 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Detect Novel and Fine-Grained Acoustic Sequences Using Pretrained Audio Representations
May 03, 2023This work investigates pretrained audio representations for few shot Sound Event Detection. We specifically address the task of few shot detection of novel acoustic sequences, or sound events with semantically meaningful temporal structure, without assuming access to non-target audio. We develop procedures for pretraining suitable representations, and methods which transfer them to our few shot learning scenario. Our experiments evaluate the general purpose utility of our pretrained representations on AudioSet, and the utility of proposed few shot methods via tasks constructed from real-world acoustic sequences. Our pretrained embeddings are suitable to the proposed task, and enable multiple aspects of our few shot framework.
Local Metrics for Multi-Object Tracking
Apr 06, 2021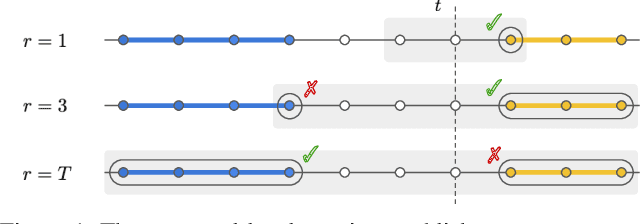
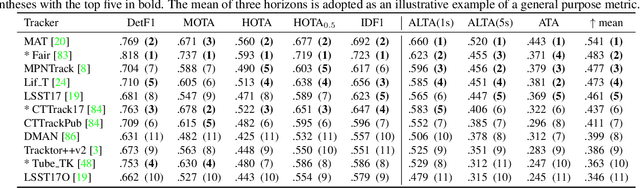
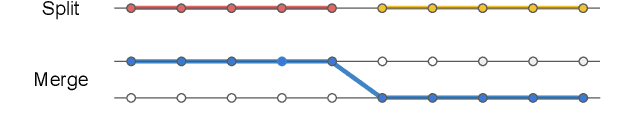
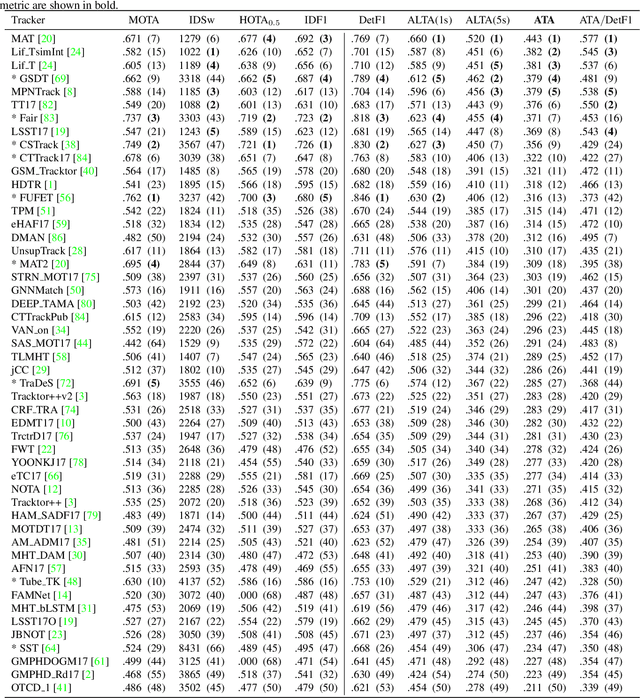
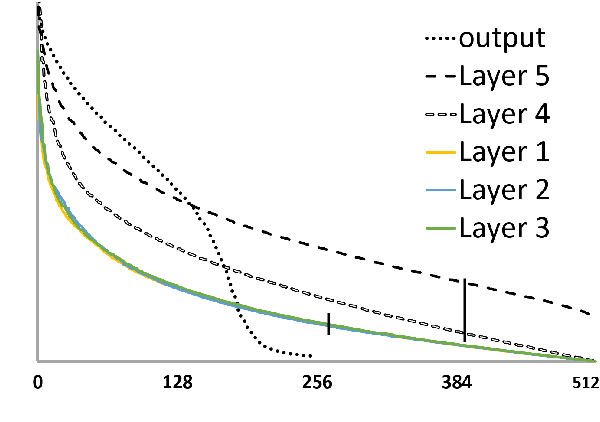
This paper introduces temporally local metrics for Multi-Object Tracking. These metrics are obtained by restricting existing metrics based on track matching to a finite temporal horizon, and provide new insight into the ability of trackers to maintain identity over time. Moreover, the horizon parameter offers a novel, meaningful mechanism by which to define the relative importance of detection and association, a common dilemma in applications where imperfect association is tolerable. It is shown that the historical Average Tracking Accuracy (ATA) metric exhibits superior sensitivity to association, enabling its proposed local variant, ALTA, to capture a wide range of characteristics. In particular, ALTA is better equipped to identify advances in association independent of detection. The paper further presents an error decomposition for ATA that reveals the impact of four distinct error types and is equally applicable to ALTA. The diagnostic capabilities of ALTA are demonstrated on the MOT 2017 and Waymo Open Dataset benchmarks.
