 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefocus Map Estimation and Deblurring from a Single Dual-Pixel Image
Oct 12, 2021
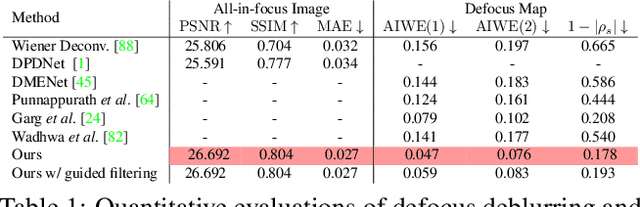
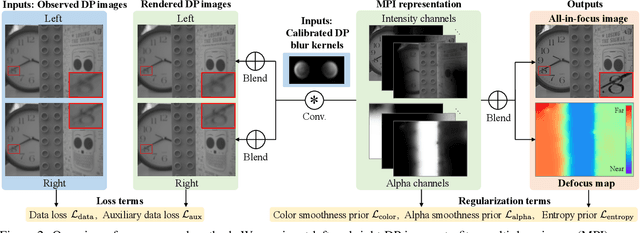
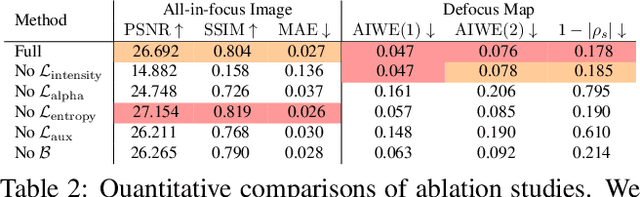
We present a method that takes as input a single dual-pixel image, and simultaneously estimates the image's defocus map -- the amount of defocus blur at each pixel -- and recovers an all-in-focus image. Our method is inspired from recent works that leverage the dual-pixel sensors available in many consumer cameras to assist with autofocus, and use them for recovery of defocus maps or all-in-focus images. These prior works have solved the two recovery problems independently of each other, and often require large labeled datasets for supervised training. By contrast, we show that it is beneficial to treat these two closely-connected problems simultaneously. To this end, we set up an optimization problem that, by carefully modeling the optics of dual-pixel images, jointly solves both problems. We use data captured with a consumer smartphone camera to demonstrate that, after a one-time calibration step, our approach improves upon prior works for both defocus map estimation and blur removal, despite being entirely unsupervised.
Scalable Font Reconstruction with Dual Latent Manifolds
Sep 10, 2021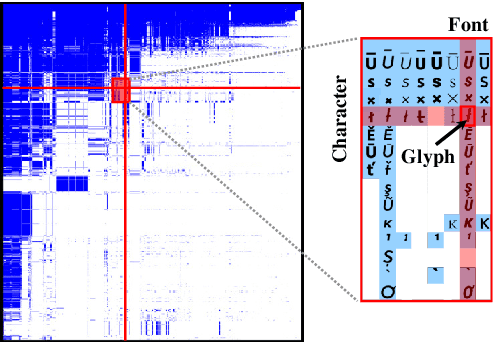
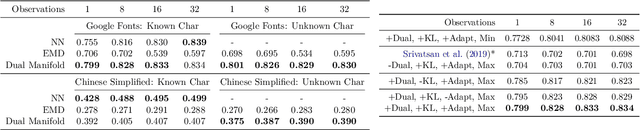
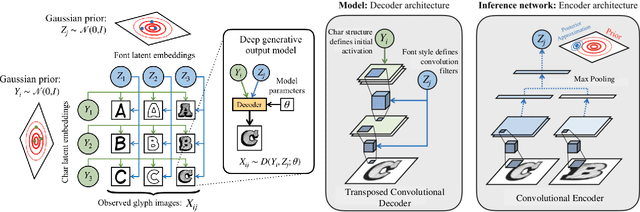
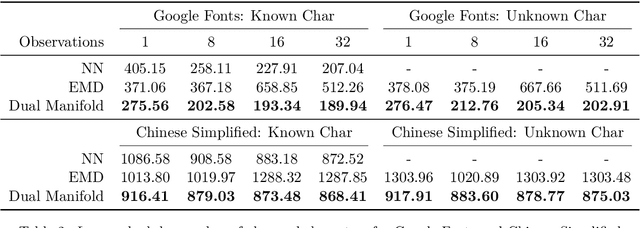
We propose a deep generative model that performs typography analysis and font reconstruction by learning disentangled manifolds of both font style and character shape. Our approach enables us to massively scale up the number of character types we can effectively model compared to previous methods. Specifically, we infer separate latent variables representing character and font via a pair of inference networks which take as input sets of glyphs that either all share a character type, or belong to the same font. This design allows our model to generalize to characters that were not observed during training time, an important task in light of the relative sparsity of most fonts. We also put forward a new loss, adapted from prior work that measures likelihood using an adaptive distribution in a projected space, resulting in more natural images without requiring a discriminator. We evaluate on the task of font reconstruction over various datasets representing character types of many languages, and compare favorably to modern style transfer systems according to both automatic and manually-evaluated metrics.
