 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning is Fine in Federated Learning
Aug 16, 2021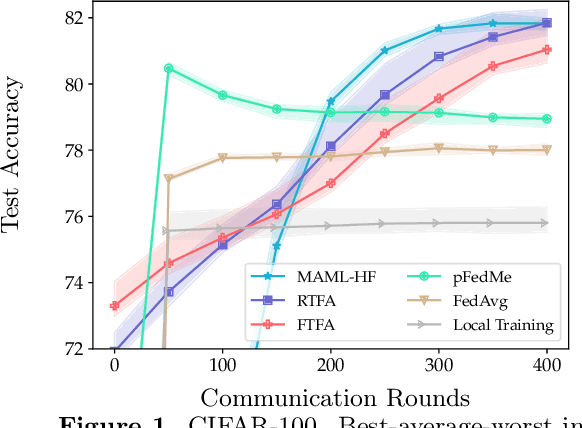

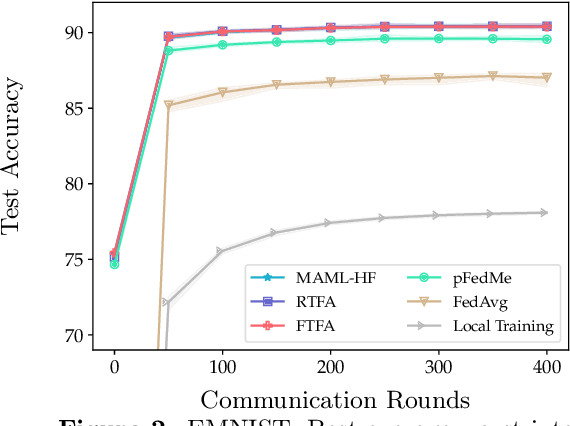
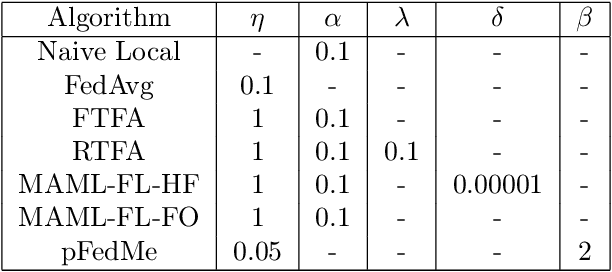
We study the performance of federated learning algorithms and their variants in an asymptotic framework. Our starting point is the formulation of federated learning as a multi-criterion objective, where the goal is to minimize each client's loss using information from all of the clients. We propose a linear regression model, where, for a given client, we theoretically compare the performance of various algorithms in the high-dimensional asymptotic limit. This asymptotic multi-criterion approach naturally models the high-dimensional, many-device nature of federated learning and suggests that personalization is central to federated learning. Our theory suggests that Fine-tuned Federated Averaging (FTFA), i.e., Federated Averaging followed by local training, and the ridge regularized variant Ridge-tuned Federated Averaging (RTFA) are competitive with more sophisticated meta-learning and proximal-regularized approaches. In addition to being conceptually simpler, FTFA and RTFA are computationally more efficient than its competitors. We corroborate our theoretical claims with extensive experiments on federated versions of the EMNIST, CIFAR-100, Shakespeare, and Stack Overflow datasets.
Adapting to Function Difficulty and Growth Conditions in Private Optimization
Aug 05, 2021We develop algorithms for private stochastic convex optimization that adapt to the hardness of the specific function we wish to optimize. While previous work provide worst-case bounds for arbitrary convex functions, it is often the case that the function at hand belongs to a smaller class that enjoys faster rates. Concretely, we show that for functions exhibiting $\kappa$-growth around the optimum, i.e., $f(x) \ge f(x^*) + \lambda \kappa^{-1} \|x-x^*\|_2^\kappa$ for $\kappa > 1$, our algorithms improve upon the standard ${\sqrt{d}}/{n\varepsilon}$ privacy rate to the faster $({\sqrt{d}}/{n\varepsilon})^{\tfrac{\kappa}{\kappa - 1}}$. Crucially, they achieve these rates without knowledge of the growth constant $\kappa$ of the function. Our algorithms build upon the inverse sensitivity mechanism, which adapts to instance difficulty (Asi & Duchi, 2020), and recent localization techniques in private optimization (Feldman et al., 2020). We complement our algorithms with matching lower bounds for these function classes and demonstrate that our adaptive algorithm is \emph{simultaneously} (minimax) optimal over all $\kappa \ge 1+c$ whenever $c = \Theta(1)$.
