 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Parametric Video-Grounded Text Generation
Jan 27, 2023



Efficient video-language modeling should consider the computational cost because of a large, sometimes intractable, number of video frames. Parametric approaches such as the attention mechanism may not be ideal since its computational cost quadratically increases as the video length increases. Rather, previous studies have relied on offline feature extraction or frame sampling to represent the video efficiently, focusing on cross-modal modeling in short video clips. In this paper, we propose a semi-parametric video-grounded text generation model, SeViT, a novel perspective on scalable video-language modeling toward long untrimmed videos. Treating a video as an external data store, SeViT includes a non-parametric frame retriever to select a few query-relevant frames from the data store for a given query and a parametric generator to effectively aggregate the frames with the query via late fusion methods. Experimental results demonstrate our method has a significant advantage in longer videos and causal video understanding. Moreover, our model achieves the new state of the art on four video-language datasets, iVQA (+4.8), Next-QA (+6.9), and Activitynet-QA (+4.8) in accuracy, and MSRVTT-Caption (+3.6) in CIDEr.
Specializing Multi-domain NMT via Penalizing Low Mutual Information
Oct 24, 2022



Multi-domain Neural Machine Translation (NMT) trains a single model with multiple domains. It is appealing because of its efficacy in handling multiple domains within one model. An ideal multi-domain NMT should learn distinctive domain characteristics simultaneously, however, grasping the domain peculiarity is a non-trivial task. In this paper, we investigate domain-specific information through the lens of mutual information (MI) and propose a new objective that penalizes low MI to become higher. Our method achieved the state-of-the-art performance among the current competitive multi-domain NMT models. Also, we empirically show our objective promotes low MI to be higher resulting in domain-specialized multi-domain NMT.
