 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTART: Traversing Sparse Footholds with Terrain Reconstruction
Dec 15, 2025


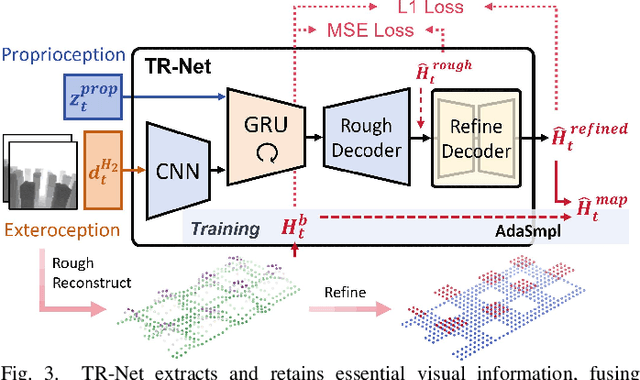
Traversing terrains with sparse footholds like legged animals presents a promising yet challenging task for quadruped robots, as it requires precise environmental perception and agile control to secure safe foot placement while maintaining dynamic stability. Model-based hierarchical controllers excel in laboratory settings, but suffer from limited generalization and overly conservative behaviors. End-to-end learning-based approaches unlock greater flexibility and adaptability, but existing state-of-the-art methods either rely on heightmaps that introduce noise and complex, costly pipelines, or implicitly infer terrain features from egocentric depth images, often missing accurate critical geometric cues and leading to inefficient learning and rigid gaits. To overcome these limitations, we propose START, a single-stage learning framework that enables agile, stable locomotion on highly sparse and randomized footholds. START leverages only low-cost onboard vision and proprioception to accurately reconstruct local terrain heightmap, providing an explicit intermediate representation to convey essential features relevant to sparse foothold regions. This supports comprehensive environmental understanding and precise terrain assessment, reducing exploration cost and accelerating skill acquisition. Experimental results demonstrate that START achieves zero-shot transfer across diverse real-world scenarios, showcasing superior adaptability, precise foothold placement, and robust locomotion.
Data Value in the Age of Scaling: Understanding LLM Scaling Dynamics Under Real-Synthetic Data Mixtures
Nov 17, 2025



The rapid progress of large language models (LLMs) is fueled by the growing reliance on datasets that blend real and synthetic data. While synthetic data offers scalability and cost-efficiency, it often introduces systematic distributional discrepancies, particularly underrepresenting long-tail knowledge due to truncation effects from data generation mechanisms like top-p sampling, temperature scaling, and finite sampling. These discrepancies pose fundamental challenges in characterizing and evaluating the utility of mixed real-synthetic datasets. In this paper, we identify a three-phase scaling behavior characterized by two breakpoints that reflect transitions in model behavior across learning head and tail knowledge. We further derive an LLM generalization bound designed for real and synthetic mixtures, revealing several key factors that govern their generalization performance. Building on our theoretical findings, we propose an effective yet efficient data valuation method that scales to large-scale datasets. Comprehensive experiments across four tasks, including image classification, sentiment classification, instruction following, and complex reasoning, demonstrate that our method surpasses state-of-the-art baselines in data valuation with significantly low computational cost.
StyleDecipher: Robust and Explainable Detection of LLM-Generated Texts with Stylistic Analysis
Oct 14, 2025With the increasing integration of large language models (LLMs) into open-domain writing, detecting machine-generated text has become a critical task for ensuring content authenticity and trust. Existing approaches rely on statistical discrepancies or model-specific heuristics to distinguish between LLM-generated and human-written text. However, these methods struggle in real-world scenarios due to limited generalization, vulnerability to paraphrasing, and lack of explainability, particularly when facing stylistic diversity or hybrid human-AI authorship. In this work, we propose StyleDecipher, a robust and explainable detection framework that revisits LLM-generated text detection using combined feature extractors to quantify stylistic differences. By jointly modeling discrete stylistic indicators and continuous stylistic representations derived from semantic embeddings, StyleDecipher captures distinctive style-level divergences between human and LLM outputs within a unified representation space. This framework enables accurate, explainable, and domain-agnostic detection without requiring access to model internals or labeled segments. Extensive experiments across five diverse domains, including news, code, essays, reviews, and academic abstracts, demonstrate that StyleDecipher consistently achieves state-of-the-art in-domain accuracy. Moreover, in cross-domain evaluations, it surpasses existing baselines by up to 36.30%, while maintaining robustness against adversarial perturbations and mixed human-AI content. Further qualitative and quantitative analysis confirms that stylistic signals provide explainable evidence for distinguishing machine-generated text. Our source code can be accessed at https://github.com/SiyuanLi00/StyleDecipher.
Toward Multi-Functional LAWNs with ISAC: Opportunities, Challenges, and the Road Ahead
Aug 24, 2025



