 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Expressive Power of Deep Polynomial Neural Networks
May 29, 2019

We study deep neural networks with polynomial activations, particularly their expressive power. For a fixed architecture and activation degree, a polynomial neural network defines an algebraic map from weights to polynomials. The image of this map is the functional space associated to the network, and it is an irreducible algebraic variety upon taking closure. This paper proposes the dimension of this variety as a precise measure of the expressive power of polynomial neural networks. We obtain several theoretical results regarding this dimension as a function of architecture, including an exact formula for high activation degrees, as well as upper and lower bounds on layer widths in order for deep polynomials networks to fill the ambient functional space. We also present computational evidence that it is profitable in terms of expressiveness for layer widths to increase monotonically and then decrease monotonically. Finally, we link our study to favorable optimization properties when training weights, and we draw intriguing connections with tensor and polynomial decompositions.
On the Expected Dynamics of Nonlinear TD Learning
May 29, 2019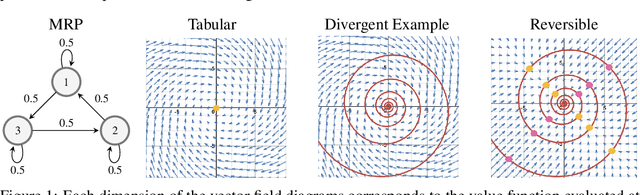
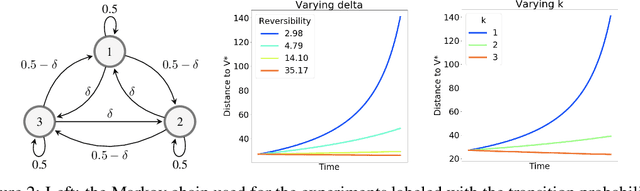
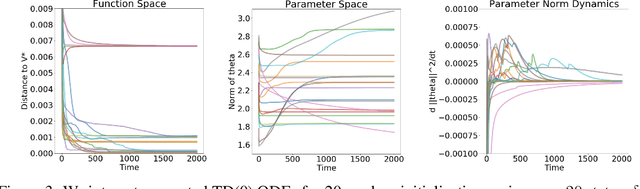
While there are convergence guarantees for temporal difference (TD) learning when using linear function approximators, the situation for nonlinear models is far less understood, and divergent examples are known. Here we take a first step towards extending theoretical convergence guarantees to TD learning with nonlinear function approximation. More precisely, we consider the expected dynamics of the TD(0) algorithm. We prove that this ODE is attracted to a compact set for smooth homogeneous functions including some ReLU networks. For over-parametrized and well-conditioned functions in sufficiently reversible environments we prove convergence to the global optimum. This result improves when using $k$-step or $ \lambda$ returns. Finally, we generalize a divergent counterexample to a family of divergent problems to motivate the assumptions needed to prove convergence.
Stability Properties of Graph Neural Networks
May 11, 2019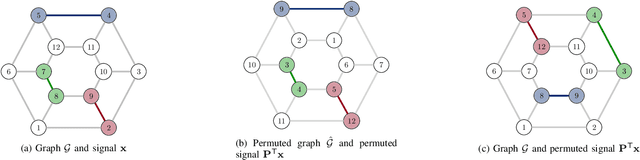
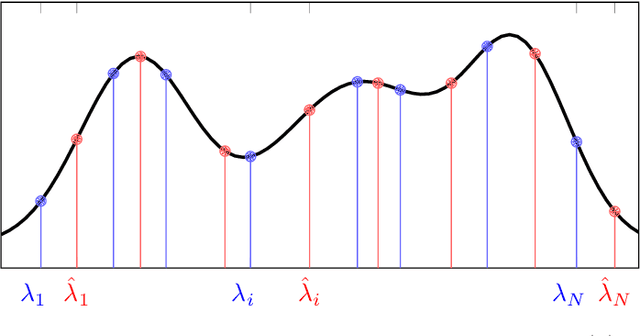
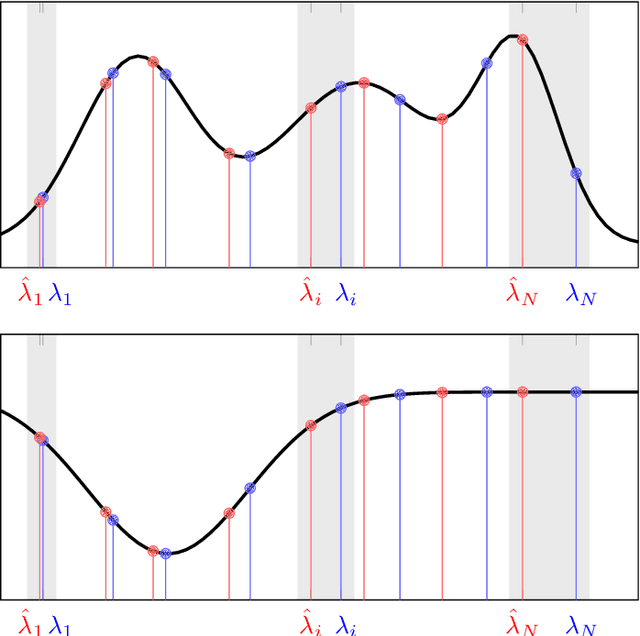
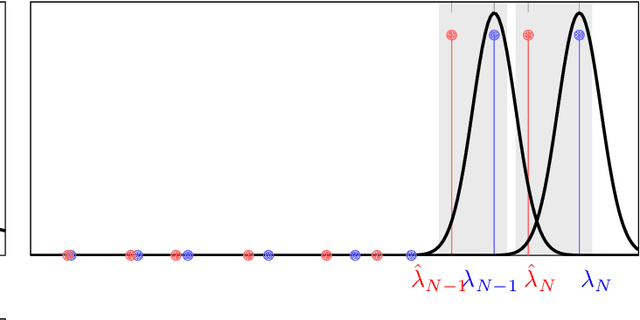