Private Adaptive Gradient Methods for Convex Optimization
Jun 25, 2021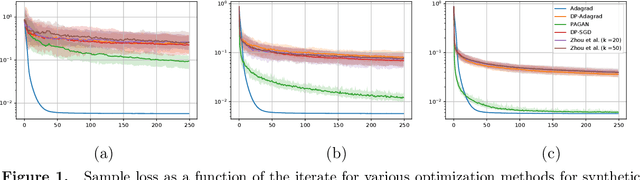

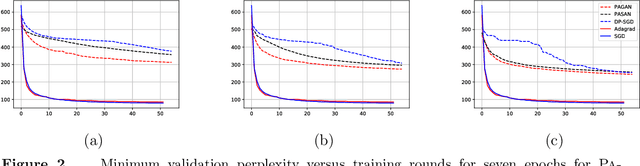
We study adaptive methods for differentially private convex optimization, proposing and analyzing differentially private variants of a Stochastic Gradient Descent (SGD) algorithm with adaptive stepsizes, as well as the AdaGrad algorithm. We provide upper bounds on the regret of both algorithms and show that the bounds are (worst-case) optimal. As a consequence of our development, we show that our private versions of AdaGrad outperform adaptive SGD, which in turn outperforms traditional SGD in scenarios with non-isotropic gradients where (non-private) Adagrad provably outperforms SGD. The major challenge is that the isotropic noise typically added for privacy dominates the signal in gradient geometry for high-dimensional problems; approaches to this that effectively optimize over lower-dimensional subspaces simply ignore the actual problems that varying gradient geometries introduce. In contrast, we study non-isotropic clipping and noise addition, developing a principled theoretical approach; the consequent procedures also enjoy significantly stronger empirical performance than prior approaches.
On Misspecification in Prediction Problems and Robustness via Improper Learning
Jan 29, 2021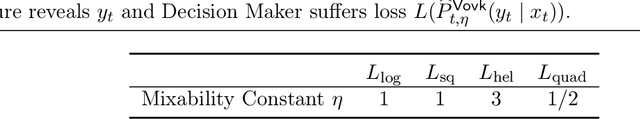
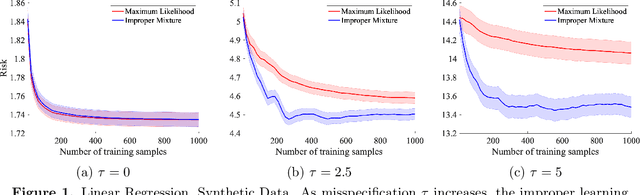
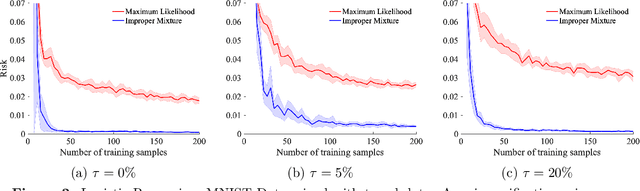
We study probabilistic prediction games when the underlying model is misspecified, investigating the consequences of predicting using an incorrect parametric model. We show that for a broad class of loss functions and parametric families of distributions, the regret of playing a "proper" predictor -- one from the putative model class -- relative to the best predictor in the same model class has lower bound scaling at least as $\sqrt{\gamma n}$, where $\gamma$ is a measure of the model misspecification to the true distribution in terms of total variation distance. In contrast, using an aggregation-based (improper) learner, one can obtain regret $d \log n$ for any underlying generating distribution, where $d$ is the dimension of the parameter; we exhibit instances in which this is unimprovable even over the family of all learners that may play distributions in the convex hull of the parametric family. These results suggest that simple strategies for aggregating multiple learners together should be more robust, and several experiments conform to this hypothesis.
