 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating 3D Motion and Forces of Human-Object Interactions from Internet Videos
Nov 02, 2021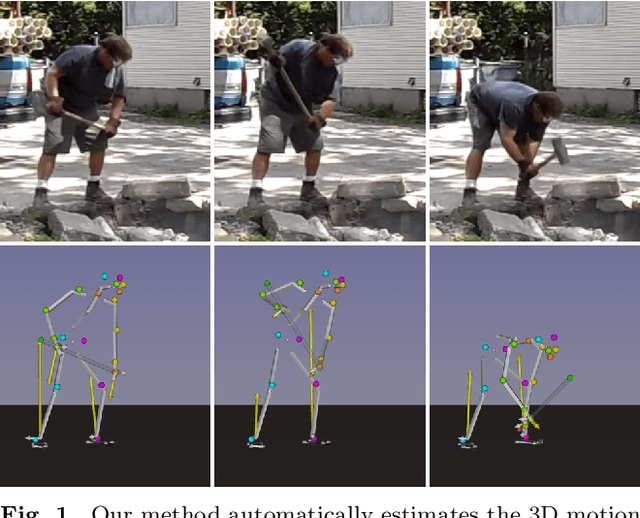

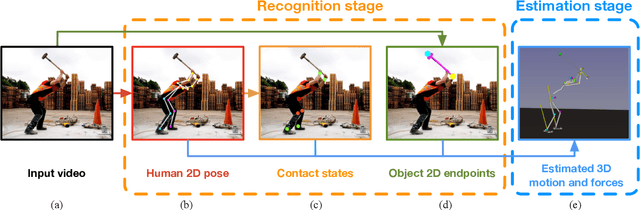

In this paper, we introduce a method to automatically reconstruct the 3D motion of a person interacting with an object from a single RGB video. Our method estimates the 3D poses of the person together with the object pose, the contact positions and the contact forces exerted on the human body. The main contributions of this work are three-fold. First, we introduce an approach to jointly estimate the motion and the actuation forces of the person on the manipulated object by modeling contacts and the dynamics of the interactions. This is cast as a large-scale trajectory optimization problem. Second, we develop a method to automatically recognize from the input video the 2D position and timing of contacts between the person and the object or the ground, thereby significantly simplifying the complexity of the optimization. Third, we validate our approach on a recent video+MoCap dataset capturing typical parkour actions, and demonstrate its performance on a new dataset of Internet videos showing people manipulating a variety of tools in unconstrained environments.
Weakly Supervised Human-Object Interaction Detection in Video via Contrastive Spatiotemporal Regions
Oct 07, 2021
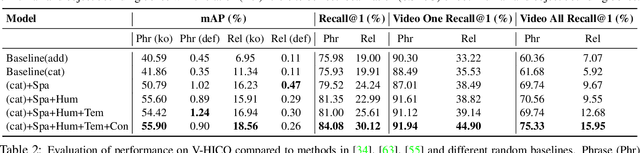
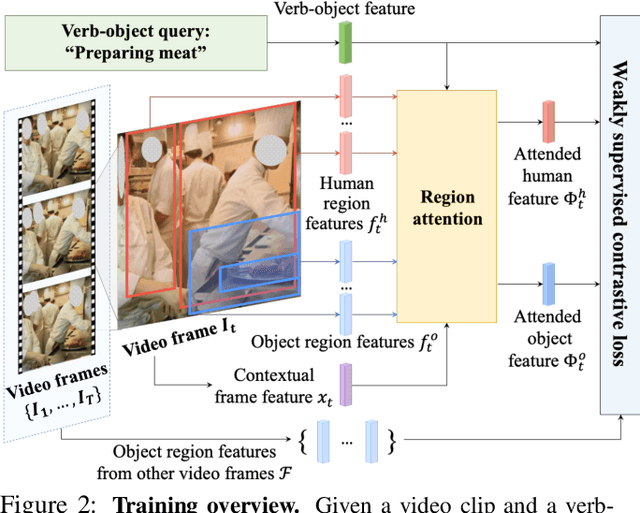
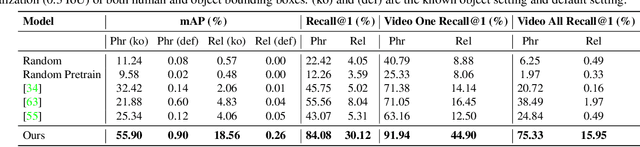
We introduce the task of weakly supervised learning for detecting human and object interactions in videos. Our task poses unique challenges as a system does not know what types of human-object interactions are present in a video or the actual spatiotemporal location of the human and the object. To address these challenges, we introduce a contrastive weakly supervised training loss that aims to jointly associate spatiotemporal regions in a video with an action and object vocabulary and encourage temporal continuity of the visual appearance of moving objects as a form of self-supervision. To train our model, we introduce a dataset comprising over 6.5k videos with human-object interaction annotations that have been semi-automatically curated from sentence captions associated with the videos. We demonstrate improved performance over weakly supervised baselines adapted to our task on our video dataset.
