 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBidimensional Leaderboards: Generate and Evaluate Language Hand in Hand
Dec 08, 2021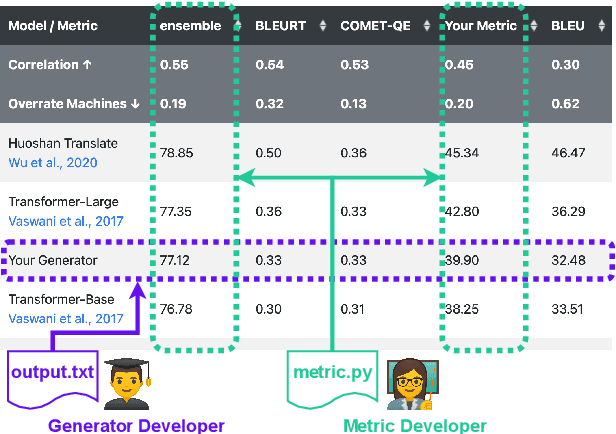
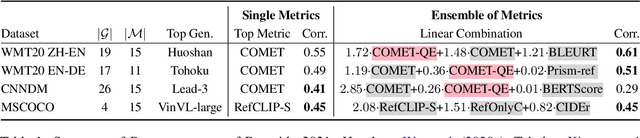
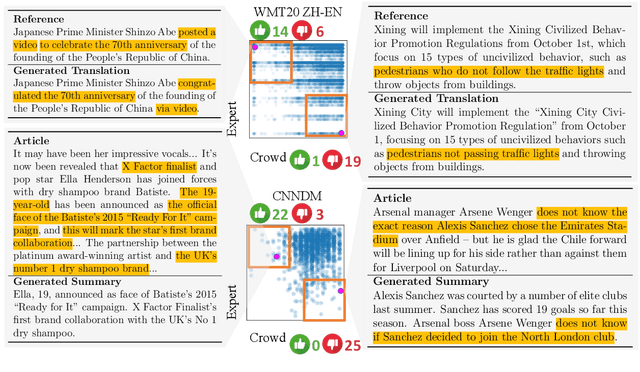

Natural language processing researchers have identified limitations of evaluation methodology for generation tasks, with new questions raised about the validity of automatic metrics and of crowdworker judgments. Meanwhile, efforts to improve generation models tend to focus on simple n-gram overlap metrics (e.g., BLEU, ROUGE). We argue that new advances on models and metrics should each more directly benefit and inform the other. We therefore propose a generalization of leaderboards, bidimensional leaderboards (Billboards), that simultaneously tracks progress in language generation tasks and metrics for their evaluation. Unlike conventional unidimensional leaderboards that sort submitted systems by predetermined metrics, a Billboard accepts both generators and evaluation metrics as competing entries. A Billboard automatically creates an ensemble metric that selects and linearly combines a few metrics based on a global analysis across generators. Further, metrics are ranked based on their correlations with human judgments. We release four Billboards for machine translation, summarization, and image captioning. We demonstrate that a linear ensemble of a few diverse metrics sometimes substantially outperforms existing metrics in isolation. Our mixed-effects model analysis shows that most automatic metrics, especially the reference-based ones, overrate machine over human generation, demonstrating the importance of updating metrics as generation models become stronger (and perhaps more similar to humans) in the future.