Neural Bridge Sampling for Evaluating Safety-Critical Autonomous Systems
Aug 24, 2020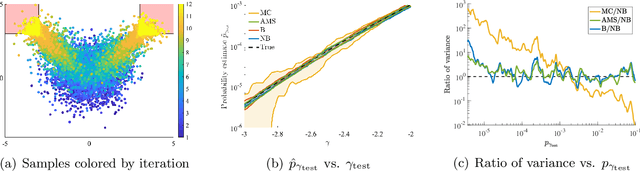
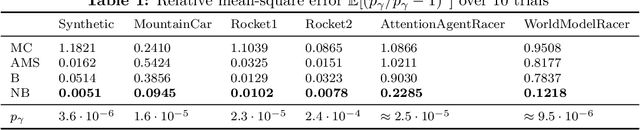
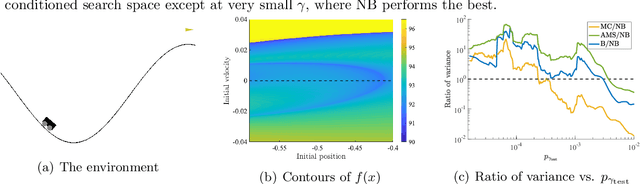
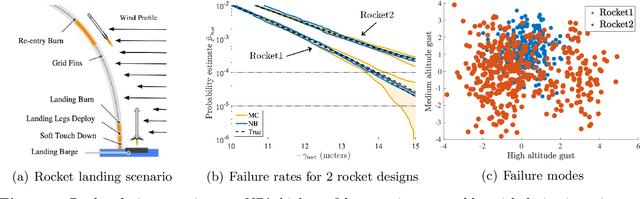
Learning-based methodologies increasingly find applications in safety-critical domains like autonomous driving and medical robotics. Due to the rare nature of dangerous events, real-world testing is prohibitively expensive and unscalable. In this work, we employ a probabilistic approach to safety evaluation in simulation, where we are concerned with computing the probability of dangerous events. We develop a novel rare-event simulation method that combines exploration, exploitation, and optimization techniques to find failure modes and estimate their rate of occurrence. We provide rigorous guarantees for the performance of our method in terms of both statistical and computational efficiency. Finally, we demonstrate the efficacy of our approach on a variety of scenarios, illustrating its usefulness as a tool for rapid sensitivity analysis and model comparison that are essential to developing and testing safety-critical autonomous systems.
Distributionally Robust Losses for Latent Covariate Mixtures
Jul 28, 2020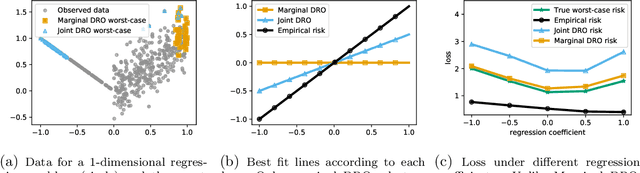
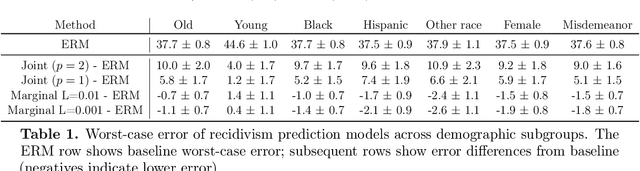
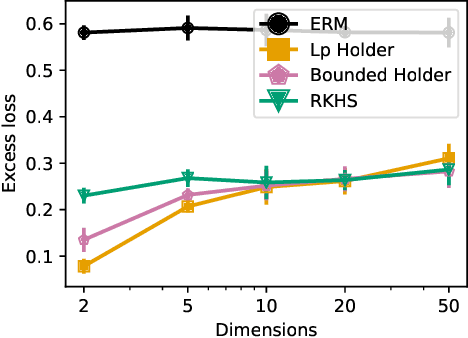
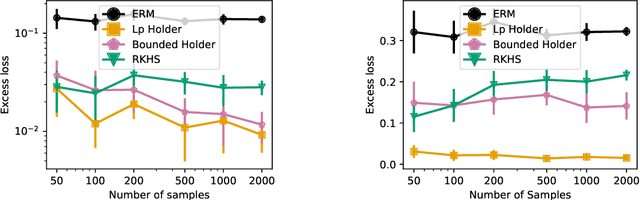
While modern large-scale datasets often consist of heterogeneous subpopulations---for example, multiple demographic groups or multiple text corpora---the standard practice of minimizing average loss fails to guarantee uniformly low losses across all subpopulations. We propose a convex procedure that controls the worst-case performance over all subpopulations of a given size. Our procedure comes with finite-sample (nonparametric) convergence guarantees on the worst-off subpopulation. Empirically, we observe on lexical similarity, wine quality, and recidivism prediction tasks that our worst-case procedure learns models that do well against unseen subpopulations.
