 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplexityMT: Benchmarking the Interaction Between Text Complexity and Machine Translation
Jun 03, 2026When a text is translated, does the translation retain the complexity of the original? We introduce ComplexityMT, a new challenge for assessing how text complexity and machine translation interact with and influence each other, using the Common European Framework of Reference for Languages (CEFR) levels as the measure of text complexity. Across six languages, including Arabic, Dutch, English, French, Hindi, and Russian, we evaluate three open-weight models, one closed model, and a commercial machine translation system on two tasks: i) correlation of CEFR with translation difficulty, and ii) shifts in CEFR levels of the source texts. Our experiments show that higher CEFR levels make texts more difficult to translate, and that machine translation shifts the CEFR level of the target text compared to the original source, for most languages. These findings provide new insights for researchers and practitioners working on multilingual pedagogical content generation and machine translation difficulty estimation.
Story Generation from Visual Inputs: Techniques, Related Tasks, and Challenges
Jun 04, 2024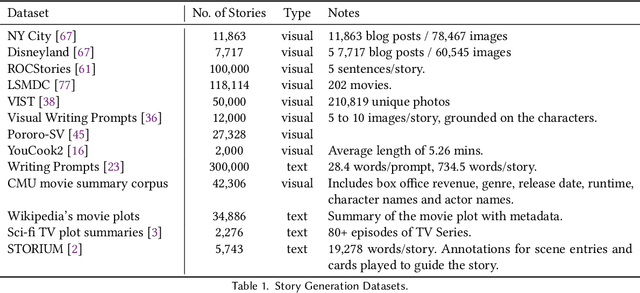
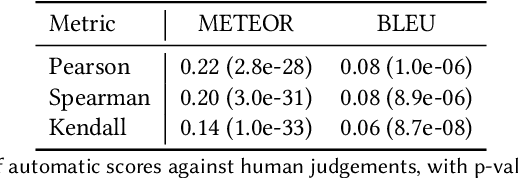
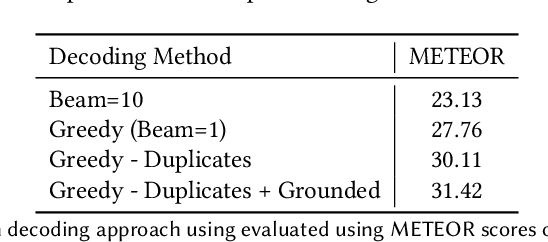

Creating engaging narratives from visual data is crucial for automated digital media consumption, assistive technologies, and interactive entertainment. This survey covers methodologies used in the generation of these narratives, focusing on their principles, strengths, and limitations. The survey also covers tasks related to automatic story generation, such as image and video captioning, and visual question answering, as well as story generation without visual inputs. These tasks share common challenges with visual story generation and have served as inspiration for the techniques used in the field. We analyze the main datasets and evaluation metrics, providing a critical perspective on their limitations.
Towards Learning Through Open-Domain Dialog
Feb 07, 2022
The development of artificial agents able to learn through dialog without domain restrictions has the potential to allow machines to learn how to perform tasks in a similar manner to humans and change how we relate to them. However, research in this area is practically nonexistent. In this paper, we identify the modifications required for a dialog system to be able to learn from the dialog and propose generic approaches that can be used to implement those modifications. More specifically, we discuss how knowledge can be extracted from the dialog, used to update the agent's semantic network, and grounded in action and observation. This way, we hope to raise awareness for this subject, so that it can become a focus of research in the future.
