 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalization Improves Privacy-Accuracy Tradeoffs in Federated Optimization
Feb 10, 2022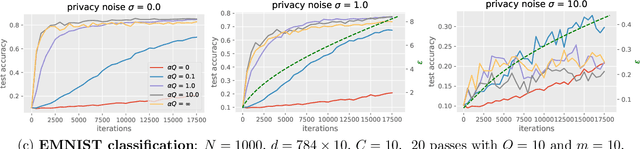
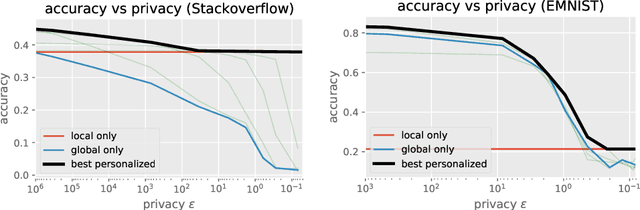
Large-scale machine learning systems often involve data distributed across a collection of users. Federated optimization algorithms leverage this structure by communicating model updates to a central server, rather than entire datasets. In this paper, we study stochastic optimization algorithms for a personalized federated learning setting involving local and global models subject to user-level (joint) differential privacy. While learning a private global model induces a cost of privacy, local learning is perfectly private. We show that coordinating local learning with private centralized learning yields a generically useful and improved tradeoff between accuracy and privacy. We illustrate our theoretical results with experiments on synthetic and real-world datasets.
Provable RL with Exogenous Distractors via Multistep Inverse Dynamics
Oct 17, 2021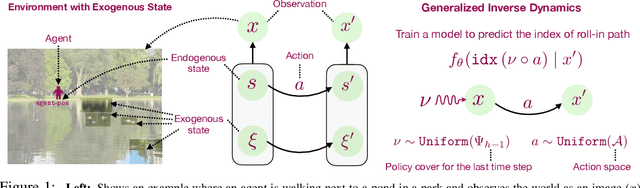

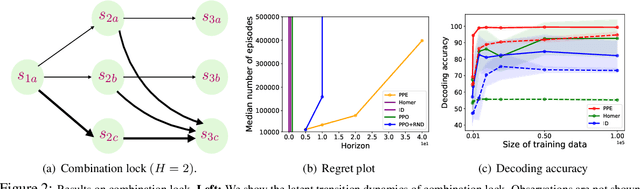
Many real-world applications of reinforcement learning (RL) require the agent to deal with high-dimensional observations such as those generated from a megapixel camera. Prior work has addressed such problems with representation learning, through which the agent can provably extract endogenous, latent state information from raw observations and subsequently plan efficiently. However, such approaches can fail in the presence of temporally correlated noise in the observations, a phenomenon that is common in practice. We initiate the formal study of latent state discovery in the presence of such exogenous noise sources by proposing a new model, the Exogenous Block MDP (EX-BMDP), for rich observation RL. We start by establishing several negative results, by highlighting failure cases of prior representation learning based approaches. Then, we introduce the Predictive Path Elimination (PPE) algorithm, that learns a generalization of inverse dynamics and is provably sample and computationally efficient in EX-BMDPs when the endogenous state dynamics are near deterministic. The sample complexity of PPE depends polynomially on the size of the latent endogenous state space while not directly depending on the size of the observation space, nor the exogenous state space. We provide experiments on challenging exploration problems which show that our approach works empirically.