Knowing what you know: valid confidence sets in multiclass and multilabel prediction
Apr 24, 2020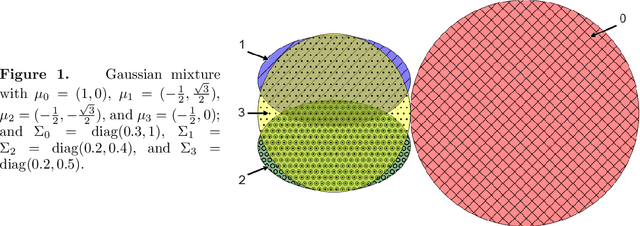
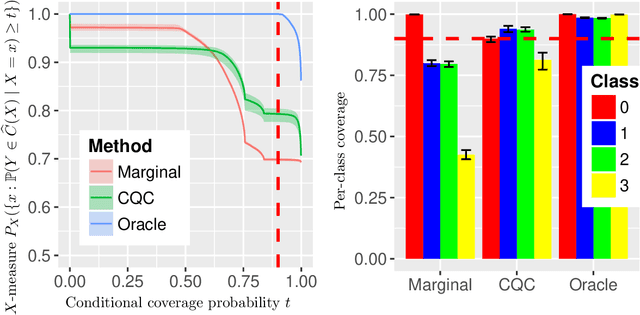
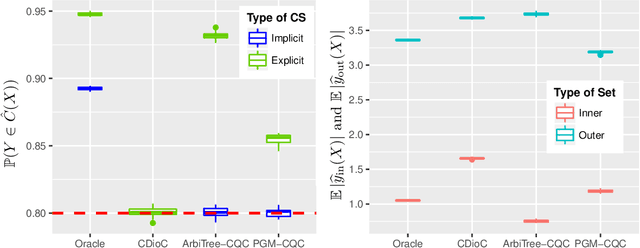
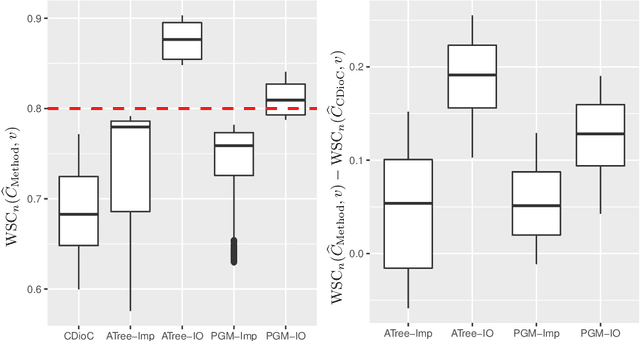
We develop conformal prediction methods for constructing valid predictive confidence sets in multiclass and multilabel problems without assumptions on the data generating distribution. A challenge here is that typical conformal prediction methods---which give marginal validity (coverage) guarantees---provide uneven coverage, in that they address easy examples at the expense of essentially ignoring difficult examples. By leveraging ideas from quantile regression, we build methods that always guarantee correct coverage but additionally provide (asymptotically optimal) conditional coverage for both multiclass and multilabel prediction problems. To address the potential challenge of exponentially large confidence sets in multilabel prediction, we build tree-structured classifiers that efficiently account for interactions between labels. Our methods can be bolted on top of any classification model---neural network, random forest, boosted tree---to guarantee its validity. We also provide an empirical evaluation suggesting the more robust coverage of our confidence sets.
