 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDragGANSpace: Latent Space Exploration and Control for GANs
Sep 26, 2025



This work integrates StyleGAN, DragGAN and Principal Component Analysis (PCA) to enhance the latent space efficiency and controllability of GAN-generated images. Style-GAN provides a structured latent space, DragGAN enables intuitive image manipulation, and PCA reduces dimensionality and facilitates cross-model alignment for more streamlined and interpretable exploration of latent spaces. We apply our techniques to the Animal Faces High Quality (AFHQ) dataset, and find that our approach of integrating PCA-based dimensionality reduction with the Drag-GAN framework for image manipulation retains performance while improving optimization efficiency. Notably, introducing PCA into the latent W+ layers of DragGAN can consistently reduce the total optimization time while maintaining good visual quality and even boosting the Structural Similarity Index Measure (SSIM) of the optimized image, particularly in shallower latent spaces (W+ layers = 3). We also demonstrate capability for aligning images generated by two StyleGAN models trained on similar but distinct data domains (AFHQ-Dog and AFHQ-Cat), and show that we can control the latent space of these aligned images to manipulate the images in an intuitive and interpretable manner. Our findings highlight the possibility for efficient and interpretable latent space control for a wide range of image synthesis and editing applications.
Syn2Real: A New Benchmark forSynthetic-to-Real Visual Domain Adaptation
Jun 26, 2018
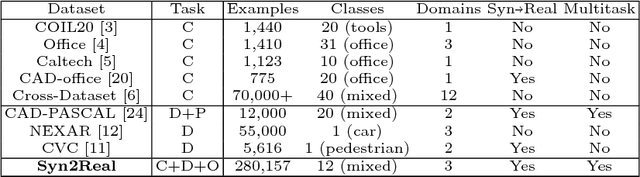


Unsupervised transfer of object recognition models from synthetic to real data is an important problem with many potential applications. The challenge is how to "adapt" a model trained on simulated images so that it performs well on real-world data without any additional supervision. Unfortunately, current benchmarks for this problem are limited in size and task diversity. In this paper, we present a new large-scale benchmark called Syn2Real, which consists of a synthetic domain rendered from 3D object models and two real-image domains containing the same object categories. We define three related tasks on this benchmark: closed-set object classification, open-set object classification, and object detection. Our evaluation of multiple state-of-the-art methods reveals a large gap in adaptation performance between the easier closed-set classification task and the more difficult open-set and detection tasks. We conclude that developing adaptation methods that work well across all three tasks presents a significant future challenge for syn2real domain transfer.
VisDA: The Visual Domain Adaptation Challenge
Nov 29, 2017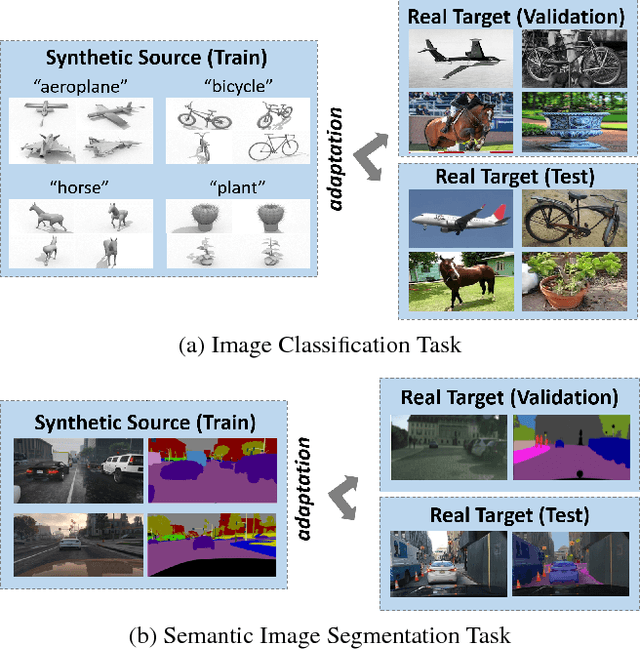
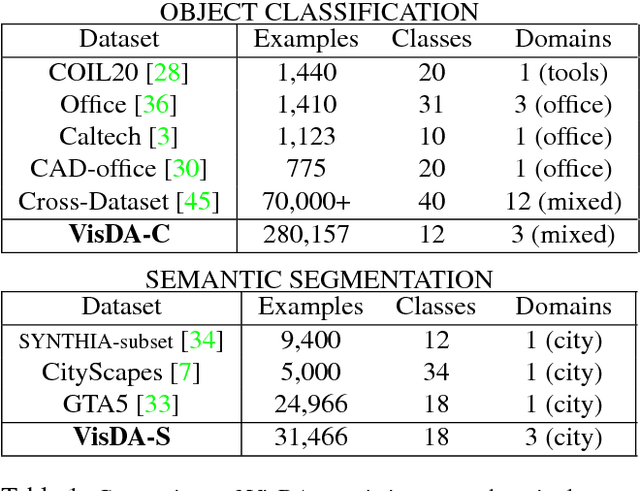
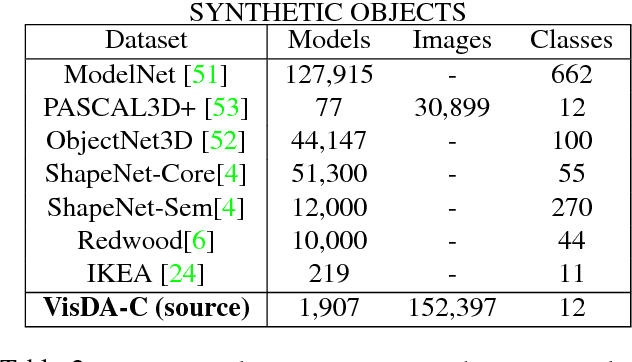

We present the 2017 Visual Domain Adaptation (VisDA) dataset and challenge, a large-scale testbed for unsupervised domain adaptation across visual domains. Unsupervised domain adaptation aims to solve the real-world problem of domain shift, where machine learning models trained on one domain must be transferred and adapted to a novel visual domain without additional supervision. The VisDA2017 challenge is focused on the simulation-to-reality shift and has two associated tasks: image classification and image segmentation. The goal in both tracks is to first train a model on simulated, synthetic data in the source domain and then adapt it to perform well on real image data in the unlabeled test domain. Our dataset is the largest one to date for cross-domain object classification, with over 280K images across 12 categories in the combined training, validation and testing domains. The image segmentation dataset is also large-scale with over 30K images across 18 categories in the three domains. We compare VisDA to existing cross-domain adaptation datasets and provide a baseline performance analysis using various domain adaptation models that are currently popular in the field.