 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopology-Agnostic Animal Motion Generation from Text Prompt
Dec 11, 2025Motion generation is fundamental to computer animation and widely used across entertainment, robotics, and virtual environments. While recent methods achieve impressive results, most rely on fixed skeletal templates, which prevent them from generalizing to skeletons with different or perturbed topologies. We address the core limitation of current motion generation methods - the combined lack of large-scale heterogeneous animal motion data and unified generative frameworks capable of jointly modeling arbitrary skeletal topologies and textual conditions. To this end, we introduce OmniZoo, a large-scale animal motion dataset spanning 140 species and 32,979 sequences, enriched with multimodal annotations. Building on OmniZoo, we propose a generalized autoregressive motion generation framework capable of producing text-driven motions for arbitrary skeletal topologies. Central to our model is a Topology-aware Skeleton Embedding Module that encodes geometric and structural properties of any skeleton into a shared token space, enabling seamless fusion with textual semantics. Given a text prompt and a target skeleton, our method generates temporally coherent, physically plausible, and semantically aligned motions, and further enables cross-species motion style transfer.
ARMO: Autoregressive Rigging for Multi-Category Objects
Mar 26, 2025Recent advancements in large-scale generative models have significantly improved the quality and diversity of 3D shape generation. However, most existing methods focus primarily on generating static 3D models, overlooking the potentially dynamic nature of certain shapes, such as humanoids, animals, and insects. To address this gap, we focus on rigging, a fundamental task in animation that establishes skeletal structures and skinning for 3D models. In this paper, we introduce OmniRig, the first large-scale rigging dataset, comprising 79,499 meshes with detailed skeleton and skinning information. Unlike traditional benchmarks that rely on predefined standard poses (e.g., A-pose, T-pose), our dataset embraces diverse shape categories, styles, and poses. Leveraging this rich dataset, we propose ARMO, a novel rigging framework that utilizes an autoregressive model to predict both joint positions and connectivity relationships in a unified manner. By treating the skeletal structure as a complete graph and discretizing it into tokens, we encode the joints using an auto-encoder to obtain a latent embedding and an autoregressive model to predict the tokens. A mesh-conditioned latent diffusion model is used to predict the latent embedding for conditional skeleton generation. Our method addresses the limitations of regression-based approaches, which often suffer from error accumulation and suboptimal connectivity estimation. Through extensive experiments on the OmniRig dataset, our approach achieves state-of-the-art performance in skeleton prediction, demonstrating improved generalization across diverse object categories. The code and dataset will be made public for academic use upon acceptance.
Implicit Interpretation of Importance Weight Aware Updates
Jul 22, 2023Due to its speed and simplicity, subgradient descent is one of the most used optimization algorithms in convex machine learning algorithms. However, tuning its learning rate is probably its most severe bottleneck to achieve consistent good performance. A common way to reduce the dependency on the learning rate is to use implicit/proximal updates. One such variant is the Importance Weight Aware (IWA) updates, which consist of infinitely many infinitesimal updates on each loss function. However, IWA updates' empirical success is not completely explained by their theory. In this paper, we show for the first time that IWA updates have a strictly better regret upper bound than plain gradient updates in the online learning setting. Our analysis is based on the new framework, generalized implicit Follow-the-Regularized-Leader (FTRL) (Chen and Orabona, 2023), to analyze generalized implicit updates using a dual formulation. In particular, our results imply that IWA updates can be considered as approximate implicit/proximal updates.
Generalized Implicit Follow-The-Regularized-Leader
May 31, 2023We propose a new class of online learning algorithms, generalized implicit Follow-The-Regularized-Leader (FTRL), that expands the scope of FTRL framework. Generalized implicit FTRL can recover known algorithms, as FTRL with linearized losses and implicit FTRL, and it allows the design of new update rules, as extensions of aProx and Mirror-Prox to FTRL. Our theory is constructive in the sense that it provides a simple unifying framework to design updates that directly improve the worst-case upper bound on the regret. The key idea is substituting the linearization of the losses with a Fenchel-Young inequality. We show the flexibility of the framework by proving that some known algorithms, like the Mirror-Prox updates, are instantiations of the generalized implicit FTRL. Finally, the new framework allows us to recover the temporal variation bound of implicit OMD, with the same computational complexity.
