 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-Efficient Black-box Adversarial Attacks Guided by a Transfer-based Prior
Mar 13, 2022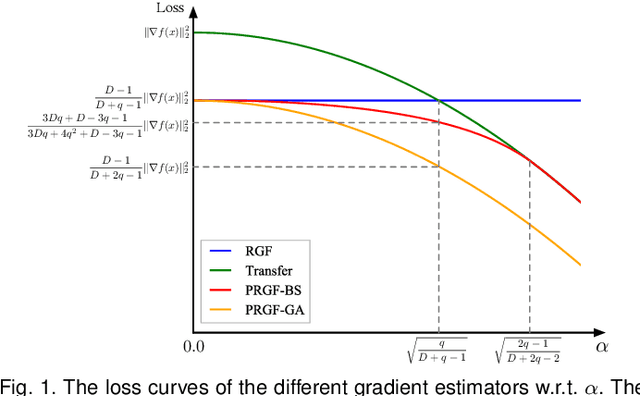
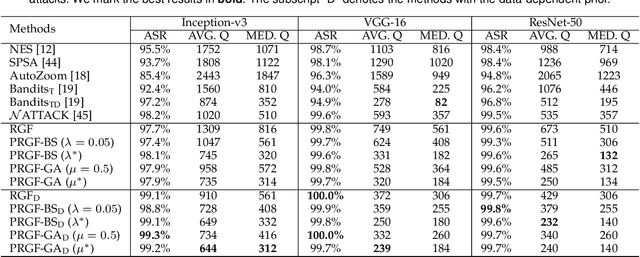
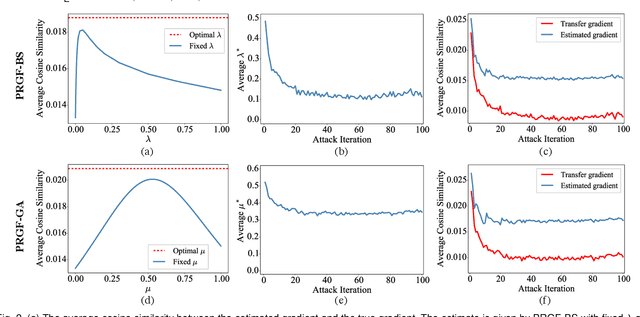
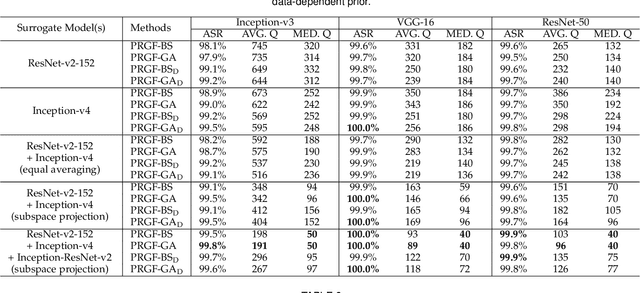
Adversarial attacks have been extensively studied in recent years since they can identify the vulnerability of deep learning models before deployed. In this paper, we consider the black-box adversarial setting, where the adversary needs to craft adversarial examples without access to the gradients of a target model. Previous methods attempted to approximate the true gradient either by using the transfer gradient of a surrogate white-box model or based on the feedback of model queries. However, the existing methods inevitably suffer from low attack success rates or poor query efficiency since it is difficult to estimate the gradient in a high-dimensional input space with limited information. To address these problems and improve black-box attacks, we propose two prior-guided random gradient-free (PRGF) algorithms based on biased sampling and gradient averaging, respectively. Our methods can take the advantage of a transfer-based prior given by the gradient of a surrogate model and the query information simultaneously. Through theoretical analyses, the transfer-based prior is appropriately integrated with model queries by an optimal coefficient in each method. Extensive experiments demonstrate that, in comparison with the alternative state-of-the-arts, both of our methods require much fewer queries to attack black-box models with higher success rates.