The surprising impact of mask-head architecture on novel class segmentation
Apr 01, 2021
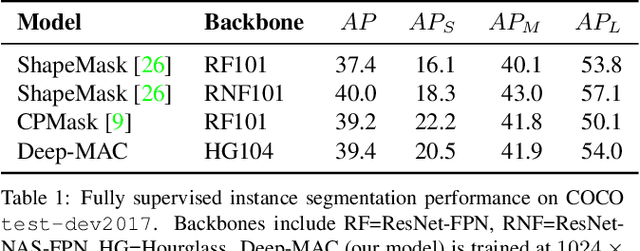
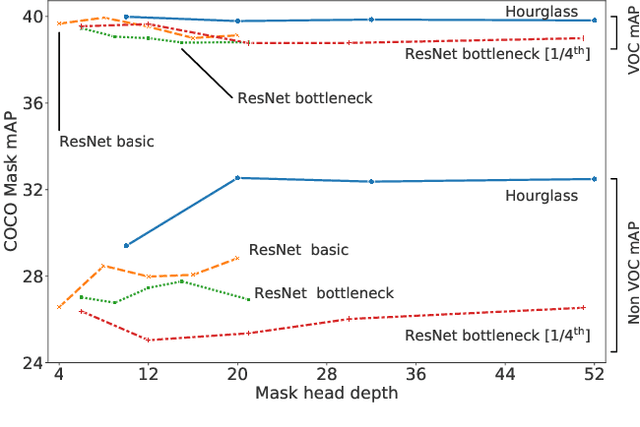
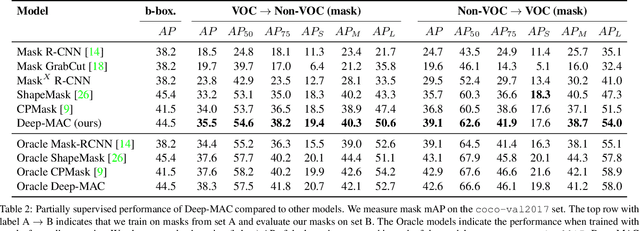
Instance segmentation models today are very accurate when trained on large annotated datasets, but collecting mask annotations at scale is prohibitively expensive. We address the partially supervised instance segmentation problem in which one can train on (significantly cheaper) bounding boxes for all categories but use masks only for a subset of categories. In this work, we focus on a popular family of models which apply differentiable cropping to a feature map and predict a mask based on the resulting crop. Within this family, we show that the architecture of the mask-head plays a surprisingly important role in generalization to classes for which we do not observe masks during training. While many architectures perform similarly when trained in fully supervised mode, we show that they often generalize to novel classes in dramatically different ways. We call this phenomenon the strong mask generalization effect, which we exploit by replacing the typical mask-head of 2-4 layers with significantly deeper off-the-shelf architectures (e.g. ResNet, Hourglass models). We also show that the choice of mask-head architecture alone can lead to SOTA results on the partially supervised COCO benchmark without the need of specialty modules or losses proposed by prior literature. Finally, we demonstrate that our effect is general, holding across underlying detection methodologies, (e.g. both anchor-based or anchor free or no detector at all) and across different backbone networks. Code and pre-trained models are available at https://git.io/deepmac.