Language-free Training for Zero-shot Video Grounding
Oct 24, 2022



Given an untrimmed video and a language query depicting a specific temporal moment in the video, video grounding aims to localize the time interval by understanding the text and video simultaneously. One of the most challenging issues is an extremely time- and cost-consuming annotation collection, including video captions in a natural language form and their corresponding temporal regions. In this paper, we present a simple yet novel training framework for video grounding in the zero-shot setting, which learns a network with only video data without any annotation. Inspired by the recent language-free paradigm, i.e. training without language data, we train the network without compelling the generation of fake (pseudo) text queries into a natural language form. Specifically, we propose a method for learning a video grounding model by selecting a temporal interval as a hypothetical correct answer and considering the visual feature selected by our method in the interval as a language feature, with the help of the well-aligned visual-language space of CLIP. Extensive experiments demonstrate the prominence of our language-free training framework, outperforming the existing zero-shot video grounding method and even several weakly-supervised approaches with large margins on two standard datasets.
MIDMs: Matching Interleaved Diffusion Models for Exemplar-based Image Translation
Sep 23, 2022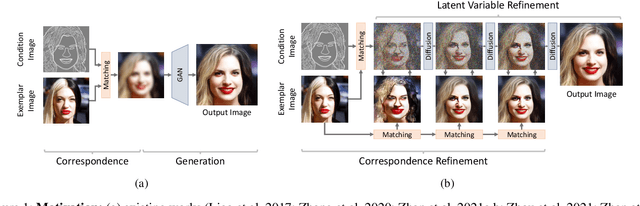
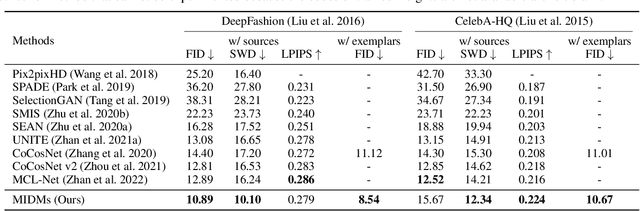
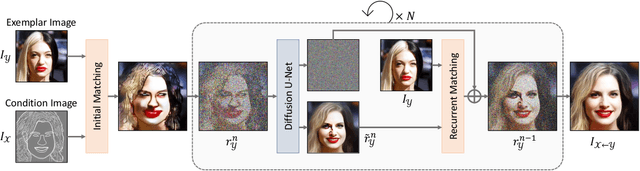
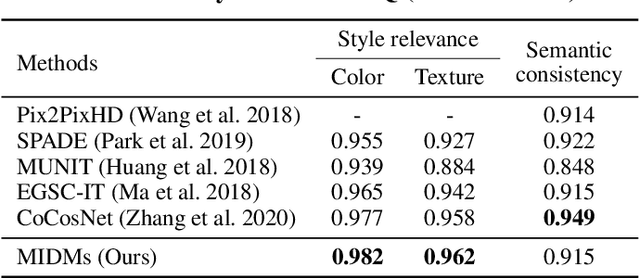