Data stemming from networks exhibit an irregular support, whereby each data element is related by arbitrary pairwise relationships determined by the network. Graph neural networks (GNNs) have emerged as information processing architectures that exploit the particularities of this underlying support. The use of nonlinearities in GNNs, coupled with the fact that filters are learned from data, raises mathematical challenges that have precluded the development of theoretical results that would give insight in the reasons for the remarkable performance of GNNs. In this work, we prove the property of stability, that states that a small change in the support of the data leads to a small (bounded) change in the output of the GNN. More specifically, we prove that the bound on the output difference of the GNN computed on one graph or another, is proportional to the difference between the graphs and the design parameters of the GNN, as long as the trained filters are integral Lipschitz. We exploit this result to provide some insights in the crucial effect that nonlinearities have in obtaining an architecture that is both stable and selective, a feat that is impossible to achieve if using only linear filters.
Advancing GraphSAGE with A Data-Driven Node Sampling
Apr 29, 2019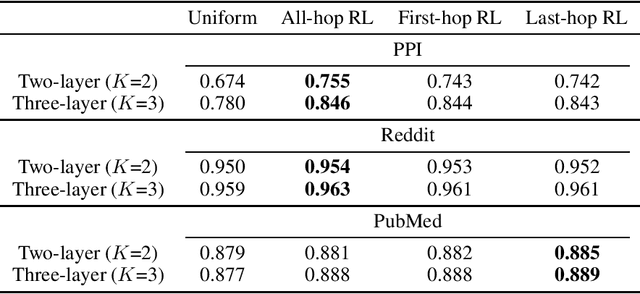
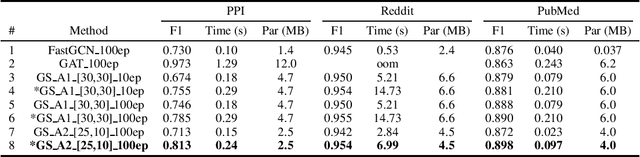
As an efficient and scalable graph neural network, GraphSAGE has enabled an inductive capability for inferring unseen nodes or graphs by aggregating subsampled local neighborhoods and by learning in a mini-batch gradient descent fashion. The neighborhood sampling used in GraphSAGE is effective in order to improve computing and memory efficiency when inferring a batch of target nodes with diverse degrees in parallel. Despite this advantage, the default uniform sampling suffers from high variance in training and inference, leading to sub-optimum accuracy. We propose a new data-driven sampling approach to reason about the real-valued importance of a neighborhood by a non-linear regressor, and to use the value as a criterion for subsampling neighborhoods. The regressor is learned using a value-based reinforcement learning. The implied importance for each combination of vertex and neighborhood is inductively extracted from the negative classification loss output of GraphSAGE. As a result, in an inductive node classification benchmark using three datasets, our method enhanced the baseline using the uniform sampling, outperforming recent variants of a graph neural network in accuracy.
