 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwapping Autoencoder for Deep Image Manipulation
Jul 01, 2020


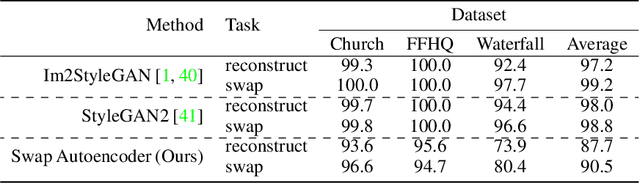
Deep generative models have become increasingly effective at producing realistic images from randomly sampled seeds, but using such models for controllable manipulation of existing images remains challenging. We propose the Swapping Autoencoder, a deep model designed specifically for image manipulation, rather than random sampling. The key idea is to encode an image with two independent components and enforce that any swapped combination maps to a realistic image. In particular, we encourage the components to represent structure and texture, by enforcing one component to encode co-occurrent patch statistics across different parts of an image. As our method is trained with an encoder, finding the latent codes for a new input image becomes trivial, rather than cumbersome. As a result, it can be used to manipulate real input images in various ways, including texture swapping, local and global editing, and latent code vector arithmetic. Experiments on multiple datasets show that our model produces better results and is substantially more efficient compared to recent generative models.
Generative Tweening: Long-term Inbetweening of 3D Human Motions
May 28, 2020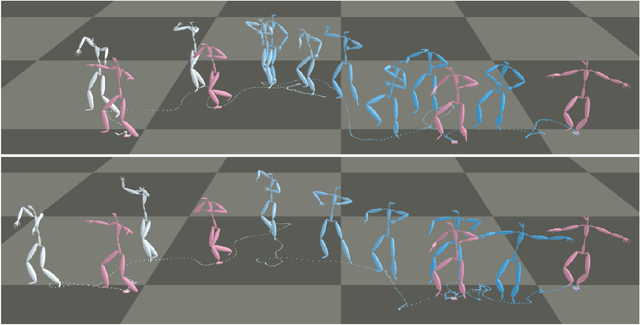
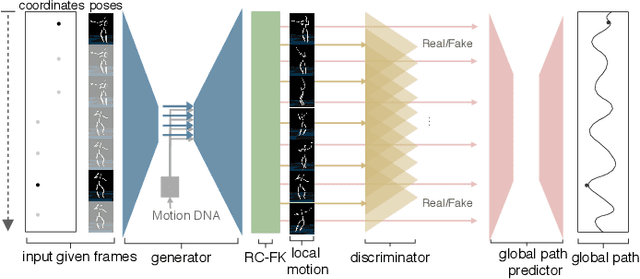

The ability to generate complex and realistic human body animations at scale, while following specific artistic constraints, has been a fundamental goal for the game and animation industry for decades. Popular techniques include key-framing, physics-based simulation, and database methods via motion graphs. Recently, motion generators based on deep learning have been introduced. Although these learning models can automatically generate highly intricate stylized motions of arbitrary length, they still lack user control. To this end, we introduce the problem of long-term inbetweening, which involves automatically synthesizing complex motions over a long time interval given very sparse keyframes by users. We identify a number of challenges related to this problem, including maintaining biomechanical and keyframe constraints, preserving natural motions, and designing the entire motion sequence holistically while considering all constraints. We introduce a biomechanically constrained generative adversarial network that performs long-term inbetweening of human motions, conditioned on keyframe constraints. This network uses a novel two-stage approach where it first predicts local motion in the form of joint angles, and then predicts global motion, i.e. the global path that the character follows. Since there are typically a number of possible motions that could satisfy the given user constraints, we also enable our network to generate a variety of outputs with a scheme that we call Motion DNA. This approach allows the user to manipulate and influence the output content by feeding seed motions (DNA) to the network. Trained with 79 classes of captured motion data, our network performs robustly on a variety of highly complex motion styles.
AutoToon: Automatic Geometric Warping for Face Cartoon Generation
Apr 06, 2020
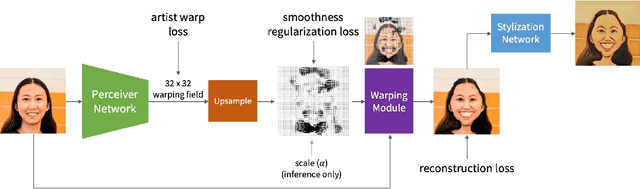


Caricature, a type of exaggerated artistic portrait, amplifies the distinctive, yet nuanced traits of human faces. This task is typically left to artists, as it has proven difficult to capture subjects' unique characteristics well using automated methods. Recent development of deep end-to-end methods has achieved promising results in capturing style and higher-level exaggerations. However, a key part of caricatures, face warping, has remained challenging for these systems. In this work, we propose AutoToon, the first supervised deep learning method that yields high-quality warps for the warping component of caricatures. Completely disentangled from style, it can be paired with any stylization method to create diverse caricatures. In contrast to prior art, we leverage an SENet and spatial transformer module and train directly on artist warping fields, applying losses both prior to and after warping. As shown by our user studies, we achieve appealing exaggerations that amplify distinguishing features of the face while preserving facial detail.
On the Continuity of Rotation Representations in Neural Networks
Dec 21, 2018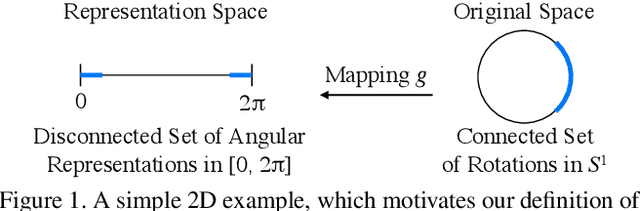
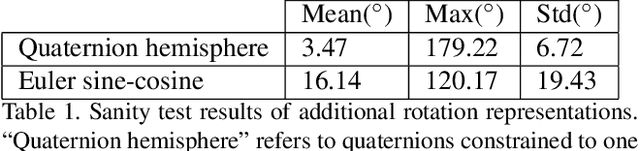

