 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Learning with Jacobian Regularization
Aug 07, 2019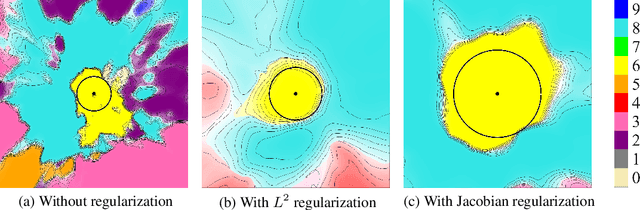
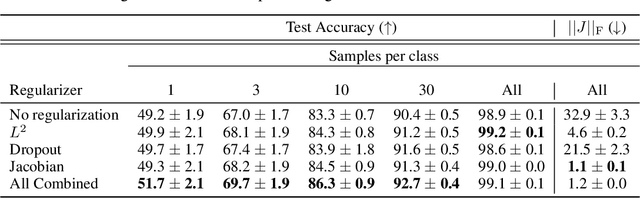
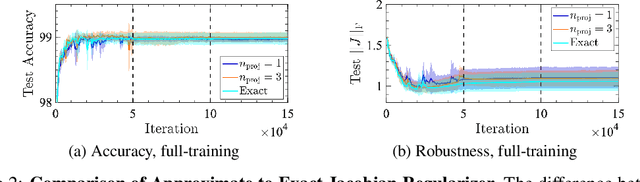
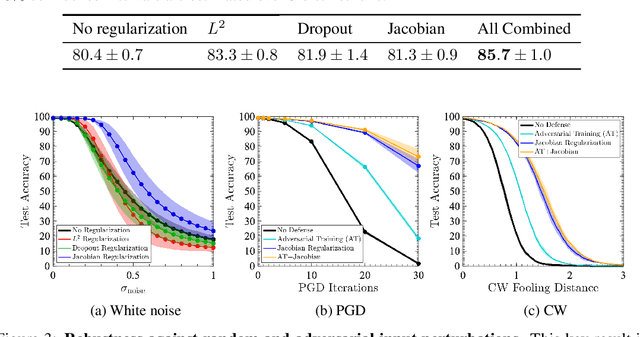
Design of reliable systems must guarantee stability against input perturbations. In machine learning, such guarantee entails preventing overfitting and ensuring robustness of models against corruption of input data. In order to maximize stability, we analyze and develop a computationally efficient implementation of Jacobian regularization that increases classification margins of neural networks. The stabilizing effect of the Jacobian regularizer leads to significant improvements in robustness, as measured against both random and adversarial input perturbations, without severely degrading generalization properties on clean data.
SplitNet: Sim2Sim and Task2Task Transfer for Embodied Visual Navigation
May 21, 2019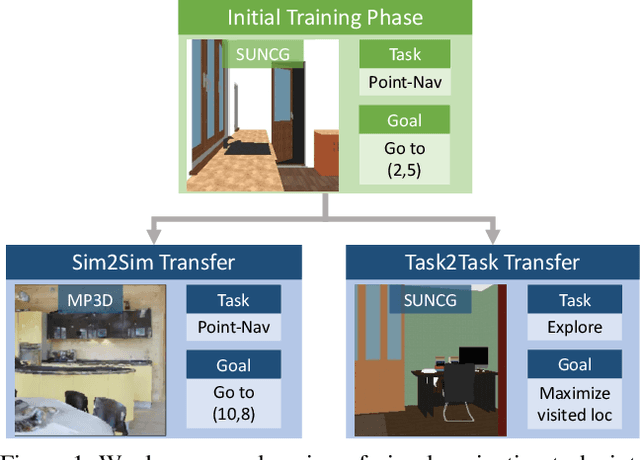
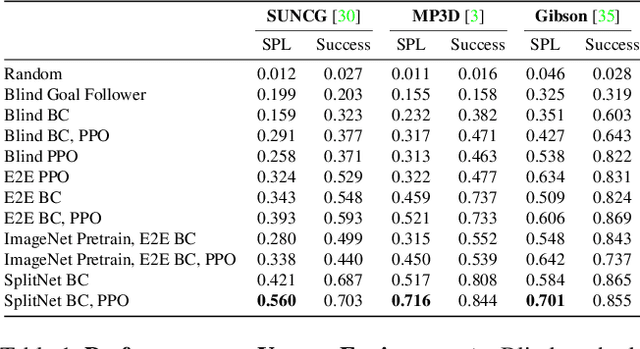
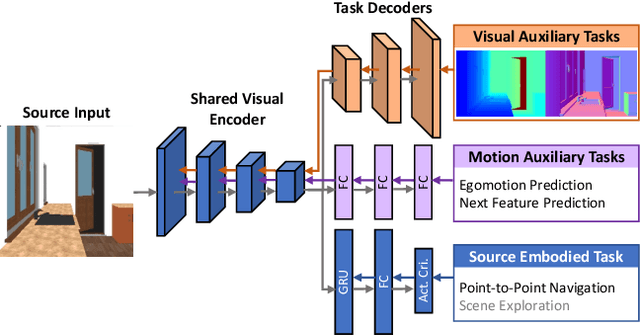
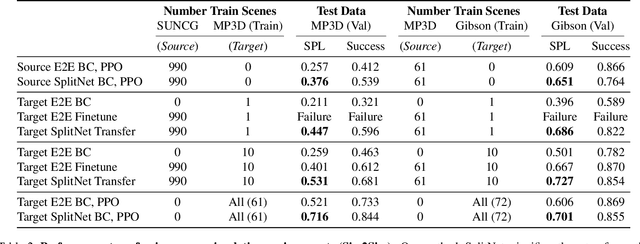
We propose SplitNet, a method for decoupling visual perception and policy learning. By incorporating auxiliary tasks and selective learning of portions of the model, we explicitly decompose the learning objectives for visual navigation into perceiving the world and acting on that perception. We show dramatic improvements over baseline