Transparent Human Evaluation for Image Captioning
Nov 17, 2021

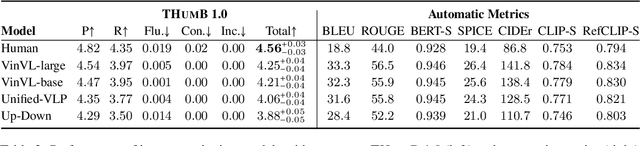
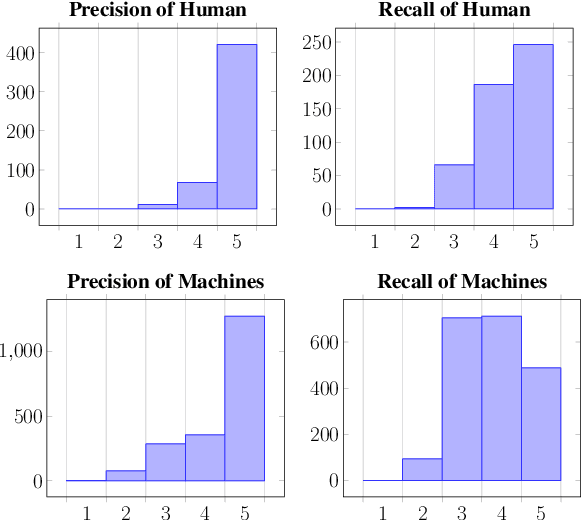
We establish a rubric-based human evaluation protocol for image captioning models. Our scoring rubrics and their definitions are carefully developed based on machine- and human-generated captions on the MSCOCO dataset. Each caption is evaluated along two main dimensions in a tradeoff (precision and recall) as well as other aspects that measure the text quality (fluency, conciseness, and inclusive language). Our evaluations demonstrate several critical problems of the current evaluation practice. Human-generated captions show substantially higher quality than machine-generated ones, especially in coverage of salient information (i.e., recall), while all automatic metrics say the opposite. Our rubric-based results reveal that CLIPScore, a recent metric that uses image features, better correlates with human judgments than conventional text-only metrics because it is more sensitive to recall. We hope that this work will promote a more transparent evaluation protocol for image captioning and its automatic metrics.
ABC: Attention with Bounded-memory Control
Oct 06, 2021
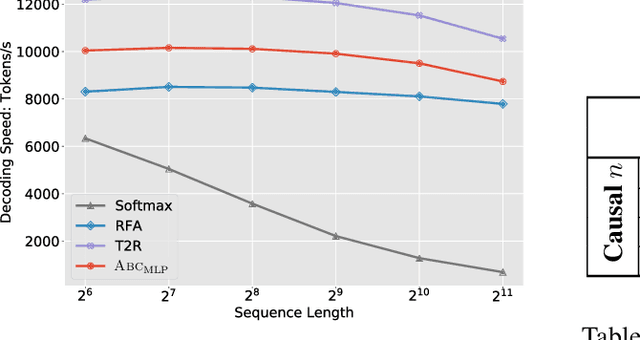
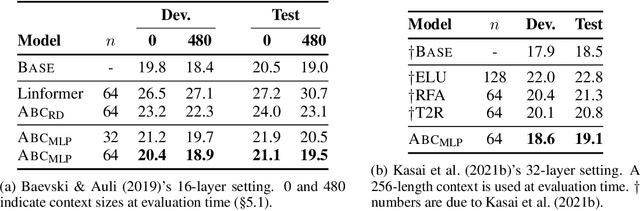
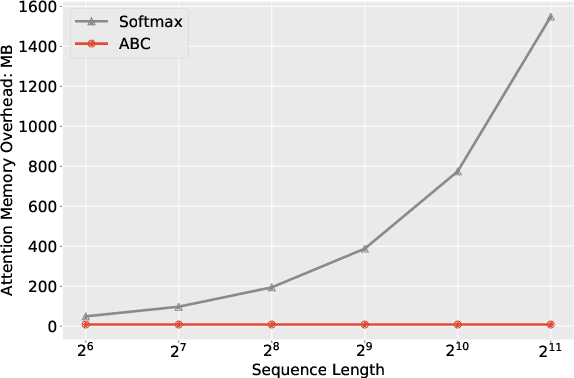
Transformer architectures have achieved state-of-the-art results on a variety of sequence modeling tasks. However, their attention mechanism comes with a quadratic complexity in sequence lengths, making the computational overhead prohibitive, especially for long sequences. Attention context can be seen as a random-access memory with each token taking a slot. Under this perspective, the memory size grows linearly with the sequence length, and so does the overhead of reading from it. One way to improve the efficiency is to bound the memory size. We show that disparate approaches can be subsumed into one abstraction, attention with bounded-memory control (ABC), and they vary in their organization of the memory. ABC reveals new, unexplored possibilities. First, it connects several efficient attention variants that would otherwise seem apart. Second, this abstraction gives new insights--an established approach (Wang et al., 2020b) previously thought to be not applicable in causal attention, actually is. Last, we present a new instance of ABC, which draws inspiration from existing ABC approaches, but replaces their heuristic memory-organizing functions with a learned, contextualized one. Our experiments on language modeling, machine translation, and masked language model finetuning show that our approach outperforms previous efficient attention models; compared to the strong transformer baselines, it significantly improves the inference time and space efficiency with no or negligible accuracy loss.