General-Purpose Communicative Function Recognition using a Hierarchical Network with Cascading Outputs and Maximum a Posteriori Path Estimation
Mar 07, 2020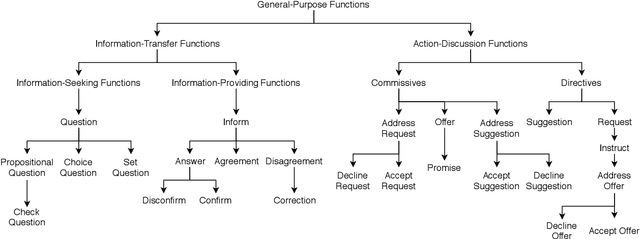
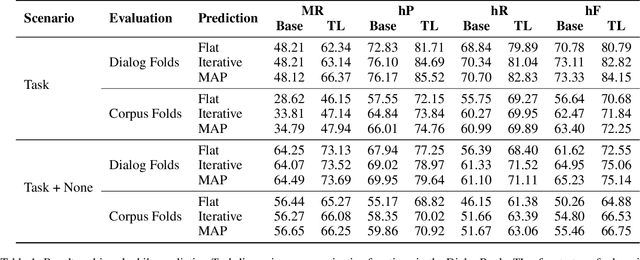
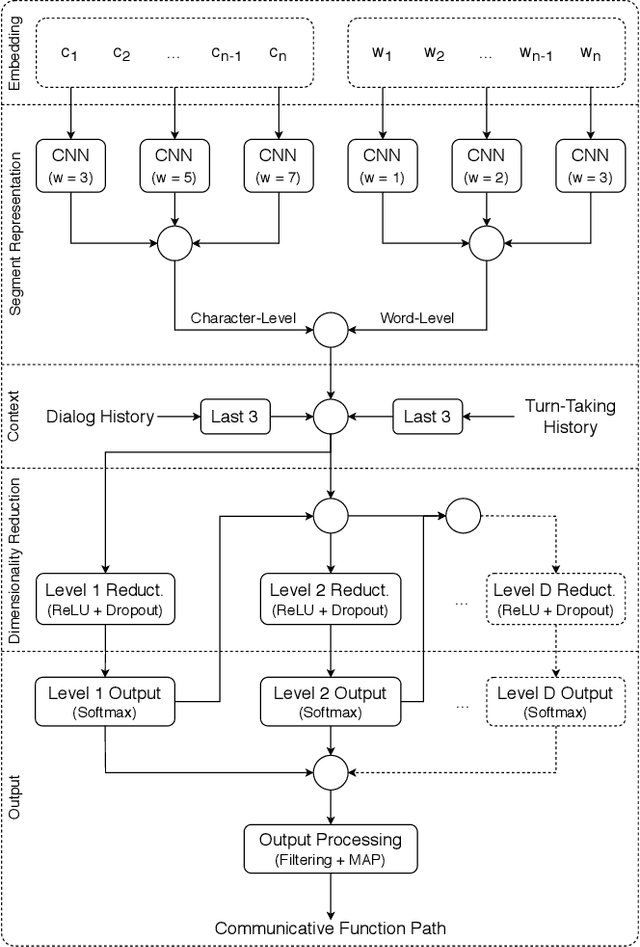
ISO 24617-2, the standard for dialog act annotation, defines a hierarchically organized set of general-purpose communicative functions. The automatic recognition of these functions, although practically unexplored, is relevant for a dialog system, since they provide cues regarding the intention behind the segments and how they should be interpreted. In this paper, we explore the recognition of general-purpose communicative functions in the DialogBank, which is a reference set of dialogs annotated according to the standard. To do so, we adapt a state-of-the-art approach on flat dialog act recognition to deal with the hierarchical classification problem. More specifically, we propose the use of a hierarchical network with cascading outputs and maximum a posteriori path estimation to predict the communicative function at each level of the hierarchy, preserve the dependencies between the functions in the path, and decide at which level to stop. Furthermore, since the amount of dialogs in the DialogBank is reduced, we rely both on additional dialogs annotated using mapping processes and on transfer learning to improve performance. The results of our experiments show that the hierarchical approach outperforms a flat one and that maximum a posteriori estimation outperforms an iterative prediction approach based on masking.