Controllable Evaluation and Generation of Physical Adversarial Patch on Face Recognition
Mar 10, 2022
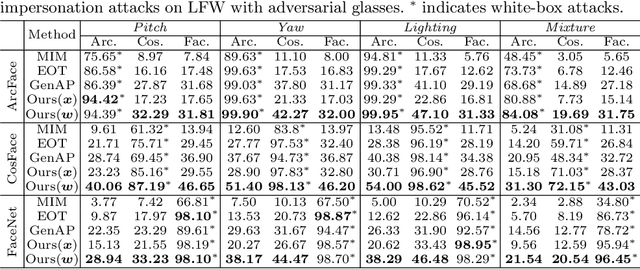
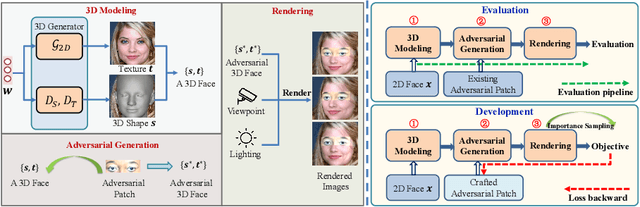
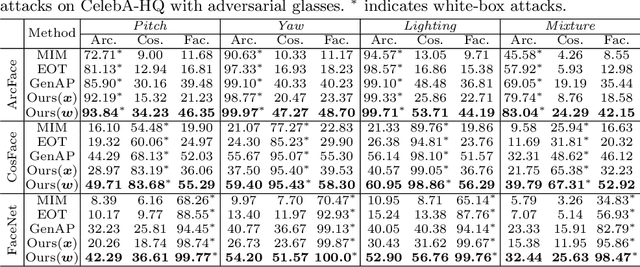
Recent studies have revealed the vulnerability of face recognition models against physical adversarial patches, which raises security concerns about the deployed face recognition systems. However, it is still challenging to ensure the reproducibility for most attack algorithms under complex physical conditions, which leads to the lack of a systematic evaluation of the existing methods. It is therefore imperative to develop a framework that can enable a comprehensive evaluation of the vulnerability of face recognition in the physical world. To this end, we propose to simulate the complex transformations of faces in the physical world via 3D-face modeling, which serves as a digital counterpart of physical faces. The generic framework allows us to control different face variations and physical conditions to conduct reproducible evaluations comprehensively. With this digital simulator, we further propose a Face3DAdv method considering the 3D face transformations and realistic physical variations. Extensive experiments validate that Face3DAdv can significantly improve the effectiveness of diverse physically realizable adversarial patches in both simulated and physical environments, against various white-box and black-box face recognition models.
Memory Replay with Data Compression for Continual Learning
Mar 09, 2022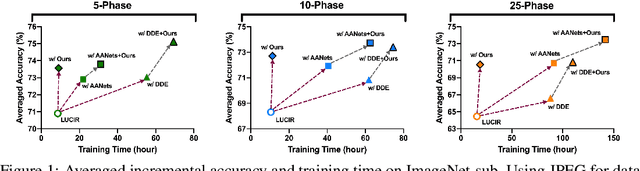
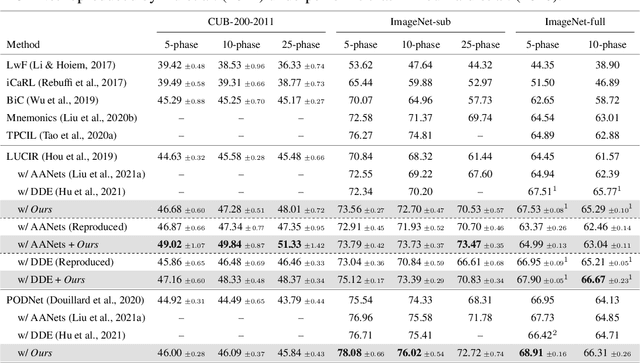
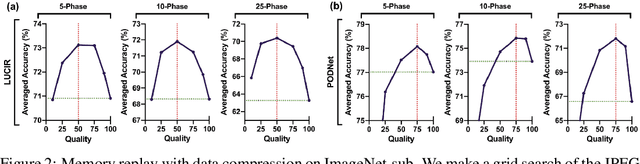
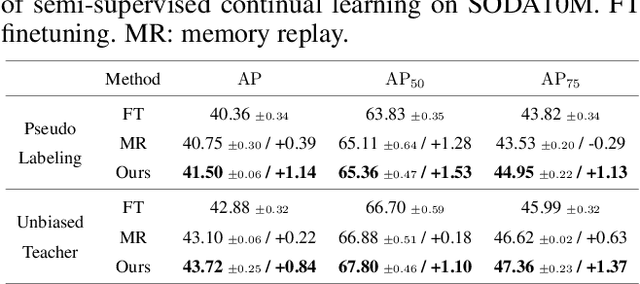
Continual learning needs to overcome catastrophic forgetting of the past. Memory replay of representative old training samples has been shown as an effective solution, and achieves the state-of-the-art (SOTA) performance. However, existing work is mainly built on a small memory buffer containing a few original data, which cannot fully characterize the old data distribution. In this work, we propose memory replay with data compression (MRDC) to reduce the storage cost of old training samples and thus increase their amount that can be stored in the memory buffer. Observing that the trade-off between the quality and quantity of compressed data is highly nontrivial for the efficacy of memory replay, we propose a novel method based on determinantal point processes (DPPs) to efficiently determine an appropriate compression quality for currently-arrived training samples. In this way, using a naive data compression algorithm with a properly selected quality can largely boost recent strong baselines by saving more compressed data in a limited storage space. We extensively validate this across several benchmarks of class-incremental learning and in a realistic scenario of object detection for autonomous driving.
