 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Vision-Language Models from Iconic to Inclusive for Multi-Label Recognition Without Labels
Jun 10, 2026Understanding multi-label images remains a challenging task in computer vision. With the rapid progress of vision-language multimodal learning, vision-language models (VLMs) enable zero-shot recognition without labeled data. However, due to their intrinsic design, these models often prioritize the most iconic object and omit other contextual positives. This intrinsic bias conflicts with the nature of multi-label learning, thereby limiting their applicability. In this work, we propose an unsupervised framework that adapts VLMs from iconic recognition toward inclusive understanding, enabling label-free multi-label image recognition. Our approach consists of two key stages, ``cutting'' and ``sewing'': In the cutting stage, we present the multi-sampling response estimator to prevent the model from concentrating only on one single object. In the second sewing stage, the multi-object blend adaptation is introduced to adjust the labels to better conform to the multi-label distribution while preserving the intrinsic characteristics of the original model within only one epoch. Extensive experiments show that our framework significantly outperforms existing unsupervised approaches on four public datasets, even surpassing several representative weakly supervised baselines. These results demonstrate the potential of adapting pre-trained VLMs for more comprehensive visual understanding without manual annotations. Our code is publicly available at https://github.com/iCVTEAM/TailorCLIP.
AcademiClaw: When Students Set Challenges for AI Agents
May 04, 2026Benchmarks within the OpenClaw ecosystem have thus far evaluated exclusively assistant-level tasks, leaving the academic-level capabilities of OpenClaw largely unexamined. We introduce AcademiClaw, a bilingual benchmark of 80 complex, long-horizon tasks sourced directly from university students' real academic workflows -- homework, research projects, competitions, and personal projects -- that they found current AI agents unable to solve effectively. Curated from 230 student-submitted candidates through rigorous expert review, the final task set spans 25+ professional domains, ranging from olympiad-level mathematics and linguistics problems to GPU-intensive reinforcement learning and full-stack system debugging, with 16 tasks requiring CUDA GPU execution. Each task executes in an isolated Docker sandbox and is scored on task completion by multi-dimensional rubrics combining six complementary techniques, with an independent five-category safety audit providing additional behavioral analysis. Experiments on six frontier models show that even the best achieves only a 55\% pass rate. Further analysis uncovers sharp capability boundaries across task domains, divergent behavioral strategies among models, and a disconnect between token consumption and output quality, providing fine-grained diagnostic signals beyond what aggregate metrics reveal. We hope that AcademiClaw and its open-sourced data and code can serve as a useful resource for the OpenClaw community, driving progress toward agents that are more capable and versatile across the full breadth of real-world academic demands. All data and code are available at https://github.com/GAIR-NLP/AcademiClaw.
Hybrid Dynamic Contrast and Probability Distillation for Unsupervised Person Re-Id
Sep 29, 2021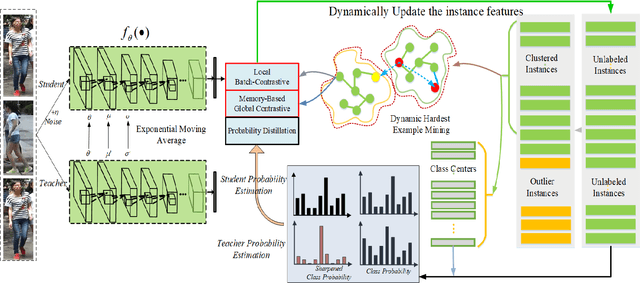
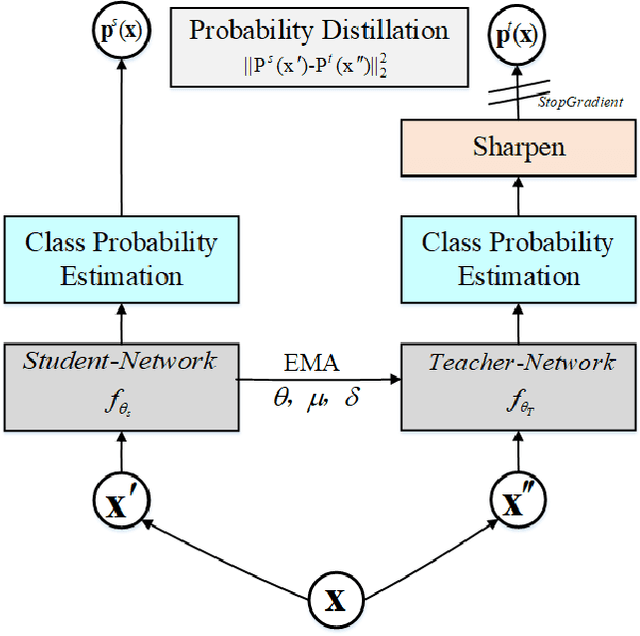

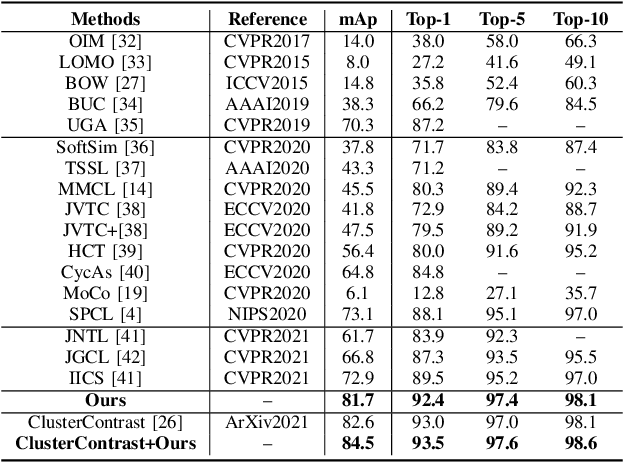
Unsupervised person re-identification (Re-Id) has attracted increasing attention due to its practical application in the read-world video surveillance system. The traditional unsupervised Re-Id are mostly based on the method alternating between clustering and fine-tuning with the classification or metric learning objectives on the grouped clusters. However, since person Re-Id is an open-set problem, the clustering based methods often leave out lots of outlier instances or group the instances into the wrong clusters, thus they can not make full use of the training samples as a whole. To solve these problems, we present the hybrid dynamic cluster contrast and probability distillation algorithm. It formulates the unsupervised Re-Id problem into an unified local-to-global dynamic contrastive learning and self-supervised probability distillation framework. Specifically, the proposed method can make the utmost of the self-supervised signals of all the clustered and un-clustered instances, from both the instances' self-contrastive level and the probability distillation respective, in the memory-based non-parametric manner. Besides, the proposed hybrid local-to-global contrastive learning can take full advantage of the informative and valuable training examples for effective and robust training. Extensive experiment results show that the proposed method achieves superior performances to state-of-the-art methods, under both the purely unsupervised and unsupervised domain adaptation experiment settings.