 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Attacks On Multi-Agent Communication
Jan 17, 2021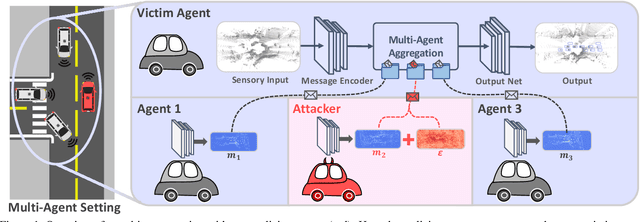
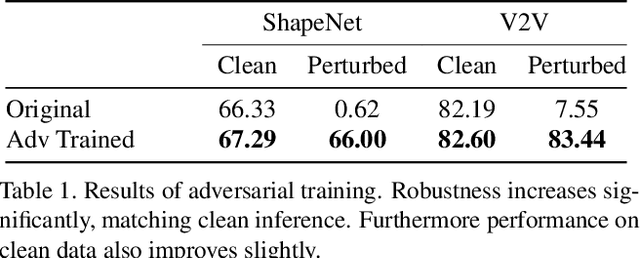
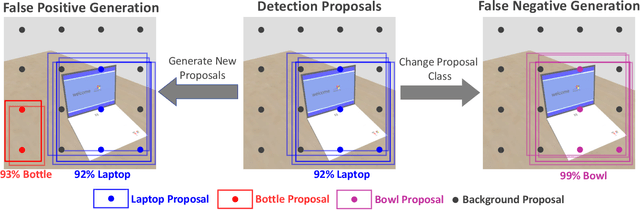
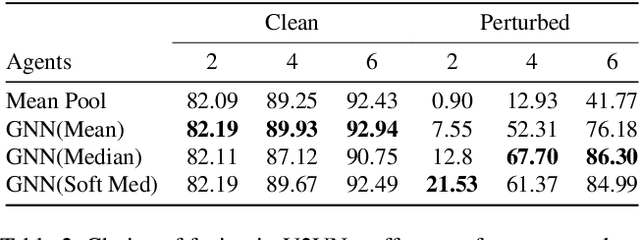
Growing at a very fast pace, modern autonomous systems will soon be deployed at scale, opening up the possibility for cooperative multi-agent systems. By sharing information and distributing workloads, autonomous agents can better perform their tasks and enjoy improved computation efficiency. However, such advantages rely heavily on communication channels which have been shown to be vulnerable to security breaches. Thus, communication can be compromised to execute adversarial attacks on deep learning models which are widely employed in modern systems. In this paper, we explore such adversarial attacks in a novel multi-agent setting where agents communicate by sharing learned intermediate representations. We observe that an indistinguishable adversarial message can severely degrade performance, but becomes weaker as the number of benign agents increase. Furthermore, we show that transfer attacks are more difficult in this setting when compared to directly perturbing the inputs, as it is necessary to align the distribution of communication messages with domain adaptation. Finally, we show that low-budget online attacks can be achieved by exploiting the temporal consistency of streaming sensory inputs.
AdvSim: Generating Safety-Critical Scenarios for Self-Driving Vehicles
Jan 16, 2021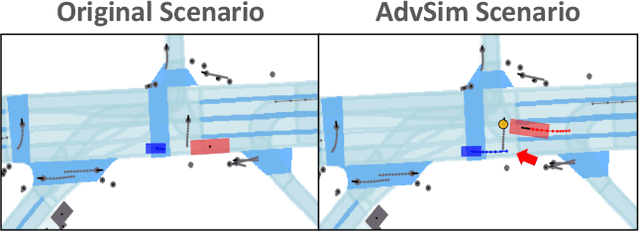
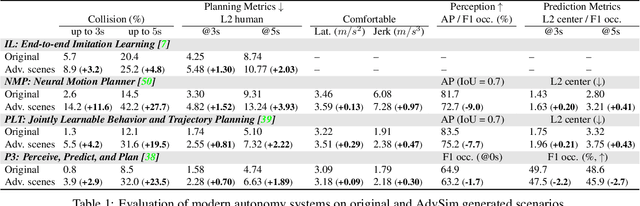

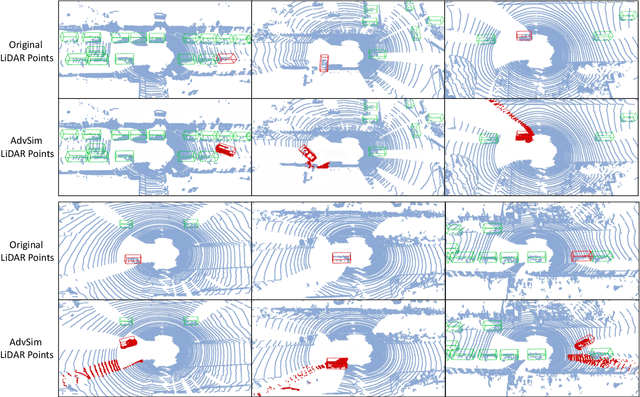
As self-driving systems become better, simulating scenarios where the autonomy stack is likely to fail becomes of key importance. Traditionally, those scenarios are generated for a few scenes with respect to the planning module that takes ground-truth actor states as input. This does not scale and cannot identify all possible autonomy