* arXiv admin note: text overlap with arXiv:1207.6083 by other authors
Robustness and Accuracy Could Be Reconcilable by (Proper) Definition
Feb 21, 2022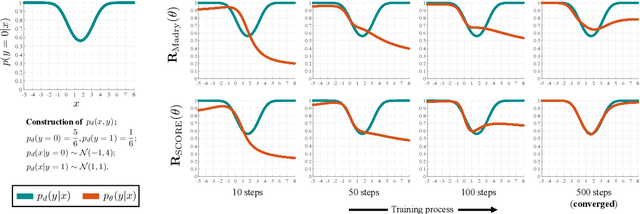
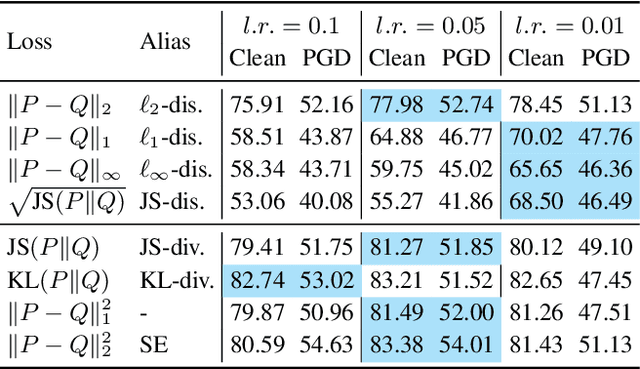
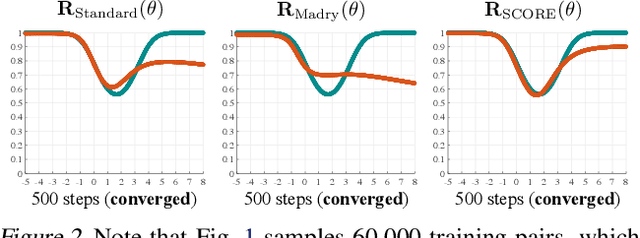
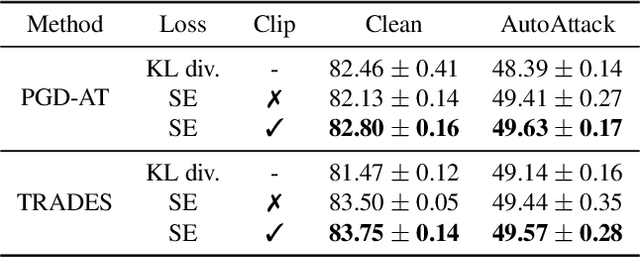
The trade-off between robustness and accuracy has been widely studied in the adversarial literature. Although still controversial, the prevailing view is that this trade-off is inherent, either empirically or theoretically. Thus, we dig for the origin of this trade-off in adversarial training and find that it may stem from the improperly defined robust error, which imposes an inductive bias of local invariance -- an overcorrection towards smoothness. Given this, we advocate employing local equivariance to describe the ideal behavior of a robust model, leading to a self-consistent robust error named SCORE. By definition, SCORE facilitates the reconciliation between robustness and accuracy, while still handling the worst-case uncertainty via robust optimization. By simply substituting KL divergence with variants of distance metrics, SCORE can be efficiently minimized. Empirically, our models achieve top-rank performance on RobustBench under AutoAttack. Besides, SCORE provides instructive insights for explaining the overfitting phenomenon and semantic input gradients observed on robust models.
DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR
Feb 08, 2022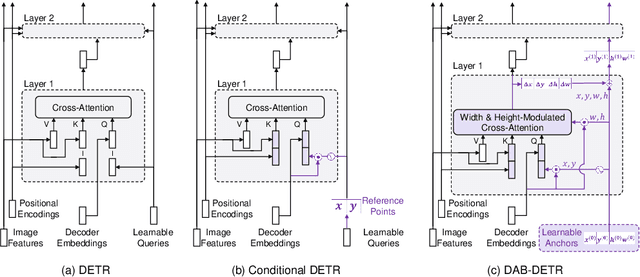


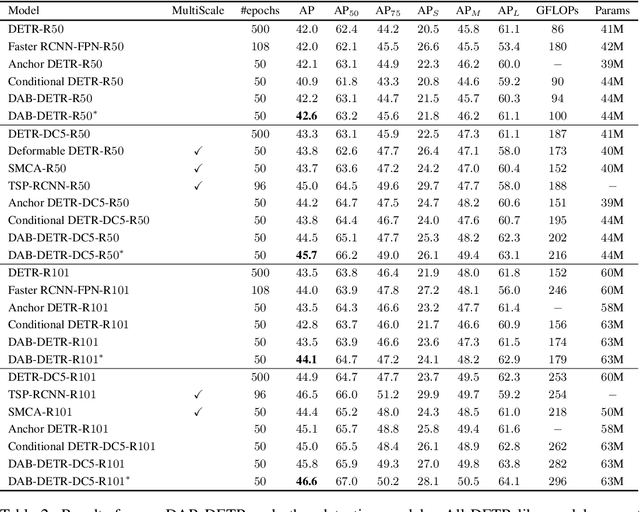
We present in this paper a novel query formulation using dynamic anchor boxes for DETR (DEtection TRansformer) and offer a deeper understanding of the role of queries in DETR. This new formulation directly uses box coordinates as queries in Transformer decoders and dynamically updates them layer-by-layer. Using box coordinates not only helps using explicit positional priors to improve the query-to-feature similarity and eliminate the slow training convergence issue in DETR, but also allows us to modulate the positional attention map using the box width and height information. Such a design makes it clear that queries in DETR can be implemented as performing soft ROI pooling layer-by-layer in a cascade manner. As a result, it leads to the best performance on MS-COCO benchmark among the DETR-like detection models under the same setting, e.g., AP 45.7\% using ResNet50-DC5 as backbone trained in 50 epochs. We also conducted extensive experiments to confirm our analysis and verify the effectiveness of our methods. Code is available at \url{https://github.com/SlongLiu/DAB-DETR}.