FormulaZero: Distributionally Robust Online Adaptation via Offline Population Synthesis
Mar 09, 2020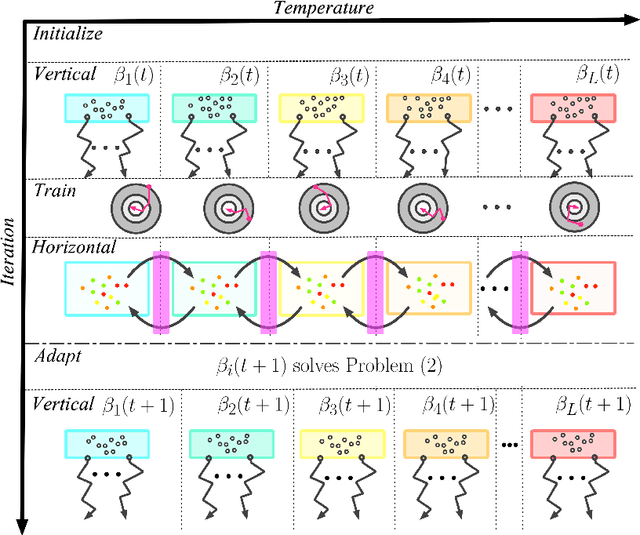
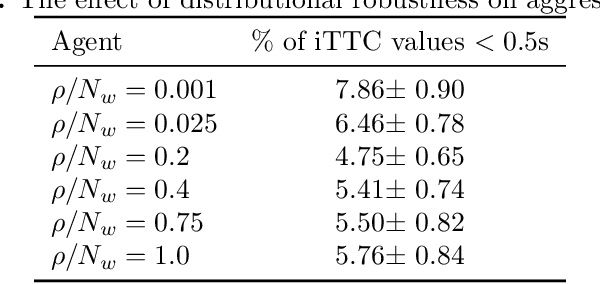

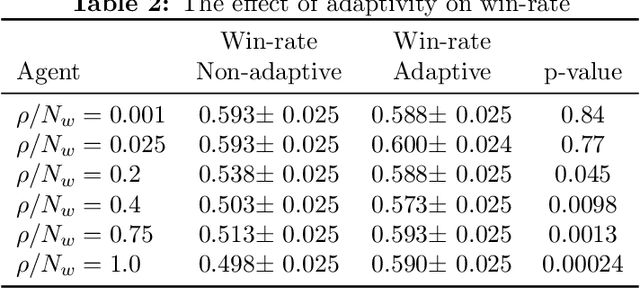
Balancing performance and safety is crucial to deploying autonomous vehicles in multi-agent environments. In particular, autonomous racing is a domain that penalizes safe but conservative policies, highlighting the need for robust, adaptive strategies. Current approaches either make simplifying assumptions about other agents or lack robust mechanisms for online adaptation. This work makes algorithmic contributions to both challenges. First, to generate a realistic, diverse set of opponents, we develop a novel method for self-play based on replica-exchange Markov chain Monte Carlo. Second, we propose a distributionally robust bandit optimization procedure that adaptively adjusts risk aversion relative to uncertainty in beliefs about opponents' behaviors. We rigorously quantify the tradeoffs in performance and robustness when approximating these computations in real-time motion-planning, and we demonstrate our methods experimentally on autonomous vehicles that achieve scaled speeds comparable to Formula One racecars.
Understanding and Mitigating the Tradeoff Between Robustness and Accuracy
Feb 25, 2020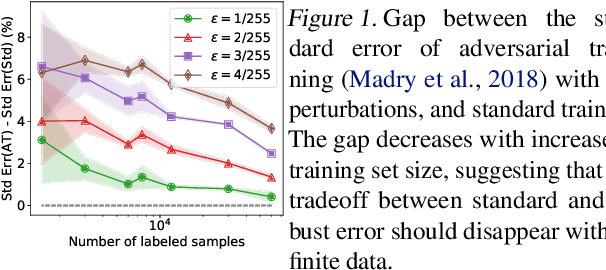
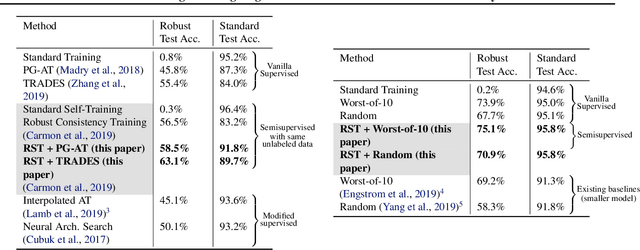
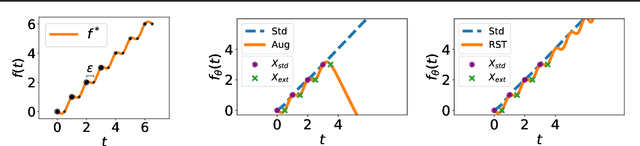

Adversarial training augments the training set with perturbations to improve the robust error (over worst-case perturbations), but it often leads to an increase in the standard error (on unperturbed test inputs). Previous explanations for this tradeoff rely on the assumption that no predictor in the hypothesis class has low standard and robust error. In this work, we precisely characterize the effect of augmentation on the standard error in linear regression when the optimal linear predictor has zero standard and robust error. In particular, we show that the standard error could increase even when the augmented perturbations have noiseless observations from the optimal linear predictor. We then prove that the recently proposed robust self-training (RST) estimator improves robust error without sacrificing standard error for noiseless linear regression. Empirically, for neural networks, we find that RST with different adversarial training methods improves both standard and robust error for random and adversarial rotations and adversarial $\ell_\infty$ perturbations in CIFAR-10.