Reconstructing and grounding narrated instructional videos in 3D
Sep 10, 2021
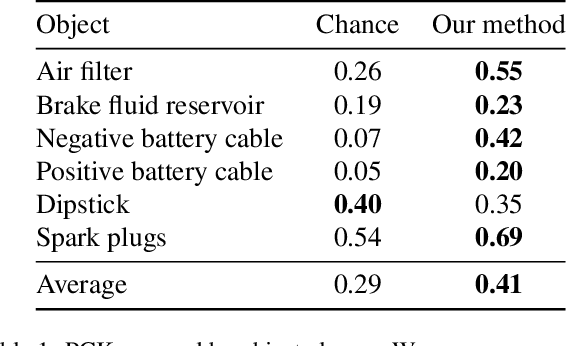
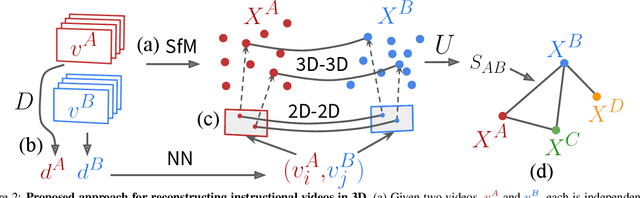

Narrated instructional videos often show and describe manipulations of similar objects, e.g., repairing a particular model of a car or laptop. In this work we aim to reconstruct such objects and to localize associated narrations in 3D. Contrary to the standard scenario of instance-level 3D reconstruction, where identical objects or scenes are present in all views, objects in different instructional videos may have large appearance variations given varying conditions and versions of the same product. Narrations may also have large variation in natural language expressions. We address these challenges by three contributions. First, we propose an approach for correspondence estimation combining learnt local features and dense flow. Second, we design a two-step divide and conquer reconstruction approach where the initial 3D reconstructions of individual videos are combined into a 3D alignment graph. Finally, we propose an unsupervised approach to ground natural language in obtained 3D reconstructions. We demonstrate the effectiveness of our approach for the domain of car maintenance. Given raw instructional videos and no manual supervision, our method successfully reconstructs engines of different car models and associates textual descriptions with corresponding objects in 3D.
Single-view robot pose and joint angle estimation via render & compare
Apr 19, 2021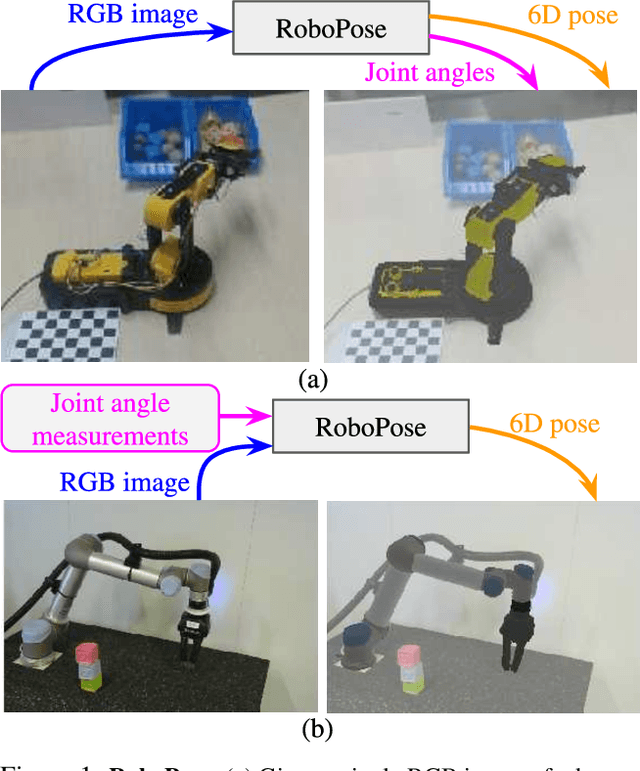
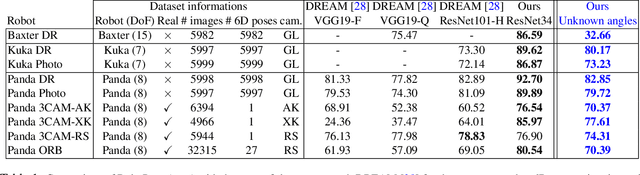
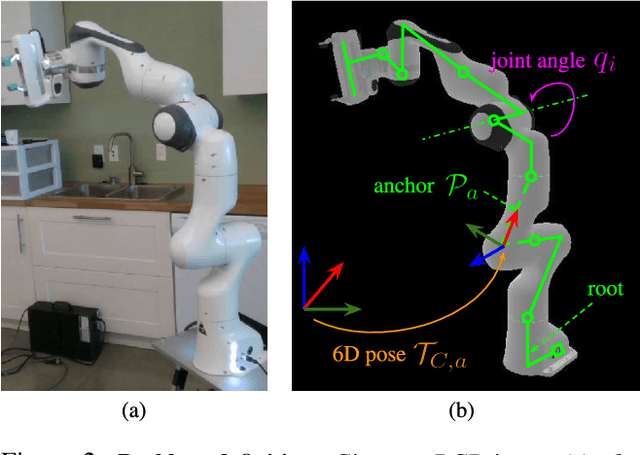
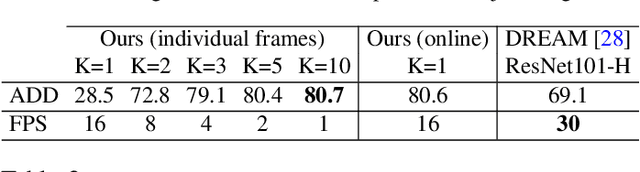