Analytic-DPM: an Analytic Estimate of the Optimal Reverse Variance in Diffusion Probabilistic Models
Jan 17, 2022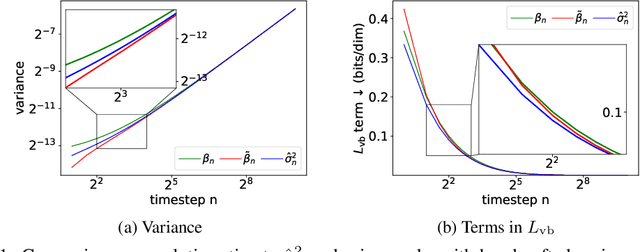
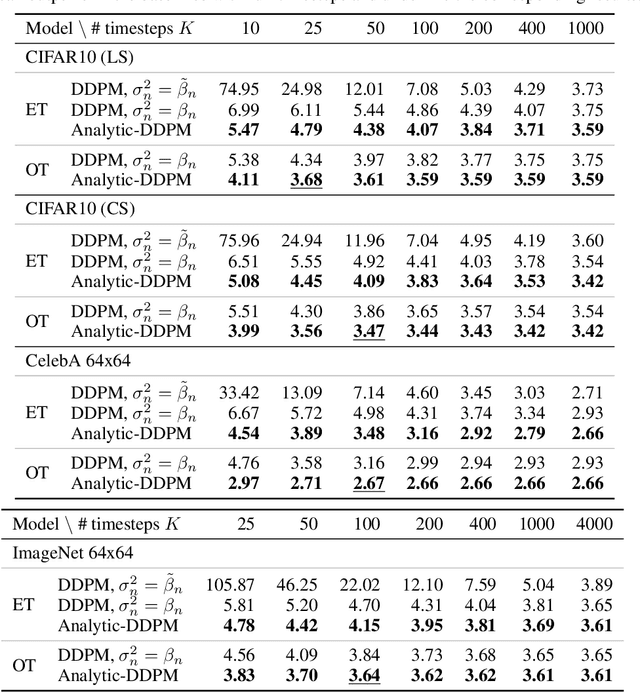
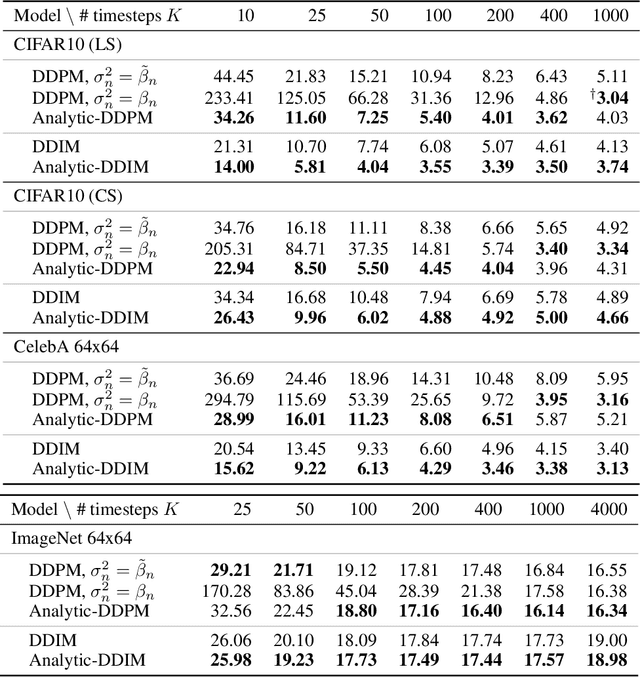
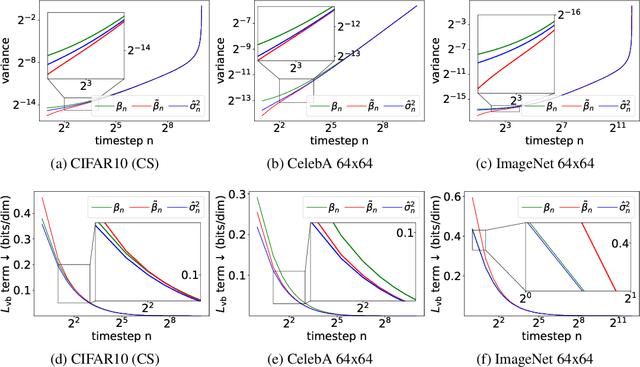
Diffusion probabilistic models (DPMs) represent a class of powerful generative models. Despite their success, the inference of DPMs is expensive since it generally needs to iterate over thousands of timesteps. A key problem in the inference is to estimate the variance in each timestep of the reverse process. In this work, we present a surprising result that both the optimal reverse variance and the corresponding optimal KL divergence of a DPM have analytic forms w.r.t. its score function. Building upon it, we propose Analytic-DPM, a training-free inference framework that estimates the analytic forms of the variance and KL divergence using the Monte Carlo method and a pretrained score-based model. Further, to correct the potential bias caused by the score-based model, we derive both lower and upper bounds of the optimal variance and clip the estimate for a better result. Empirically, our analytic-DPM improves the log-likelihood of various DPMs, produces high-quality samples, and meanwhile enjoys a 20x to 80x speed up.