One Question Answering Model for Many Languages with Cross-lingual Dense Passage Retrieval
Jul 26, 2021
We present CORA, a Cross-lingual Open-Retrieval Answer Generation model that can answer questions across many languages even when language-specific annotated data or knowledge sources are unavailable. We introduce a new dense passage retrieval algorithm that is trained to retrieve documents across languages for a question. Combined with a multilingual autoregressive generation model, CORA answers directly in the target language without any translation or in-language retrieval modules as used in prior work. We propose an iterative training method that automatically extends annotated data available only in high-resource languages to low-resource ones. Our results show that CORA substantially outperforms the previous state of the art on multilingual open question answering benchmarks across 26 languages, 9 of which are unseen during training. Our analyses show the significance of cross-lingual retrieval and generation in many languages, particularly under low-resource settings.
Probing Across Time: What Does RoBERTa Know and When?
Apr 16, 2021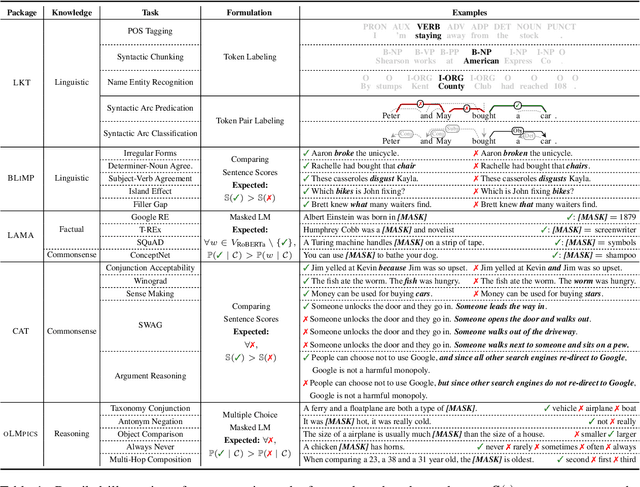
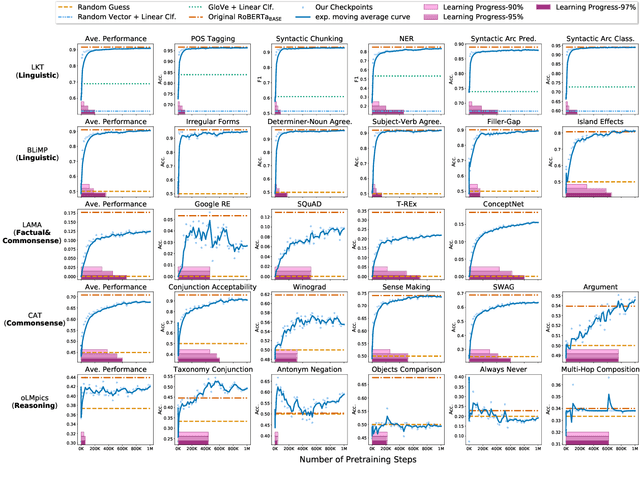
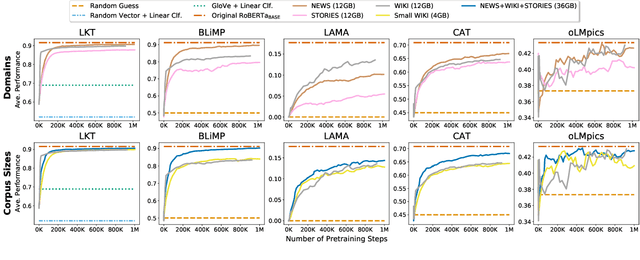
Models of language trained on very large corpora have been demonstrated useful for NLP. As fixed artifacts, they have become the object of intense study, with many researchers "probing" the extent to which linguistic abstractions, factual and commonsense knowledge, and reasoning abilities they acquire and readily demonstrate. Building on this line of work, we consider a new question: for types of knowledge a language model learns, when during (pre)training are they acquired? We plot probing performance across iterations, using RoBERTa as a case study. Among our findings: linguistic knowledge is acquired fast, stably, and robustly across domains. Facts and commonsense are slower and more domain-sensitive. Reasoning abilities are, in general, not stably acquired. As new datasets, pretraining protocols, and probes emerge, we believe that probing-across-time analyses can help researchers understand the complex, intermingled learning that these models undergo and guide us toward more efficient approaches that accomplish necessary learning faster.