We introduce RoboPose, a method to estimate the joint angles and the 6D camera-to-robot pose of a known articulated robot from a single RGB image. This is an important problem to grant mobile and itinerant autonomous systems the ability to interact with other robots using only visual information in non-instrumented environments, especially in the context of collaborative robotics. It is also challenging because robots have many degrees of freedom and an infinite space of possible configurations that often result in self-occlusions and depth ambiguities when imaged by a single camera. The contributions of this work are three-fold. First, we introduce a new render & compare approach for estimating the 6D pose and joint angles of an articulated robot that can be trained from synthetic data, generalizes to new unseen robot configurations at test time, and can be applied to a variety of robots. Second, we experimentally demonstrate the importance of the robot parametrization for the iterative pose updates and design a parametrization strategy that is independent of the robot structure. Finally, we show experimental results on existing benchmark datasets for four different robots and demonstrate that our method significantly outperforms the state of the art. Code and pre-trained models are available on the project webpage https://www.di.ens.fr/willow/research/robopose/.
Visualizing computation in large-scale cellular automata
Apr 01, 2021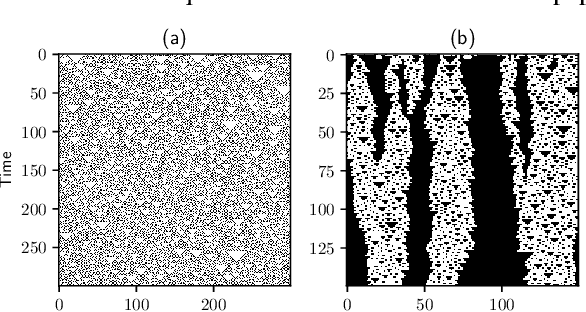
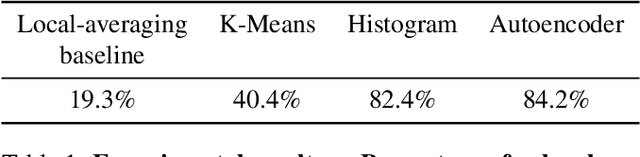
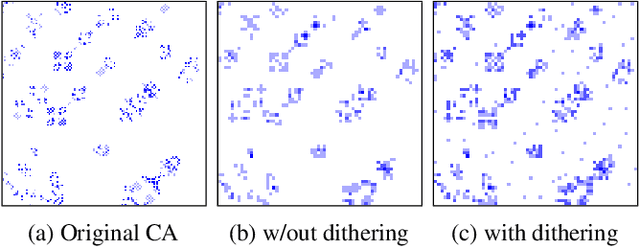
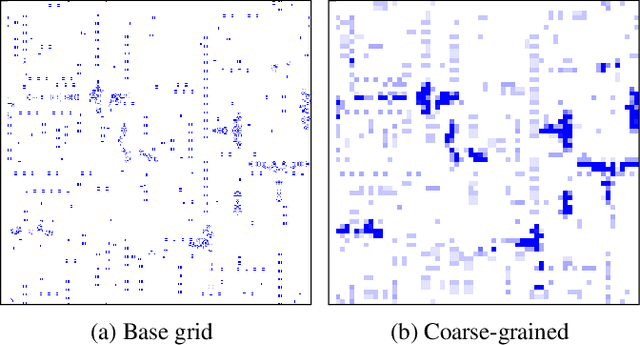
Emergent processes in complex systems such as cellular automata can perform computations of increasing complexity, and could possibly lead to artificial evolution. Such a feat would require scaling up current simulation sizes to allow for enough computational capacity. Understanding complex computations happening in cellular automata and other systems capable of emergence poses many challenges, especially in large-scale systems. We propose methods for coarse-graining cellular automata based on frequency analysis of cell states, clustering and autoencoders. These innovative techniques facilitate