We present a novel method for exemplar-based image translation, called matching interleaved diffusion models (MIDMs). Most existing methods for this task were formulated as GAN-based matching-then-generation framework. However, in this framework, matching errors induced by the difficulty of semantic matching across cross-domain, e.g., sketch and photo, can be easily propagated to the generation step, which in turn leads to degenerated results. Motivated by the recent success of diffusion models overcoming the shortcomings of GANs, we incorporate the diffusion models to overcome these limitations. Specifically, we formulate a diffusion-based matching-and-generation framework that interleaves cross-domain matching and diffusion steps in the latent space by iteratively feeding the intermediate warp into the noising process and denoising it to generate a translated image. In addition, to improve the reliability of the diffusion process, we design a confidence-aware process using cycle-consistency to consider only confident regions during translation. Experimental results show that our MIDMs generate more plausible images than state-of-the-art methods.
Automatic Detection of Noisy Electrocardiogram Signals without Explicit Noise Labels
Aug 08, 2022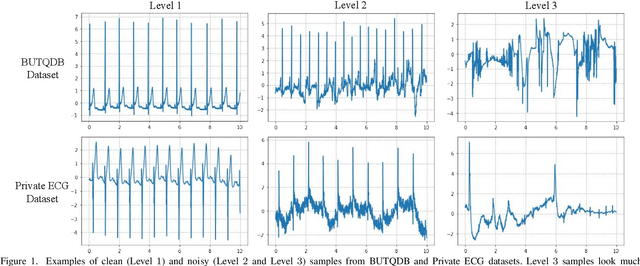
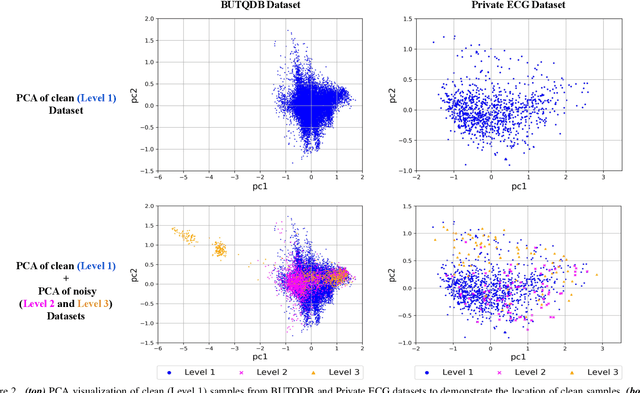
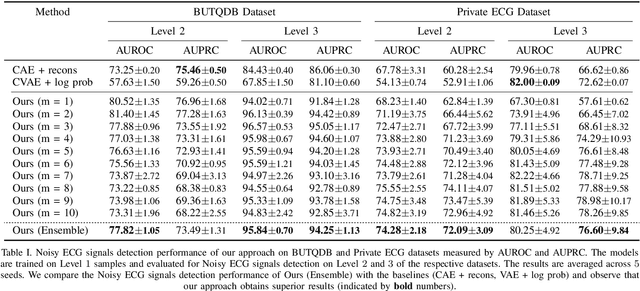
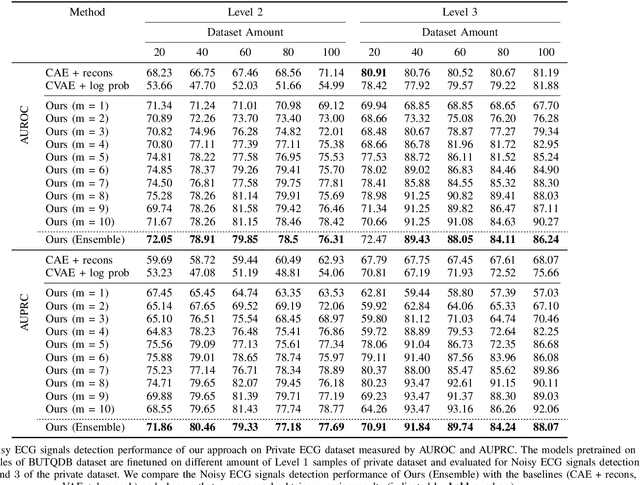
Electrocardiogram (ECG) signals are beneficial in diagnosing cardiovascular diseases, which are one of the leading causes of death. However, they are often contaminated by noise artifacts and affect the automatic and manual diagnosis process. Automatic deep learning-based examination of ECG signals can lead to inaccurate diagnosis, and manual analysis involves rejection of noisy ECG samples by clinicians, which might cost extra time. To address this limitation, we present a two-stage deep