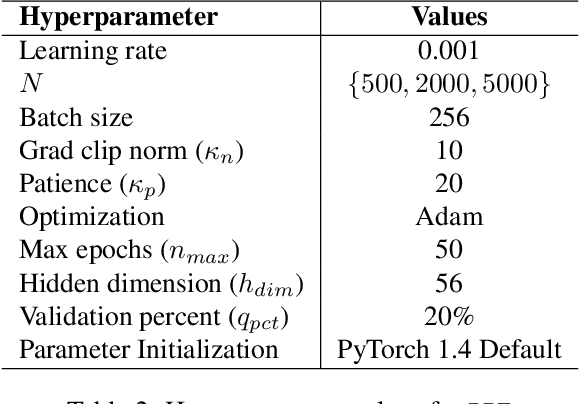
ChaCha for Online AutoML
Jun 11, 2021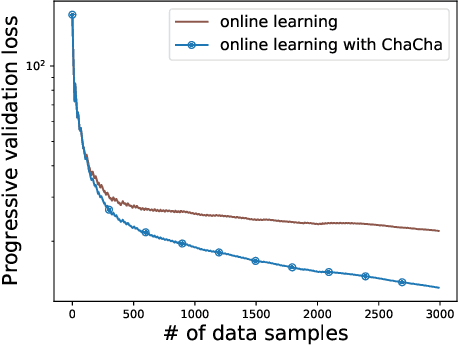
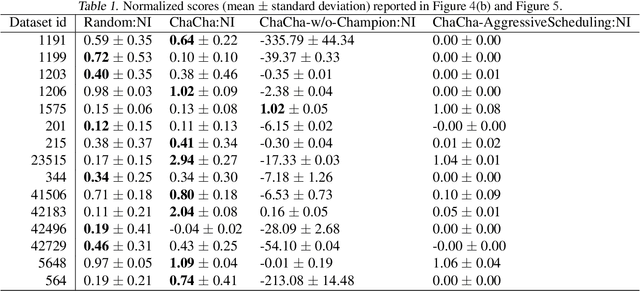
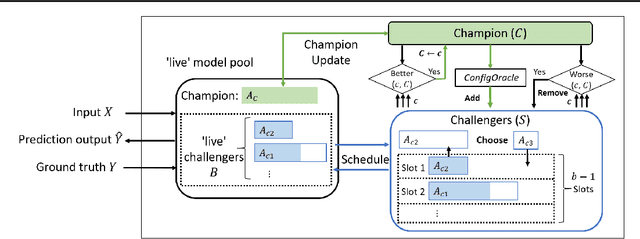
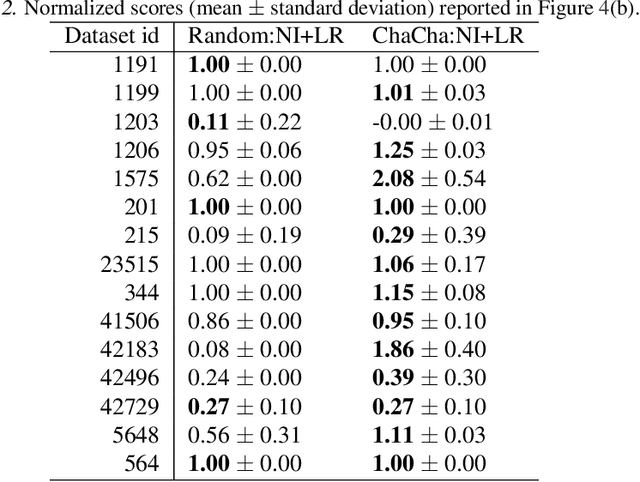
We propose the ChaCha (Champion-Challengers) algorithm for making an online choice of hyperparameters in online learning settings. ChaCha handles the process of determining a champion and scheduling a set of `live' challengers over time based on sample complexity bounds. It is guaranteed to have sublinear regret after the optimal configuration is added into consideration by an application-dependent oracle based on the champions. Empirically, we show that ChaCha provides good performance across a wide array of datasets when optimizing over featurization and hyperparameter decisions.