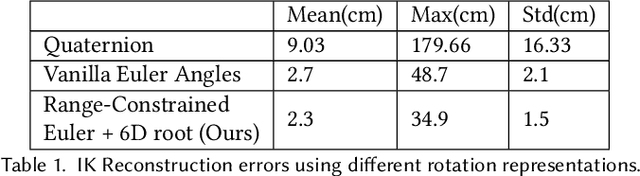
In neural networks, it is often desirable to work with various representations of the same space. For example, 3D rotations can be represented with quaternions or Euler angles. In this paper, we advance a definition of a continuous representation, which can be helpful for training deep neural network. We relate this to the definition of topological equivalence. We then investigate what are continuous and discontinuous representations for 2D, 3D, and n-dimensional rotations. We demonstrate that for 3D rotations, all representations are discontinuous in four or fewer dimensions in real Euclidean space. Thus, widely used representations such as quaternions and Euler angles are discontinuous and difficult for neural networks to learn. We show that the 3D rotations have continuous representations in 5D and 6D which are more suitable for learning. We also present continuous representations for the general case of the n dimensional rotation group SO(n). While our main focus is on rotations, we also show that our constructions apply to other groups such as the orthogonal group and similarity transforms. We finally present empirical results, which show that our continuous rotation representations outperform discontinuous ones for several practical problems in graphics and vision, including a simple autoencoder sanity test, a rotation estimator for 3D point clouds, and an inverse kinematics solver for 3D human poses.
TextureGAN: Controlling Deep Image Synthesis with Texture Patches
Apr 14, 2018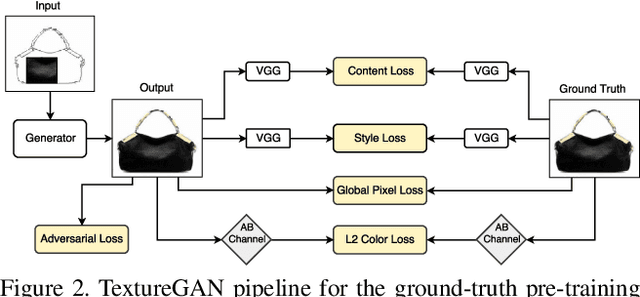
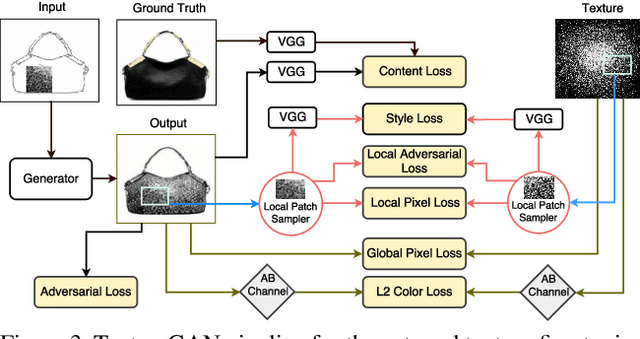


In this paper, we investigate deep image synthesis guided by sketch, color, and texture. Previous image synthesis methods can be controlled by sketch and color strokes but we are the first to examine texture control. We allow a user to place a texture patch on a sketch at arbitrary locations and scales to control the desired output texture. Our generative network learns to synthesize objects consistent with these texture suggestions. To achieve this, we develop a local texture loss in addition to adversarial and content loss to train the generative network. We conduct experiments using sketches generated from real images and textures sampled from a separate texture database and results show that our proposed algorithm is able to generate plausible images that are faithful to user controls. Ablation studies show that our proposed pipeline can generate more realistic images than adapting existing methods directly.
Scribbler: Controlling Deep Image Synthesis with Sketch and Color
Dec 05, 2016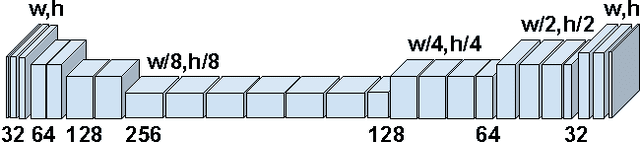



Recently, there have been several promising methods to generate realistic imagery from deep convolutional networks. These methods sidestep the traditional computer graphics rendering pipeline and instead generate imagery at the pixel level by learning from large collections of photos (e.g. faces or bedrooms). However, these methods are of limited utility because it is difficult for a user to control what the network produces. In this paper, we propose a deep adversarial image synthesis architecture that is conditioned on sketched boundaries and sparse color strokes to generate realistic cars, bedrooms, or faces. We demonstrate a sketch based image synthesis system which allows users to 'scribble' over the sketch to indicate preferred color for objects. Our network can then generate convincing images that satisfy both the color and the sketch constraints of user. The network is feed-forward which allows users to see the effect of their edits in real time. We compare to recent work on sketch to image synthesis and show that our approach can generate more realistic, more diverse, and more controllable outputs. The architecture is also effective at user-guided colorization of grayscale images.