Improving Next-Application Prediction with Deep Personalized-Attention Neural Network
Nov 09, 2021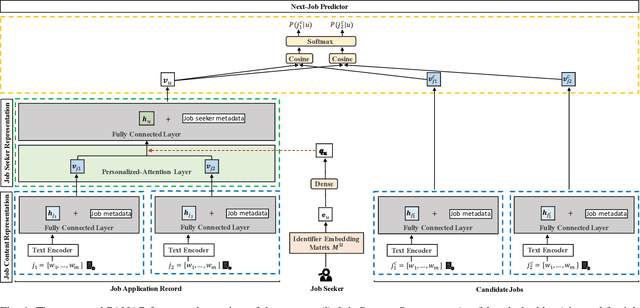
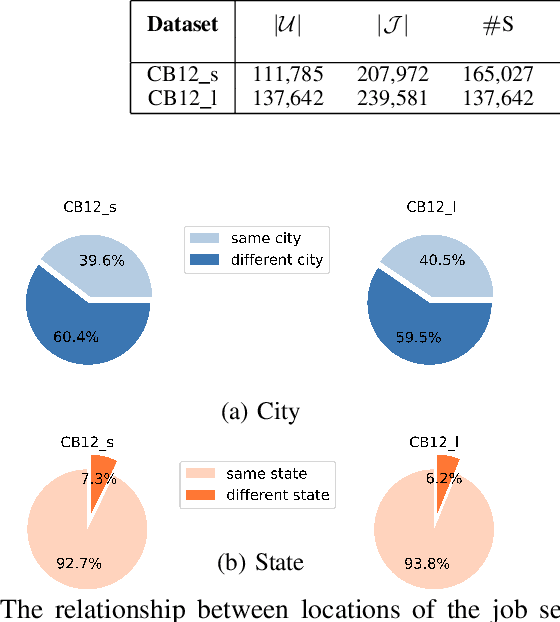
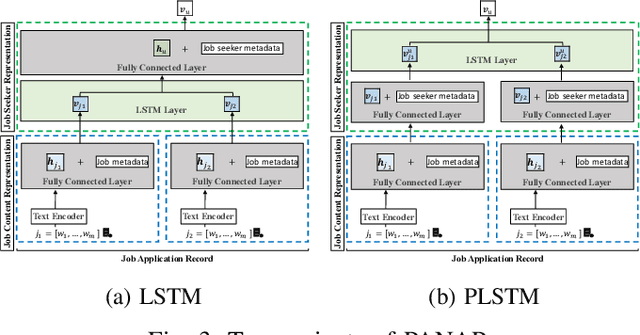
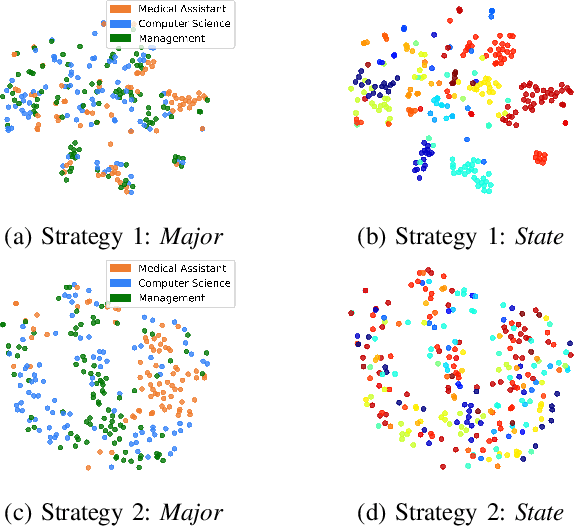
Recently, due to the ubiquity and supremacy of E-recruitment platforms, job recommender systems have been largely studied. In this paper, we tackle the next job application problem, which has many practical applications. In particular, we propose to leverage next-item recommendation approaches to consider better the job seeker's career preference to discover the next relevant job postings (referred to jobs for short) they might apply for. Our proposed model, named Personalized-Attention Next-Application Prediction (PANAP), is composed of three modules. The first module learns job representations from textual content and metadata attributes in an unsupervised way. The second module learns job seeker representations. It includes a personalized-attention mechanism that can adapt the importance of each job in the learned career preference representation to the specific job seeker's profile. The attention mechanism also brings some interpretability to learned representations. Then, the third module models the Next-Application Prediction task as a top-K search process based on the similarity of representations. In addition, the geographic location is an essential factor that affects the preferences of job seekers in the recruitment domain. Therefore, we explore the influence of geographic location on the model performance from the perspective of negative sampling strategies. Experiments on the public CareerBuilder12 dataset show the interest in our approach.