failures, such as perception failures due to occlusion. In this paper, we propose AdvSim, an adversarial framework to generate safety-critical scenarios for any LiDAR-based autonomy system. Given an initial traffic scenario, AdvSim modifies the actors' trajectories in a physically plausible manner and updates the LiDAR sensor data to create realistic observations of the perturbed world. Importantly, by simulating directly from sensor data, we obtain adversarial scenarios that are safety-critical for the full autonomy stack. Our experiments show that our approach is general and can identify thousands of semantically meaningful safety-critical scenarios for a wide range of modern self-driving systems. Furthermore, we show that the robustness and safety of these autonomy systems can be further improved by training them with scenarios generated by AdvSim.
Learning to Communicate and Correct Pose Errors
Nov 10, 2020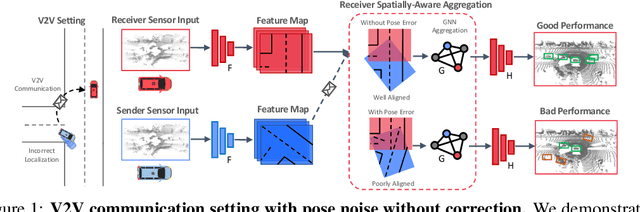
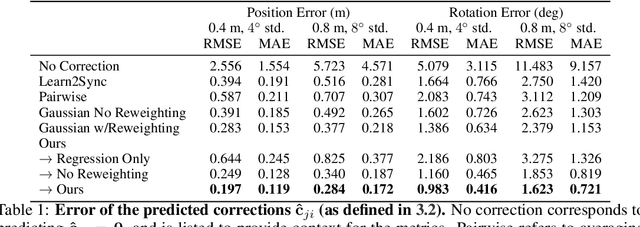
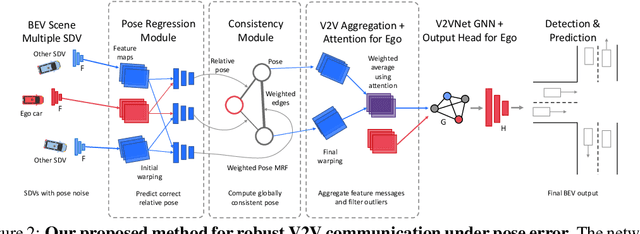
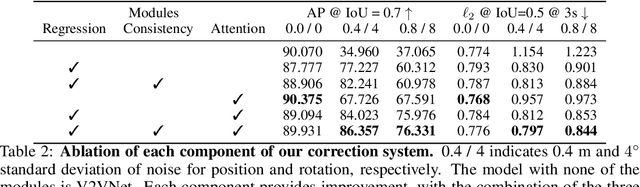
Learned communication makes multi-agent systems more effective by aggregating distributed information. However, it also exposes individual agents to the threat of erroneous messages they might receive. In this paper, we study the setting proposed in V2VNet, where nearby self-driving vehicles jointly perform object detection and motion forecasting in a cooperative manner. Despite a huge performance boost when the agents solve the task together, the gain is quickly diminished in the presence of pose noise since the communication relies on spatial transformations. Hence, we propose a novel neural reasoning framework that learns to communicate, to estimate potential errors, and finally, to reach a consensus about those errors. Experiments confirm that our proposed framework significantly improves the robustness of multi-agent self-driving perception and motion forecasting systems under realistic and severe localization noise.