Hierarchical Multi-Label Dialog Act Recognition on Spanish Data
Jul 29, 2019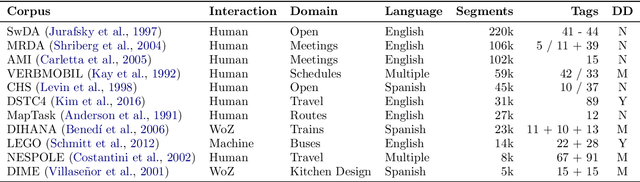

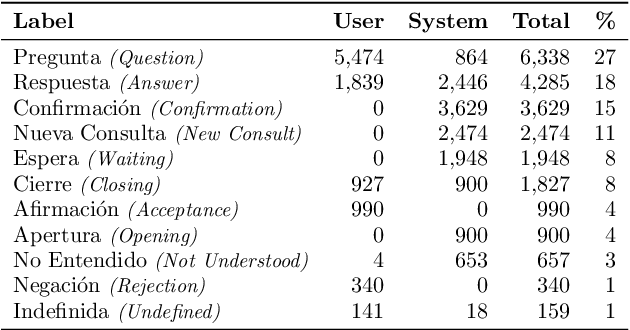
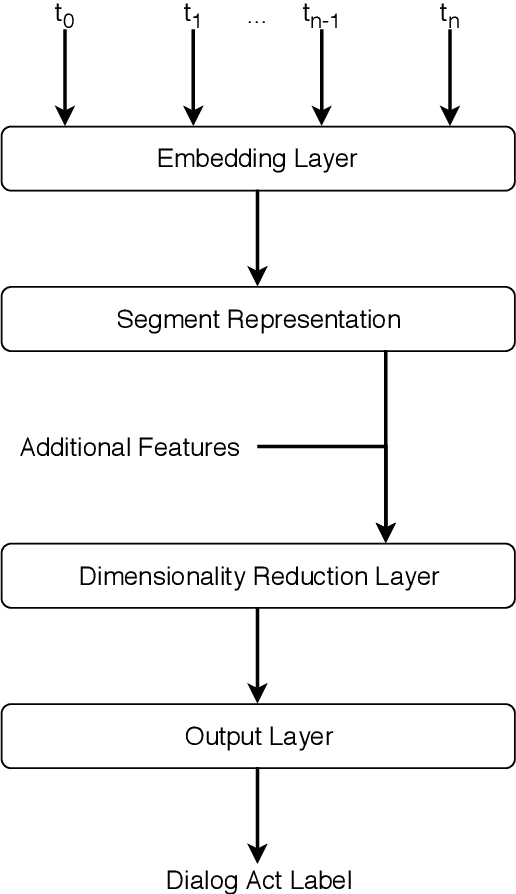
Dialog acts reveal the intention behind the uttered words. Thus, their automatic recognition is important for a dialog system trying to understand its conversational partner. The study presented in this article approaches that task on the DIHANA corpus, whose three-level dialog act annotation scheme poses problems which have not been explored in recent studies. In addition to the hierarchical problem, the two lower levels pose multi-label classification problems. Furthermore, each level in the hierarchy refers to a different aspect concerning the intention of the speaker both in terms of the structure of the dialog and the task. Also, since its dialogs are in Spanish, it allows us to assess whether the state-of-the-art approaches on English data generalize to a different language. More specifically, we compare the performance of different segment representation approaches focusing on both sequences and patterns of words and assess the importance of the dialog history and the relations between the multiple levels of the hierarchy. Concerning the single-label classification problem posed by the top level, we show that the conclusions drawn on English data also hold on Spanish data. Furthermore, we show that the approaches can be adapted to multi-label scenarios. Finally, by hierarchically combining the best classifiers for each level, we achieve the best results reported for this corpus.
* 21 pages, 4 figures, 17 tables, translated version of the article published in Linguam\'atica 11(1)
A Study on Dialog Act Recognition using Character-Level Tokenization
Jul 23, 2018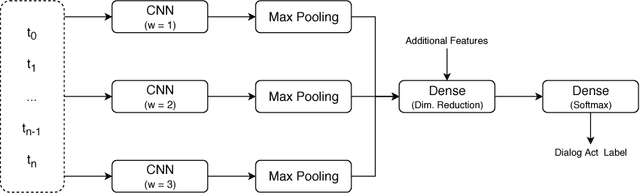


Dialog act recognition is an important step for dialog systems since it reveals the intention behind the uttered words. Most approaches on the task use word-level tokenization. In contrast, this paper explores the use of character-level tokenization. This is relevant since there is information at the sub-word level that is related to the function of the words and, thus, their intention. We also explore the use of different context windows around each token, which are able to capture important elements, such as affixes. Furthermore, we assess the importance of punctuation and capitalization. We performed experiments on both the Switchboard Dialog Act Corpus and the DIHANA Corpus. In both cases, the experiments not only show that character-level tokenization leads to better performance than the typical word-level approaches, but also that both approaches are able to capture complementary information. Thus, the best results are achieved by combining tokenization at both levels.