models on transferring between simulators, an encouraging step towards Sim2Real. Additionally, SplitNet generalizes better to unseen environments from the same simulator and transfers faster and more effectively to novel embodied navigation tasks. Further, given only a small sample from a target domain, SplitNet can match the performance of traditional end-to-end pipelines which receive the entire dataset. Code and video are available at https://github.com/facebookresearch/splitnet and https://youtu.be/TJkZcsD2vrc
Predictive Inequity in Object Detection
Feb 21, 2019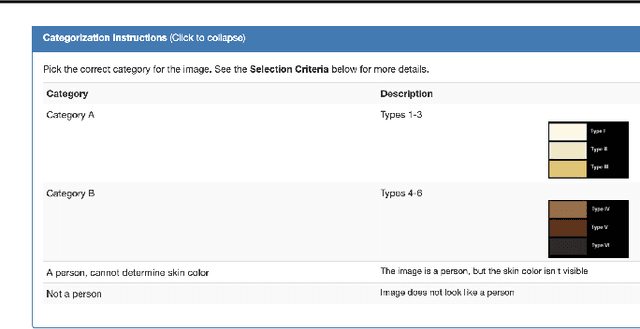

In this work, we investigate whether state-of-the-art object detection systems have equitable predictive performance on pedestrians with different skin tones. This work is motivated by many recent examples of ML and vision systems displaying higher error rates for certain demographic groups than others. We annotate an existing large scale dataset which contains pedestrians, BDD100K, with Fitzpatrick skin tones in ranges [1-3] or [4-6]. We then provide an in-depth comparative analysis of performance between these two skin tone groupings, finding that neither time of day nor occlusion explain this behavior, suggesting this disparity is not merely the result of pedestrians in the 4-6 range appearing in more difficult scenes for detection. We investigate to what extent time of day, occlusion, and reweighting the supervised loss during training affect this predictive bias.