Policy Learning Using Weak Supervision
Oct 05, 2020

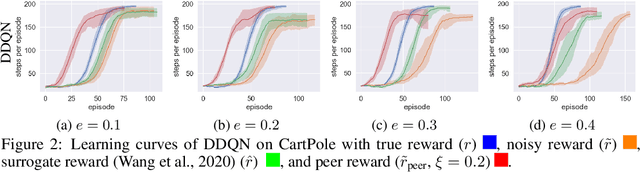
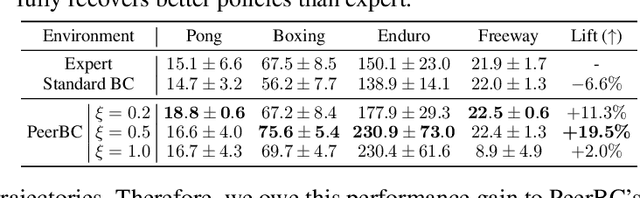
Most existing policy learning solutions require the learning agents to receive high-quality supervision signals, e.g., rewards in reinforcement learning (RL) or high-quality expert's demonstrations in behavioral cloning (BC). These quality supervisions are either infeasible or prohibitively expensive to obtain in practice. We aim for a unified framework that leverages the weak supervisions to perform policy learning efficiently. To handle this problem, we treat the "weak supervisions" as imperfect information coming from a peer agent, and evaluate the learning agent's policy based on a "correlated agreement" with the peer agent's policy (instead of simple agreements). Our way of leveraging peer agent's information offers us a family of solutions that learn effectively from weak supervisions with theoretical guarantees. Extensive evaluations on tasks including RL with noisy reward, BC with weak demonstrations and standard policy co-training (RL + BC) show that the proposed approach leads to substantial improvements, especially when the complexity or the noise of the learning environments grows.
BabyAI++: Towards Grounded-Language Learning beyond Memorization
Apr 15, 2020

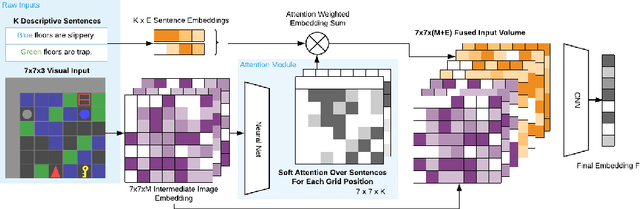
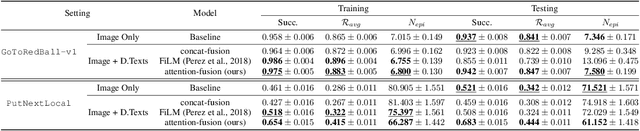
Despite success in many real-world tasks (e.g., robotics), reinforcement learning (RL) agents still learn from tabula rasa when facing new and dynamic scenarios. By contrast, humans can offload this burden through textual descriptions. Although recent works have shown the benefits of instructive texts in goal-conditioned RL, few have studied whether descriptive texts help agents to generalize across dynamic environments. To promote research in this direction, we introduce a new platform, BabyAI++, to generate various dynamic environments along with corresponding descriptive texts. Moreover, we benchmark several baselines inherited from the instruction following setting and develop a novel approach towards visually-grounded language learning on our platform. Extensive experiments show strong evidence that using descriptive texts improves the generalization of RL agents across environments with varied dynamics.