Deep Dialog Act Recognition using Multiple Token, Segment, and Context Information Representations
Jul 23, 2018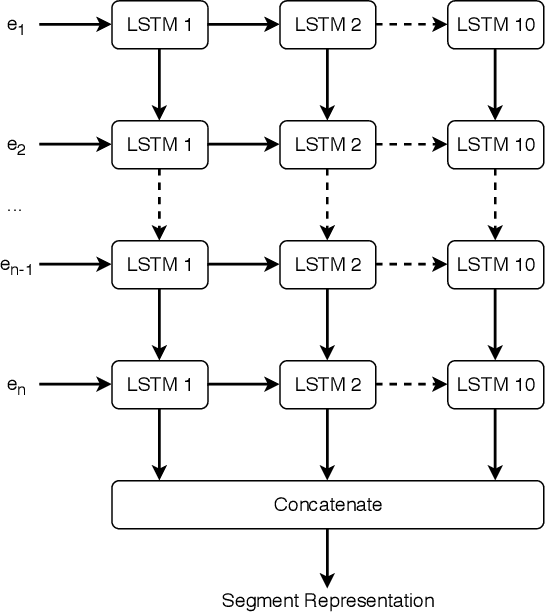
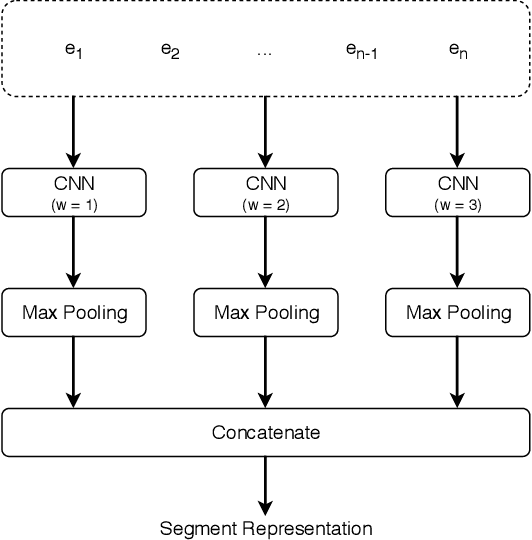
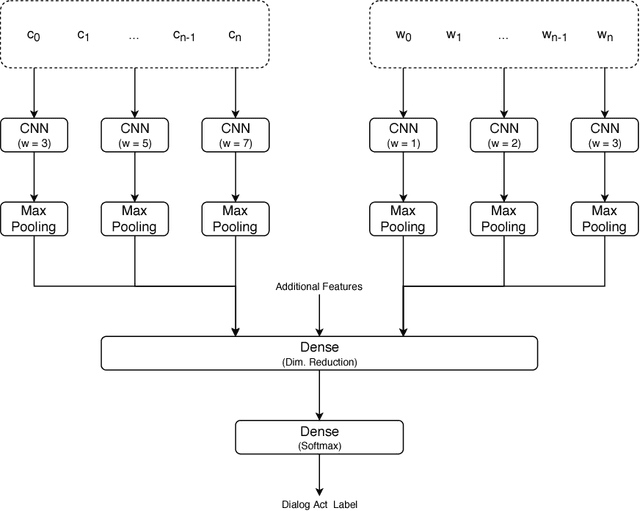
A dialog act is a representation of an intention transmitted in the form of words. In this sense, when someone wants to transmit some intention, it is revealed both in the selected words and in how they are combined to form a structured segment. Furthermore, the intentions of a speaker depend not only on her intrinsic motivation, but also on the history of the dialog and the expectation she has of its future. In this article we explore multiple representation approaches to capture cues for intention at different levels. Recent approaches on automatic dialog act recognition use Word2Vec embeddings for word representation. However, these are not able to capture segment structure information nor morphological traits related to intention. Thus, we also explore the use of dependency-based word embeddings, as well as character-level tokenization. To generate the segment representation, the top performing approaches on the task use either RNNs that are able to capture information concerning the sequentiality of the tokens or CNNs that are able to capture token patterns that reveal function. However, both aspects are important and should be captured together. Thus, we also explore the use of an RCNN. Finally, context information concerning turn-taking, as well as that provided by the surrounding segments has been proved important in previous studies. However, the representation approaches used for the latter in those studies are not appropriate to capture sequentiality, which is one of the most important characteristics of the segments in a dialog. Thus, we explore the use of approaches able to capture that information. By combining the best approaches for each aspect, we achieve results that surpass the previous state-of-the-art in a dialog system context and similar to human-level in an annotation context on the Switchboard Dialog Act Corpus, which is the most explored corpus for the task.