Global convergence of neuron birth-death dynamics
Mar 27, 2019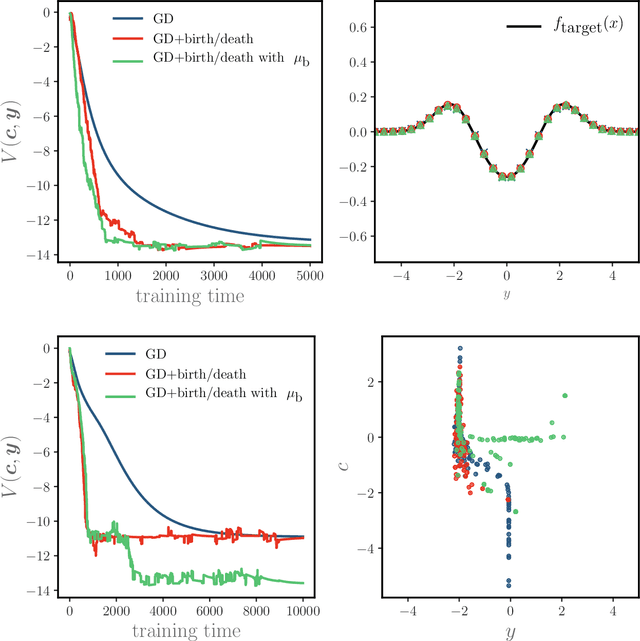
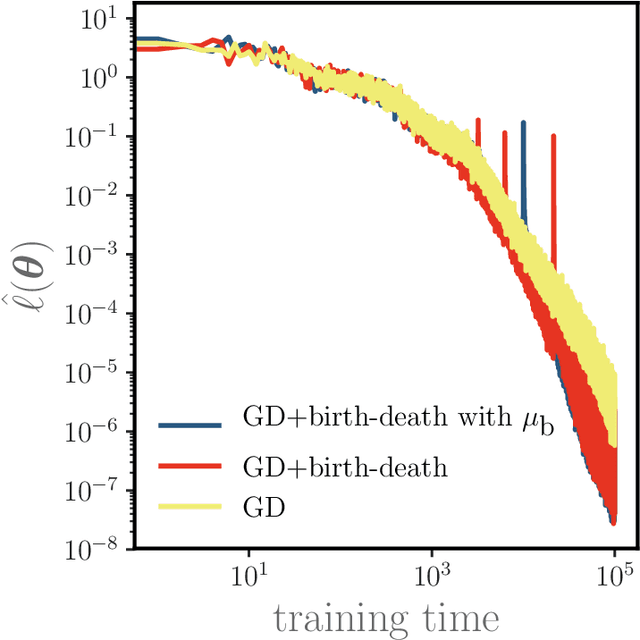
Neural networks with a large number of parameters admit a mean-field description, which has recently served as a theoretical explanation for the favorable training properties of "overparameterized" models. In this regime, gradient descent obeys a deterministic partial differential equation (PDE) that converges to a globally optimal solution for networks with a single hidden layer under appropriate assumptions. In this work, we propose a non-local mass transport dynamics that leads to a modified PDE with the same minimizer. We implement this non-local dynamics as a stochastic neuronal birth-death process and we prove that it accelerates the rate of convergence in the mean-field limit. We subsequently realize this PDE with two classes of numerical schemes that converge to the mean-field equation, each of which can easily be implemented for neural networks with finite numbers of parameters. We illustrate our algorithms with two models to provide intuition for the mechanism through which convergence is accelerated.