learning-based framework to automatically detect the noisy ECG samples. Through extensive experiments and analysis on two different datasets, we observe that the deep learning-based framework can detect slightly and highly noisy ECG samples effectively. We also study the transfer of the model learned on one dataset to another dataset and observe that the framework effectively detects noisy ECG samples.
PointFix: Learning to Fix Domain Bias for Robust Online Stereo Adaptation
Jul 27, 2022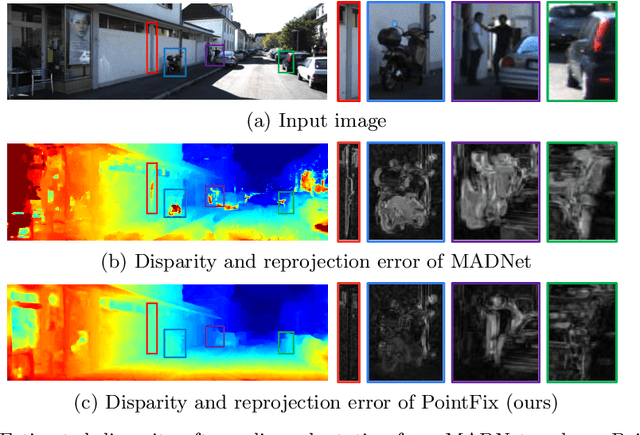
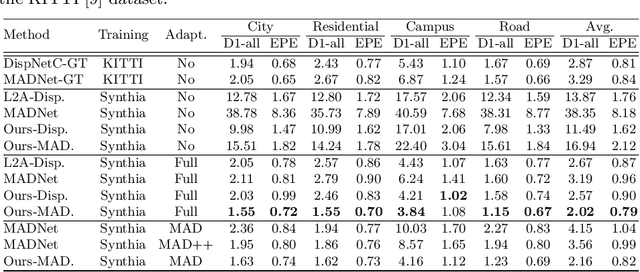
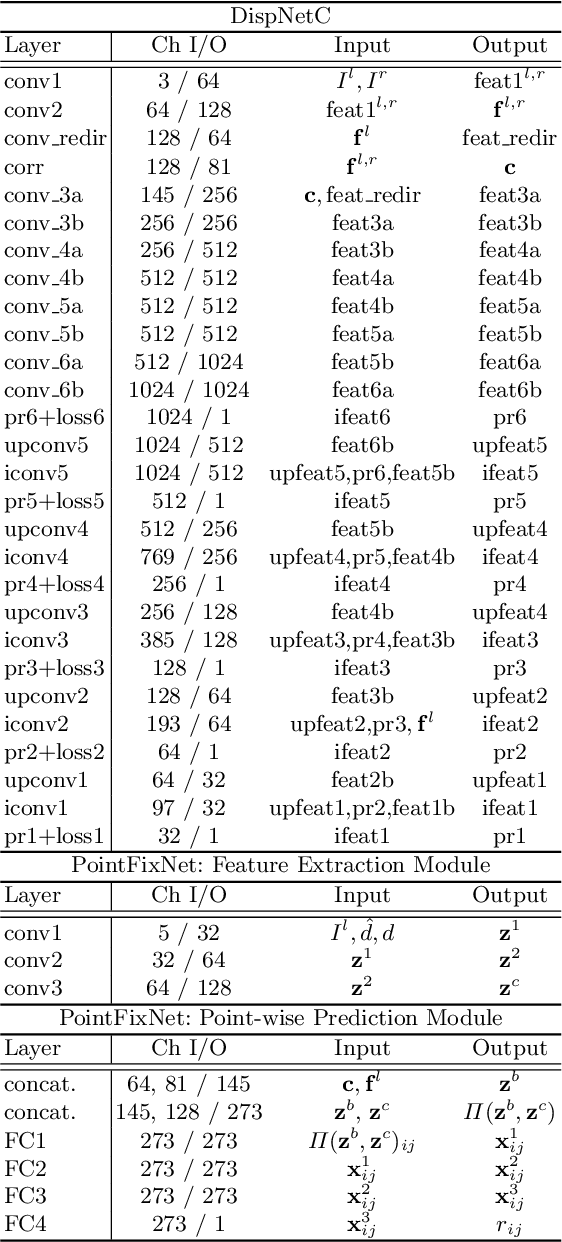
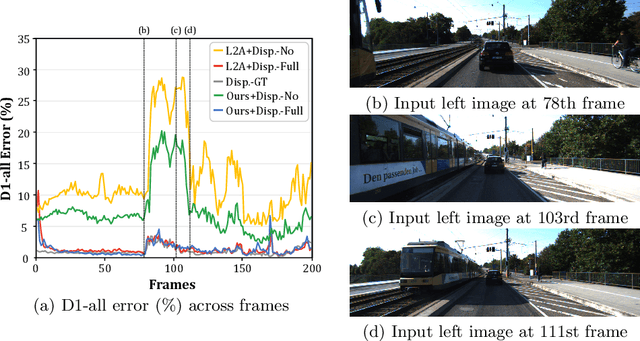
Online stereo adaptation tackles the domain shift problem, caused by different environments between synthetic (training) and real (test) datasets, to promptly adapt stereo models in dynamic real-world applications such as autonomous driving. However, previous methods often fail to counteract particular regions related to dynamic objects with more severe environmental changes. To mitigate this issue, we propose to incorporate an auxiliary point-selective network into a meta-learning framework, called PointFix, to provide a robust initialization of stereo models for online stereo adaptation. In a nutshell, our auxiliary network learns to fix local variants intensively by effectively back-propagating local information through the meta-gradient for the robust initialization of the baseline model. This network is model-agnostic, so can be used in any kind of architectures in a plug-and-play manner. We conduct extensive experiments to verify the effectiveness of our method under three adaptation settings such as short-, mid-, and long-term sequences. Experimental results show that the proper initialization of the base stereo model by the auxiliary network enables our learning paradigm to achieve state-of-the-art performance at inference.