HyperNeRF: A Higher-Dimensional Representation for Topologically Varying Neural Radiance Fields
Jun 24, 2021
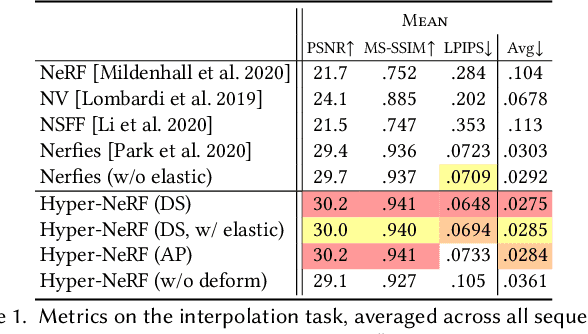
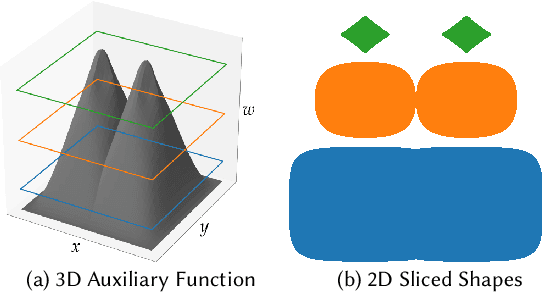
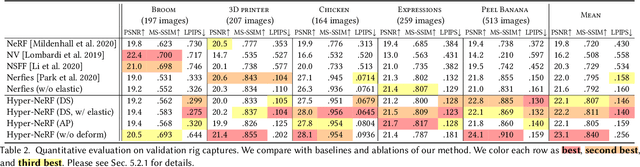
Neural Radiance Fields (NeRF) are able to reconstruct scenes with unprecedented fidelity, and various recent works have extended NeRF to handle dynamic scenes. A common approach to reconstruct such non-rigid scenes is through the use of a learned deformation field mapping from coordinates in each input image into a canonical template coordinate space. However, these deformation-based approaches struggle to model changes in topology, as topological changes require a discontinuity in the deformation field, but these deformation fields are necessarily continuous. We address this limitation by lifting NeRFs into a higher dimensional space, and by representing the 5D radiance field corresponding to each individual input image as a slice through this "hyper-space". Our method is inspired by level set methods, which model the evolution of surfaces as slices through a higher dimensional surface. We evaluate our method on two tasks: (i) interpolating smoothly between "moments", i.e., configurations of the scene, seen in the input images while maintaining visual plausibility, and (ii) novel-view synthesis at fixed moments. We show that our method, which we dub HyperNeRF, outperforms existing methods on both tasks by significant margins. Compared to Nerfies, HyperNeRF reduces average error rates by 8.6% for interpolation and 8.8% for novel-view synthesis, as measured by LPIPS.