Kymatio: Scattering Transforms in Python
Dec 28, 2018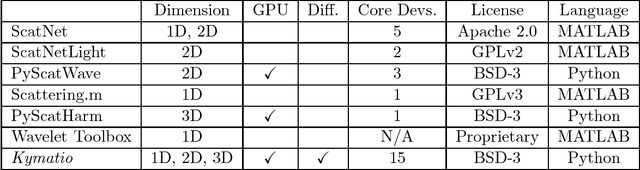
The wavelet scattering transform is an invariant signal representation suitable for many signal processing and machine learning applications. We present the Kymatio software package, an easy-to-use, high-performance Python implementation of the scattering transform in 1D, 2D, and 3D that is compatible with modern deep learning frameworks. All transforms may be executed on a GPU (in addition to CPU), offering a considerable speed up over CPU implementations. The package also has a small memory footprint, resulting inefficient memory usage. The source code, documentation, and examples are available undera BSD license at https://www.kymat.io/
Deep Geometric Prior for Surface Reconstruction
Nov 27, 2018
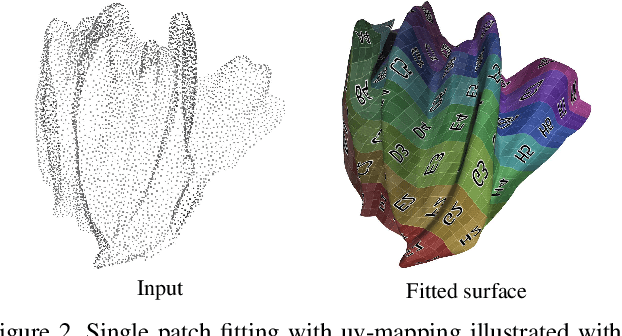
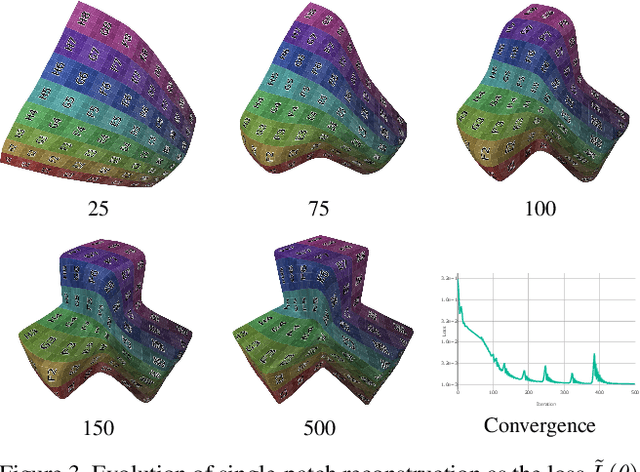
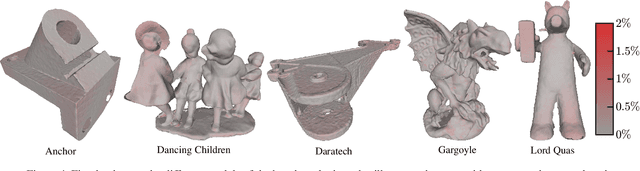
The reconstruction of a discrete surface from a point cloud is a fundamental geometry processing problem that has been studied for decades, with many methods developed. We propose the use of a deep neural network as a geometric prior for surface reconstruction. Specifically, we overfit a neural network representing a local chart parameterization to part of an input point cloud using the Wasserstein distance as a measure of approximation. By jointly fitting many such networks to overlapping parts of the point cloud, while enforcing a consistency condition, we compute a manifold atlas. By sampling this atlas, we can produce a dense reconstruction of the surface approximating the input cloud. The entire procedure does not require any training data or explicit regularization, yet, we show that it is able to perform remarkably well: not introducing typical overfitting artifacts, and approximating sharp features closely at the same time. We experimentally show that this geometric prior produces good results for both man-made objects containing sharp features and smoother organic objects, as well as noisy inputs. We compare our method with a number of well-known reconstruction methods on a standard surface reconstruction benchmark.
