 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Unimodal Shortcuts: MLLMs as Cross-Modal Reasoners for Grounded Named Entity Recognition
Feb 04, 2026Grounded Multimodal Named Entity Recognition (GMNER) aims to extract text-based entities, assign them semantic categories, and ground them to corresponding visual regions. In this work, we explore the potential of Multimodal Large Language Models (MLLMs) to perform GMNER in an end-to-end manner, moving beyond their typical role as auxiliary tools within cascaded pipelines. Crucially, our investigation reveals a fundamental challenge: MLLMs exhibit $\textbf{modality bias}$, including visual bias and textual bias, which stems from their tendency to take unimodal shortcuts rather than rigorous cross-modal verification. To address this, we propose Modality-aware Consistency Reasoning ($\textbf{MCR}$), which enforces structured cross-modal reasoning through Multi-style Reasoning Schema Injection (MRSI) and Constraint-guided Verifiable Optimization (CVO). MRSI transforms abstract constraints into executable reasoning chains, while CVO empowers the model to dynamically align its reasoning trajectories with Group Relative Policy Optimization (GRPO). Experiments on GMNER and visual grounding tasks demonstrate that MCR effectively mitigates modality bias and achieves superior performance compared to existing baselines.
Detecting Emotional Dynamic Trajectories: An Evaluation Framework for Emotional Support in Language Models
Nov 12, 2025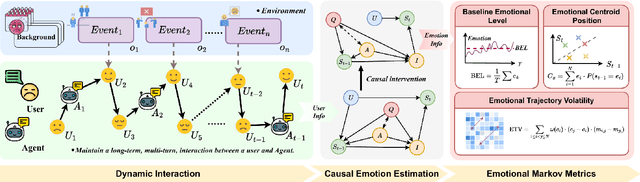
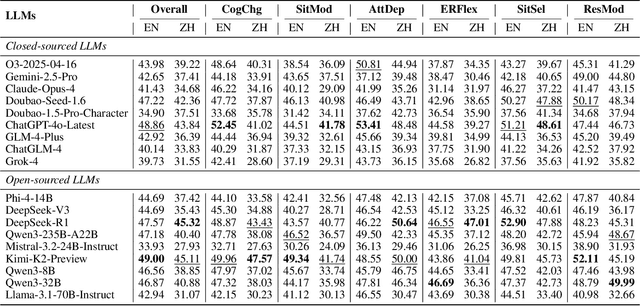
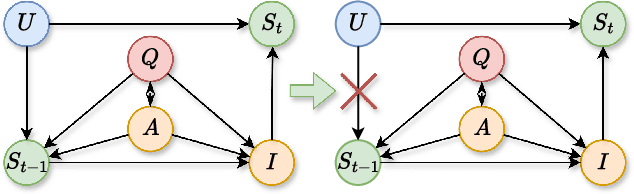
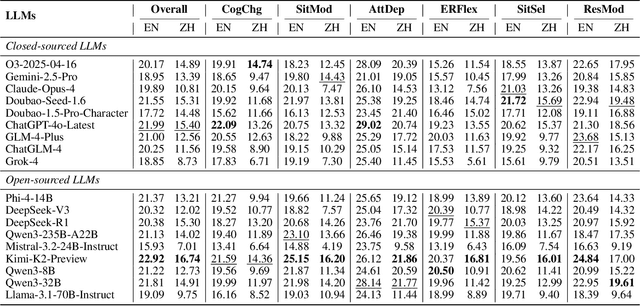
Emotional support is a core capability in human-AI interaction, with applications including psychological counseling, role play, and companionship. However, existing evaluations of large language models (LLMs) often rely on short, static dialogues and fail to capture the dynamic and long-term nature of emotional support. To overcome this limitation, we shift from snapshot-based evaluation to trajectory-based assessment, adopting a user-centered perspective that evaluates models based on their ability to improve and stabilize user emotional states over time. Our framework constructs a large-scale benchmark consisting of 328 emotional contexts and 1,152 disturbance events, simulating realistic emotional shifts under evolving dialogue scenarios. To encourage psychologically grounded responses, we constrain model outputs using validated emotion regulation strategies such as situation selection and cognitive reappraisal. User emotional trajectories are modeled as a first-order Markov process, and we apply causally-adjusted emotion estimation to obtain unbiased emotional state tracking. Based on this framework, we introduce three trajectory-level metrics: Baseline Emotional Level (BEL), Emotional Trajectory Volatility (ETV), and Emotional Centroid Position (ECP). These metrics collectively capture user emotional dynamics over time and support comprehensive evaluation of long-term emotional support performance of LLMs. Extensive evaluations across a diverse set of LLMs reveal significant disparities in emotional support capabilities and provide actionable insights for model development.
Evaluating and Steering Modality Preferences in Multimodal Large Language Model
May 27, 2025Multimodal large language models (MLLMs) have achieved remarkable performance on complex tasks with multimodal context. However, it is still understudied whether they exhibit modality preference when processing multimodal contexts. To study this question, we first build a \textbf{MC\textsuperscript{2}} benchmark under controlled evidence conflict scenarios to systematically evaluate modality preference, which is the tendency to favor one modality over another when making decisions based on multimodal conflicting evidence. Our extensive evaluation reveals that all 18 tested MLLMs generally demonstrate clear modality bias, and modality preference can be influenced by external interventions. An in-depth analysis reveals that the preference direction can be captured within the latent representations of MLLMs. Built on this, we propose a probing and steering method based on representation engineering to explicitly control modality preference without additional fine-tuning or carefully crafted prompts. Our method effectively amplifies modality preference toward a desired direction and applies to downstream tasks such as hallucination mitigation and multimodal machine translation, yielding promising improvements.
A Mask Free Neural Network for Monaural Speech Enhancement
Jun 07, 2023



In speech enhancement, the lack of clear structural characteristics in the target speech phase requires the use of conservative and cumbersome network frameworks. It seems difficult to achieve competitive performance using direct methods and simple network architectures. However, we propose the MFNet, a direct and simple network that can not only map speech but also map reverse noise. This network is constructed by stacking global local former blocks (GLFBs), which combine the advantages of Mobileblock for global processing and Metaformer architecture for local interaction. Our experimental results demonstrate that our network using mapping method outperforms masking methods, and direct mapping of reverse noise is the optimal solution in strong noise environments. In a horizontal comparison on the 2020 Deep Noise Suppression (DNS) challenge test set without reverberation, to the best of our knowledge, MFNet is the current state-of-the-art (SOTA) mapping model.