 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaulty Coffees: Barriers to Adoption of an In-the-wild Robo-Barista
Mar 17, 2026We set out to study whether task-based narratives could influence long-term engagement with a service robot. To do so, we deployed a Robo-Barista for five weeks in an over-50's housing complex in Stockton, England. Residents received a free daily coffee by interacting with a Furhat robot assigned to either a narrative or non-narrative dialogue condition. Despite designing for sustained engagement, repeat interaction was low, and we encountered curiosity trials without retention, technical breakdowns, accessibility barriers, and the social dynamics of a housing complex setting. Rather than treating these as peripheral issues, we foreground them in this paper. We reflect on the in-the-wild realities of our experiment and offer lessons for conducting longitudinal Human-Robot Interaction research when studies unravel in practice.
Come Closer: The Effects of Robot Personality on Human Proxemics Behaviours
Sep 06, 2023



Social Robots in human environments need to be able to reason about their physical surroundings while interacting with people. Furthermore, human proxemics behaviours around robots can indicate how people perceive the robots and can inform robot personality and interaction design. Here, we introduce Charlie, a situated robot receptionist that can interact with people using verbal and non-verbal communication in a dynamic environment, where users might enter or leave the scene at any time. The robot receptionist is stationary and cannot navigate. Therefore, people have full control over their personal space as they are the ones approaching the robot. We investigated the influence of different apparent robot personalities on the proxemics behaviours of the humans. The results indicate that different types of robot personalities, specifically introversion and extroversion, can influence human proxemics behaviours. Participants maintained shorter distances with the introvert robot receptionist, compared to the extrovert robot. Interestingly, we observed that human-robot proxemics were not the same as typical human-human interpersonal distances, as defined in the literature. We therefore propose new proxemics zones for human-robot interaction.
Feeding the Coffee Habit: A Longitudinal Study of a Robo-Barista
Sep 06, 2023Studying Human-Robot Interaction over time can provide insights into what really happens when a robot becomes part of people's everyday lives. "In the Wild" studies inform the design of social robots, such as for the service industry, to enable them to remain engaging and useful beyond the novelty effect and initial adoption. This paper presents an "In the Wild" experiment where we explored the evolution of interaction between users and a Robo-Barista. We show that perceived trust and prior attitudes are both important factors associated with the usefulness, adaptability and likeability of the Robo-Barista. A combination of interaction features and user attributes are used to predict user satisfaction. Qualitative insights illuminated users' Robo-Barista experience and contribute to a number of lessons learned for future long-term studies.
We are all Individuals: The Role of Robot Personality and Human Traits in Trustworthy Interaction
Jul 28, 2023



As robots take on roles in our society, it is important that their appearance, behaviour and personality are appropriate for the job they are given and are perceived favourably by the people with whom they interact. Here, we provide an extensive quantitative and qualitative study exploring robot personality but, importantly, with respect to individual human traits. Firstly, we show that we can accurately portray personality in a social robot, in terms of extroversion-introversion using vocal cues and linguistic features. Secondly, through garnering preferences and trust ratings for these different robot personalities, we establish that, for a Robo-Barista, an extrovert robot is preferred and trusted more than an introvert robot, regardless of the subject's own personality. Thirdly, we find that individual attitudes and predispositions towards robots do impact trust in the Robo-Baristas, and are therefore important considerations in addition to robot personality, roles and interaction context when designing any human-robot interaction study.
* 8 pages, RO-MAN'22, 31st IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), August 2022, Naples, Italy
'What are you referring to?' Evaluating the Ability of Multi-Modal Dialogue Models to Process Clarificational Exchanges
Jul 28, 2023



Referential ambiguities arise in dialogue when a referring expression does not uniquely identify the intended referent for the addressee. Addressees usually detect such ambiguities immediately and work with the speaker to repair it using meta-communicative, Clarificational Exchanges (CE): a Clarification Request (CR) and a response. Here, we argue that the ability to generate and respond to CRs imposes specific constraints on the architecture and objective functions of multi-modal, visually grounded dialogue models. We use the SIMMC 2.0 dataset to evaluate the ability of different state-of-the-art model architectures to process CEs, with a metric that probes the contextual updates that arise from them in the model. We find that language-based models are able to encode simple multi-modal semantic information and process some CEs, excelling with those related to the dialogue history, whilst multi-modal models can use additional learning objectives to obtain disentangled object representations, which become crucial to handle complex referential ambiguities across modalities overall.
A Surrogate Model Framework for Explainable Autonomous Behaviour
May 31, 2023



Adoption and deployment of robotic and autonomous systems in industry are currently hindered by the lack of transparency, required for safety and accountability. Methods for providing explanations are needed that are agnostic to the underlying autonomous system and easily updated. Furthermore, different stakeholders with varying levels of expertise, will require different levels of information. In this work, we use surrogate models to provide transparency as to the underlying policies for behaviour activation. We show that these surrogate models can effectively break down autonomous agents' behaviour into explainable components for use in natural language explanations.