Assessing User Expertise in Spoken Dialog System Interactions
Jan 18, 2017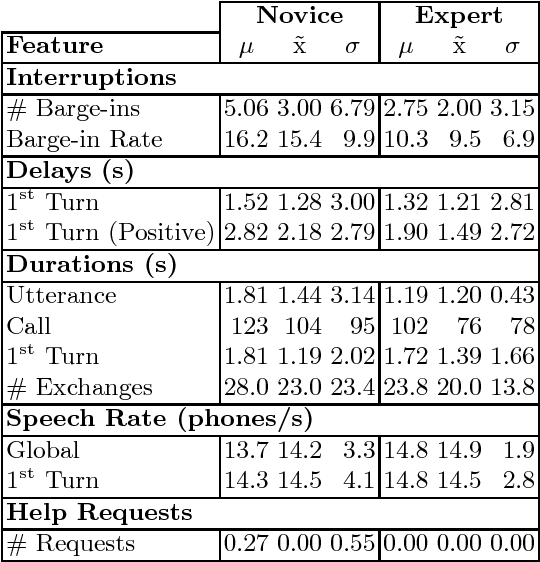
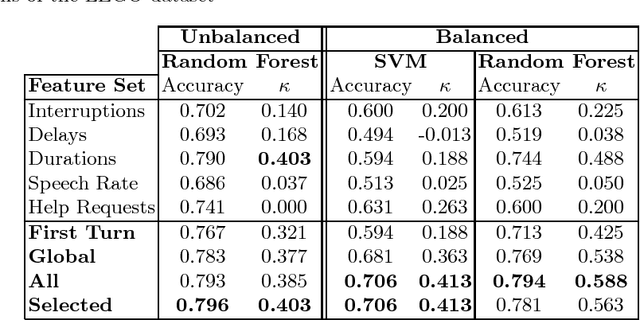
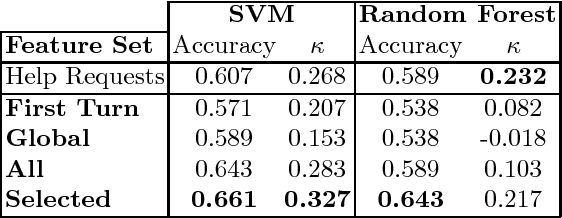
Identifying the level of expertise of its users is important for a system since it can lead to a better interaction through adaptation techniques. Furthermore, this information can be used in offline processes of root cause analysis. However, not much effort has been put into automatically identifying the level of expertise of an user, especially in dialog-based interactions. In this paper we present an approach based on a specific set of task related features. Based on the distribution of the features among the two classes - Novice and Expert - we used Random Forests as a classification approach. Furthermore, we used a Support Vector Machine classifier, in order to perform a result comparison. By applying these approaches on data from a real system, Let's Go, we obtained preliminary results that we consider positive, given the difficulty of the task and the lack of competing approaches for comparison.