* 16 pages (including supplementary appendix). Appearing at ICML 2021
Interaction-Grounded Learning
Jun 09, 2021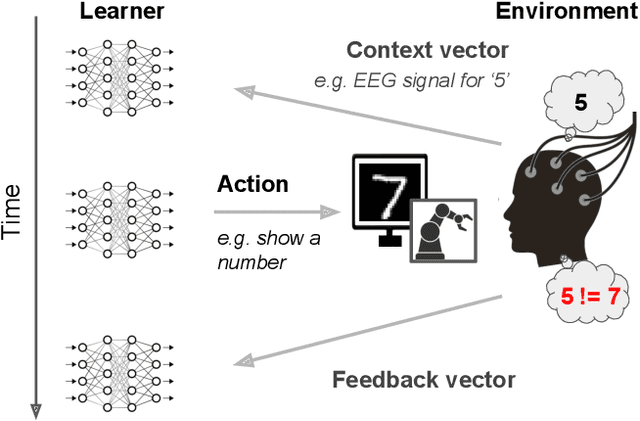
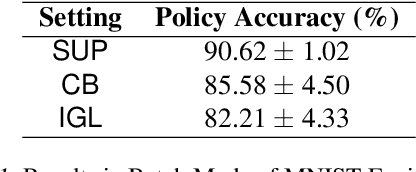

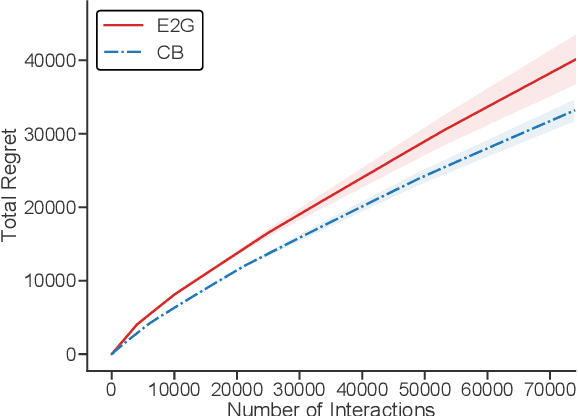
Consider a prosthetic arm, learning to adapt to its user's control signals. We propose Interaction-Grounded Learning for this novel setting, in which a learner's goal is to interact with the environment with no grounding or explicit reward to optimize its policies. Such a problem evades common RL solutions which require an explicit reward. The learning agent observes a multidimensional context vector, takes an action, and then observes a multidimensional feedback vector. This multidimensional feedback vector has no explicit reward information. In order to succeed, the algorithm must learn how to evaluate the feedback vector to discover a latent reward signal, with which it can ground its policies without supervision. We show that in an Interaction-Grounded Learning setting, with certain natural assumptions, a learner can discover the latent reward and ground its policy for successful interaction. We provide theoretical guarantees and a proof-of-concept empirical evaluation to demonstrate the effectiveness of our proposed approach.
Resonance: Replacing Software Constants with Context-Aware Models in Real-time Communication
Nov 23, 2020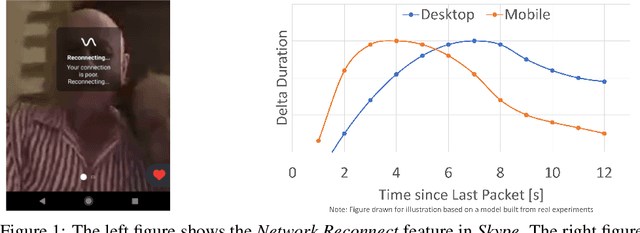


Large software systems tune hundreds of 'constants' to optimize their runtime performance. These values are commonly derived through intuition, lab tests, or A/B tests. A 'one-size-fits-all' approach is often sub-optimal as the best value depends on runtime context. In this paper, we provide an experimental approach to replace constants with learned contextual functions for Skype - a widely used real-time communication (RTC) application. We present Resonance, a system based on contextual bandits (CB). We describe experiences from three real-world experiments: applying it to the audio, video, and transport components in Skype. We surface a unique and practical challenge of performing machine learning (ML) inference in large software systems written using encapsulation principles. Finally, we open-source FeatureBroker, a library to reduce the friction in adopting ML models in such development environments
Learning the Linear Quadratic Regulator from Nonlinear Observations
Oct 08, 2020
We introduce a new problem setting for continuous control called the LQR with Rich Observations, or RichLQR. In our setting, the environment is summarized by a low-dimensional continuous latent state with linear dynamics and quadratic costs, but the agent operates on high-dimensional, nonlinear observations such as images from a camera. To enable sample-efficient learning, we assume that the learner has access to a class of decoder functions (e.g., neural networks) that is flexible enough to capture the mapping from observations to latent states. We introduce a new algorithm, RichID, which learns a near-optimal policy for the RichLQR with sample complexity scaling only with the dimension of the latent state space and the capacity of the decoder function class. RichID is oracle-efficient and accesses the decoder class only through calls to a least-squares regression oracle. Our results constitute the first provable sample complexity guarantee for continuous control with an unknown nonlinearity in the system model and general function approximation.