Towards Explaining Autonomy with Verbalised Decision Tree States
Sep 28, 2022
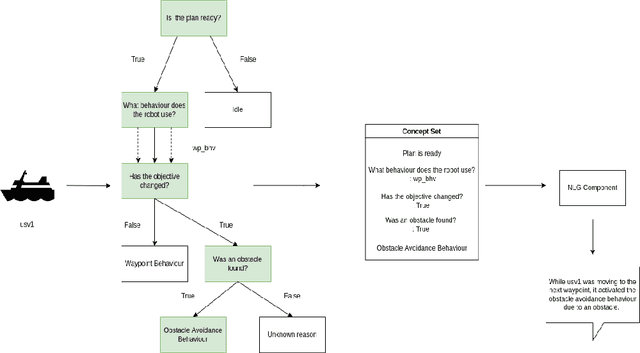
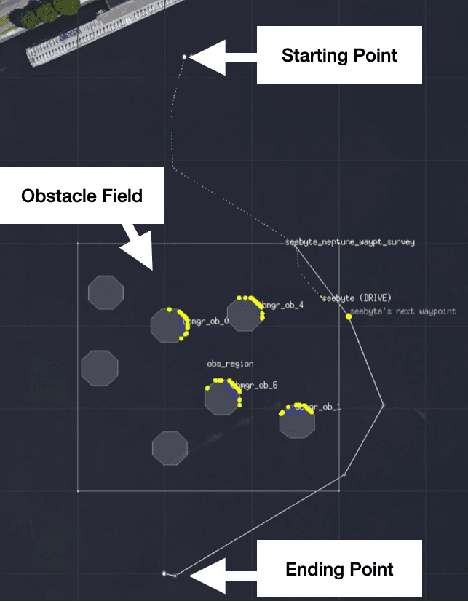
The development of new AUV technology increased the range of tasks that AUVs can tackle and the length of their operations. As a result, AUVs are capable of handling highly complex operations. However, these missions do not fit easily into the traditional method of defining a mission as a series of pre-planned waypoints because it is not possible to know, in advance, everything that might occur during the mission. This results in a gap between the operator's expectations and actual operational performance. Consequently, this can create a diminished level of trust between the operators and AUVs, resulting in unnecessary mission interruptions. To bridge this gap between in-mission robotic behaviours and operators' expectations, this work aims to provide a framework to explain decisions and actions taken by an autonomous vehicle during the mission, in an easy-to-understand manner. Additionally, the objective is to have an autonomy-agnostic system that can be added as an additional layer on top of any autonomy architecture. To make the approach applicable across different autonomous systems equipped with different autonomies, this work decouples the inner workings of the autonomy from the decision points and the resulting executed actions applying Knowledge Distillation. Finally, to present the explanations to the operators in a more natural way, the output of the distilled decision tree is combined with natural language explanations and reported to the operators as sentences. For this reason, an additional step known as Concept2Text Generation is added at the end of the explanation pipeline.
Classification of Phonological Parameters in Sign Languages
May 24, 2022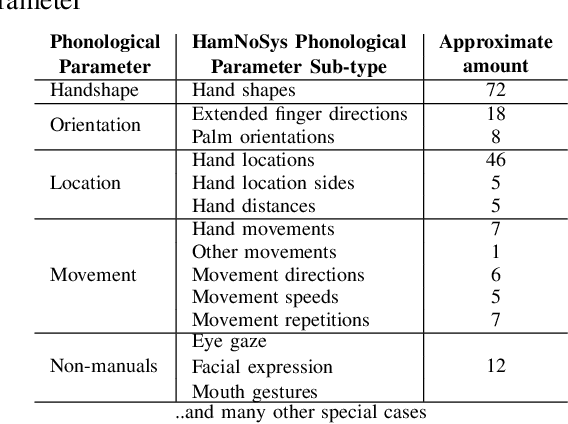

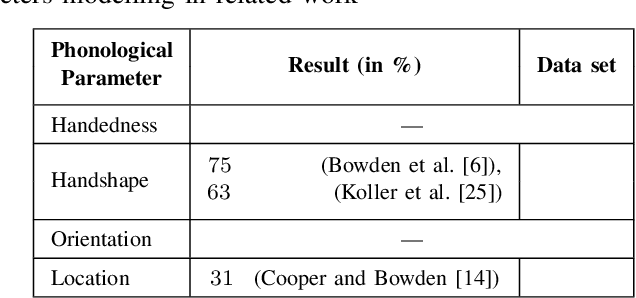
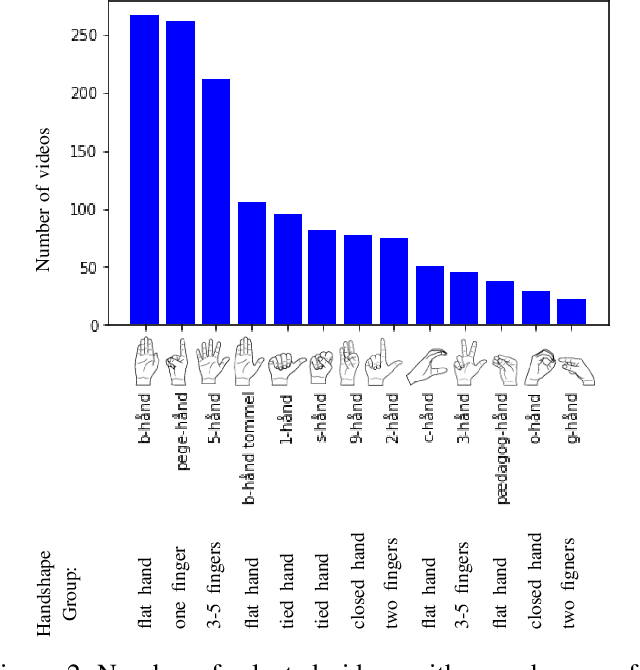
