 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamBench++: A Human-Aligned Benchmark for Personalized Image Generation
Jun 24, 2024



Personalized image generation holds great promise in assisting humans in everyday work and life due to its impressive function in creatively generating personalized content. However, current evaluations either are automated but misalign with humans or require human evaluations that are time-consuming and expensive. In this work, we present DreamBench++, a human-aligned benchmark automated by advanced multimodal GPT models. Specifically, we systematically design the prompts to let GPT be both human-aligned and self-aligned, empowered with task reinforcement. Further, we construct a comprehensive dataset comprising diverse images and prompts. By benchmarking 7 modern generative models, we demonstrate that DreamBench++ results in significantly more human-aligned evaluation, helping boost the community with innovative findings.
NutePrune: Efficient Progressive Pruning with Numerous Teachers for Large Language Models
Feb 15, 2024



The considerable size of Large Language Models (LLMs) presents notable deployment challenges, particularly on resource-constrained hardware. Structured pruning, offers an effective means to compress LLMs, thereby reducing storage costs and enhancing inference speed for more efficient utilization. In this work, we study data-efficient and resource-efficient structure pruning methods to obtain smaller yet still powerful models. Knowledge Distillation is well-suited for pruning, as the intact model can serve as an excellent teacher for pruned students. However, it becomes challenging in the context of LLMs due to memory constraints. To address this, we propose an efficient progressive Numerous-teacher pruning method (NutePrune). NutePrune mitigates excessive memory costs by loading only one intact model and integrating it with various masks and LoRA modules, enabling it to seamlessly switch between teacher and student roles. This approach allows us to leverage numerous teachers with varying capacities to progressively guide the pruned model, enhancing overall performance. Extensive experiments across various tasks demonstrate the effectiveness of NutePrune. In LLaMA-7B zero-shot experiments, NutePrune retains 97.17% of the performance of the original model at 20% sparsity and 95.07% at 25% sparsity.
Parameter-efficient is not sufficient: Exploring Parameter, Memory, and Time Efficient Adapter Tuning for Dense Predictions
Jun 16, 2023Pre-training & fine-tuning is a prevalent paradigm in computer vision (CV). Recently, parameter-efficient transfer learning (PETL) methods have shown promising performance in transferring knowledge from pre-trained models with only a few trainable parameters. Despite their success, the existing PETL methods in CV can be computationally expensive and require large amounts of memory and time cost during training, which limits low-resource users from conducting research and applications on large models. In this work, we propose Parameter, Memory, and Time Efficient Visual Adapter ($\mathrm{E^3VA}$) tuning to address this issue. We provide a gradient backpropagation highway for low-rank adapters which removes large gradient computations for the frozen pre-trained parameters, resulting in substantial savings of training memory and training time. Furthermore, we optimise the $\mathrm{E^3VA}$ structure for dense predictions tasks to promote model performance. Extensive experiments on COCO, ADE20K, and Pascal VOC benchmarks show that $\mathrm{E^3VA}$ can save up to 62.2% training memory and 26.2% training time on average, while achieving comparable performance to full fine-tuning and better performance than most PETL methods. Note that we can even train the Swin-Large-based Cascade Mask RCNN on GTX 1080Ti GPUs with less than 1.5% trainable parameters.
Time-aware Graph Structure Learning via Sequence Prediction on Temporal Graphs
Jun 13, 2023Temporal Graph Learning, which aims to model the time-evolving nature of graphs, has gained increasing attention and achieved remarkable performance recently. However, in reality, graph structures are often incomplete and noisy, which hinders temporal graph networks (TGNs) from learning informative representations. Graph contrastive learning uses data augmentation to generate plausible variations of existing data and learn robust representations. However, rule-based augmentation approaches may be suboptimal as they lack learnability and fail to leverage rich information from downstream tasks. To address these issues, we propose a Time-aware Graph Structure Learning (TGSL) approach via sequence prediction on temporal graphs, which learns better graph structures for downstream tasks through adding potential temporal edges. In particular, it predicts time-aware context embedding based on previously observed interactions and uses the Gumble-Top-K to select the closest candidate edges to this context embedding. Additionally, several candidate sampling strategies are proposed to ensure both efficiency and diversity. Furthermore, we jointly learn the graph structure and TGNs in an end-to-end manner and perform inference on the refined graph. Extensive experiments on temporal link prediction benchmarks demonstrate that TGSL yields significant gains for the popular TGNs such as TGAT and GraphMixer, and it outperforms other contrastive learning methods on temporal graphs. We will release the code in the future.
AdapterGNN: Efficient Delta Tuning Improves Generalization Ability in Graph Neural Networks
Apr 19, 2023