Supervised Community Detection with Line Graph Neural Networks
Oct 25, 2018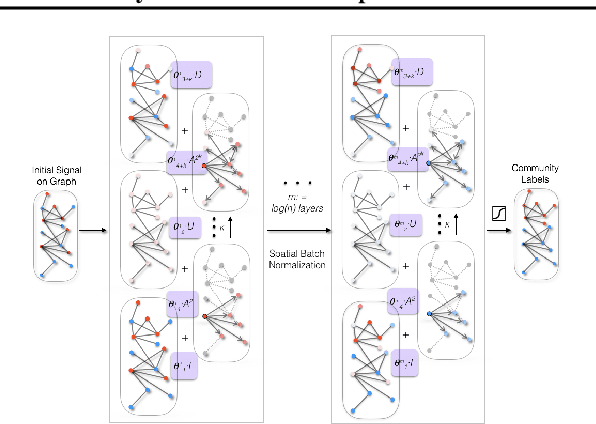
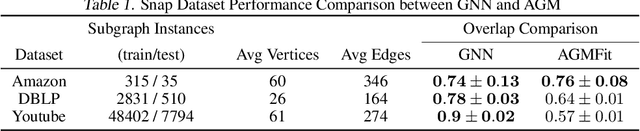
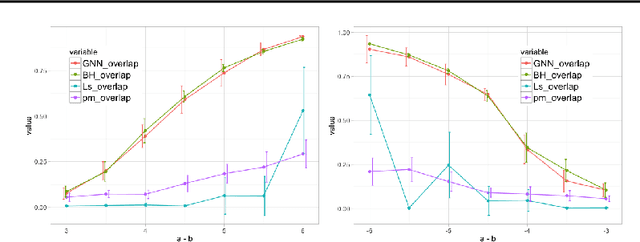
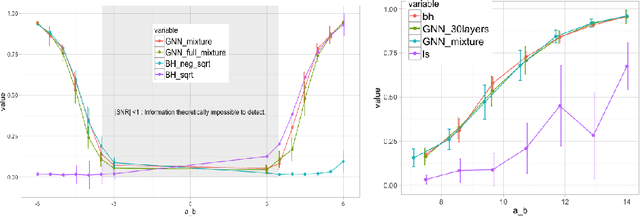
We study data-driven methods for community detection on graphs, an inverse problem that is typically solved in terms of the spectrum of certain operators or via posterior inference under certain probabilistic graphical models. Focusing on random graph families such as the stochastic block model, recent research has unified both approaches and identified both statistical and computational signal-to-noise detection thresholds. This graph inference task can be recast as a node-wise graph classification problem, and, as such, computational detection thresholds can be translated in terms of learning within appropriate models. We present a novel family of Graph Neural Networks (GNNs) and show that they can reach those detection thresholds in a purely data-driven manner without access to the underlying generative models, and even improve upon current computational thresholds in hard regimes. For that purpose, we propose to augment GNNs with the non-backtracking operator, defined on the line graph of edge adjacencies. We also perform the first analysis of optimization landscape on using GNNs to solve community detection problems, demonstrating that under certain simplifications and assumptions, the loss value at the local minima is close to the loss value at the global minimum/minima. Finally, the resulting model is also tested on real datasets, performing significantly better than previous models.
Divide and Conquer Networks
Oct 14, 2018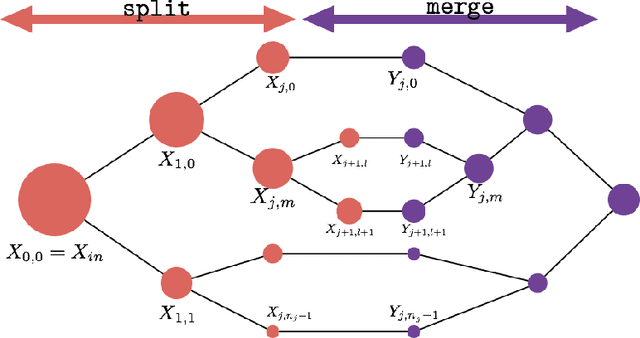
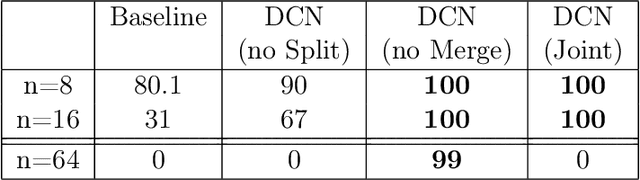
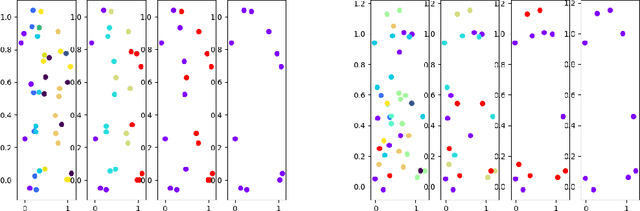
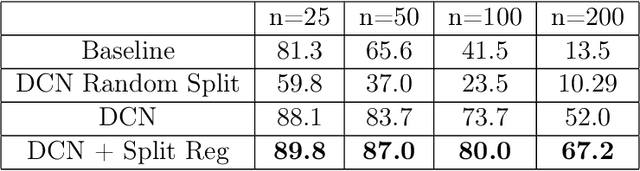
We consider the learning of algorithmic tasks by mere observation of input-output pairs. Rather than studying this as a black-box discrete regression problem with no assumption whatsoever on the input-output mapping, we concentrate on tasks that are amenable to the principle of divide and conquer, and study what are its implications in terms of