Signers compose sign language phonemes that enable communication by combining phonological parameters such as handshape, orientation, location, movement, and non-manual features. Linguistic research often breaks down signs into their constituent parts to study sign languages and often a lot of effort is invested into the annotation of the videos. In this work we show how a single model can be used to recognise the individual phonological parameters within sign languages with the aim of either to assist linguistic annotations or to describe the signs for the sign recognition models. We use Danish Sign Language data set `Ordbog over Dansk Tegnsprog' to generate multiple data sets using pose estimation model, which are then used for training the multi-label Fast R-CNN model to support multi-label modelling. Moreover, we show that there is a significant co-dependence between the orientation and location phonological parameters in the generated data and we incorporate this co-dependence in the model to achieve better performance.
Unsupervised Sign Language Phoneme Clustering using HamNoSys Notation
May 21, 2022

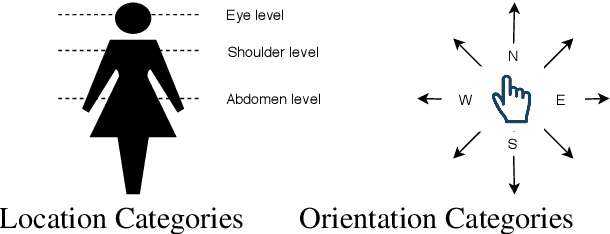
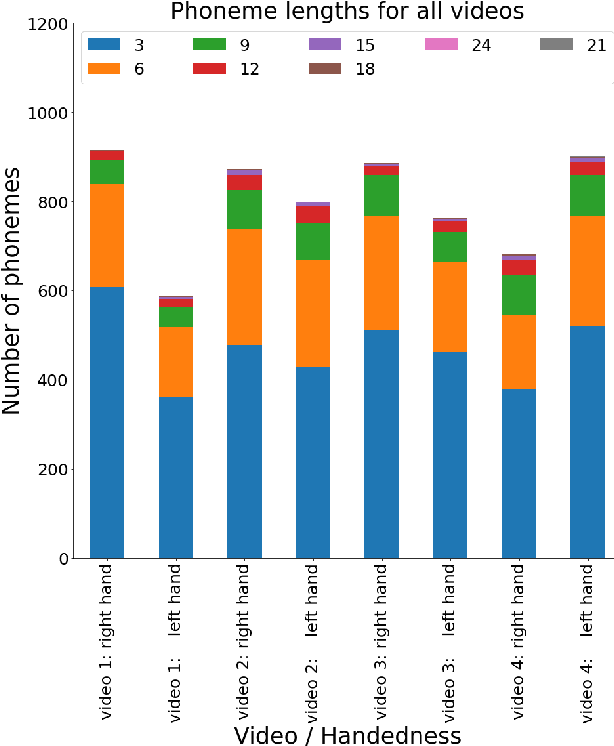
Traditionally, sign language resources have been collected in controlled settings for specific tasks involving supervised sign classification or linguistic studies accompanied by specific annotation type. To date, very few who explored signing videos found online on social media platforms as well as the use of unsupervised methods applied to such resources. Due to the fact that the field is striving to achieve acceptable model performance on the data that differs from that seen during training calls for more diversity in sign language data, stepping away from the data obtained in controlled laboratory settings. Moreover, since the sign language data collection and annotation carries large overheads, it is desirable to accelerate the annotation process. Considering the aforementioned tendencies, this paper takes the side of harvesting online data in a pursuit for automatically generating and annotating sign language corpora through phoneme clustering.