Integrated sensing and communication (ISAC) has been envisioned as a foundational technology for future low-altitude wireless networks (LAWNs), enabling real-time environmental perception and data exchange across aerial-ground systems. In this article, we first explore the roles of ISAC in LAWNs from both node-level and network-level perspectives. We highlight the performance gains achieved through hierarchical integration and cooperation, wherein key design trade-offs are demonstrated. Apart from physical-layer enhancements, emerging LAWN applications demand broader functionalities. To this end, we propose a multi-functional LAWN framework that extends ISAC with capabilities in control, computation, wireless power transfer, and large language model (LLM)-based intelligence. We further provide a representative case study to present the benefits of ISAC-enabled LAWNs and the promising research directions are finally outlined.
ZPD-SCA: Unveiling the Blind Spots of LLMs in Assessing Students' Cognitive Abilities
Aug 20, 2025



Large language models (LLMs) have demonstrated potential in educational applications, yet their capacity to accurately assess the cognitive alignment of reading materials with students' developmental stages remains insufficiently explored. This gap is particularly critical given the foundational educational principle of the Zone of Proximal Development (ZPD), which emphasizes the need to match learning resources with Students' Cognitive Abilities (SCA). Despite the importance of this alignment, there is a notable absence of comprehensive studies investigating LLMs' ability to evaluate reading comprehension difficulty across different student age groups, especially in the context of Chinese language education. To fill this gap, we introduce ZPD-SCA, a novel benchmark specifically designed to assess stage-level Chinese reading comprehension difficulty. The benchmark is annotated by 60 Special Grade teachers, a group that represents the top 0.15% of all in-service teachers nationwide. Experimental results reveal that LLMs perform poorly in zero-shot learning scenarios, with Qwen-max and GLM even falling below the probability of random guessing. When provided with in-context examples, LLMs performance improves substantially, with some models achieving nearly double the accuracy of their zero-shot baselines. These results reveal that LLMs possess emerging abilities to assess reading difficulty, while also exposing limitations in their current training for educationally aligned judgment. Notably, even the best-performing models display systematic directional biases, suggesting difficulties in accurately aligning material difficulty with SCA. Furthermore, significant variations in model performance across different genres underscore the complexity of task. We envision that ZPD-SCA can provide a foundation for evaluating and improving LLMs in cognitively aligned educational applications.
Advancing the Control of Low-Altitude Wireless Networks: Architecture, Design Principles, and Future Directions
Aug 11, 2025



This article introduces a control-oriented low-altitude wireless network (LAWN) that integrates near-ground communications and remote estimation of the internal system state. This integration supports reliable networked control in dynamic aerial-ground environments. First, we introduce the network's modular architecture and key performance metrics. Then, we discuss core design trade-offs across the control, communication, and estimation layers. A case study illustrates closed-loop coordination under wireless constraints. Finally, we outline future directions for scalable, resilient LAWN deployments in real-time and resource-constrained scenarios.
Model-Agnostic Sentiment Distribution Stability Analysis for Robust LLM-Generated Texts Detection
Aug 09, 2025