NeRFactor: Neural Factorization of Shape and Reflectance Under an Unknown Illumination
Jun 03, 2021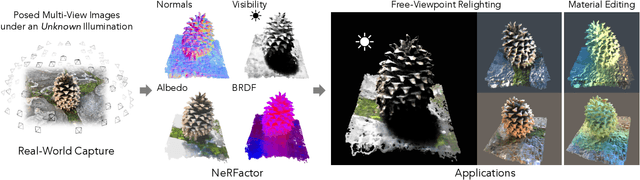
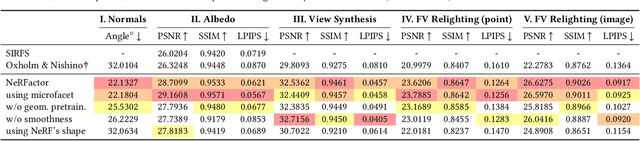
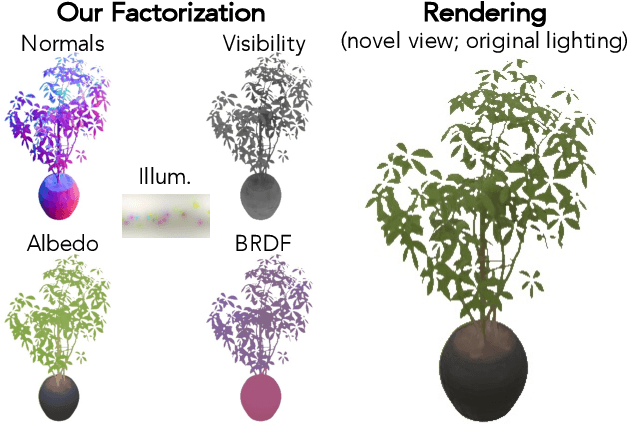
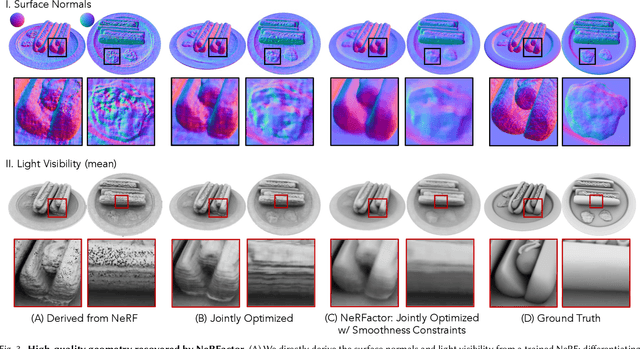
We address the problem of recovering the shape and spatially-varying reflectance of an object from posed multi-view images of the object illuminated by one unknown lighting condition. This enables the rendering of novel views of the object under arbitrary environment lighting and editing of the object's material properties. The key to our approach, which we call Neural Radiance Factorization (NeRFactor), is to distill the volumetric geometry of a Neural Radiance Field (NeRF) [Mildenhall et al. 2020] representation of the object into a surface representation and then jointly refine the geometry while solving for the spatially-varying reflectance and the environment lighting. Specifically, NeRFactor recovers 3D neural fields of surface normals, light visibility, albedo, and Bidirectional Reflectance Distribution Functions (BRDFs) without any supervision, using only a re-rendering loss, simple smoothness priors, and a data-driven BRDF prior learned from real-world BRDF measurements. By explicitly modeling light visibility, NeRFactor is able to separate shadows from albedo and synthesize realistic soft or hard shadows under arbitrary lighting conditions. NeRFactor is able to recover convincing 3D models for free-viewpoint relighting in this challenging and underconstrained capture setup for both synthetic and real scenes. Qualitative and quantitative experiments show that NeRFactor outperforms classic and deep learning-based state of the art across various tasks. Our code and data are available at people.csail.mit.edu/xiuming/projects/nerfactor/.