the discovery of large-scale structure formation and complexity analysis in those systems. They emphasize interesting behaviors in elementary cellular automata while filtering out background patterns. Moreover, our methods reduce large 2D automata to smaller sizes and enable identifying systems that behave interestingly at multiple scales.
Thinking Fast and Slow: Efficient Text-to-Visual Retrieval with Transformers
Mar 30, 2021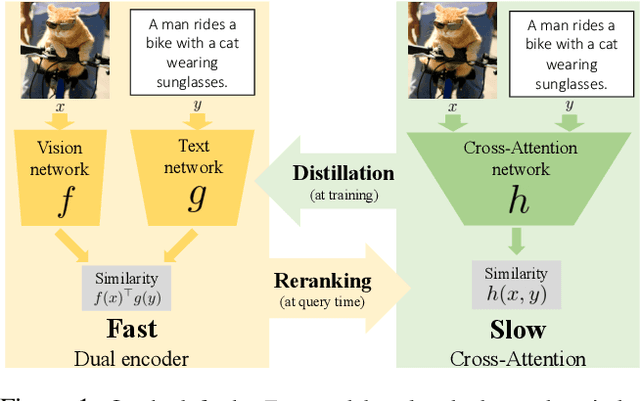
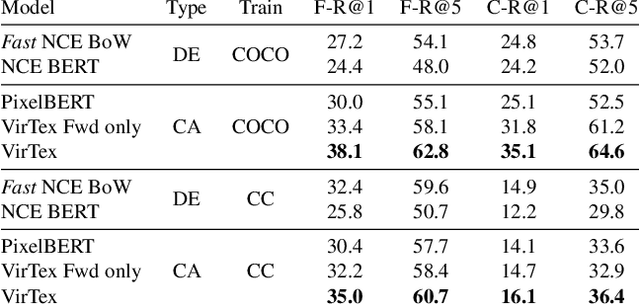
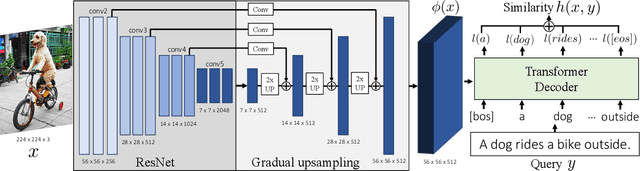
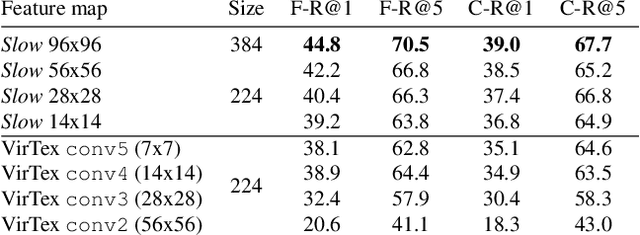
Our objective is language-based search of large-scale image and video datasets. For this task, the approach that consists of independently mapping text and vision to a joint embedding space, a.k.a. dual encoders, is attractive as retrieval scales and is efficient for billions of images using approximate nearest neighbour search. An alternative approach of using vision-text transformers with cross-attention gives considerable improvements in accuracy over the joint embeddings, but is often inapplicable in practice for large-scale retrieval given the cost of the cross-attention mechanisms required for each sample at test time. This work combines the best of both worlds. We make the following three contributions. First, we equip transformer-based models with a new fine-grained cross-attention architecture, providing significant improvements in retrieval accuracy whilst preserving scalability. Second, we introduce a generic approach for combining a Fast dual encoder model with our Slow but accurate transformer-based model via distillation and re-ranking. Finally, we validate our approach on the Flickr30K image dataset where we show an increase in inference speed by several orders of magnitude while having results competitive to the state of the art. We also extend our method to the video domain, improving the state of the art on the VATEX dataset.