Mutual Information Divergence: A Unified Metric for Multimodal Generative Models
May 25, 2022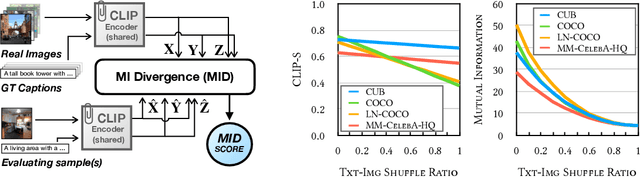
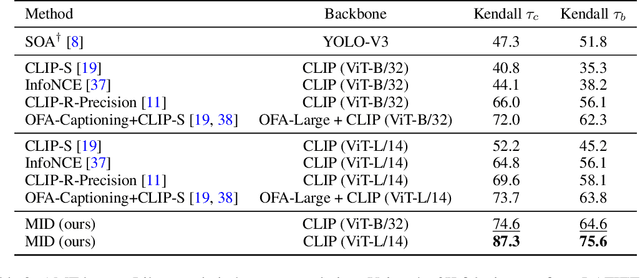
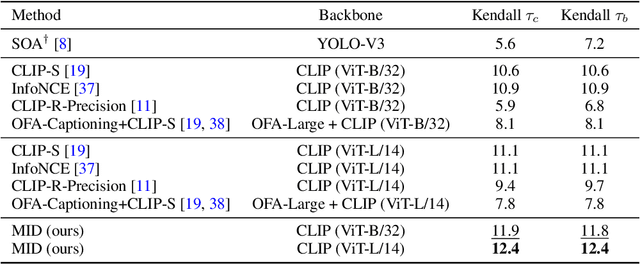
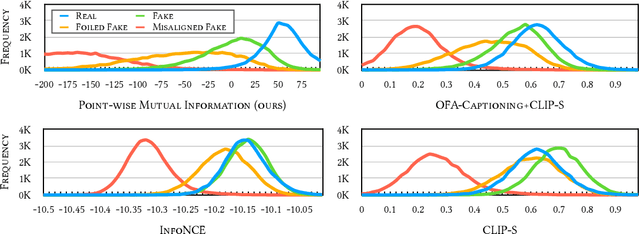
Text-to-image generation and image captioning are recently emerged as a new experimental paradigm to assess machine intelligence. They predict continuous quantity accompanied by their sampling techniques in the generation, making evaluation complicated and intractable to get marginal distributions. Based on a recent trend that multimodal generative evaluations exploit a vison-and-language pre-trained model, we propose the negative Gaussian cross-mutual information using the CLIP features as a unified metric, coined by Mutual Information Divergence (MID). To validate, we extensively compare it with competing metrics using carefully-generated or human-annotated judgments in text-to-image generation and image captioning tasks. The proposed MID significantly outperforms the competitive methods by having consistency across benchmarks, sample parsimony, and robustness toward the exploited CLIP model. We look forward to seeing the underrepresented implications of the Gaussian cross-mutual information in multimodal representation learning and the future works based on this novel proposition.
Probabilistic Representations for Video Contrastive Learning
Apr 08, 2022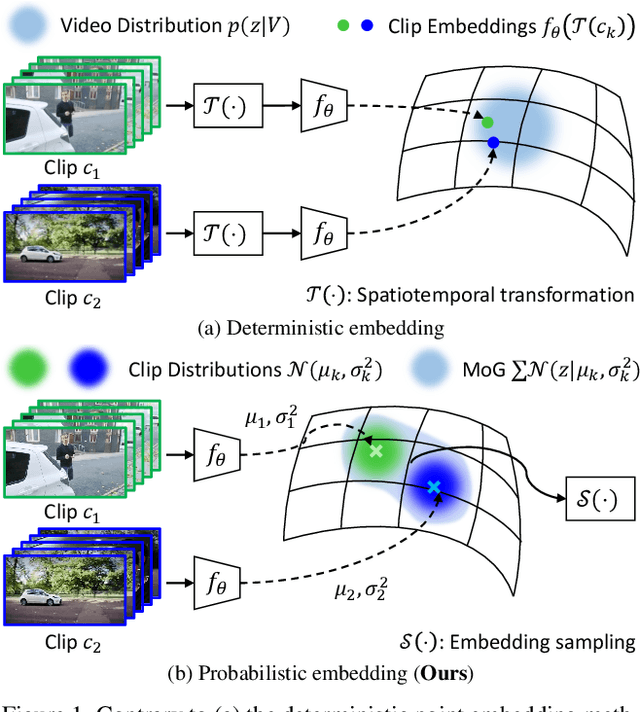
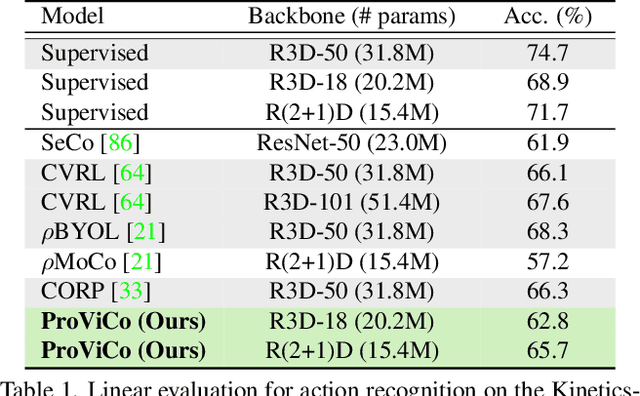
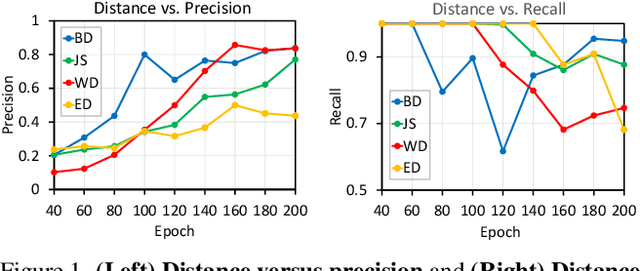

This paper presents Probabilistic Video Contrastive Learning, a self-supervised representation learning method that bridges contrastive learning with probabilistic representation. We hypothesize that the clips composing the video have different distributions in short-term duration, but