Better Parameter-free Stochastic Optimization with ODE Updates for Coin-Betting
Jun 12, 2020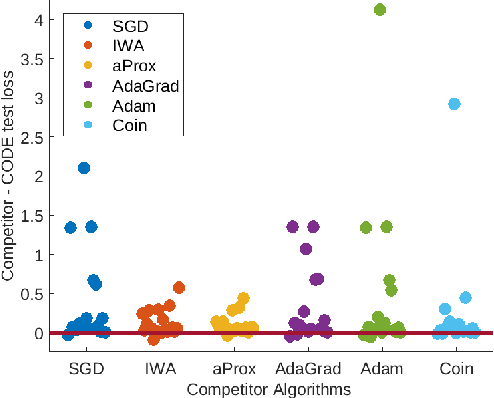
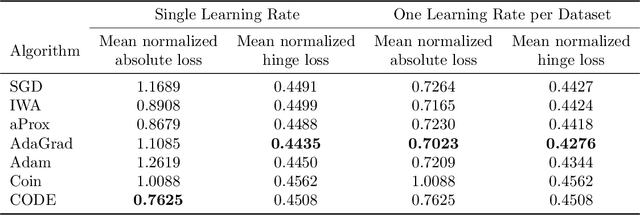
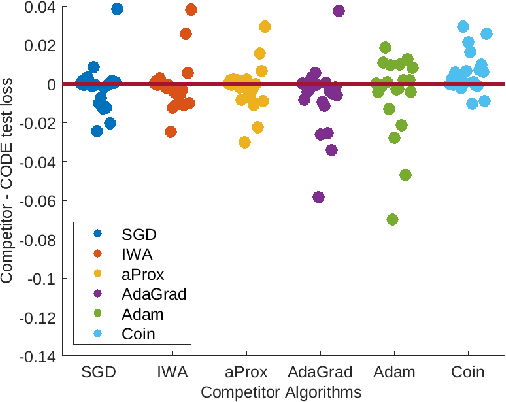
Parameter-free stochastic gradient descent (PFSGD) algorithms do not require setting learning rates while achieving optimal theoretical performance. In practical applications, however, there remains an empirical gap between tuned stochastic gradient descent (SGD) and PFSGD. In this paper, we close the empirical gap with a new parameter-free algorithm based on continuous-time Coin-Betting on truncated models. The new update is derived through the solution of an Ordinary Differential Equation (ODE) and solved in a closed form. We show empirically that this new parameter-free algorithm outperforms algorithms with the "best default" learning rates and almost matches the performance of finely tuned baselines without anything to tune.