Baking Neural Radiance Fields for Real-Time View Synthesis
Mar 26, 2021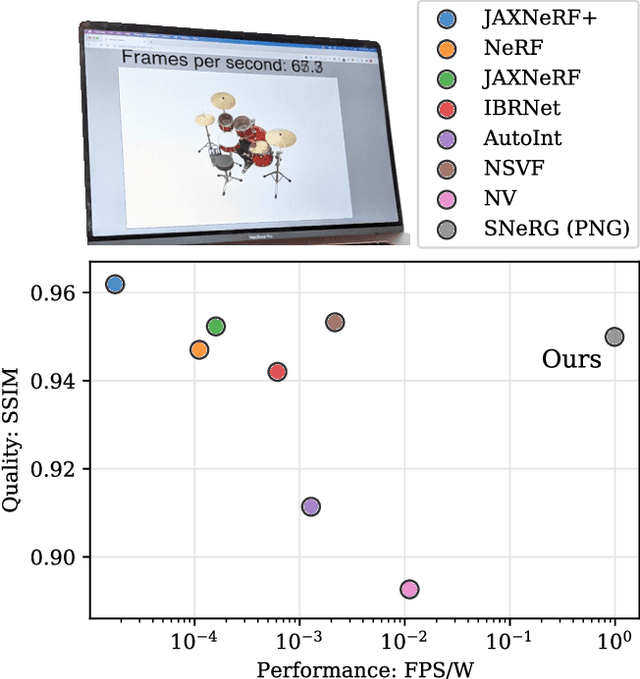

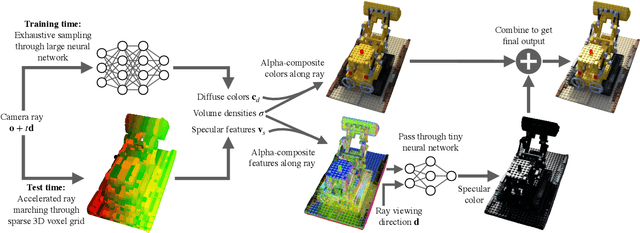
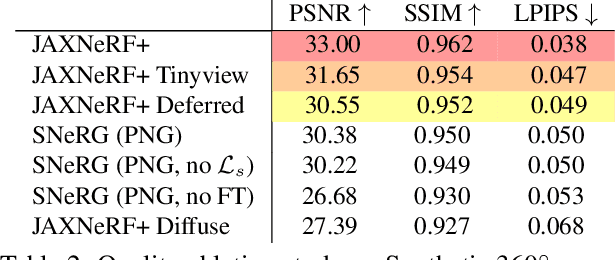
Neural volumetric representations such as Neural Radiance Fields (NeRF) have emerged as a compelling technique for learning to represent 3D scenes from images with the goal of rendering photorealistic images of the scene from unobserved viewpoints. However, NeRF's computational requirements are prohibitive for real-time applications: rendering views from a trained NeRF requires querying a multilayer perceptron (MLP) hundreds of times per ray. We present a method to train a NeRF, then precompute and store (i.e. "bake") it as a novel representation called a Sparse Neural Radiance Grid (SNeRG) that enables real-time rendering on commodity hardware. To achieve this, we introduce 1) a reformulation of NeRF's architecture, and 2) a sparse voxel grid representation with learned feature vectors. The resulting scene representation retains NeRF's ability to render fine geometric details and view-dependent appearance, is compact (averaging less than 90 MB per scene), and can be rendered in real-time (higher than 30 frames per second on a laptop GPU). Actual screen captures are shown in our video.
Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields
Mar 24, 2021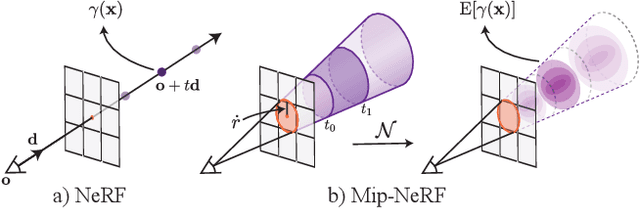


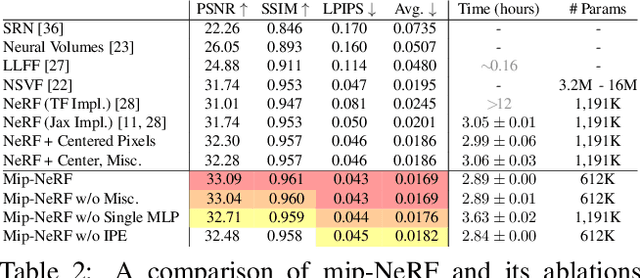
The rendering procedure used by neural radiance fields (NeRF) samples a scene with a single ray per pixel and may therefore produce renderings that are excessively blurred or aliased when training or testing images observe scene content at different resolutions. The straightforward solution of supersampling by rendering with multiple rays per pixel is impractical for NeRF, because rendering each ray requires querying a multilayer perceptron hundreds of times. Our solution, which we call "mip-NeRF" (a la "mipmap"), extends NeRF to represent the scene at a continuously-valued scale. By efficiently rendering anti-aliased conical frustums instead of rays, mip-NeRF reduces objectionable aliasing artifacts and significantly improves NeRF's ability to represent fine details, while also being 7% faster than NeRF and half the size. Compared to NeRF, mip-NeRF reduces average error rates by 16% on the dataset presented with NeRF and by 60% on a challenging multiscale variant of that dataset that we present. Mip-NeRF is also able to match the accuracy of a brute-force supersampled NeRF on our multiscale dataset while being 22x faster.
IBRNet: Learning Multi-View Image-Based Rendering
Feb 25, 2021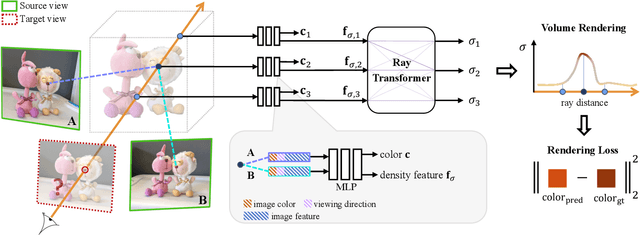
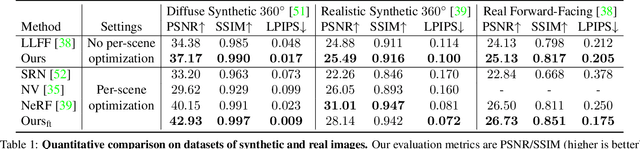
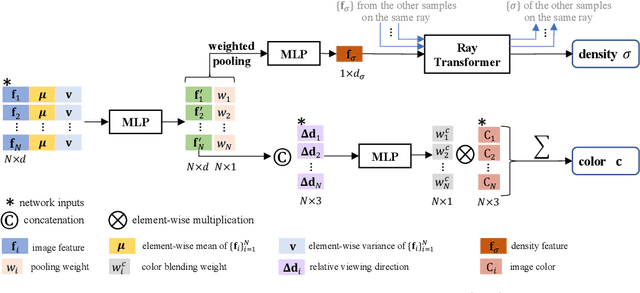
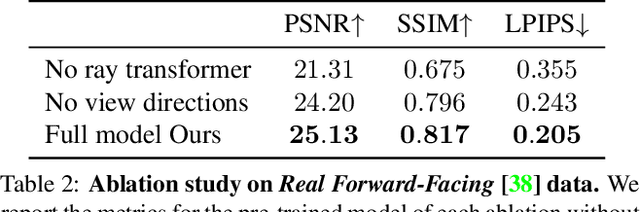
We present a method that synthesizes novel views of complex scenes by interpolating a sparse set of nearby views. The core of our method is a network architecture that includes a multilayer perceptron and a ray transformer that estimates radiance and volume density at continuous 5D locations (3D spatial locations and 2D viewing directions), drawing appearance information on the fly from multiple source views. By drawing on source views at render time, our method hearkens back to classic work on image-based rendering (IBR), and allows us to render high-resolution imagery. Unlike neural scene representation work that optimizes per-scene functions for rendering, we learn a generic view interpolation function that generalizes to novel scenes. We render images using classic volume rendering, which is fully differentiable and allows us to train using only multi-view posed images as supervision. Experiments show that our method outperforms recent novel view synthesis methods that also seek to generalize to novel scenes. Further, if fine-tuned on each scene, our method is competitive with state-of-the-art single-scene neural rendering methods.