Syn2Real: A New Benchmark forSynthetic-to-Real Visual Domain Adaptation
Jun 26, 2018
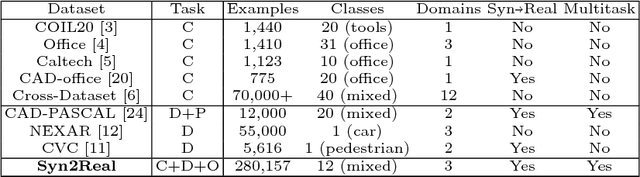


Unsupervised transfer of object recognition models from synthetic to real data is an important problem with many potential applications. The challenge is how to "adapt" a model trained on simulated images so that it performs well on real-world data without any additional supervision. Unfortunately, current benchmarks for this problem are limited in size and task diversity. In this paper, we present a new large-scale benchmark called Syn2Real, which consists of a synthetic domain rendered from 3D object models and two real-image domains containing the same object categories. We define three related tasks on this benchmark: closed-set object classification, open-set object classification, and object detection. Our evaluation of multiple state-of-the-art methods reveals a large gap in adaptation performance between the easier closed-set classification task and the more difficult open-set and detection tasks. We conclude that developing adaptation methods that work well across all three tasks presents a significant future challenge for syn2real domain transfer.
Algorithms and Theory for Multiple-Source Adaptation
May 20, 2018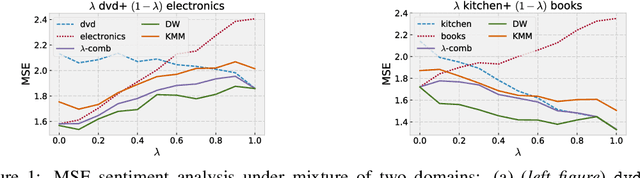
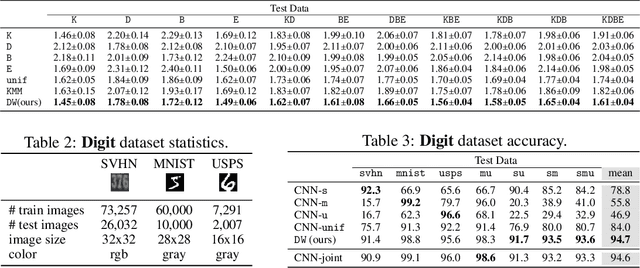
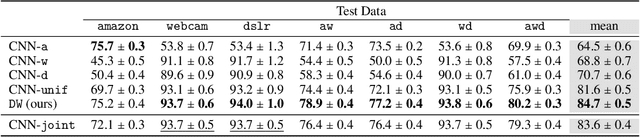
This work includes a number of novel contributions for the multiple-source adaptation problem. We present new normalized solutions with strong theoretical guarantees for the cross-entropy loss and other similar losses. We also provide new guarantees that hold in the case where the conditional probabilities for the source domains are distinct. Moreover, we give new algorithms for determining the distribution-weighted combination solution for the cross-entropy loss and other losses. We report the results of a series of experiments with real-world datasets. We find that our algorithm outperforms competing approaches by producing a single robust model that performs well on any target mixture distribution. Altogether, our theory, algorithms, and empirical results provide a full solution for the multiple-source adaptation problem with very practical benefits.
CyCADA: Cycle-Consistent Adversarial Domain Adaptation
Dec 29, 2017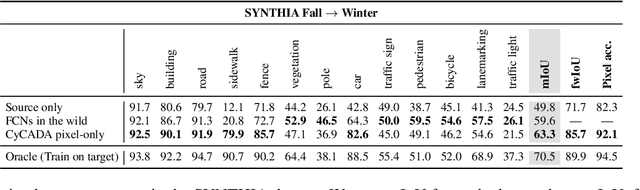
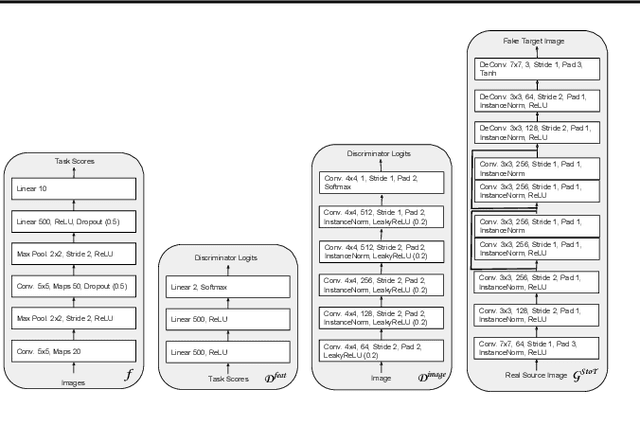


Domain adaptation is critical for success in new, unseen environments. Adversarial adaptation models applied in feature spaces discover domain invariant representations, but are difficult to visualize and sometimes fail to capture pixel-level and low-level domain shifts. Recent work has shown that generative adversarial networks combined with cycle-consistency constraints are surprisingly effective at mapping images between domains, even without the use of aligned image pairs. We propose a novel discriminatively-trained Cycle-Consistent Adversarial Domain Adaptation model. CyCADA adapts representations at both the pixel-level and feature-level, enforces cycle-consistency while leveraging a task loss, and does not require aligned pairs. Our model can be applied in a variety of visual recognition and prediction settings. We show new state-of-the-art results across multiple adaptation tasks, including digit classification and semantic segmentation of road scenes demonstrating transfer from synthetic to real world domains.
