 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions
Feb 16, 2018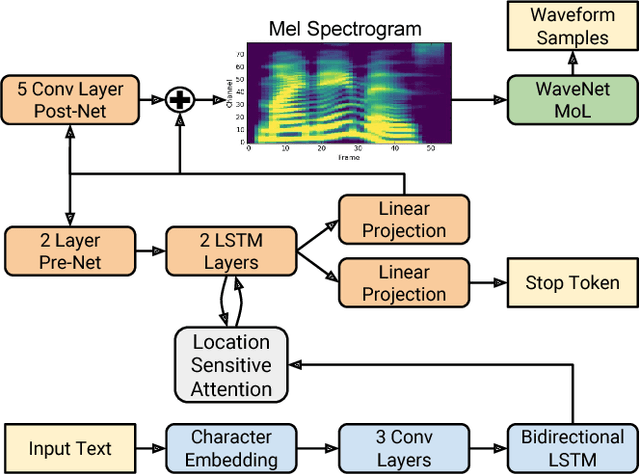

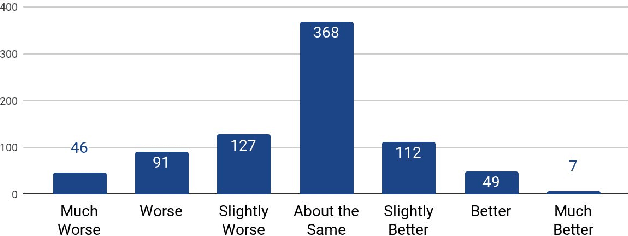
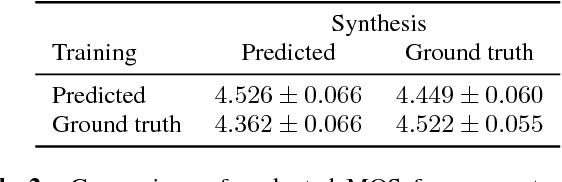
This paper describes Tacotron 2, a neural network architecture for speech synthesis directly from text. The system is composed of a recurrent sequence-to-sequence feature prediction network that maps character embeddings to mel-scale spectrograms, followed by a modified WaveNet model acting as a vocoder to synthesize timedomain waveforms from those spectrograms. Our model achieves a mean opinion score (MOS) of $4.53$ comparable to a MOS of $4.58$ for professionally recorded speech. To validate our design choices, we present ablation studies of key components of our system and evaluate the impact of using mel spectrograms as the input to WaveNet instead of linguistic, duration, and $F_0$ features. We further demonstrate that using a compact acoustic intermediate representation enables significant simplification of the WaveNet architecture.
In Teacher We Trust: Learning Compressed Models for Pedestrian Detection
Dec 01, 2016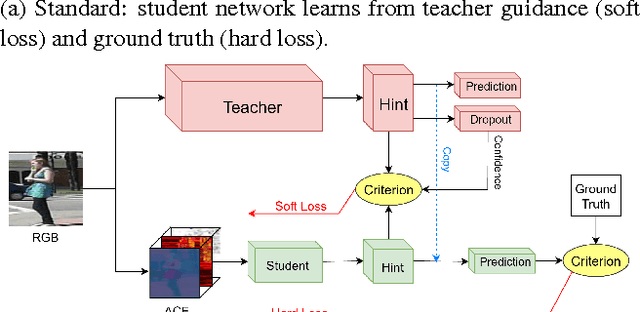
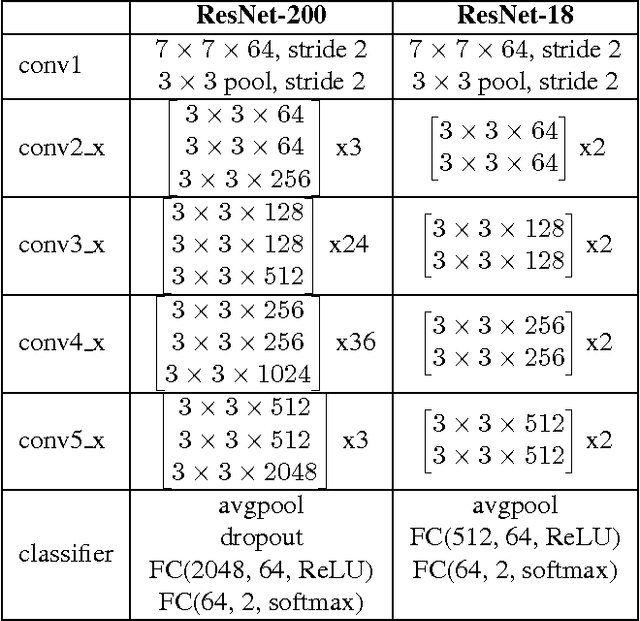
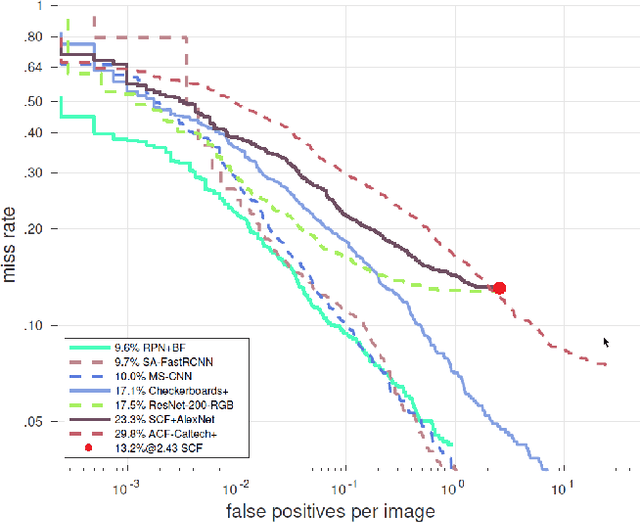
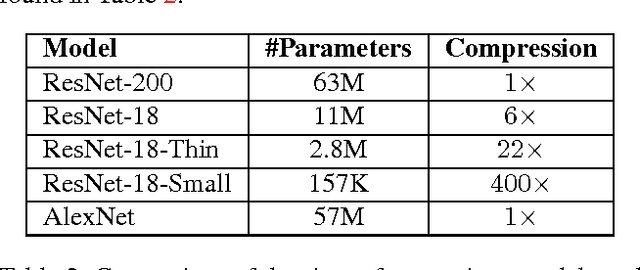
Deep convolutional neural networks continue to advance the state-of-the-art in many domains as they grow bigger and more complex. It has been observed that many of the parameters of a large network are redundant, allowing for the possibility of learning a smaller network that mimics the outputs of the large network through a process called Knowledge Distillation. We show, however, that standard Knowledge Distillation is not effective for learning small models for the task of pedestrian detection. To improve this process, we introduce a higher-dimensional hint layer to increase information flow. We also estimate the variance in the outputs of the large network and propose a loss function to incorporate this uncertainty. Finally, we attempt to boost the complexity of the small network without increasing its size by using as input hand-designed features that have been demonstrated to be effective for pedestrian detection. We succeed in training a model that contains $400\times$ fewer parameters than the large network while outperforming AlexNet on the Caltech Pedestrian Dataset.