Just Ask: Learning to Answer Questions from Millions of Narrated Videos
Dec 01, 2020
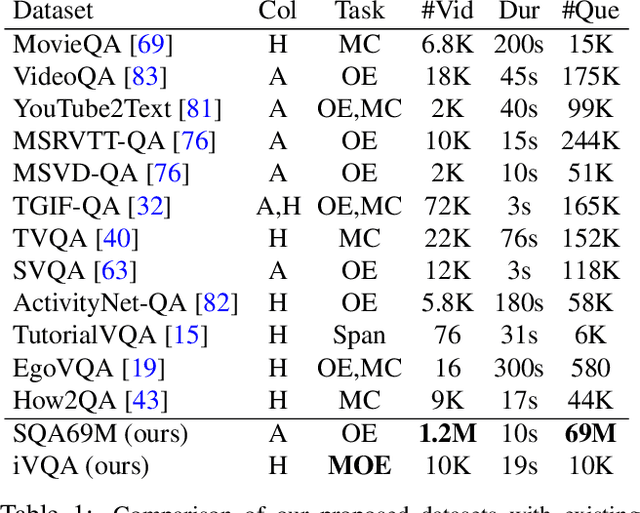


Modern approaches to visual question answering require large annotated datasets for training. Manual annotation of questions and answers for videos, however, is tedious, expensive and prevents scalability. In this work, we propose to avoid manual annotation and to learn video question answering (VideoQA) from millions of readily-available narrated videos. We propose to automatically generate question-answer pairs from transcribed video narrations leveraging a state-of-the-art text transformer pipeline and obtain a new large-scale VideoQA training dataset. To handle the open vocabulary of diverse answers in this dataset, we propose a training procedure based on a contrastive loss between a video-question multi-modal transformer and an answer embedding. We evaluate our model on the zero-shot VideoQA task and show excellent results, in particular for rare answers. Furthermore, we demonstrate that finetuning our model on target datasets significantly outperforms the state of the art on MSRVTT-QA, MSVD-QA and ActivityNet-QA. Finally, for a detailed evaluation we introduce a new manually annotated VideoQA dataset with reduced language biases and high quality annotations. Our code and datasets will be made publicly available at https://www.di.ens.fr/willow/research/just-ask/ .
Learning Object Manipulation Skills via Approximate State Estimation from Real Videos
Nov 13, 2020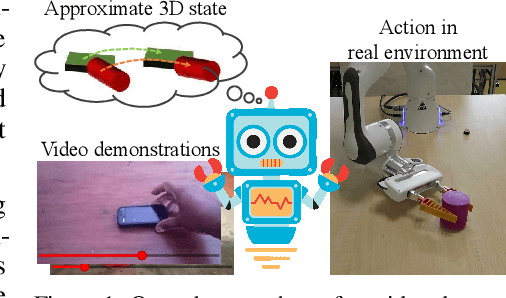
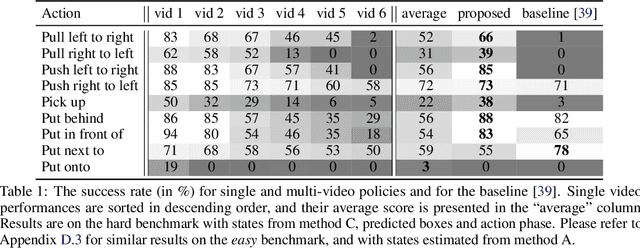
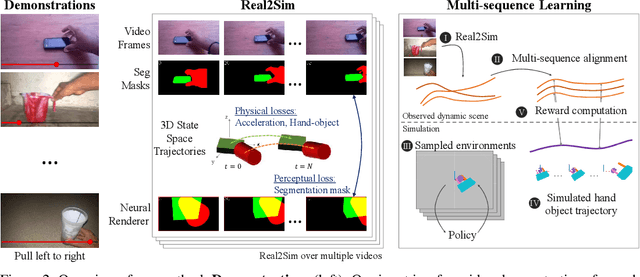

Humans are adept at learning new tasks by watching a few instructional videos. On the other hand, robots that learn new actions either require a lot of effort through trial and error, or use expert demonstrations that are challenging to obtain. In this paper, we explore a method that facilitates learning object manipulation skills directly from videos. Leveraging recent advances in 2D visual recognition and differentiable rendering, we develop an optimization based method to estimate a coarse 3D state representation for the hand and the manipulated object(s) without requiring any supervision. We use these trajectories as dense rewards for an agent that learns to mimic them through reinforcement learning. We evaluate our method on simple single- and two-object actions from the Something-Something dataset. Our approach allows an agent to learn actions from single videos, while watching multiple demonstrations makes the policy more robust. We show that policies learned in a simulated environment can be easily transferred to a real robot.