AFEC: Active Forgetting of Negative Transfer in Continual Learning
Nov 04, 2021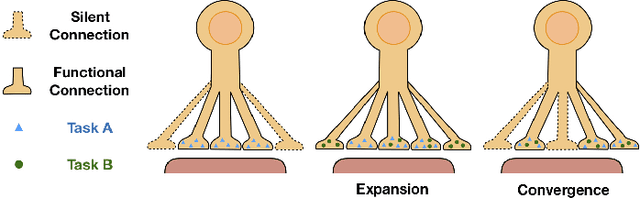
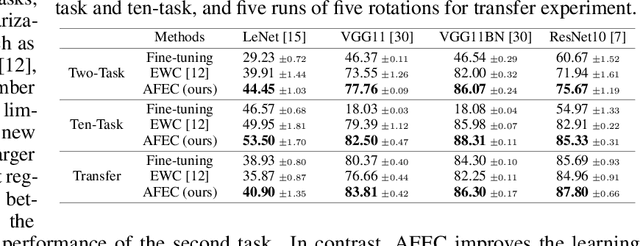
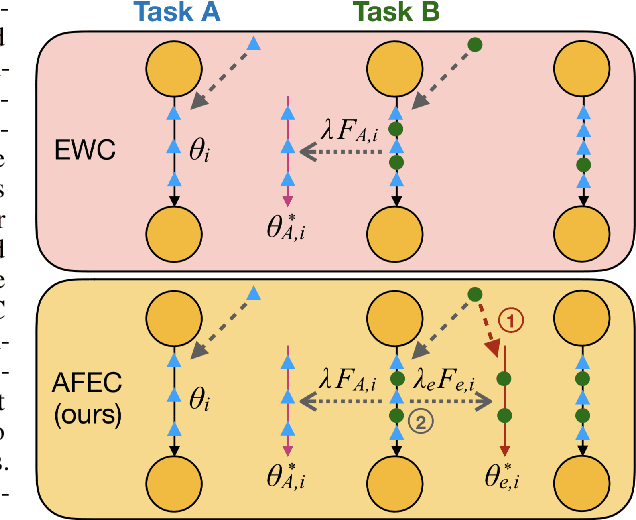
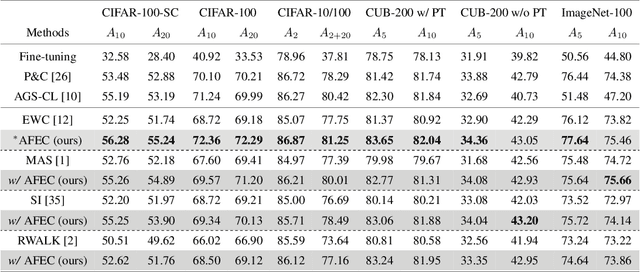
Continual learning aims to learn a sequence of tasks from dynamic data distributions. Without accessing to the old training samples, knowledge transfer from the old tasks to each new task is difficult to determine, which might be either positive or negative. If the old knowledge interferes with the learning of a new task, i.e., the forward knowledge transfer is negative, then precisely remembering the old tasks will further aggravate the interference, thus decreasing the performance of continual learning. By contrast, biological neural networks can actively forget the old knowledge that conflicts with the learning of a new experience, through regulating the learning-triggered synaptic expansion and synaptic convergence. Inspired by the biological active forgetting, we propose to actively forget the old knowledge that limits the learning of new tasks to benefit continual learning. Under the framework of Bayesian continual learning, we develop a novel approach named Active Forgetting with synaptic Expansion-Convergence (AFEC). Our method dynamically expands parameters to learn each new task and then selectively combines them, which is formally consistent with the underlying mechanism of biological active forgetting. We extensively evaluate AFEC on a variety of continual learning benchmarks, including CIFAR-10 regression tasks, visual classification tasks and Atari reinforcement tasks, where AFEC effectively improves the learning of new tasks and achieves the state-of-the-art performance in a plug-and-play way.
