 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiCE: Mixture of Contrastive Experts for Unsupervised Image Clustering
May 05, 2021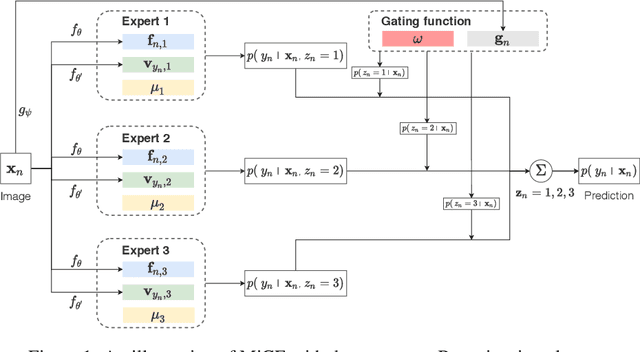
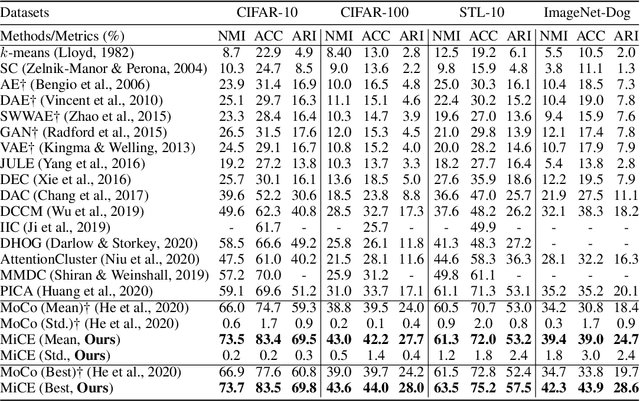

We present Mixture of Contrastive Experts (MiCE), a unified probabilistic clustering framework that simultaneously exploits the discriminative representations learned by contrastive learning and the semantic structures captured by a latent mixture model. Motivated by the mixture of experts, MiCE employs a gating function to partition an unlabeled dataset into subsets according to the latent semantics and multiple experts to discriminate distinct subsets of instances assigned to them in a contrastive learning manner. To solve the nontrivial inference and learning problems caused by the latent variables, we further develop a scalable variant of the Expectation-Maximization (EM) algorithm for MiCE and provide proof of the convergence. Empirically, we evaluate the clustering performance of MiCE on four widely adopted natural image datasets. MiCE achieves significantly better results than various previous methods and a strong contrastive learning baseline.
D$\textbf{S}^3$L: Deep Self-Semi-Supervised Learning for Image Recognition
May 23, 2019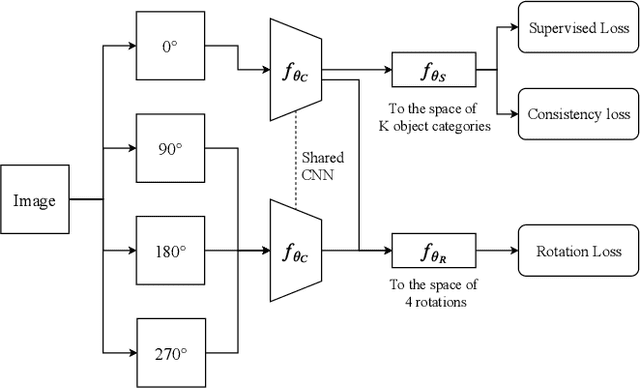
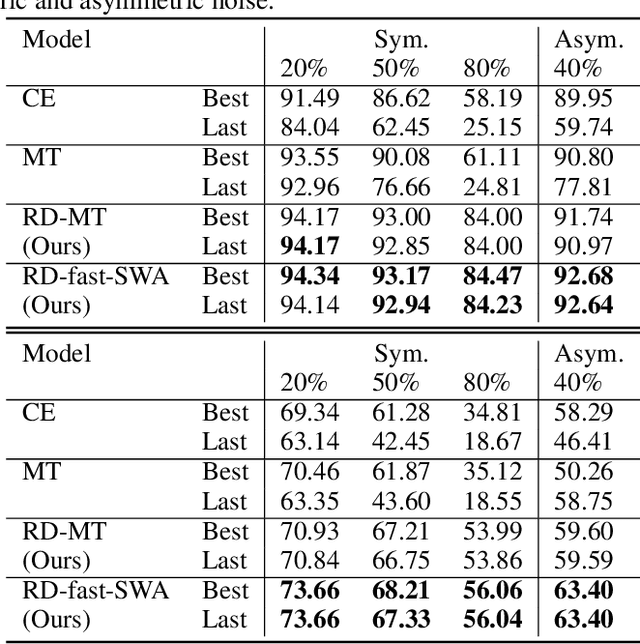
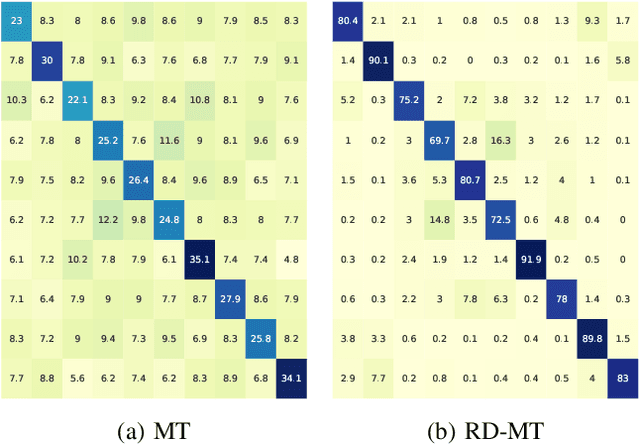
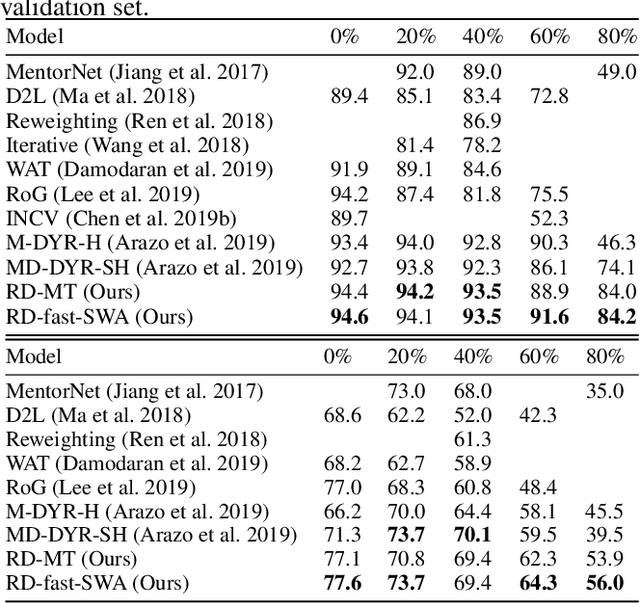
Despite the recent progress in deep semi-supervised learning (Semi-SL), the amount of labels still plays a dominant role. The success in self-supervised learning (Self-SL) hints a promising direction to exploit the vast unlabeled data by leveraging an additional set of deterministic labels. In this paper, we propose Deep Self-Semi-Supervised learning (D$S^3$L), a flexible multi-task framework with shared parameters that integrates the rotation task in Self-SL with the consistency-based methods in deep Semi-SL. Our method is easy to implement and is complementary to all consistency-based approaches. The experiments demonstrate that our method significantly improves over the published state-of-the-art methods on several standard benchmarks, especially when fewer labels are presented.