CosyPose: Consistent multi-view multi-object 6D pose estimation
Aug 19, 2020

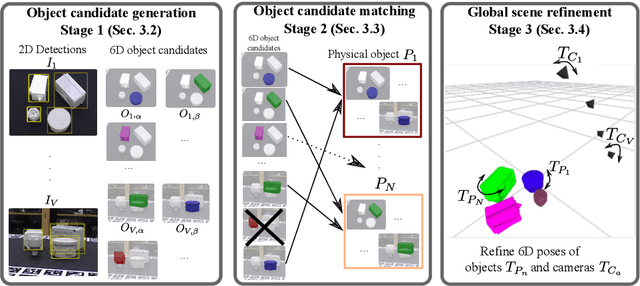

We introduce an approach for recovering the 6D pose of multiple known objects in a scene captured by a set of input images with unknown camera viewpoints. First, we present a single-view single-object 6D pose estimation method, which we use to generate 6D object pose hypotheses. Second, we develop a robust method for matching individual 6D object pose hypotheses across different input images in order to jointly estimate camera viewpoints and 6D poses of all objects in a single consistent scene. Our approach explicitly handles object symmetries, does not require depth measurements, is robust to missing or incorrect object hypotheses, and automatically recovers the number of objects in the scene. Third, we develop a method for global scene refinement given multiple object hypotheses and their correspondences across views. This is achieved by solving an object-level bundle adjustment problem that refines the poses of cameras and objects to minimize the reprojection error in all views. We demonstrate that the proposed method, dubbed CosyPose, outperforms current state-of-the-art results for single-view and multi-view 6D object pose estimation by a large margin on two challenging benchmarks: the YCB-Video and T-LESS datasets. Code and pre-trained models are available on the project webpage https://www.di.ens.fr/willow/research/cosypose/.
RareAct: A video dataset of unusual interactions
Aug 03, 2020


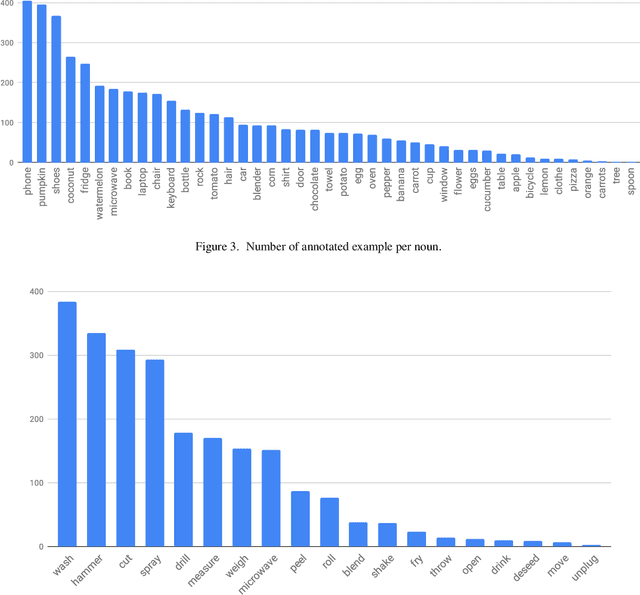
This paper introduces a manually annotated video dataset of unusual actions, namely RareAct, including actions such as "blend phone", "cut keyboard" and "microwave shoes". RareAct aims at evaluating the zero-shot and few-shot compositionality of action recognition models for unlikely compositions of common action verbs and object nouns. It contains 122 different actions which were obtained by combining verbs and nouns rarely co-occurring together in the large-scale textual corpus from HowTo100M, but that frequently appear separately. We provide benchmarks using a state-of-the-art HowTo100M pretrained video and text model and show that zero-shot and few-shot compositionality of actions remains a challenging and unsolved task.