learning. This principle creates a powerful inductive bias that we leverage with neural architectures that are defined recursively and dynamically, by learning two scale-invariant atomic operations: how to split a given input into smaller sets, and how to merge two partially solved tasks into a larger partial solution. Our model can be trained in weakly supervised environments, namely by just observing input-output pairs, and in even weaker environments, using a non-differentiable reward signal. Moreover, thanks to the dynamic aspect of our architecture, we can incorporate the computational complexity as a regularization term that can be optimized by backpropagation. We demonstrate the flexibility and efficiency of the Divide-and-Conquer Network on several combinatorial and geometric tasks: convex hull, clustering, knapsack and euclidean TSP. Thanks to the dynamic programming nature of our model, we show significant improvements in terms of generalization error and computational complexity.
Backplay: "Man muss immer umkehren"
Sep 28, 2018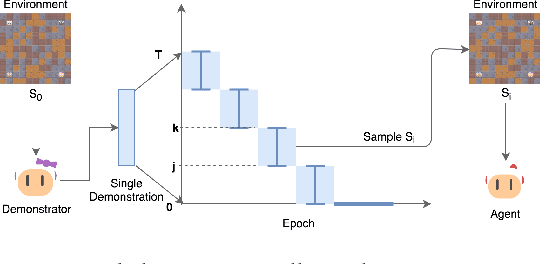
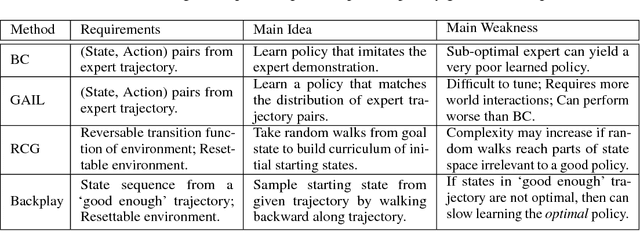
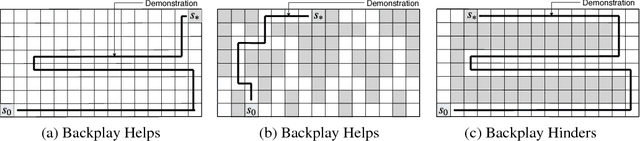
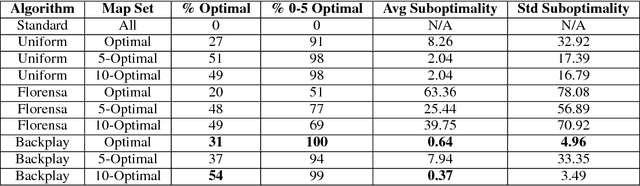
A long-standing problem in model-free reinforcement learning (RL) is that it requires a large number of trials to learn a good policy, especially in environments with sparse rewards. We explore a method to increase the sample efficiency of RL when we have access to demonstrations. Our approach, Backplay, uses a single demonstration to construct a curriculum for a given task. Rather than starting each training episode in the environment's fixed initial state, we start the agent near the end of the demonstration and move the starting point backwards during the course of training until we reach the initial state. We perform experiments in a competitive four-player game (Pommerman) and a path-finding maze game. We find that Backplay provides significant gains in sample complexity with a stark advantage in sparse reward settings. In some cases, it reached success rates greater than 50 and generalized to unseen initial conditions, while standard RL did not yield any improvement.