PERF-Net: Pose Empowered RGB-Flow Net
Sep 28, 2020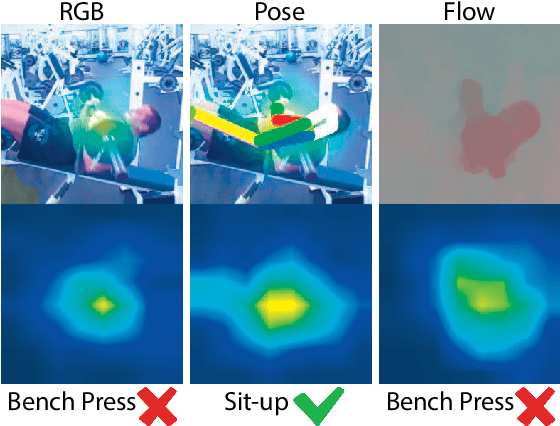
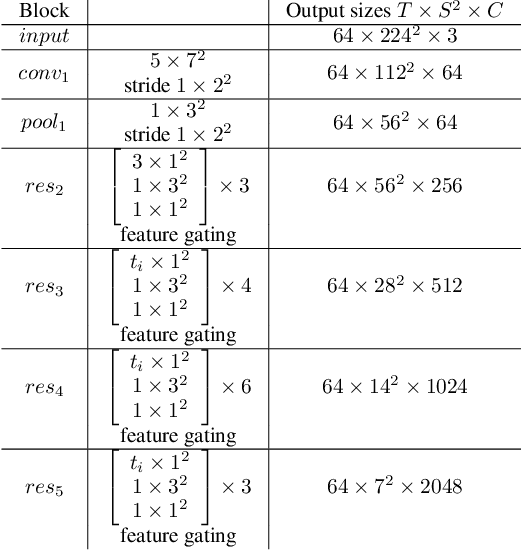

In recent years, many works in the video action recognition literature have shown that two stream models (combining spatial and temporal input streams) are necessary for achieving state of the art performance. In this paper we show the benefits of including yet another stream based on human pose estimated from each frame -- specifically by rendering pose on input RGB frames. At first blush, this additional stream may seem redundant given that human pose is fully determined by RGB pixel values -- however we show (perhaps surprisingly) that this simple and flexible addition can provide complementary gains. Using this insight, we then propose a new model, which we dub PERF-Net (short for Pose Empowered RGB-Flow Net), which combines this new pose stream with the standard RGB and flow based input streams via distillation techniques and show that our model outperforms the state-of-the-art by a large margin in a number of human action recognition datasets while not requiring flow or pose to be explicitly computed at inference time.