iNeRF: Inverting Neural Radiance Fields for Pose Estimation
Dec 10, 2020
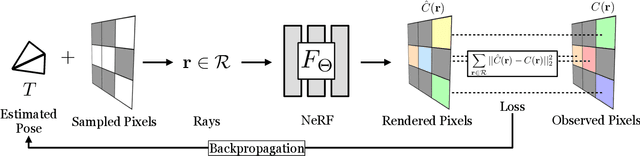
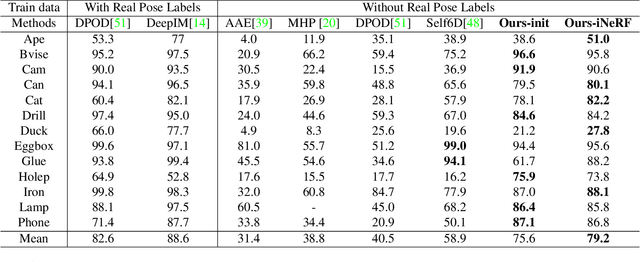
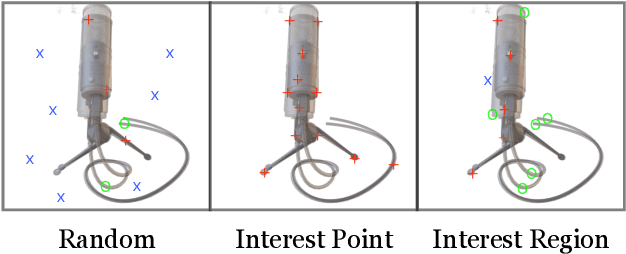
We present iNeRF, a framework that performs pose estimation by "inverting" a trained Neural Radiance Field (NeRF). NeRFs have been shown to be remarkably effective for the task of view synthesis - synthesizing photorealistic novel views of real-world scenes or objects. In this work, we investigate whether we can apply analysis-by-synthesis with NeRF for 6DoF pose estimation - given an image, find the translation and rotation of a camera relative to a 3D model. Starting from an initial pose estimate, we use gradient descent to minimize the residual between pixels rendered from an already-trained NeRF and pixels in an observed image. In our experiments, we first study 1) how to sample rays during pose refinement for iNeRF to collect informative gradients and 2) how different batch sizes of rays affect iNeRF on a synthetic dataset. We then show that for complex real-world scenes from the LLFF dataset, iNeRF can improve NeRF by estimating the camera poses of novel images and using these images as additional training data for NeRF. Finally, we show iNeRF can be combined with feature-based pose initialization. The approach outperforms all other RGB-based methods relying on synthetic data on LineMOD.
NeRD: Neural Reflectance Decomposition from Image Collections
Dec 08, 2020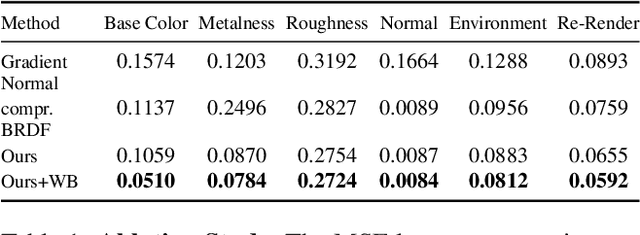

Decomposing a scene into its shape, reflectance, and illumination is a challenging but essential problem in computer vision and graphics. This problem is inherently more challenging when the illumination is not a single light source under laboratory conditions but is instead an unconstrained environmental illumination. Though recent work has shown that implicit representations can be used to model the radiance field of an object, these techniques only enable view synthesis and not relighting. Additionally, evaluating