* 10 pages
The Influence of Context on Dialogue Act Recognition
Jan 09, 2017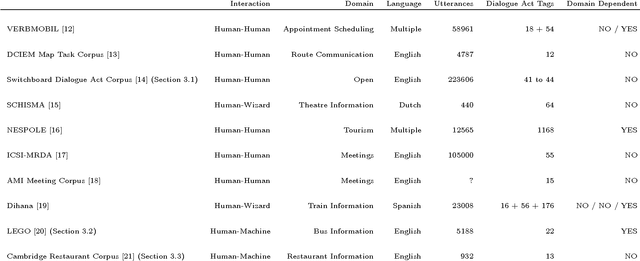
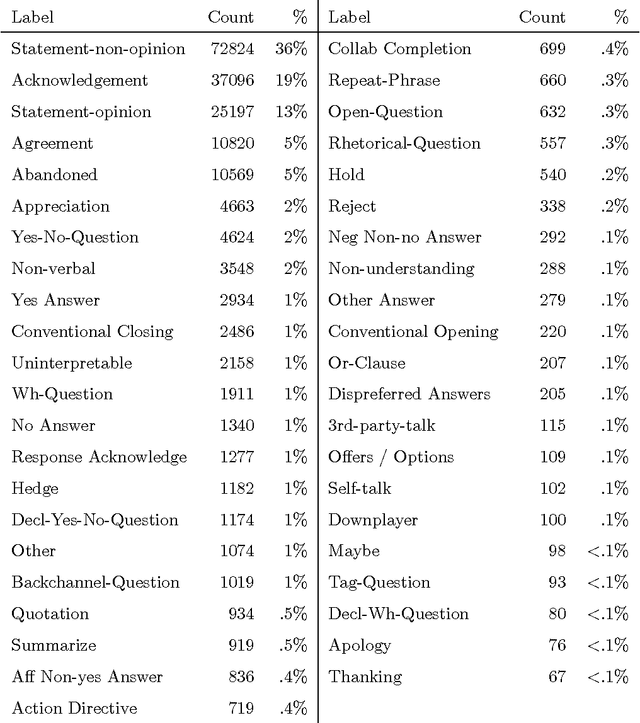
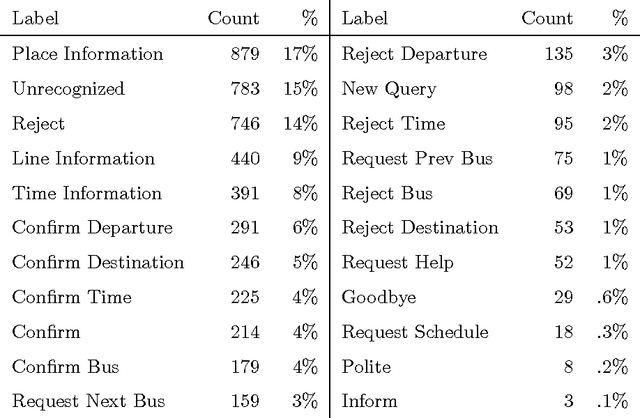
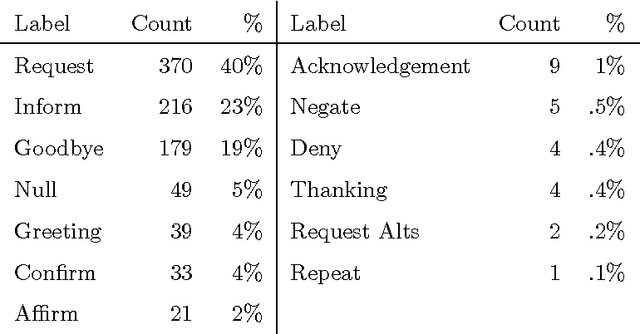
This article presents an analysis of the influence of context information on dialog act recognition. We performed experiments on the widely explored Switchboard corpus, as well as on data annotated according to the recent ISO 24617-2 standard. The latter was obtained from the Tilburg DialogBank and through the mapping of the annotations of a subset of the Let's Go corpus. We used a classification approach based on SVMs, which had proved successful in previous work and allowed us to limit the amount of context information provided. This way, we were able to observe the influence patterns as the amount of context information increased. Our base features consisted of n-grams, punctuation, and wh-words. Context information was obtained from one to five preceding segments and provided either as n-grams or dialog act classifications, with the latter typically leading to better results and more stable influence patterns. In addition to the conclusions about the importance and influence of context information, our experiments on the Switchboard corpus also led to results that advanced the state-of-the-art on the dialog act recognition task on that corpus. Furthermore, the results obtained on data annotated according to the ISO 24617-2 standard define a baseline for future work and contribute for the standardization of experiments in the area.