Compact Speaker Embedding: lrx-vector
Aug 11, 2020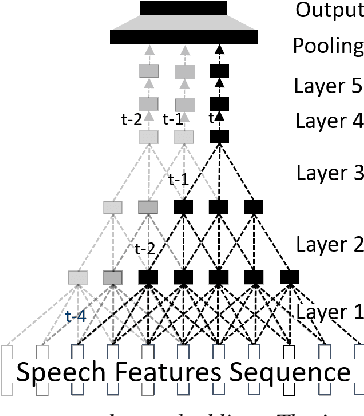
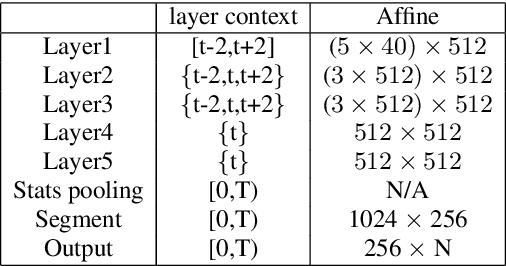

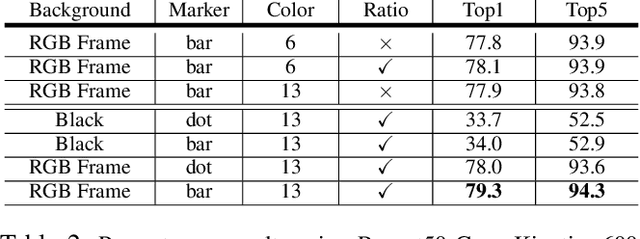
Deep neural networks (DNN) have recently been widely used in speaker recognition systems, achieving state-of-the-art performance on various benchmarks. The x-vector architecture is especially popular in this research community, due to its excellent performance and manageable computational complexity. In this paper, we present the lrx-vector system, which is the low-rank factorized version of the x-vector embedding network. The primary objective of this topology is to further reduce the memory requirement of the speaker recognition system. We discuss the deployment of knowledge distillation for training the lrx-vector system and compare against low-rank factorization with SVD. On the VOiCES 2019 far-field corpus we were able to reduce the weights by 28% compared to the full-rank x-vector system while keeping the recognition rate constant (1.83% EER).
* Accepted to INTERSPEECH 2020
RetinaTrack: Online Single Stage Joint Detection and Tracking
Mar 30, 2020
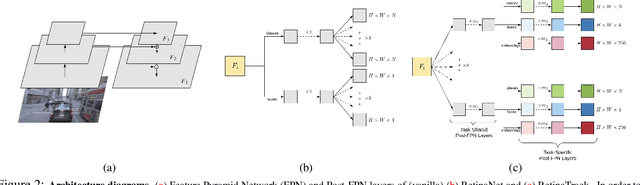
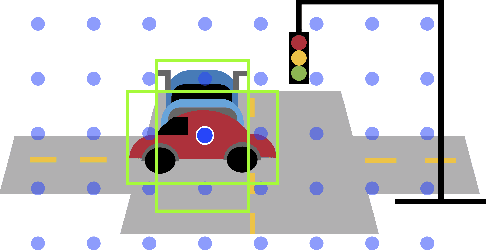
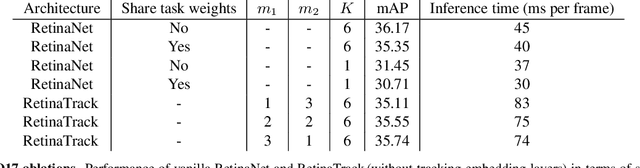
Traditionally multi-object tracking and object detection are performed using separate systems with most prior works focusing exclusively on one of these aspects over the other. Tracking systems clearly benefit from having access to accurate detections, however and there is ample evidence in literature that detectors can benefit from tracking which, for example, can help to smooth predictions over time. In this paper we focus on the tracking-by-detection paradigm for autonomous driving where both tasks are mission critical. We propose a conceptually simple and efficient joint model of detection and tracking, called RetinaTrack, which modifies the popular single stage RetinaNet approach such that it is amenable to instance-level embedding training. We show, via evaluations on the Waymo Open Dataset, that we outperform a recent state of the art tracking algorithm while requiring significantly less computation. We believe that our simple yet effective approach can serve as a strong baseline for future work in this area.