Finetuning Pretrained Transformers into RNNs
Mar 24, 2021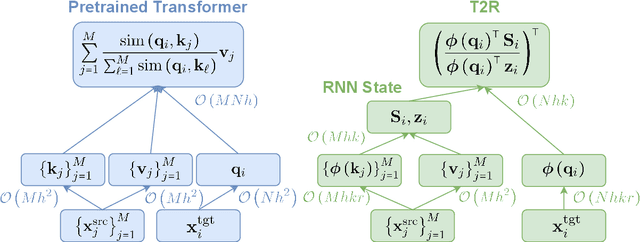
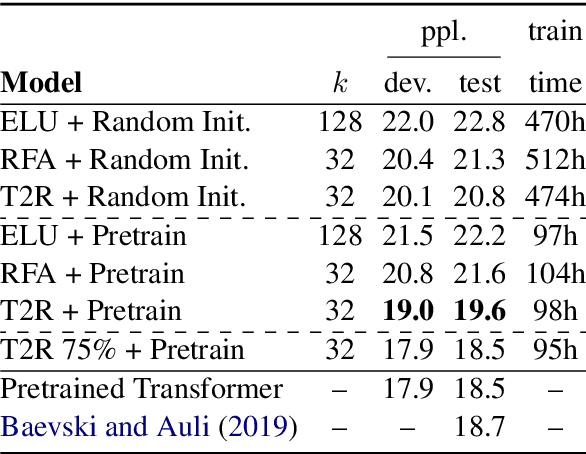
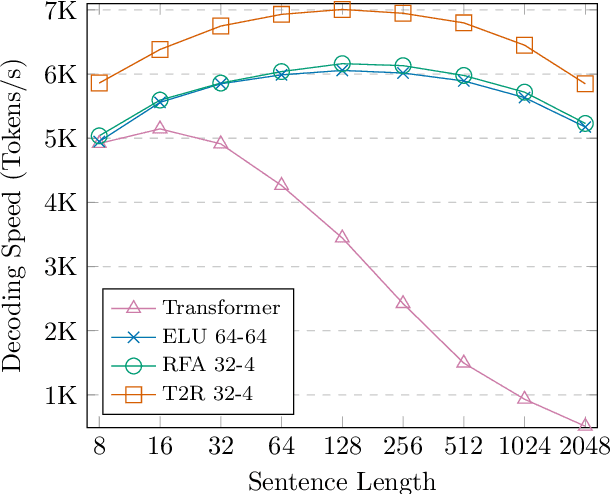
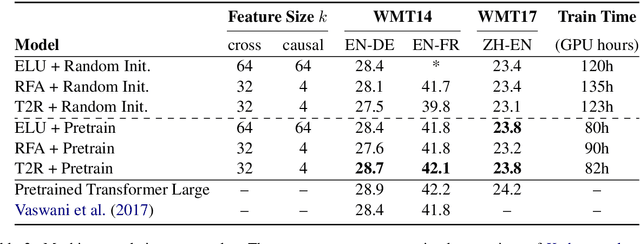
Transformers have outperformed recurrent neural networks (RNNs) in natural language generation. This comes with a significant computational overhead, as the attention mechanism scales with a quadratic complexity in sequence length. Efficient transformer variants have received increasing interest from recent works. Among them, a linear-complexity recurrent variant has proven well suited for autoregressive generation. It approximates the softmax attention with randomized or heuristic feature maps, but can be difficult to train or yield suboptimal accuracy. This work aims to convert a pretrained transformer into its efficient recurrent counterpart, improving the efficiency while retaining the accuracy. Specifically, we propose a swap-then-finetune procedure: in an off-the-shelf pretrained transformer, we replace the softmax attention with its linear-complexity recurrent alternative and then finetune. With a learned feature map, our approach provides an improved tradeoff between efficiency and accuracy over the standard transformer and other recurrent variants. We also show that the finetuning process needs lower training cost than training these recurrent variants from scratch. As many recent models for natural language tasks are increasingly dependent on large-scale pretrained transformers, this work presents a viable approach to improving inference efficiency without repeating the expensive pretraining process.
