 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMD-ViSCo: A Unified Model for Multi-Directional Vital Sign Waveform Conversion
Jun 10, 2025Despite the remarkable progress of deep-learning methods generating a target vital sign waveform from a source vital sign waveform, most existing models are designed exclusively for a specific source-to-target pair. This requires distinct model architectures, optimization procedures, and pre-processing pipelines, resulting in multiple models that hinder usability in clinical settings. To address this limitation, we propose the Multi-Directional Vital-Sign Converter (MD-ViSCo), a unified framework capable of generating any target waveform such as electrocardiogram (ECG), photoplethysmogram (PPG), or arterial blood pressure (ABP) from any single input waveform with a single model. MD-ViSCo employs a shallow 1-Dimensional U-Net integrated with a Swin Transformer that leverages Adaptive Instance Normalization (AdaIN) to capture distinct waveform styles. To evaluate the efficacy of MD-ViSCo, we conduct multi-directional waveform generation on two publicly available datasets. Our framework surpasses state-of-the-art baselines (NabNet & PPG2ABP) on average across all waveform types, lowering Mean absolute error (MAE) by 8.8% and improving Pearson correlation (PC) by 4.9% over two datasets. In addition, the generated ABP waveforms satisfy the Association for the Advancement of Medical Instrumentation (AAMI) criterion and achieve Grade B on the British Hypertension Society (BHS) standard, outperforming all baselines. By eliminating the need for developing a distinct model for each task, we believe that this work offers a unified framework that can deal with any kind of vital sign waveforms with a single model in healthcare monitoring.
EHRFL: Federated Learning Framework for Heterogeneous EHRs and Precision-guided Selection of Participating Clients
Apr 20, 2024



In this study, we provide solutions to two practical yet overlooked scenarios in federated learning for electronic health records (EHRs): firstly, we introduce EHRFL, a framework that facilitates federated learning across healthcare institutions with distinct medical coding systems and database schemas using text-based linearization of EHRs. Secondly, we focus on a scenario where a single healthcare institution initiates federated learning to build a model tailored for itself, in which the number of clients must be optimized in order to reduce expenses incurred by the host. For selecting participating clients, we present a novel precision-based method, leveraging data latents to identify suitable participants for the institution. Our empirical results show that EHRFL effectively enables federated learning across hospitals with different EHR systems. Furthermore, our results demonstrate the efficacy of our precision-based method in selecting reduced number of participating clients without compromising model performance, resulting in lower operational costs when constructing institution-specific models. We believe this work lays a foundation for the broader adoption of federated learning on EHRs.
Rediscovery of CNN's Versatility for Text-based Encoding of Raw Electronic Health Records
Mar 15, 2023



Making the most use of abundant information in electronic health records (EHR) is rapidly becoming an important topic in the medical domain. Recent work presented a promising framework that embeds entire features in raw EHR data regardless of its form and medical code standards. The framework, however, only focuses on encoding EHR with minimal preprocessing and fails to consider how to learn efficient EHR representation in terms of computation and memory usage. In this paper, we search for a versatile encoder not only reducing the large data into a manageable size but also well preserving the core information of patients to perform diverse clinical tasks. We found that hierarchically structured Convolutional Neural Network (CNN) often outperforms the state-of-the-art model on diverse tasks such as reconstruction, prediction, and generation, even with fewer parameters and less training time. Moreover, it turns out that making use of the inherent hierarchy of EHR data can boost the performance of any kind of backbone models and clinical tasks performed. Through extensive experiments, we present concrete evidence to generalize our research findings into real-world practice. We give a clear guideline on building the encoder based on the research findings captured while exploring numerous settings.
UniHPF : Universal Healthcare Predictive Framework with Zero Domain Knowledge
Nov 15, 2022



Despite the abundance of Electronic Healthcare Records (EHR), its heterogeneity restricts the utilization of medical data in building predictive models. To address this challenge, we propose Universal Healthcare Predictive Framework (UniHPF), which requires no medical domain knowledge and minimal pre-processing for multiple prediction tasks. Experimental results demonstrate that UniHPF is capable of building large-scale EHR models that can process any form of medical data from distinct EHR systems. We believe that our findings can provide helpful insights for further research on the multi-source learning of EHRs.
Universal EHR Federated Learning Framework
Nov 14, 2022