Exploring Context, Attention and Audio Features for Audio Visual Scene-Aware Dialog
Dec 20, 2019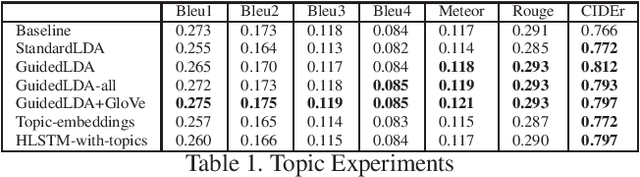
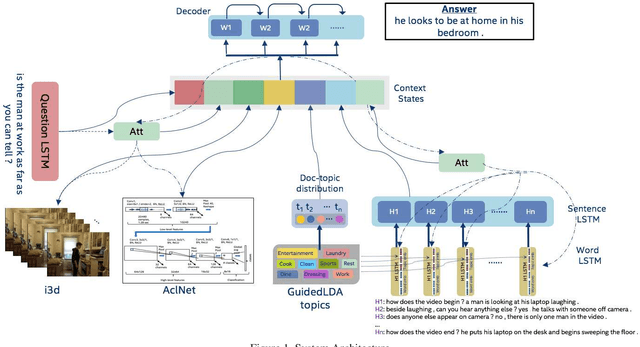
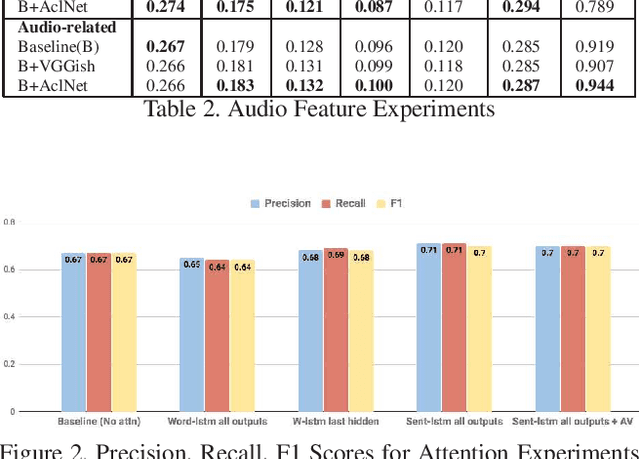
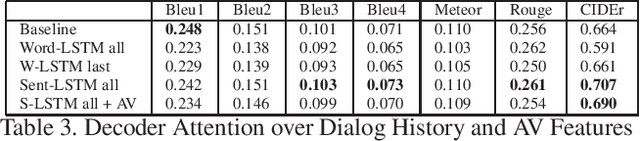
We are witnessing a confluence of vision, speech and dialog system technologies that are enabling the IVAs to learn audio-visual groundings of utterances and have conversations with users about the objects, activities and events surrounding them. Recent progress in visual grounding techniques and Audio Understanding are enabling machines to understand shared semantic concepts and listen to the various sensory events in the environment. With audio and visual grounding methods, end-to-end multimodal SDS are trained to meaningfully communicate with us in natural language about the real dynamic audio-visual sensory world around us. In this work, we explore the role of `topics' as the context of the conversation along with multimodal attention into such an end-to-end audio-visual scene-aware dialog system architecture. We also incorporate an end-to-end audio classification ConvNet, AclNet, into our models. We develop and test our approaches on the Audio Visual Scene-Aware Dialog (AVSD) dataset released as a part of the DSTC7. We present the analysis of our experiments and show that some of our model variations outperform the baseline system released for AVSD.
Leveraging Topics and Audio Features with Multimodal Attention for Audio Visual Scene-Aware Dialog
Dec 20, 2019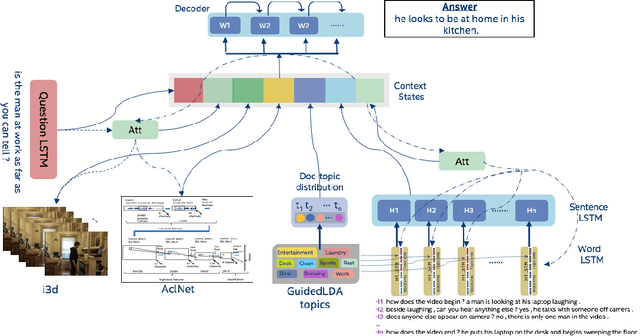

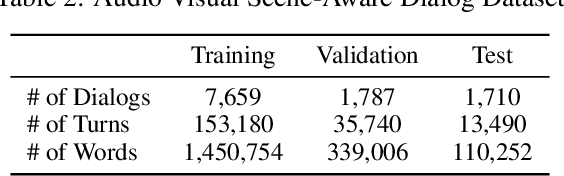
With the recent advancements in Artificial Intelligence (AI), Intelligent Virtual Assistants (IVA) such as Alexa, Google Home, etc., have become a ubiquitous part of many homes. Currently, such IVAs are mostly audio-based, but going forward, we are witnessing a confluence of vision, speech and dialog system technologies that are enabling the IVAs to learn audio-visual groundings of utterances. This will enable agents to have conversations with users about the objects, activities and events surrounding them. In this work, we present three main architectural explorations for the Audio Visual Scene-Aware Dialog (AVSD): 1) investigating `topics' of the dialog as an important contextual feature for the conversation, 2) exploring several multimodal attention mechanisms during response generation, 3) incorporating an end-to-end audio classification ConvNet, AclNet, into our architecture. We discuss detailed analysis of the experimental results and show that our model variations outperform the baseline system presented for the AVSD task.