Beyond Adversarial Training: Min-Max Optimization in Adversarial Attack and Defense
Jun 09, 2019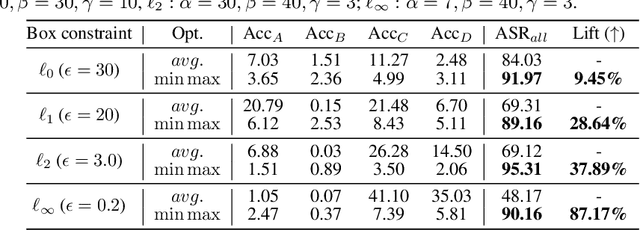
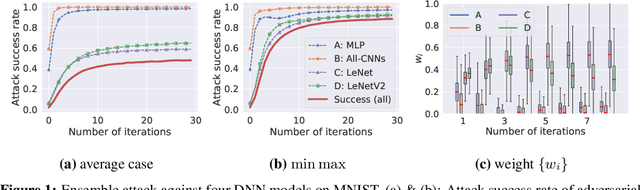
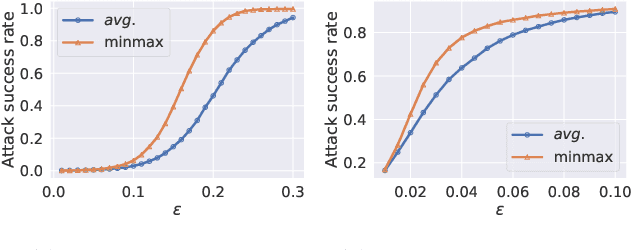
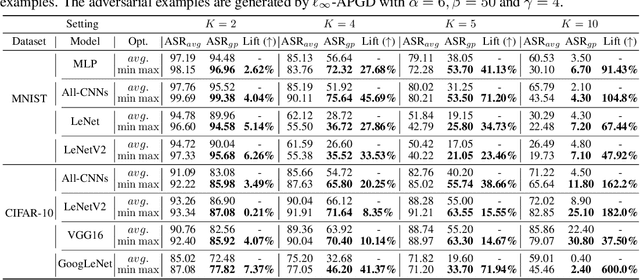
The worst-case training principle that minimizes the maximal adversarial loss, also known as adversarial training (AT), has shown to be a state-of-the-art approach for enhancing adversarial robustness against norm-ball bounded input perturbations. Nonetheless, min-max optimization beyond the purpose of AT has not been rigorously explored in the research of adversarial attack and defense. In particular, given a set of risk sources (domains), minimizing the maximal loss induced from the domain set can be reformulated as a general min-max problem that is different from AT, since the maximization is taken over the probability simplex of the domain set. Examples of this general formulation include attacking model ensembles, devising universal perturbation to input samples or data transformations, and generalized AT over multiple norm-ball threat models. We show that these problems can be solved under a unified and theoretically principled min-max optimization framework. Our proposed approach leads to substantial performance improvement over the uniform averaging strategy in four different tasks. Moreover, we show how the self-adjusted weighting factors of the probability simplex from our proposed algorithms can be used to explain the importance of different attack and defense models.
One Bit Matters: Understanding Adversarial Examples as the Abuse of Redundancy
Oct 23, 2018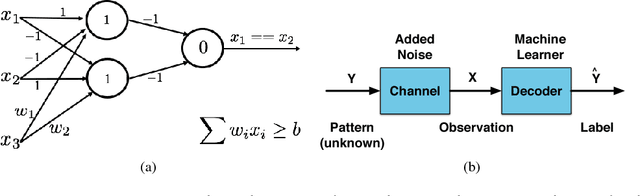
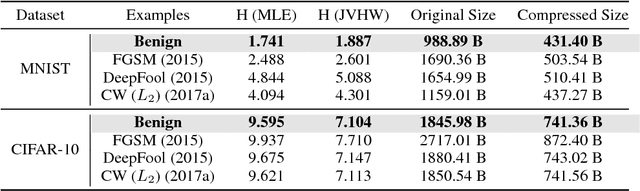
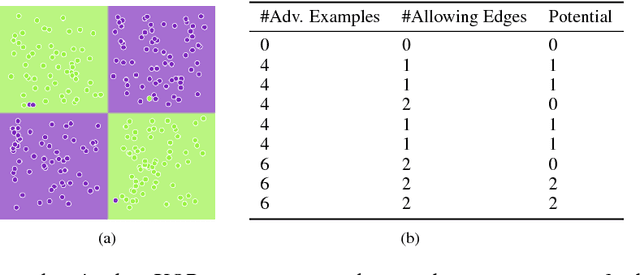
Despite the great success achieved in machine learning (ML), adversarial examples have caused concerns with regards to its trustworthiness: A small perturbation of an input results in an arbitrary failure of an otherwise seemingly well-trained ML model. While studies are being conducted to discover the intrinsic properties of adversarial examples, such as their transferability and universality, there is insufficient theoretic analysis to help understand the phenomenon in a way that can influence the design process of ML experiments. In this paper, we deduce an information-theoretic model which explains adversarial attacks as the abuse of feature redundancies in ML algorithms. We prove that feature redundancy is a necessary condition for the existence of adversarial examples. Our model helps to explain some major questions raised in many anecdotal studies on adversarial examples. Our theory is backed up by empirical measurements of the information content of benign and adversarial examples on both image and text datasets. Our measurements show that typical adversarial examples introduce just enough redundancy to overflow the decision making of an ML model trained on corresponding benign examples. We conclude with actionable recommendations to improve the robustness of machine learners against adversarial examples.