Implicit Parameter-free Online Learning with Truncated Linear Models
Mar 19, 2022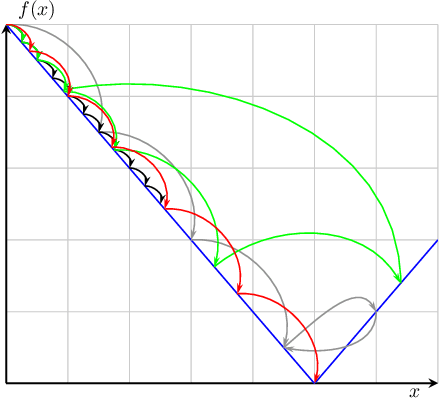
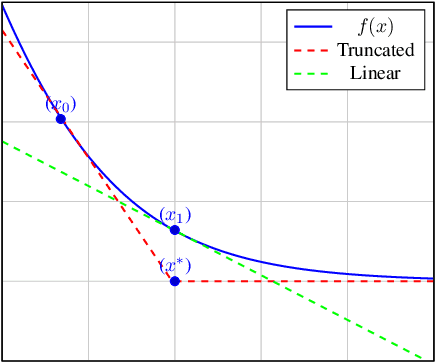
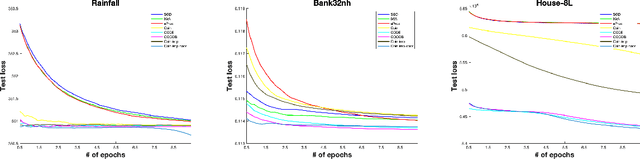
Parameter-free algorithms are online learning algorithms that do not require setting learning rates. They achieve optimal regret with respect to the distance between the initial point and any competitor. Yet, parameter-free algorithms do not take into account the geometry of the losses. Recently, in the stochastic optimization literature, it has been proposed to instead use truncated linear lower bounds, which produce better performance by more closely modeling the losses. In particular, truncated linear models greatly reduce the problem of overshooting the minimum of the loss function. Unfortunately, truncated linear models cannot be used with parameter-free algorithms because the updates become very expensive to compute. In this paper, we propose new parameter-free algorithms that can take advantage of truncated linear models through a new update that has an "implicit" flavor. Based on a novel decomposition of the regret, the new update is efficient, requires only one gradient at each step, never overshoots the minimum of the truncated model, and retains the favorable parameter-free properties. We also conduct an empirical study demonstrating the practical utility of our algorithms.
Better Parameter-free Stochastic Optimization with ODE Updates for Coin-Betting
Jun 12, 2020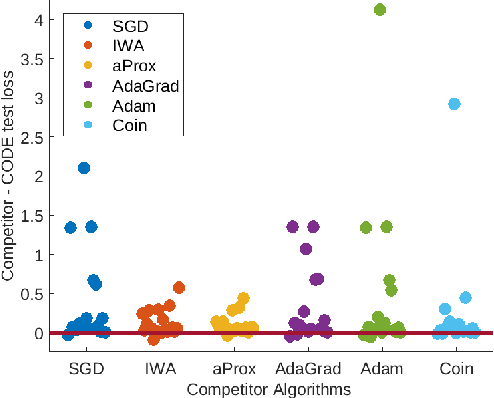
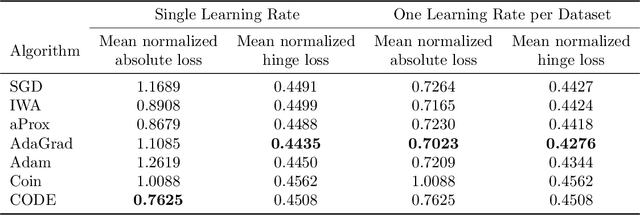
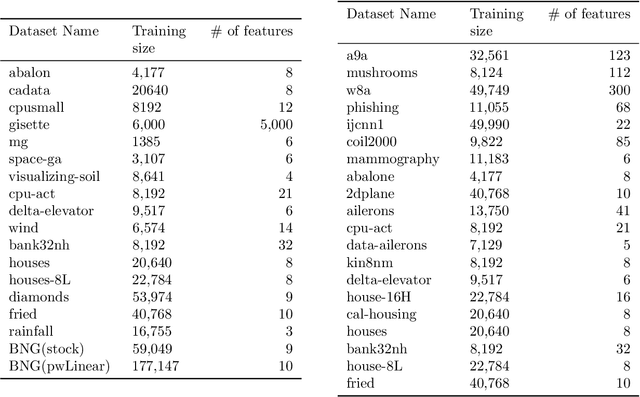
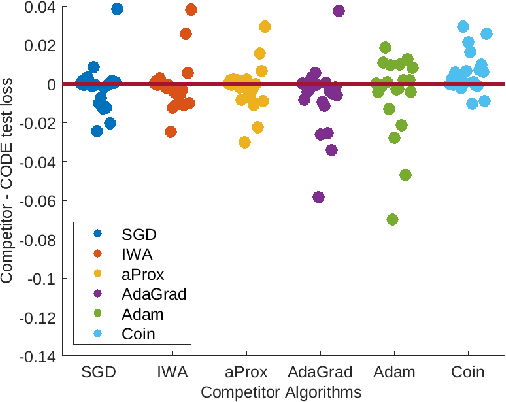
Parameter-free stochastic gradient descent (PFSGD) algorithms do not require setting learning rates while achieving optimal theoretical performance. In practical applications, however, there remains an empirical gap between tuned stochastic gradient descent (SGD) and PFSGD. In this paper, we close the empirical gap with a new parameter-free algorithm based on continuous-time Coin-Betting on truncated models. The new update is derived through the solution of an Ordinary Differential Equation (ODE) and solved in a closed form. We show empirically that this new parameter-free algorithm outperforms algorithms with the "best default" learning rates and almost matches the performance of finely tuned baselines without anything to tune.