these radiance fields is resource and time-intensive. By decomposing a scene into explicit representations, any rendering framework can be leveraged to generate novel views under any illumination in real-time. NeRD is a method that achieves this decomposition by introducing physically-based rendering to neural radiance fields. Even challenging non-Lambertian reflectances, complex geometry, and unknown illumination can be decomposed to high-quality models. The datasets and code is available at the project page: https://markboss.me/publication/2021-nerd/
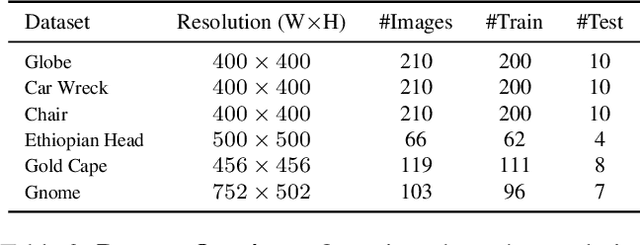
NeRV: Neural Reflectance and Visibility Fields for Relighting and View Synthesis
Dec 07, 2020
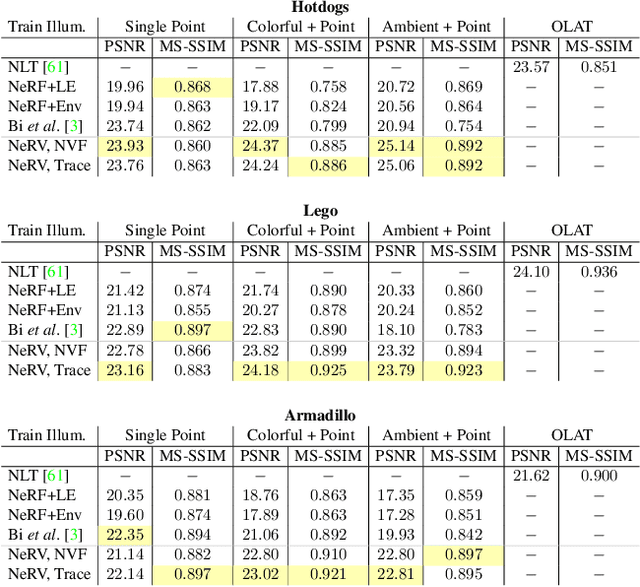
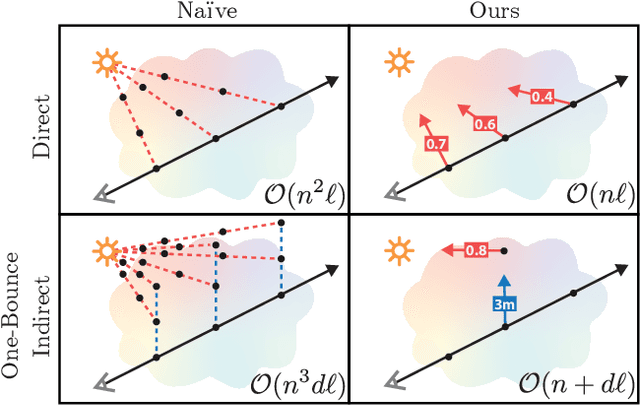
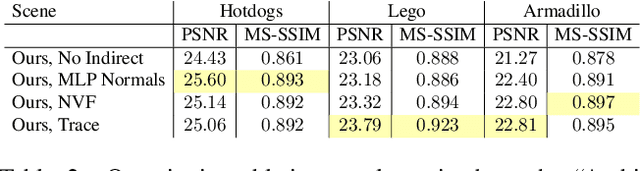
We present a method that takes as input a set of images of a scene illuminated by unconstrained known lighting, and produces as output a 3D representation that can be rendered from novel viewpoints under arbitrary lighting conditions. Our method represents the scene as a continuous volumetric function parameterized as MLPs whose inputs are a 3D location and whose outputs are the following scene properties at that input location: volume density, surface normal, material parameters, distance to the first surface intersection in any direction, and visibility of the external environment in any direction. Together, these allow us to render novel views of the object under arbitrary lighting, including indirect illumination effects. The predicted visibility and surface intersection fields are critical to our model's ability to simulate direct and indirect illumination during training, because the brute-force techniques used by prior work are intractable for lighting conditions outside of controlled setups with a single light. Our method outperforms alternative approaches for recovering relightable 3D scene representations, and performs well in complex lighting settings that have posed a significant challenge to prior work.