Label Efficient Learning of Transferable Representations across Domains and Tasks
Nov 30, 2017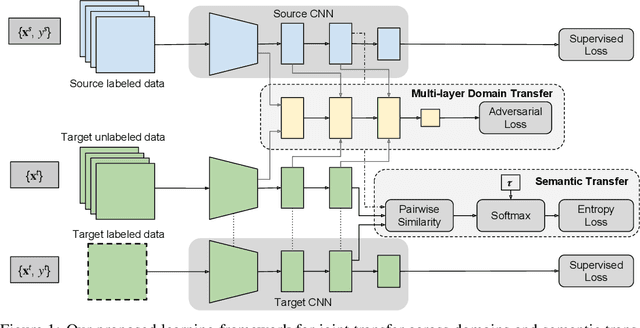
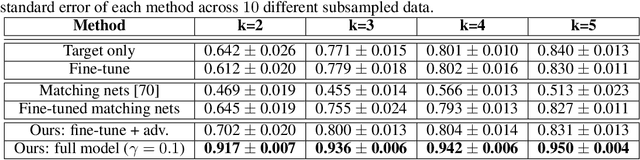
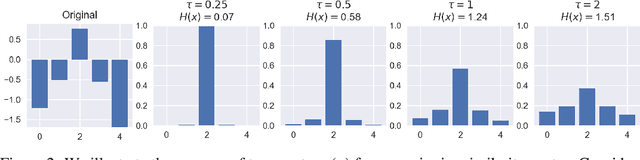
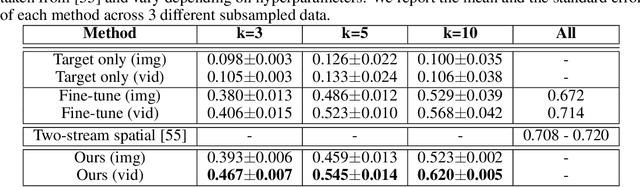
We propose a framework that learns a representation transferable across different domains and tasks in a label efficient manner. Our approach battles domain shift with a domain adversarial loss, and generalizes the embedding to novel task using a metric learning-based approach. Our model is simultaneously optimized on labeled source data and unlabeled or sparsely labeled data in the target domain. Our method shows compelling results on novel classes within a new domain even when only a few labeled examples per class are available, outperforming the prevalent fine-tuning approach. In addition, we demonstrate the effectiveness of our framework on the transfer learning task from image object recognition to video action recognition.