can represent the complicated and sophisticated video distribution through combination in a common embedding space. Thus, the proposed method represents video clips as normal distributions and combines them into a Mixture of Gaussians to model the whole video distribution. By sampling embeddings from the whole video distribution, we can circumvent the careful sampling strategy or transformations to generate augmented views of the clips, unlike previous deterministic methods that have mainly focused on such sample generation strategies for contrastive learning. We further propose a stochastic contrastive loss to learn proper video distributions and handle the inherent uncertainty from the nature of the raw video. Experimental results verify that our probabilistic embedding stands as a state-of-the-art video representation learning for action recognition and video retrieval on the most popular benchmarks, including UCF101 and HMDB51.
Pin the Memory: Learning to Generalize Semantic Segmentation
Apr 07, 2022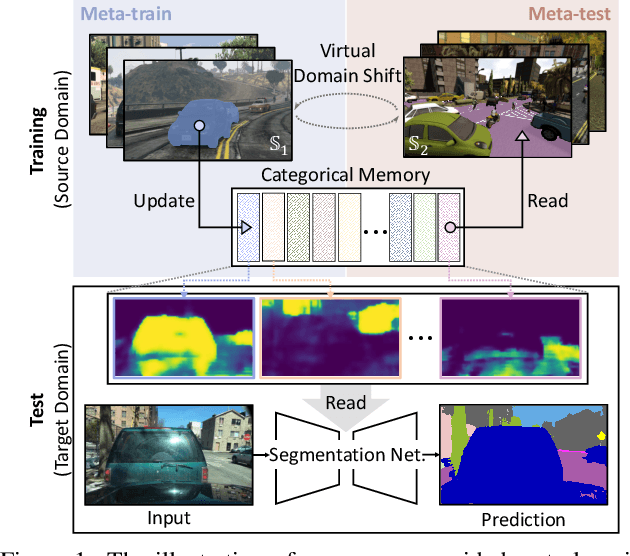
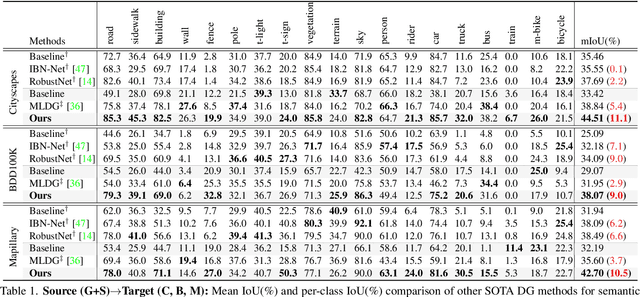
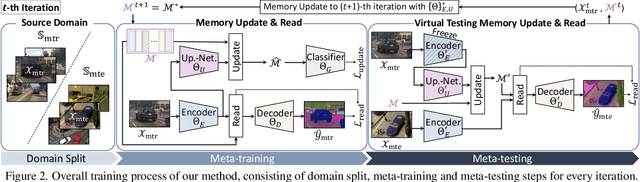
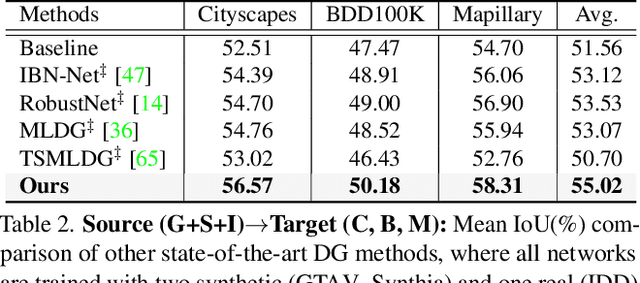
The rise of deep neural networks has led to several breakthroughs for semantic segmentation. In spite of this, a model trained on source domain often fails to work properly in new challenging domains, that is directly concerned with the generalization capability of the model. In this paper, we present a novel memory-guided domain generalization method for semantic segmentation based on meta-learning framework. Especially, our method abstracts the conceptual knowledge of semantic classes into categorical memory which is constant beyond the domains. Upon the meta-learning concept, we repeatedly train memory-guided networks and simulate virtual test to 