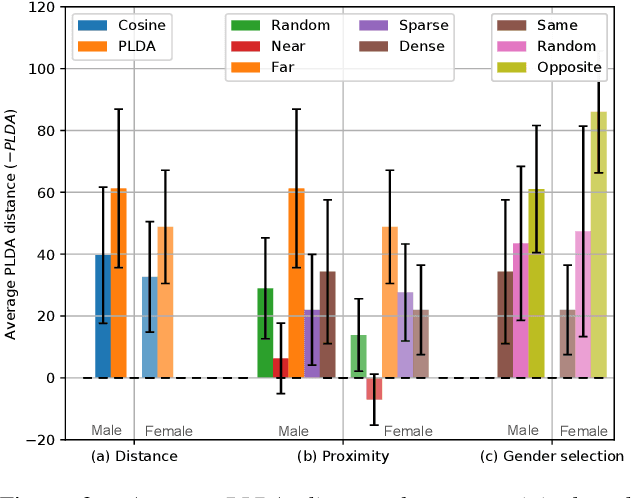
The recently proposed x-vector based anonymization scheme converts any input voice into that of a random pseudo-speaker. In this paper, we present a flexible pseudo-speaker selection technique as a baseline for the first VoicePrivacy Challenge. We explore several design choices for the distance metric between speakers, the region of x-vector space where the pseudo-speaker is picked, and gender selection. To assess the strength of anonymization achieved, we consider attackers using an x-vector based speaker verification system who may use original or anonymized speech for enrollment, depending on their knowledge of the anonymization scheme. The Equal Error Rate (EER) achieved by the attackers and the decoding Word Error Rate (WER) over anonymized data are reported as the measures of privacy and utility. Experiments are performed using datasets derived from LibriSpeech to find the optimal combination of design choices in terms of privacy and utility.
Introducing the VoicePrivacy Initiative
May 13, 2020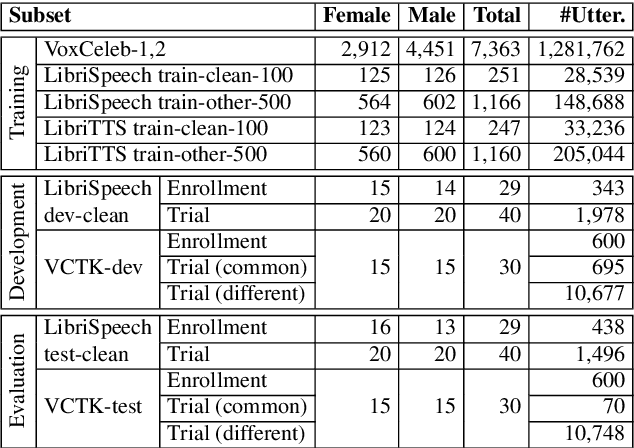
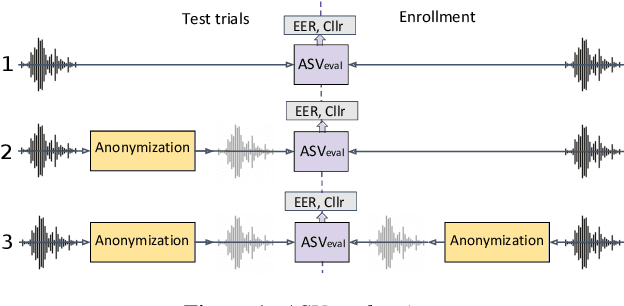
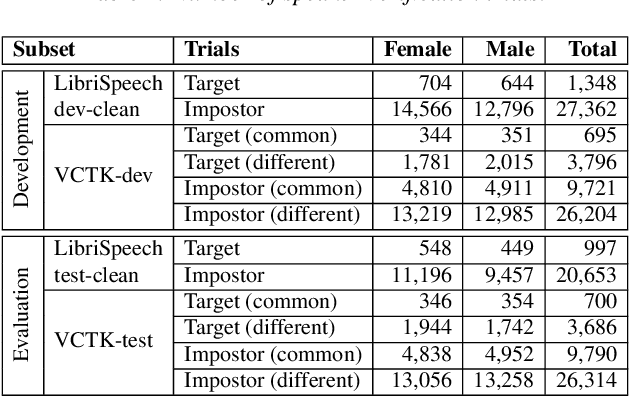
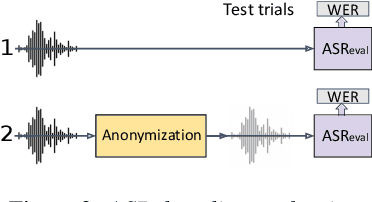
The VoicePrivacy initiative aims to promote the development of privacy preservation tools for speech technology by gathering a new community to define the tasks of interest and the evaluation methodology, and benchmarking solutions through a series of challenges. In this paper, we formulate the voice anonymization task selected for the VoicePrivacy 2020 Challenge and describe the datasets used for system development and evaluation. We also present the attack models and the associated objective and subjective evaluation metrics. We introduce two anonymization baselines and report objective evaluation results.