Efficient Contextual Bandits with Continuous Actions
Jun 10, 2020
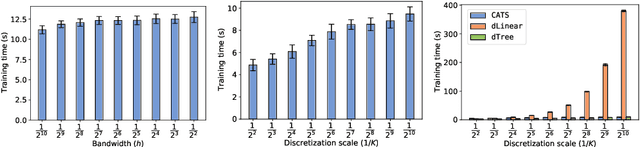
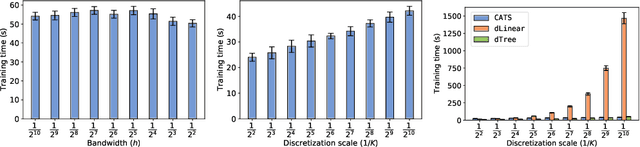
We create a computationally tractable algorithm for contextual bandits with continuous actions having unknown structure. Our reduction-style algorithm composes with most supervised learning representations. We prove that it works in a general sense and verify the new functionality with large-scale experiments.
Federated Residual Learning
Mar 28, 2020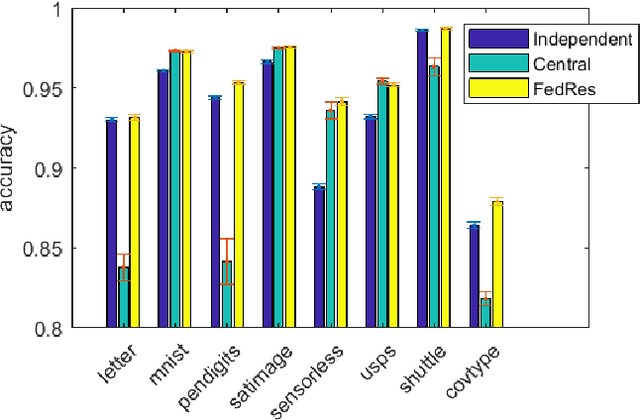
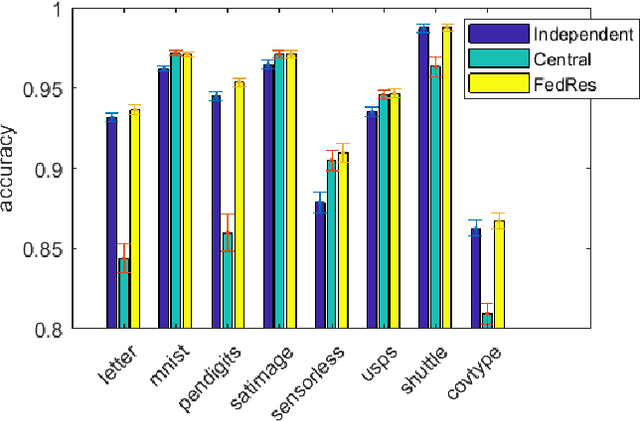
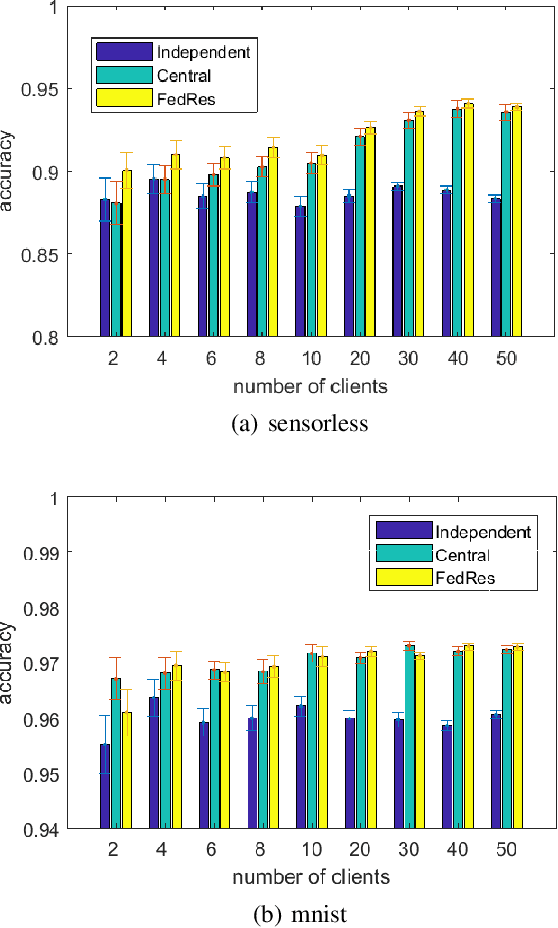
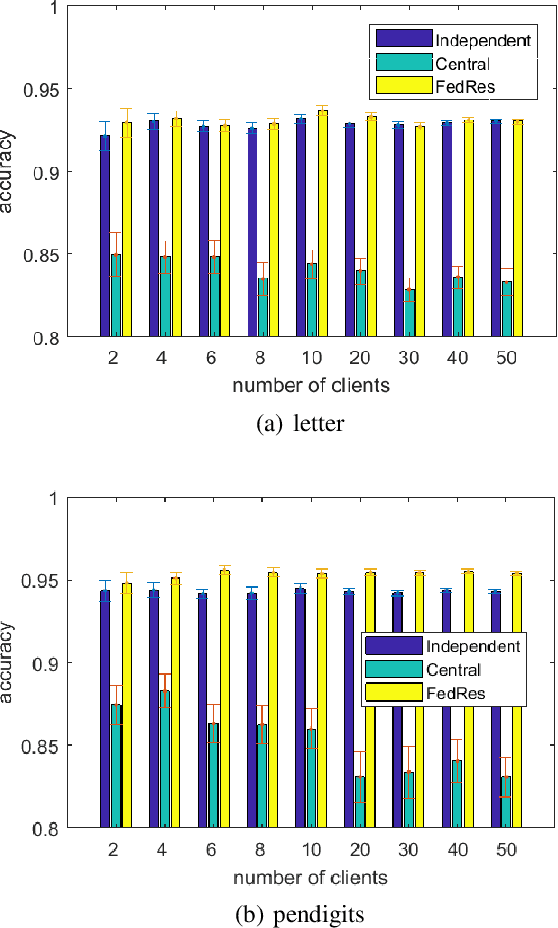
We study a new form of federated learning where the clients train personalized local models and make predictions jointly with the server-side shared model. Using this new federated learning framework, the complexity of the central shared model can be minimized while still gaining all the performance benefits that joint training provides. Our framework is robust to data heterogeneity, addressing the slow convergence problem traditional federated learning methods face when the data is non-i.i.d. across clients. We test the theory empirically and find substantial performance gains over baselines.
