 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Block-Scaled Data Types
Mar 30, 2026NVFP4 has grown increasingly popular as a 4-bit format for quantizing large language models due to its hardware support and its ability to retain useful information with relatively few bits per parameter. However, the format is not without limitations: recent work has shown that NVFP4 suffers from its error distribution, resulting in large amounts of quantization error on near-maximal values in each group of 16 values. In this work, we leverage this insight to design new Adaptive Block-Scaled Data Types that can adapt to the distribution of their input values. For four-bit quantization, our proposed IF4 (Int/Float 4) data type selects between FP4 and INT4 representations for each group of 16 values, which are then scaled by an E4M3 scale factor as is done with NVFP4. The selected data type is denoted using the scale factor's sign bit, which is currently unused in NVFP4, and we apply the same insight to design formats for other bit-widths, including IF3 and IF6. When used to quantize language models, we find that IF4 outperforms existing 4-bit block-scaled formats, achieving lower loss during quantized training and achieving higher accuracy on many tasks in post-training quantization. We additionally design and evaluate an IF4 Multiply-Accumulate (MAC) unit to demonstrate that IF4 can be implemented efficiently in next-generation hardware accelerators. Our code is available at https://github.com/mit-han-lab/fouroversix.
A Comparative Study in Surgical AI: Datasets, Foundation Models, and Barriers to Med-AGI
Mar 28, 2026Recent Artificial Intelligence (AI) models have matched or exceeded human experts in several benchmarks of biomedical task performance, but have lagged behind on surgical image-analysis benchmarks. Since surgery requires integrating disparate tasks -- including multimodal data integration, human interaction, and physical effects -- generally-capable AI models could be particularly attractive as a collaborative tool if performance could be improved. On the one hand, the canonical approach of scaling architecture size and training data is attractive, especially since there are millions of hours of surgical video data generated per year. On the other hand, preparing surgical data for AI training requires significantly higher levels of professional expertise, and training on that data requires expensive computational resources. These trade-offs paint an uncertain picture of whether and to-what-extent modern AI could aid surgical practice. In this paper, we explore this question through a case study of surgical tool detection using state-of-the-art AI methods available in 2026. We demonstrate that even with multi-billion parameter models and extensive training, current Vision Language Models fall short in the seemingly simple task of tool detection in neurosurgery. Additionally, we show scaling experiments indicating that increasing model size and training time only leads to diminishing improvements in relevant performance metrics. Thus, our experiments suggest that current models could still face significant obstacles in surgical use cases. Moreover, some obstacles cannot be simply ``scaled away'' with additional compute and persist across diverse model architectures, raising the question of whether data and label availability are the only limiting factors. We discuss the main contributors to these constraints and advance potential solutions.
SurgPhase: Time efficient pituitary tumor surgery phase recognition via an interactive web platform
Mar 26, 2026Accurate surgical phase recognition is essential for analyzing procedural workflows, supporting intraoperative decision-making, and enabling data-driven improvements in surgical education and performance evaluation. In this work, we present a comprehensive framework for phase recognition in pituitary tumor surgery (PTS) videos, combining self-supervised representation learning, robust temporal modeling, and scalable data annotation strategies. Our method achieves 90\% accuracy on a held-out test set, outperforming current state-of-the-art approaches and demonstrating strong generalization across variable surgical cases. A central contribution of this work is the integration of a collaborative online platform designed for surgeons to upload surgical videos, receive automated phase analysis, and contribute to a growing dataset. This platform not only facilitates large-scale data collection but also fosters knowledge sharing and continuous model improvement. To address the challenge of limited labeled data, we pretrain a ResNet-50 model using the self-supervised framework on 251 unlabeled PTS videos, enabling the extraction of high-quality feature representations. Fine-tuning is performed on a labeled dataset of 81 procedures using a modified training regime that incorporates focal loss, gradual layer unfreezing, and dynamic sampling to address class imbalance and procedural variability.
NeMo: a toolkit for building AI applications using Neural Modules
Sep 14, 2019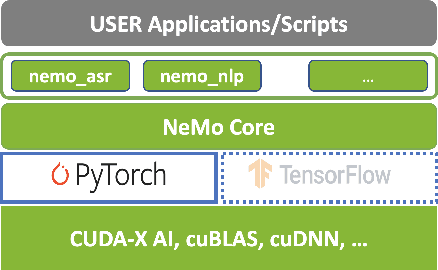

NeMo (Neural Modules) is a Python framework-agnostic toolkit for creating AI applications through re-usability, abstraction, and composition. NeMo is built around neural modules, conceptual blocks of neural networks that take typed inputs and produce typed outputs. Such modules typically represent data layers, encoders, decoders, language models, loss functions, or methods of combining activations. NeMo makes it easy to combine and re-use these building blocks while providing a level of semantic correctness checking via its neural type system. The toolkit comes with extendable collections of pre-built modules for automatic speech recognition and natural language processing. Furthermore, NeMo provides built-in support for distributed training and mixed precision on latest NVIDIA GPUs. NeMo is open-source https://github.com/NVIDIA/NeMo