Reinforcement Learning with Perturbed Rewards
Oct 05, 2018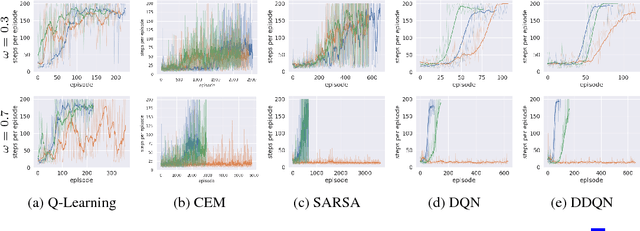
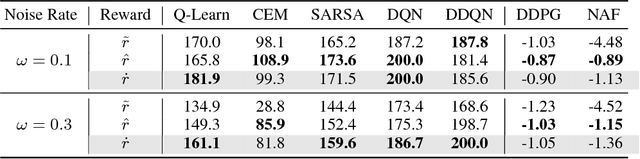
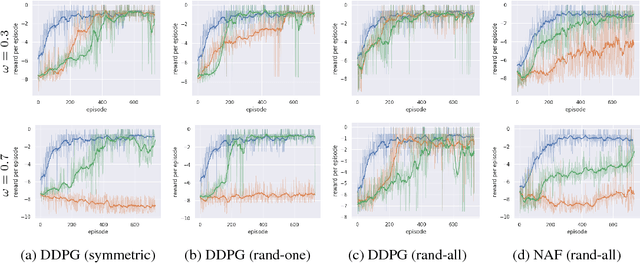
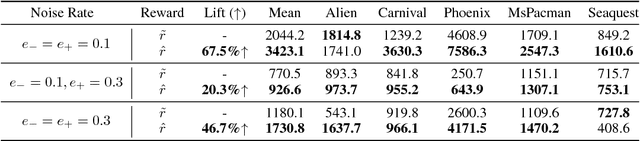
Recent studies have shown the vulnerability of reinforcement learning (RL) models in noisy settings. The sources of noises differ across scenarios. For instance, in practice, the observed reward channel is often subject to noise (e.g., when observed rewards are collected through sensors), and thus observed rewards may not be credible as a result. Also, in applications such as robotics, a deep reinforcement learning (DRL) algorithm can be manipulated to produce arbitrary errors. In this paper, we consider noisy RL problems where observed rewards by RL agents are generated with a reward confusion matrix. We call such observed rewards as perturbed rewards. We develop an unbiased reward estimator aided robust RL framework that enables RL agents to learn in noisy environments while observing only perturbed rewards. Our framework draws upon approaches for supervised learning with noisy data. The core ideas of our solution include estimating a reward confusion matrix and defining a set of unbiased surrogate rewards. We prove the convergence and sample complexity of our approach. Extensive experiments on different DRL platforms show that policies based on our estimated surrogate reward can achieve higher expected rewards, and converge faster than existing baselines. For instance, the state-of-the-art PPO algorithm is able to obtain 67.5% and 46.7% improvements in average on five Atari games, when the error rates are 10% and 30% respectively.