Exploring Multi-Modal Representations for Ambiguity Detection & Coreference Resolution in the SIMMC 2.0 Challenge
Feb 25, 2022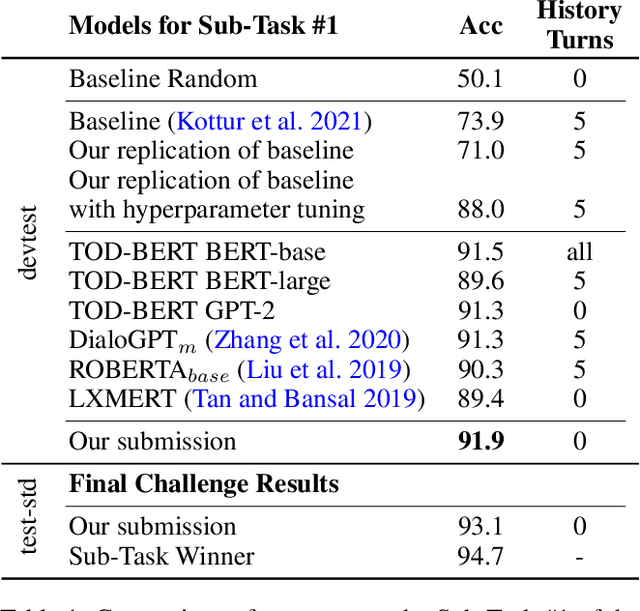
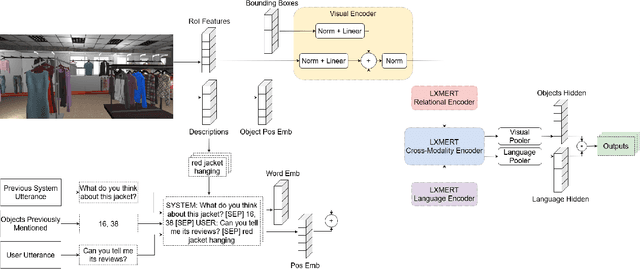
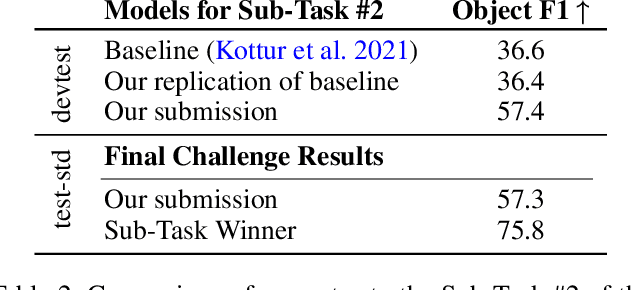
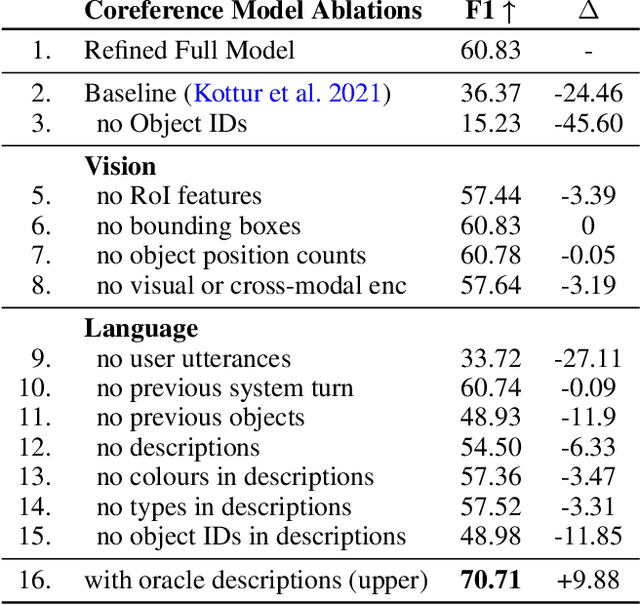
Anaphoric expressions, such as pronouns and referential descriptions, are situated with respect to the linguistic context of prior turns, as well as, the immediate visual environment. However, a speaker's referential descriptions do not always uniquely identify the referent, leading to ambiguities in need of resolution through subsequent clarificational exchanges. Thus, effective Ambiguity Detection and Coreference Resolution are key to task success in Conversational AI. In this paper, we present models for these two tasks as part of the SIMMC 2.0 Challenge (Kottur et al. 2021). Specifically, we use TOD-BERT and LXMERT based models, compare them to a number of baselines and provide ablation experiments. Our results show that (1) language models are able to exploit correlations in the data to detect ambiguity; and (2) unimodal coreference resolution models can avoid the need for a vision component, through the use of smart object representations.