GENIE: A Leaderboard for Human-in-the-Loop Evaluation of Text Generation
Jan 17, 2021

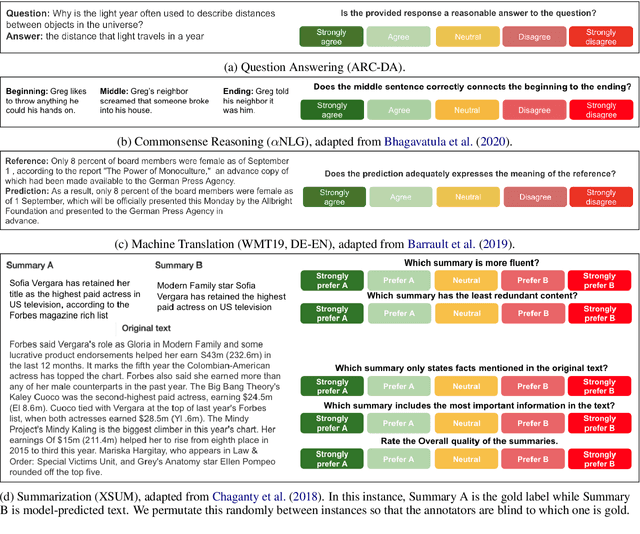
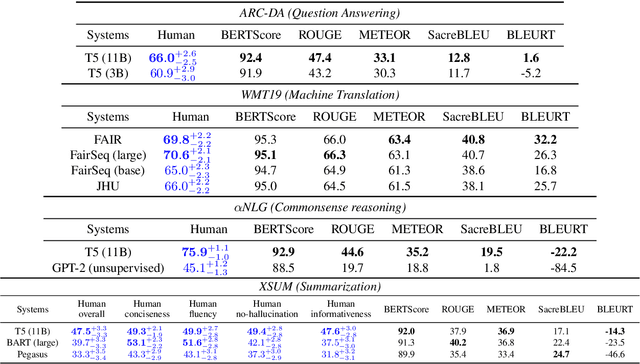
Leaderboards have eased model development for many NLP datasets by standardizing their evaluation and delegating it to an independent external repository. Their adoption, however, is so far limited to tasks that can be reliably evaluated in an automatic manner. This work introduces GENIE, an extensible human evaluation leaderboard, which brings the ease of leaderboards to text generation tasks. GENIE automatically posts leaderboard submissions to crowdsourcing platforms asking human annotators to evaluate them on various axes (e.g., correctness, conciseness, fluency) and compares their answers to various automatic metrics. We introduce several datasets in English to GENIE, representing four core challenges in text generation: machine translation, summarization, commonsense reasoning, and machine comprehension. We provide formal granular evaluation metrics and identify areas for future research. We make GENIE publicly available and hope that it will spur progress in language generation models as well as their automatic and manual evaluation.
XOR QA: Cross-lingual Open-Retrieval Question Answering
Oct 24, 2020
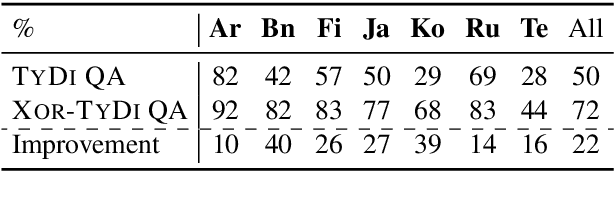
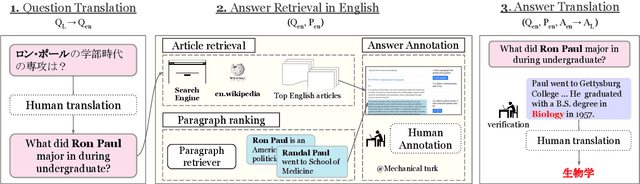
Multilingual question answering tasks typically assume answers exist in the same language as the question. Yet in practice, many languages face both information scarcity---where languages have few reference articles---and information asymmetry---where questions reference concepts from other cultures. This work extends open-retrieval question answering to a cross-lingual setting enabling questions from one language to be answered via answer content from another language. We construct a large-scale dataset built on questions from TyDi QA lacking same-language answers. Our task formulation, called Cross-lingual Open Retrieval Question Answering (XOR QA), includes 40k information-seeking questions from across 7 diverse non-English languages. Based on this dataset, we introduce three new tasks that involve cross-lingual document retrieval using multi-lingual and English resources. We establish baselines with state-of-the-art machine translation systems and cross-lingual pretrained models. Experimental results suggest that XOR QA is a challenging task that will facilitate the development of novel techniques for multilingual question answering. Our data and code are available at https://nlp.cs.washington.edu/xorqa.
Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation
Jun 28, 2020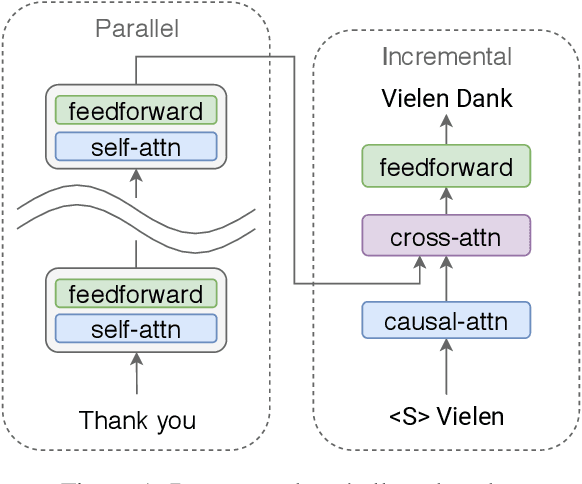

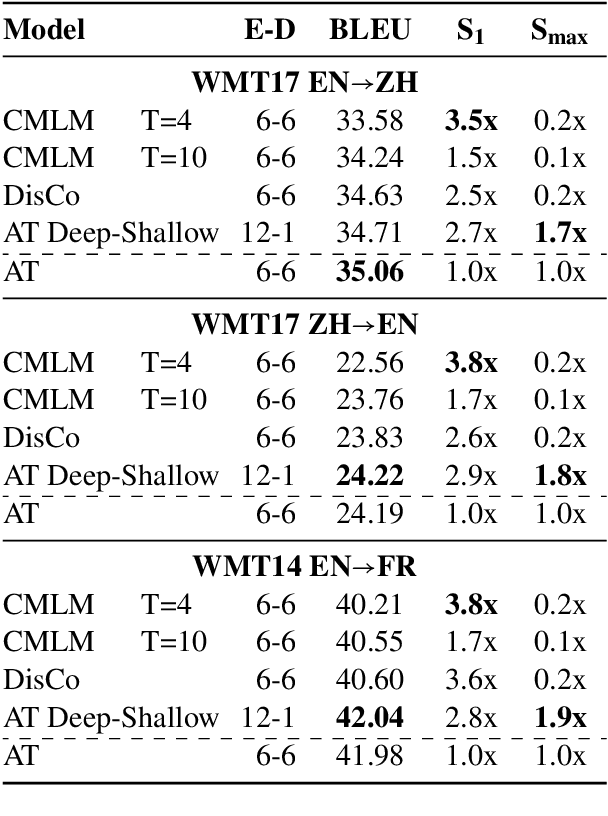
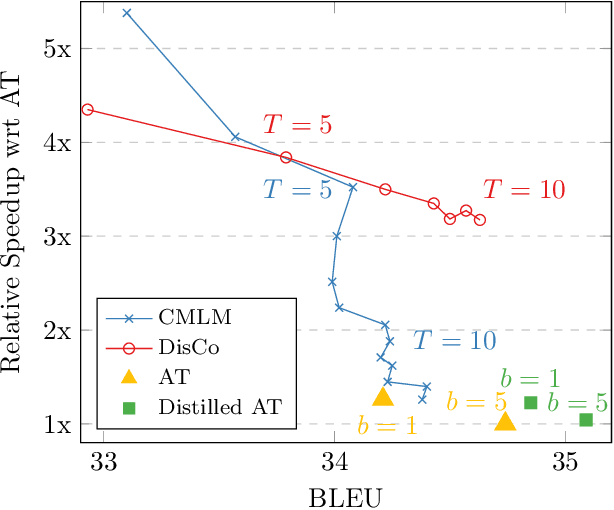
State-of-the-art neural machine translation models generate outputs autoregressively, where every step conditions on the previously generated tokens. This sequential nature causes inherent decoding latency. Non-autoregressive translation techniques, on the other hand, parallelize generation across positions and speed up inference at the expense of translation quality. Much recent effort has been devoted to non-autoregressive methods, aiming for a better balance between speed and quality. In this work, we re-examine the trade-off and argue that transformer-based autoregressive models can be substantially sped up without loss in accuracy. Specifically, we study autoregressive models with encoders and decoders of varied depths. Our extensive experiments show that given a sufficiently deep encoder, a one-layer autoregressive decoder yields state-of-the-art accuracy with comparable latency to strong non-autoregressive models. Our findings suggest that the latency disadvantage for autoregressive translation has been overestimated due to a suboptimal choice of layer allocation, and we provide a new speed-quality baseline for future research toward fast, accurate translation.