VisDA: The Visual Domain Adaptation Challenge
Nov 29, 2017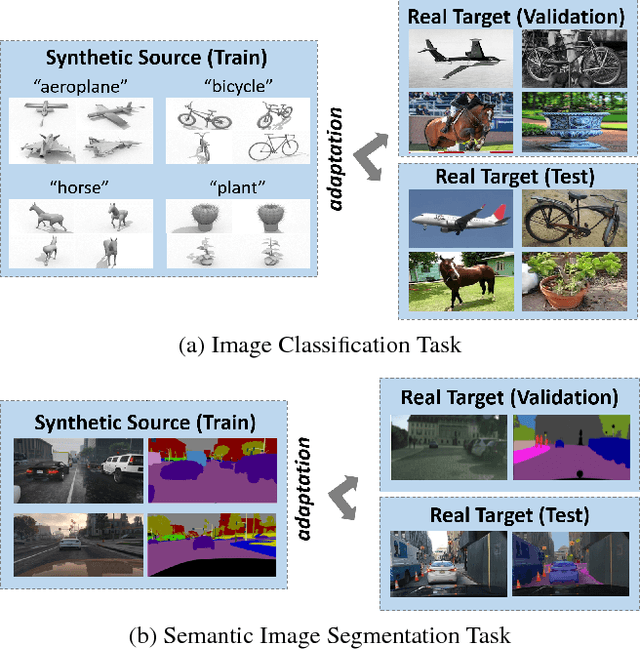
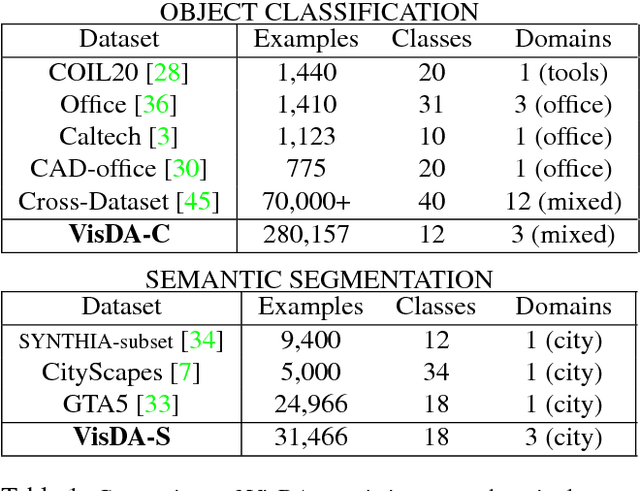
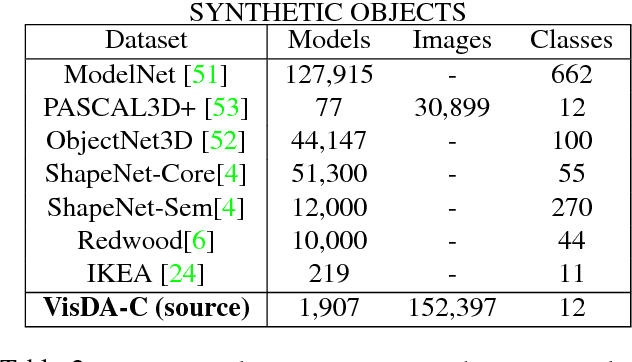

We present the 2017 Visual Domain Adaptation (VisDA) dataset and challenge, a large-scale testbed for unsupervised domain adaptation across visual domains. Unsupervised domain adaptation aims to solve the real-world problem of domain shift, where machine learning models trained on one domain must be transferred and adapted to a novel visual domain without additional supervision. The VisDA2017 challenge is focused on the simulation-to-reality shift and has two associated tasks: image classification and image segmentation. The goal in both tracks is to first train a model on simulated, synthetic data in the source domain and then adapt it to perform well on real image data in the unlabeled test domain. Our dataset is the largest one to date for cross-domain object classification, with over 280K images across 12 categories in the combined training, validation and testing domains. The image segmentation dataset is also large-scale with over 30K images across 18 categories in the three domains. We compare VisDA to existing cross-domain adaptation datasets and provide a baseline performance analysis using various domain adaptation models that are currently popular in the field.