Unrestricted Adversarial Attacks on ImageNet Competition
Oct 25, 2021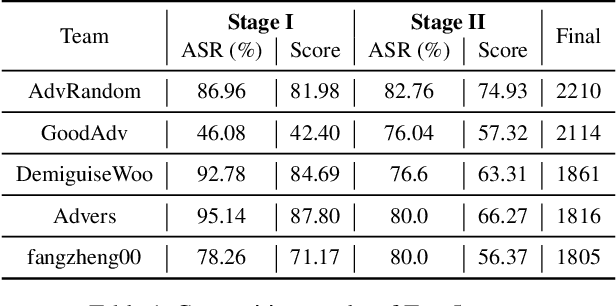
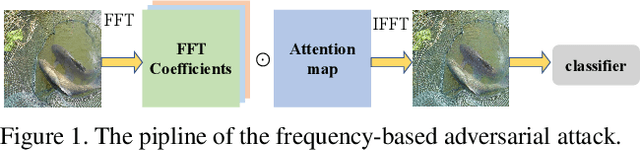
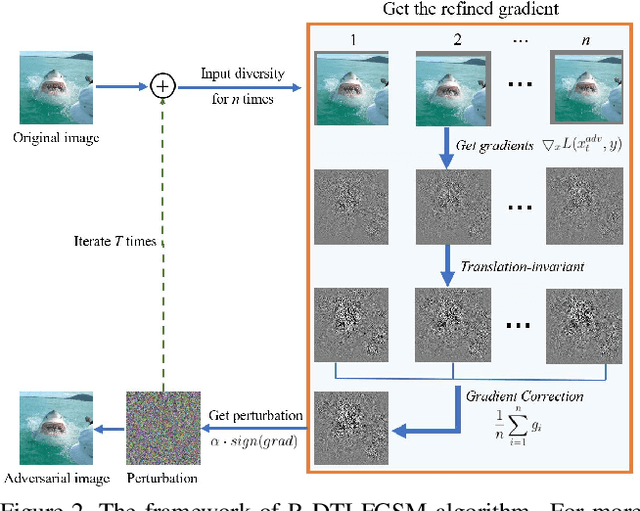
Many works have investigated the adversarial attacks or defenses under the settings where a bounded and imperceptible perturbation can be added to the input. However in the real-world, the attacker does not need to comply with this restriction. In fact, more threats to the deep model come from unrestricted adversarial examples, that is, the attacker makes large and visible modifications on the image, which causes the model classifying mistakenly, but does not affect the normal observation in human perspective. Unrestricted adversarial attack is a popular and practical direction but has not been studied thoroughly. We organize this competition with the purpose of exploring more effective unrestricted adversarial attack algorithm, so as to accelerate the academical research on the model robustness under stronger unbounded attacks. The competition is held on the TianChi platform (\url{https://tianchi.aliyun.com/competition/entrance/531853/introduction}) as one of the series of AI Security Challengers Program.
TiKick: Towards Playing Multi-agent Football Full Games from Single-agent Demonstrations
Oct 19, 2021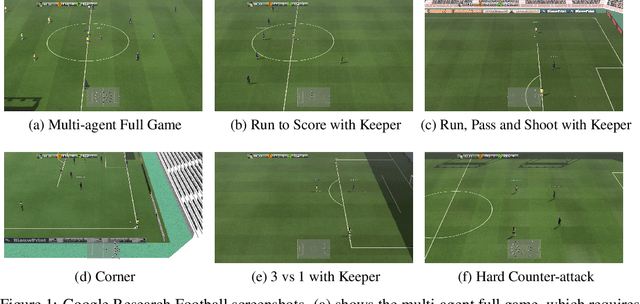

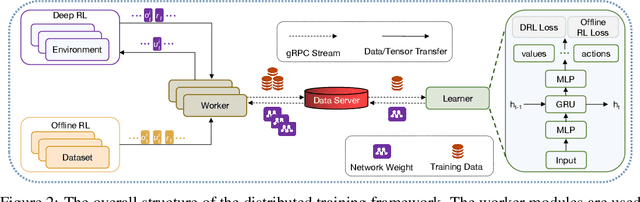
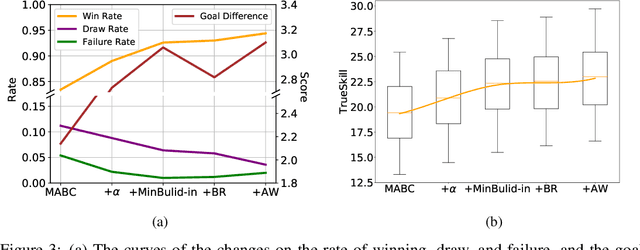
Deep reinforcement learning (DRL) has achieved super-human performance on complex video games (e.g., StarCraft II and Dota II). However, current DRL systems still suffer from challenges of multi-agent coordination, sparse rewards, stochastic environments, etc. In seeking to address these challenges, we employ a football video game, e.g., Google Research Football (GRF), as our testbed and develop an end-to-end learning-based AI system (denoted as TiKick) to complete this challenging task. In this work, we first generated a large replay dataset from the self-playing of single-agent experts, which are obtained from league training. We then developed a distributed learning system and new offline algorithms to learn a powerful multi-agent AI from the fixed single-agent dataset. To the best of our knowledge, Tikick is the first learning-based AI system that can take over the multi-agent Google Research Football full game, while previous work could either control a single agent or experiment on toy academic scenarios. Extensive experiments further show that our pre-trained model can accelerate the training process of the modern multi-agent algorithm and our method achieves state-of-the-art performances on various academic scenarios.