Long Term Temporal Context for Per-Camera Object Detection
Dec 07, 2019
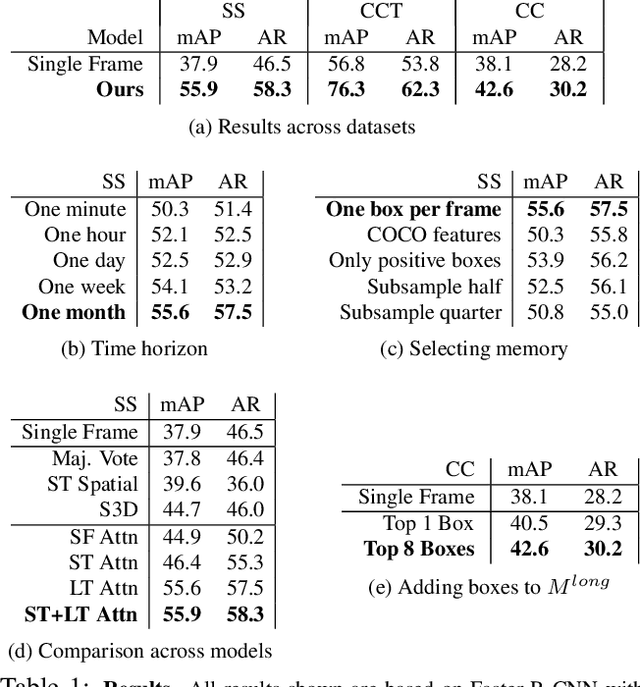

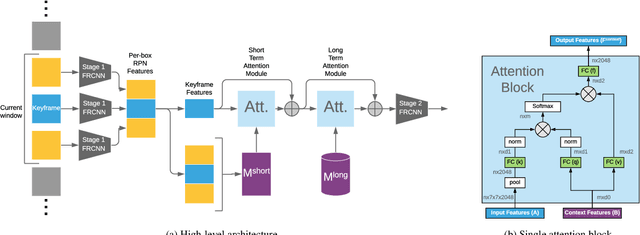
In static monitoring cameras, useful contextual information can stretch far beyond the few seconds typical video understanding models might see: subjects may exhibit similar behavior over multiple days, and background objects remain static. However, due to power and storage constraints, sampling frequencies are low, often no faster than one frame per second, and sometimes are irregular due to the use of a motion trigger. In order to perform well in this setting, models must be robust to irregular sampling rates. In this paper we propose an attention-based approach that allows our model to index into a long term memory bank constructed on a per-camera basis and aggregate contextual features from other frames to boost object detection performance on the current frame. We apply our models to two settings: (1) species detection using camera trap data, which is sampled at a low, variable frame rate based on a motion trigger and used to study biodiversity, and (2) vehicle detection in traffic cameras, which have similarly low frame rate. We show that our model leads to performance gains over strong baselines in all settings. Moreover, we show that increasing the time horizon for our memory bank leads to improved results. When applied to camera trap data from the Snapshot Serengeti dataset, our best model which leverages context from up to a month of images outperforms the single-frame baseline by 17.9% mAP at 0.5 IOU, and outperforms S3D (a 3d convolution based baseline) by 11.2% mAP.