Element Level Differential Privacy: The Right Granularity of Privacy
Dec 05, 2019
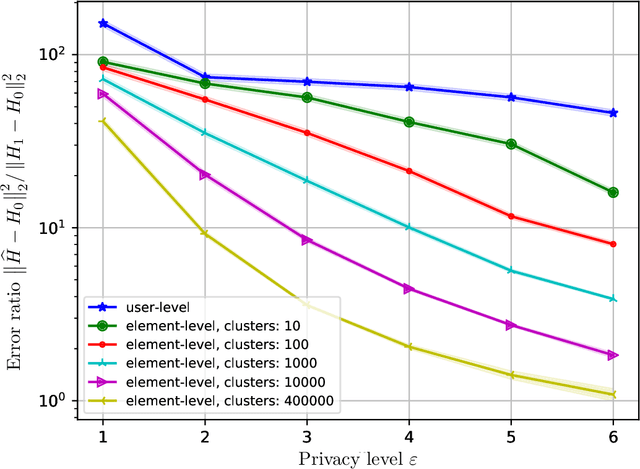
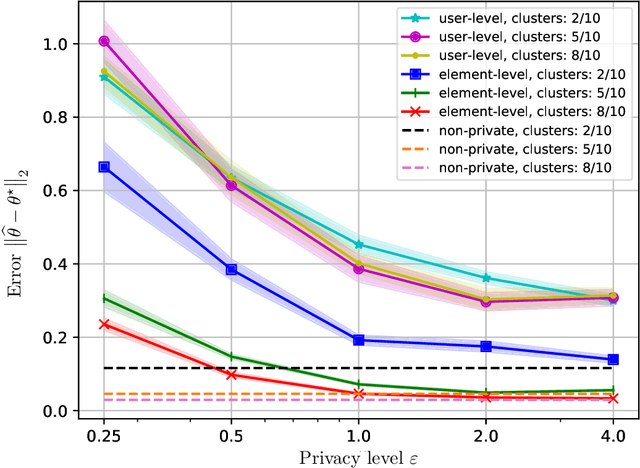
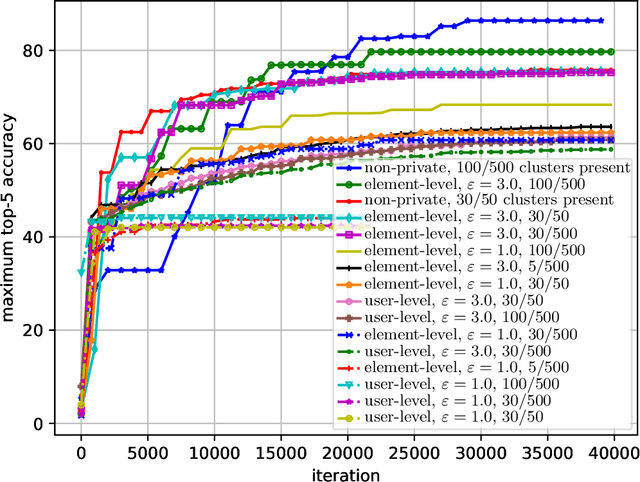
Differential Privacy (DP) provides strong guarantees on the risk of compromising a user's data in statistical learning applications, though these strong protections make learning challenging and may be too stringent for some use cases. To address this, we propose element level differential privacy, which extends differential privacy to provide protection against leaking information about any particular "element" a user has, allowing better utility and more robust results than classical DP. By carefully choosing these "elements," it is possible to provide privacy protections at a desired granularity. We provide definitions, associated privacy guarantees, and analysis to identify the tradeoffs with the new definition; we also develop several private estimation and learning methodologies, providing careful examples for item frequency and M-estimation (empirical risk minimization) with concomitant privacy and utility analysis. We complement our theoretical and methodological advances with several real-world applications, estimating histograms and fitting several large-scale prediction models, including deep networks.