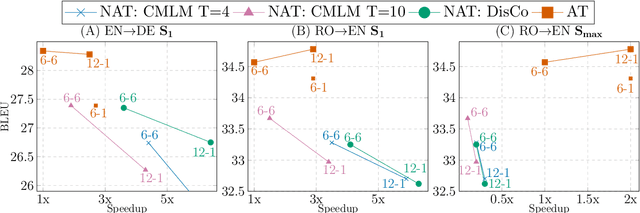
Parallel Machine Translation with Disentangled Context Transformer
Jan 15, 2020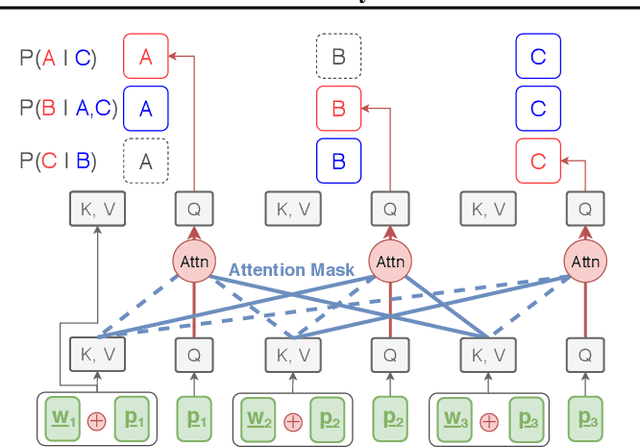
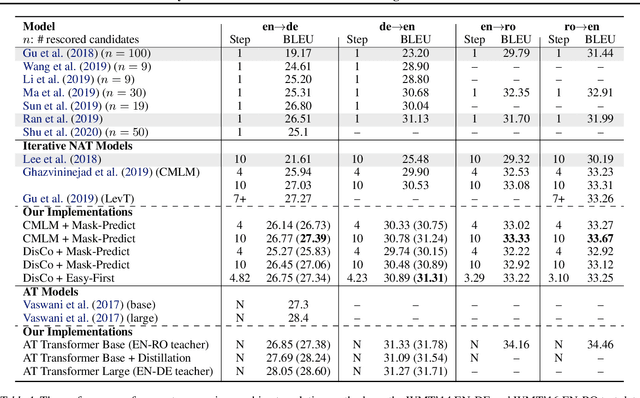
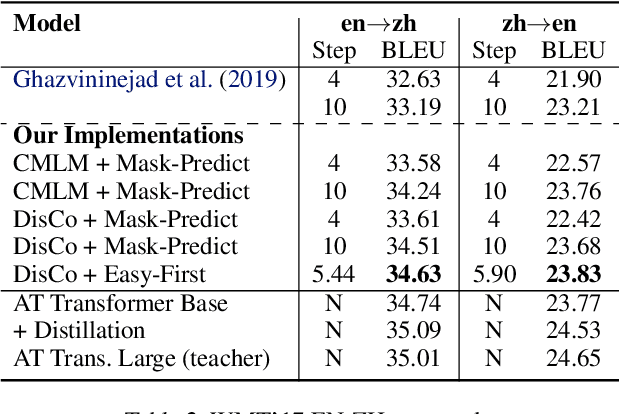
State-of-the-art neural machine translation models generate a translation from left to right and every step is conditioned on the previously generated tokens. The sequential nature of this generation process causes fundamental latency in inference since we cannot generate multiple tokens in each sentence in parallel. We propose an attention-masking based model, called Disentangled Context (DisCo) transformer, that simultaneously generates all tokens given different contexts. The DisCo transformer is trained to predict every output token given an arbitrary subset of the other reference tokens. We also develop the parallel easy-first inference algorithm, which iteratively refines every token in parallel and reduces the number of required iterations. Our extensive experiments on 7 directions with varying data sizes demonstrate that our model achieves competitive, if not better, performance compared to the state of the art in non-autoregressive machine translation while significantly reducing decoding time on average.