Kinematic State Abstraction and Provably Efficient Rich-Observation Reinforcement Learning
Nov 13, 2019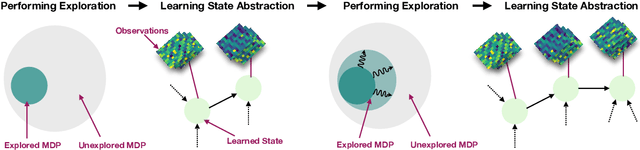

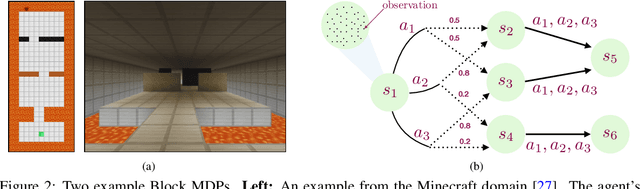

We present an algorithm, HOMER, for exploration and reinforcement learning in rich observation environments that are summarizable by an unknown latent state space. The algorithm interleaves representation learning to identify a new notion of kinematic state abstraction with strategic exploration to reach new states using the learned abstraction. The algorithm provably explores the environment with sample complexity scaling polynomially in the number of latent states and the time horizon, and, crucially, with no dependence on the size of the observation space, which could be infinitely large. This exploration guarantee further enables sample-efficient global policy optimization for any reward function. On the computational side, we show that the algorithm can be implemented efficiently whenever certain supervised learning problems are tractable. Empirically, we evaluate HOMER on a challenging exploration problem, where we show that the algorithm is exponentially more sample efficient than standard reinforcement learning baselines.