Mapping the Dialog Act Annotations of the LEGO Corpus into the Communicative Functions of ISO 24617-2
Dec 05, 2016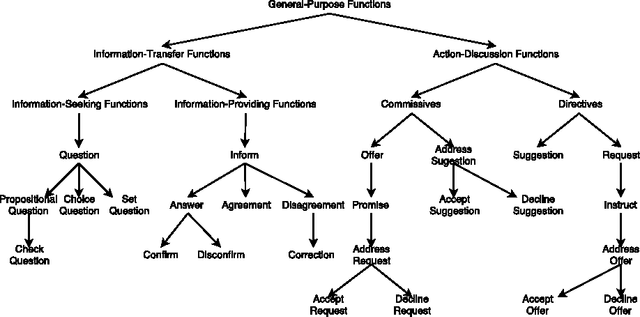
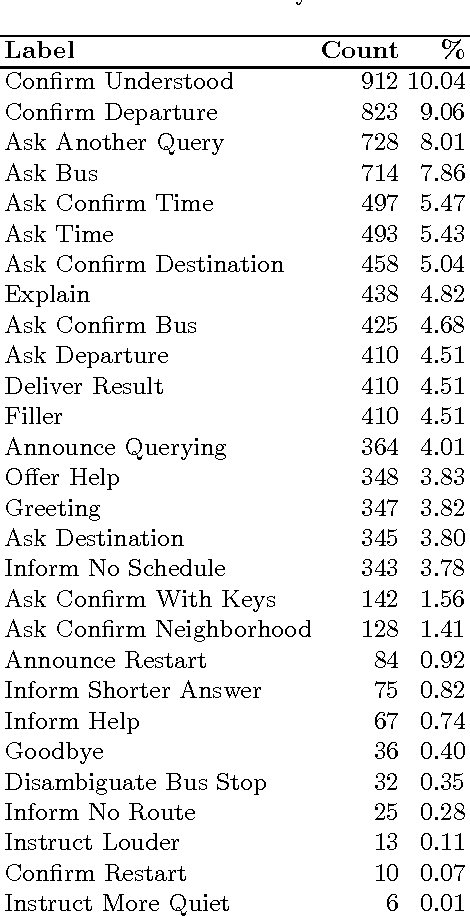
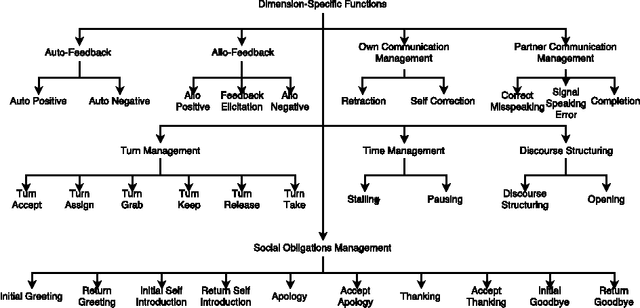
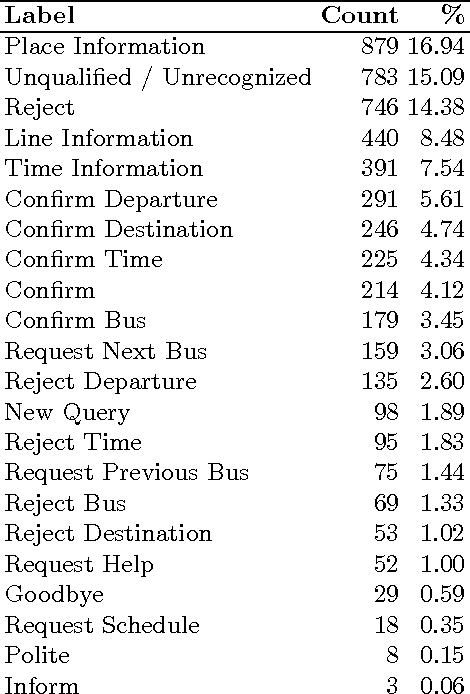
In this paper we present strategies for mapping the dialog act annotations of the LEGO corpus into the communicative functions of the ISO 24617-2 standard. Using these strategies, we obtained an additional 347 dialogs annotated according to the standard. This is particularly important given the reduced amount of existing data in those conditions due to the recency of the standard. Furthermore, these are dialogs from a widely explored corpus for dialog related tasks. However, its dialog annotations have been neglected due to their high domain-dependency, which renders them unuseful outside the context of the corpus. Thus, through our mapping process, we both obtain more data annotated according to a recent standard and provide useful dialog act annotations for a widely explored corpus in the context of dialog research.