Structural sparsification for Far-field Speaker Recognition with GNA
Oct 25, 2019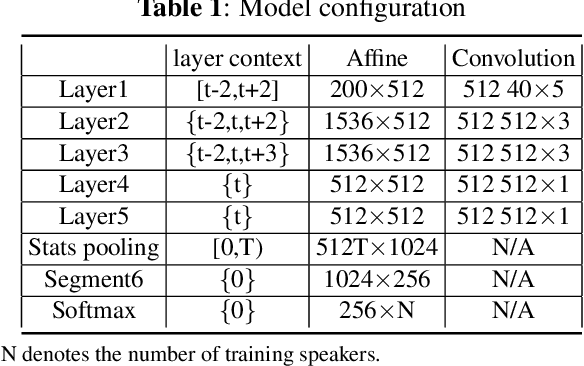
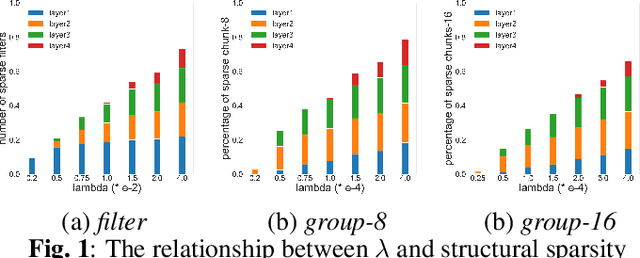
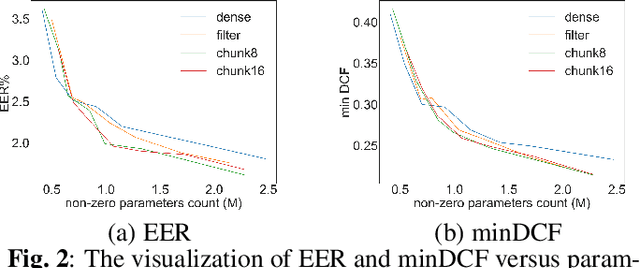
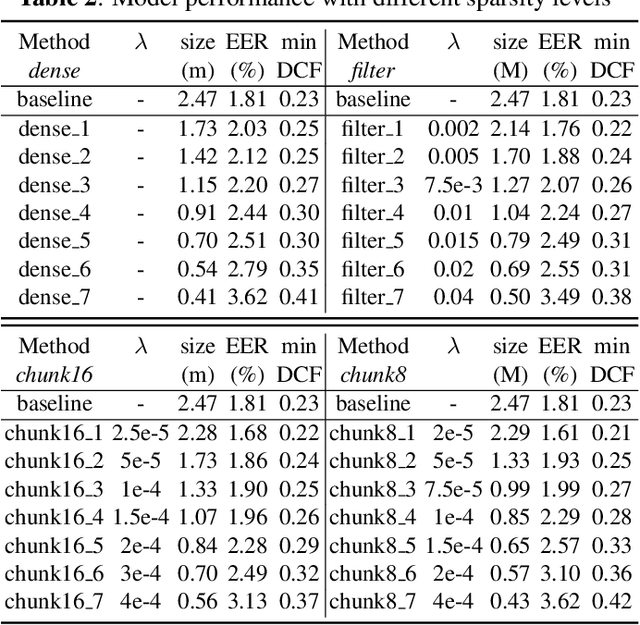
Recently, deep neural networks (DNN) have been widely used in speaker recognition area. In order to achieve fast response time and high accuracy, the requirements for hardware resources increase rapidly. However, as the speaker recognition application is often implemented on mobile devices, it is necessary to maintain a low computational cost while keeping high accuracy in far-field condition. In this paper, we apply structural sparsification on time-delay neural networks (TDNN) to remove redundant structures and accelerate the execution. On our targeted hardware, our model can remove 60% of parameters and only slightly increasing equal error rate (EER) by 0.18% while our structural sparse model can achieve more than 2x speedup.