Federated learning (FL) is the most practical multi-source learning method for electronic healthcare records (EHR). Despite its guarantee of privacy protection, the wide application of FL is restricted by two large challenges: the heterogeneous EHR systems, and the non-i.i.d. data characteristic. A recent research proposed a framework that unifies heterogeneous EHRs, named UniHPF. We attempt to address both the challenges simultaneously by combining UniHPF and FL. Our study is the first approach to unify heterogeneous EHRs into a single FL framework. This combination provides an average of 3.4% performance gain compared to local learning. We believe that our framework is practically applicable in the real-world FL.
Unifying Heterogenous Electronic Health Records Systems via Text-Based Code Embedding
Nov 19, 2021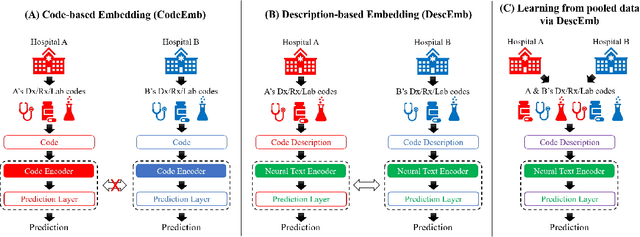
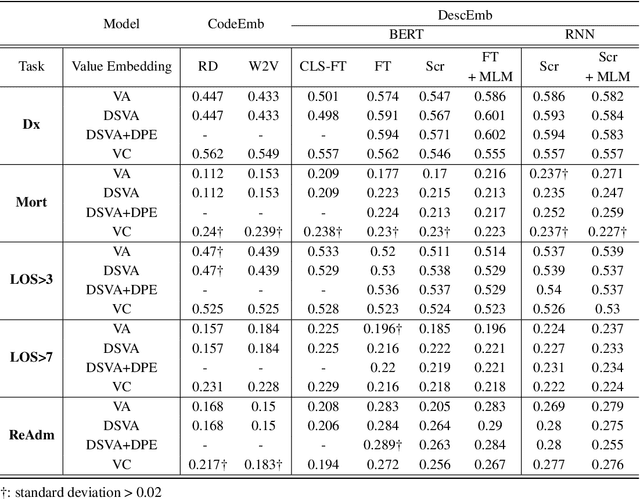
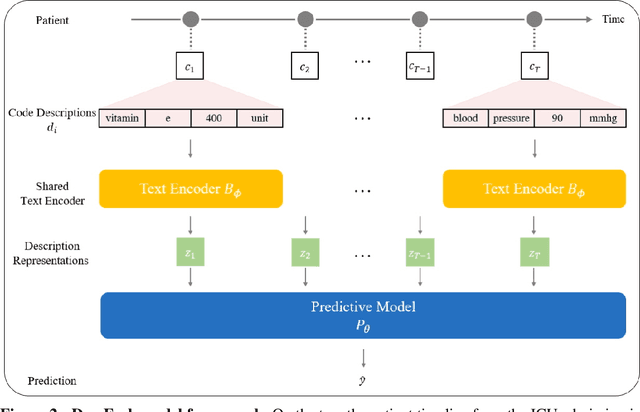
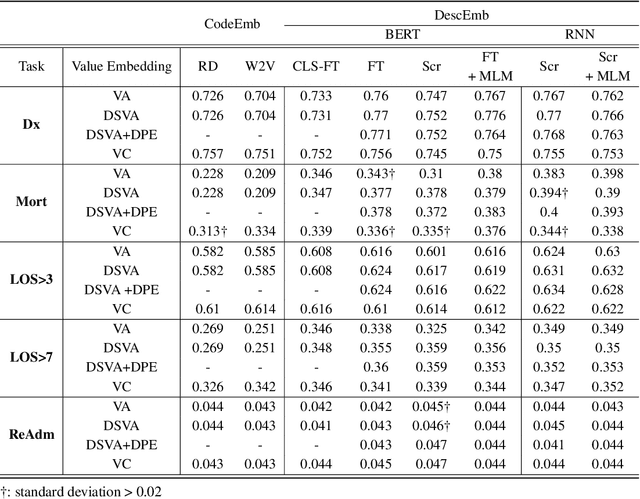
EHR systems lack a unified code system forrepresenting medical concepts, which acts asa barrier for the deployment of deep learningmodels in large scale to multiple clinics and hos-pitals. To overcome this problem, we introduceDescription-based Embedding,DescEmb, a code-agnostic representation learning framework forEHR. DescEmb takes advantage of the flexibil-ity of neural language understanding models toembed clinical events using their textual descrip-tions rather than directly mapping each event toa dedicated embedding. DescEmb outperformedtraditional code-based embedding in extensiveexperiments, especially in a zero-shot transfertask (one hospital to another), and was able totrain a single unified model for heterogeneousEHR datasets.