The rapid advancement of large language models (LLMs) has resulted in increasingly sophisticated AI-generated content, posing significant challenges in distinguishing LLM-generated text from human-written language. Existing detection methods, primarily based on lexical heuristics or fine-tuned classifiers, often suffer from limited generalizability and are vulnerable to paraphrasing, adversarial perturbations, and cross-domain shifts. In this work, we propose SentiDetect, a model-agnostic framework for detecting LLM-generated text by analyzing the divergence in sentiment distribution stability. Our method is motivated by the empirical observation that LLM outputs tend to exhibit emotionally consistent patterns, whereas human-written texts display greater emotional variability. To capture this phenomenon, we define two complementary metrics: sentiment distribution consistency and sentiment distribution preservation, which quantify stability under sentiment-altering and semantic-preserving transformations. We evaluate SentiDetect on five diverse datasets and a range of advanced LLMs,including Gemini-1.5-Pro, Claude-3, GPT-4-0613, and LLaMa-3.3. Experimental results demonstrate its superiority over state-of-the-art baselines, with over 16% and 11% F1 score improvements on Gemini-1.5-Pro and GPT-4-0613, respectively. Moreover, SentiDetect also shows greater robustness to paraphrasing, adversarial attacks, and text length variations, outperforming existing detectors in challenging scenarios.
Stereo 3D Gaussian Splatting SLAM for Outdoor Urban Scenes
Jul 31, 20253D Gaussian Splatting (3DGS) has recently gained popularity in SLAM applications due to its fast rendering and high-fidelity representation. However, existing 3DGS-SLAM systems have predominantly focused on indoor environments and relied on active depth sensors, leaving a gap for large-scale outdoor applications. We present BGS-SLAM, the first binocular 3D Gaussian Splatting SLAM system designed for outdoor scenarios. Our approach uses only RGB stereo pairs without requiring LiDAR or active sensors. BGS-SLAM leverages depth estimates from pre-trained deep stereo networks to guide 3D Gaussian optimization with a multi-loss strategy enhancing both geometric consistency and visual quality. Experiments on multiple datasets demonstrate that BGS-SLAM achieves superior tracking accuracy and mapping performance compared to other 3DGS-based solutions in complex outdoor environments.
Predictive Control over LAWN: Joint Trajectory Design and Resource Allocation
Jul 03, 2025



Low-altitude wireless networks (LAWNs) have been envisioned as flexible and transformative platforms for enabling delay-sensitive control applications in Internet of Things (IoT) systems. In this work, we investigate the real-time wireless control over a LAWN system, where an aerial drone is employed to serve multiple mobile automated guided vehicles (AGVs) via finite blocklength (FBL) transmission. Toward this end, we adopt the model predictive control (MPC) to ensure accurate trajectory tracking, while we analyze the communication reliability using the outage probability. Subsequently, we formulate an optimization problem to jointly determine control policy, transmit power allocation, and drone trajectory by accounting for the maximum travel distance and control input constraints. To address the resultant non-convex optimization problem, we first derive the closed-form expression of the outage probability under FBL transmission. Based on this, we reformulate the original problem as a quadratic programming (QP) problem, followed by developing an alternating optimization (AO) framework. Specifically, we employ the projected gradient descent (PGD) method and the successive convex approximation (SCA) technique to achieve computationally efficient sub-optimal solutions. Furthermore, we thoroughly analyze the convergence and computational complexity of the proposed algorithm. Extensive simulations and AirSim-based experiments are conducted to validate the superiority of our proposed approach compared to the baseline schemes in terms of control performance.
SDR-Empowered Environment Sensing Design and Experimental Validation Using OTFS-ISAC Signals
Jul 02, 2025This paper investigates the system design and experimental validation of integrated sensing and communication (ISAC) for environmental sensing, which is expected to be a critical enabler for next-generation wireless networks. We advocate exploiting orthogonal time frequency space (OTFS) modulation for its inherent sparsity and stability in delay-Doppler (DD) domain channels, facilitating a low-overhead environment sensing design. Moreover, a comprehensive environmental sensing framework is developed, encompassing DD domain channel estimation, target localization, and experimental validation. In particular, we first explore the OTFS channel estimation in the presence of fractional delay and Doppler shifts. Given the estimated parameters, we propose a three-ellipse positioning algorithm to localize the target's position, followed by determining the mobile transmitter's velocity. Additionally, to evaluate the performance of our proposed design, we conduct extensive simulations and experiments using a software-defined radio (SDR)-based platform with universal software radio peripheral (USRP). The experimental validations demonstrate that our proposed approach outperforms the benchmarks in terms of localization accuracy and velocity estimation, confirming its effectiveness in practical environmental sensing applications.