Multiple-Source Adaptation for Regression Problems
Nov 14, 2017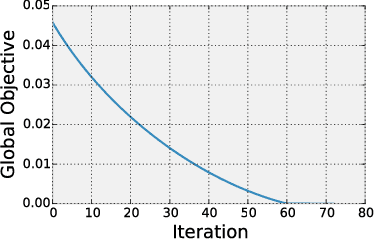

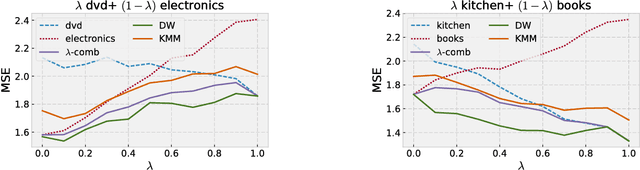
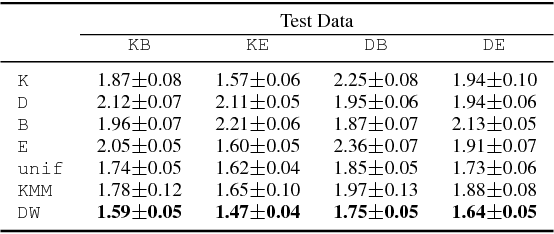
We present a detailed theoretical analysis of the problem of multiple-source adaptation in the general stochastic scenario, extending known results that assume a single target labeling function. Our results cover a more realistic scenario and show the existence of a single robust predictor accurate for \emph{any} target mixture of the source distributions. Moreover, we present an efficient and practical optimization solution to determine the robust predictor in the important case of squared loss, by casting the problem as an instance of DC-programming. We report the results of experiments with both an artificial task and a sentiment analysis task. We find that our algorithm outperforms competing approaches by producing a single robust model that performs well on any target mixture distribution.
Fine-grained Recognition in the Wild: A Multi-Task Domain Adaptation Approach
Sep 07, 2017
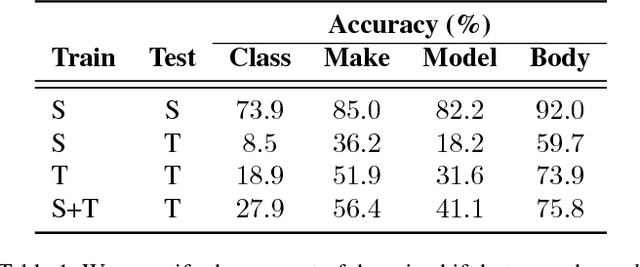
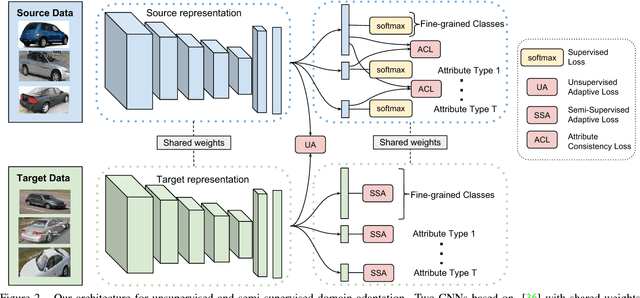
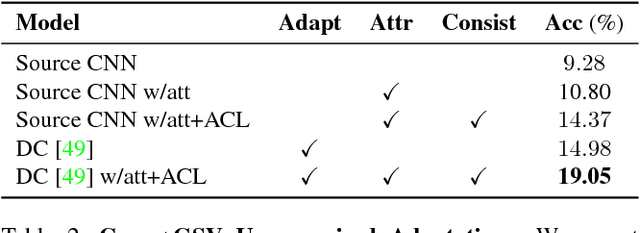
While fine-grained object recognition is an important problem in computer vision, current models are unlikely to accurately classify objects in the wild. These fully supervised models need additional annotated images to classify objects in every new scenario, a task that is infeasible. However, sources such as e-commerce websites and field guides provide annotated images for many classes. In this work, we study fine-grained domain adaptation as a step towards overcoming the dataset shift between easily acquired annotated images and the real world. Adaptation has not been studied in the fine-grained setting where annotations such as attributes could be used to increase performance. Our work uses an attribute based multi-task adaptation loss to increase accuracy from a baseline of 4.1% to 19.1% in the semi-supervised adaptation case. Prior do- main adaptation works have been benchmarked on small datasets such as [46] with a total of 795 images for some domains, or simplistic datasets such as [41] consisting of digits. We perform experiments on a subset of a new challenging fine-grained dataset consisting of 1,095,021 images of 2, 657 car categories drawn from e-commerce web- sites and Google Street View.