1) learn how to memorize a domain-agnostic and distinct information of classes and 2) offer an externally settled memory as a class-guidance to reduce the ambiguity of representation in the test data of arbitrary unseen domain. To this end, we also propose memory divergence and feature cohesion losses, which encourage to learn memory reading and update processes for category-aware domain generalization. Extensive experiments for semantic segmentation demonstrate the superior generalization capability of our method over state-of-the-art works on various benchmarks.
Multi-domain Unsupervised Image-to-Image Translation with Appearance Adaptive Convolution
Feb 06, 2022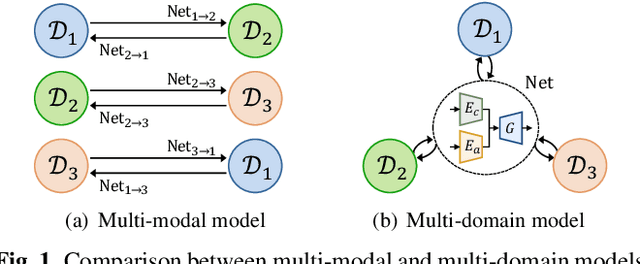
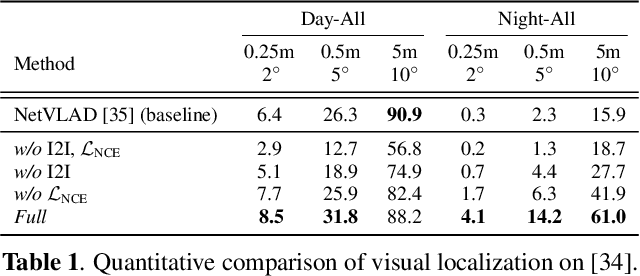
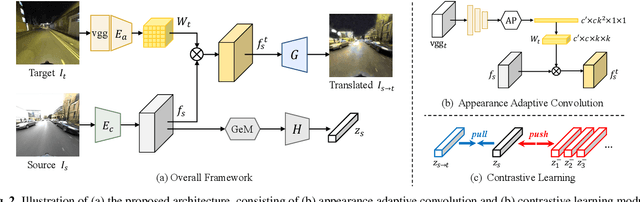

Over the past few years, image-to-image (I2I) translation methods have been proposed to translate a given image into diverse outputs. Despite the impressive results, they mainly focus on the I2I translation between two domains, so the multi-domain I2I translation still remains a challenge. To address this problem, we propose a novel multi-domain unsupervised image-to-image translation (MDUIT) framework that leverages the decomposed content feature and appearance adaptive convolution to translate an image into a target appearance while preserving the given geometric content. We also exploit a contrast learning objective, which improves the disentanglement ability and effectively utilizes multi-domain image data in the training process by pairing the semantically similar images. This allows our method to learn the diverse mappings between multiple visual domains with only a single framework. We show that the proposed method produces visually diverse and plausible results in multiple domains compared to the state-of-the-art methods.