Multiple Character Embeddings for Chinese Word Segmentation
Oct 02, 2018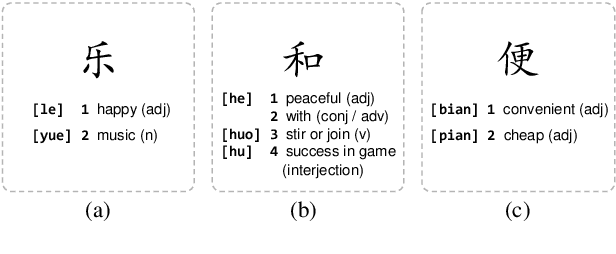
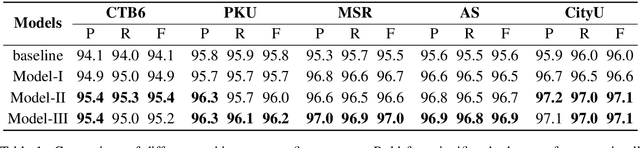
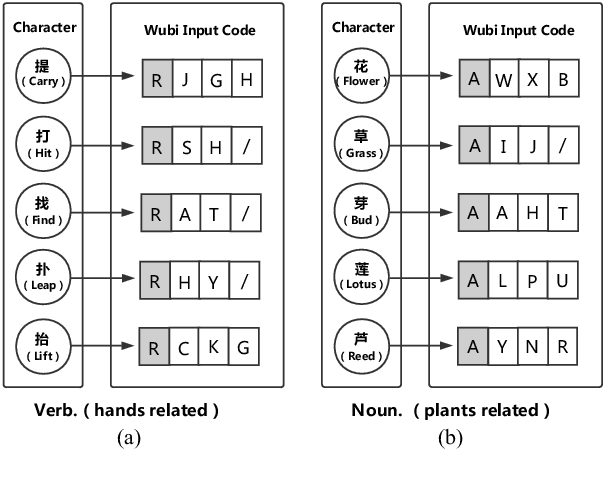
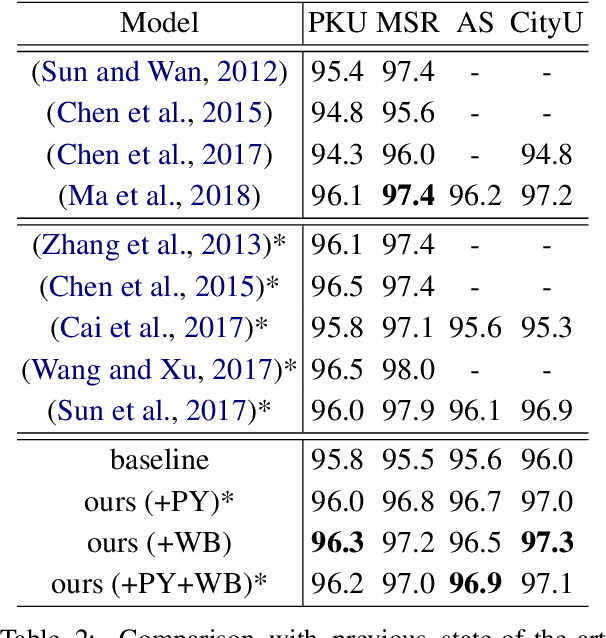
Chinese word segmentation (CWS) is often regarded as a character-based sequence labeling task in most current works which have achieved great performance by leveraging powerful neural networks. However, these works neglect an important clue: Chinese characters contain both semantic and phonetic meanings. In this paper, we introduce multiple character embeddings including Pinyin Romanization and Wubi Input, both of which are easily accessible and effective in depicting semantics of characters. To fully leverage them, we propose a novel shared Bi-LSTM-CRF model, which fuses multiple features efficiently. Extensive experiments on five corpora demonstrate that extra embeddings help obtain a significant improvement. Specifically, we achieve the state-of-the-art performance in AS and CityU datasets with F1 scores 96.9 and 97.3, respectively without leveraging any external resources.
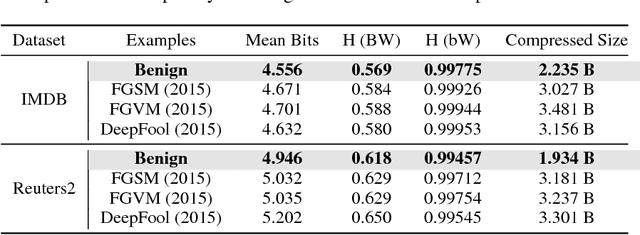
The Helmholtz Method: Using Perceptual Compression to Reduce Machine Learning Complexity
Jul 10, 2018


This paper proposes a fundamental answer to a frequently asked question in multimedia computing and machine learning: Do artifacts from perceptual compression contribute to error in the machine learning process and if so, how much? Our approach to the problem is a reinterpretation of the Helmholtz Free Energy formula from physics to explain the relationship between content and noise when using sensors (such as cameras or microphones) to capture multimedia data. The reinterpretation allows a bit-measurement of the noise contained in images, audio, and video by combining a classifier with perceptual compression, such as JPEG or MP3. Our experiments on CIFAR-10 as well as Fraunhofer's IDMT-SMT-Audio-Effects dataset indicate that, at the right quality level, perceptual compression is actually not harmful but contributes to a significant reduction of complexity of the machine learning process. That is, our noise quantification method can be used to speed up the training of deep learning classifiers significantly while maintaining, or sometimes even improving, overall classification accuracy. Moreover, our results provide insights into the reasons for the success of deep learning.