Fine-tuning pre-trained models has recently yielded remarkable performance gains in graph neural networks (GNNs). In addition to pre-training techniques, inspired by the latest work in the natural language fields, more recent work has shifted towards applying effective fine-tuning approaches, such as parameter-efficient tuning (delta tuning). However, given the substantial differences between GNNs and transformer-based models, applying such approaches directly to GNNs proved to be less effective. In this paper, we present a comprehensive comparison of delta tuning techniques for GNNs and propose a novel delta tuning method specifically designed for GNNs, called AdapterGNN. AdapterGNN preserves the knowledge of the large pre-trained model and leverages highly expressive adapters for GNNs, which can adapt to downstream tasks effectively with only a few parameters, while also improving the model's generalization ability on the downstream tasks. Extensive experiments show that AdapterGNN achieves higher evaluation performance (outperforming full fine-tuning by 1.4% and 5.5% in the chemistry and biology domains respectively, with only 5% of its parameters tuned) and lower generalization gaps compared to full fine-tuning. Moreover, we empirically show that a larger GNN model can have a worse generalization ability, which differs from the trend observed in large language models. We have also provided a theoretical justification for delta tuning can improve the generalization ability of GNNs by applying generalization bounds.
An Automated Question-Answering Framework Based on Evolution Algorithm
Jan 26, 2022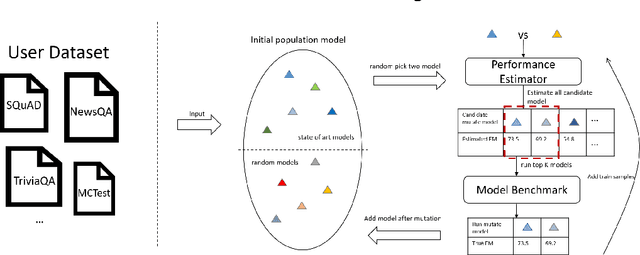

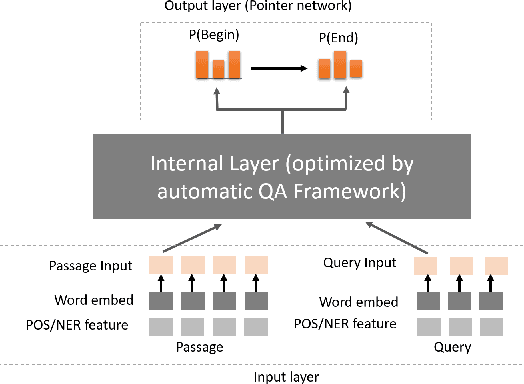
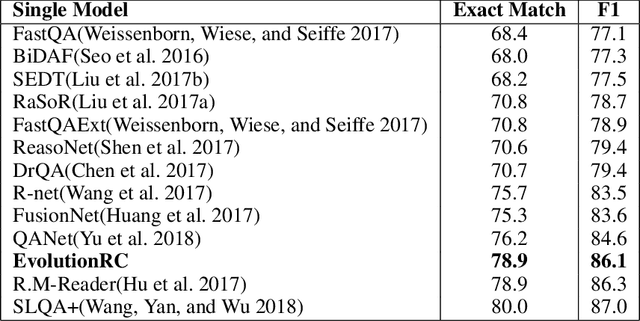
Building a deep learning model for a Question-Answering (QA) task requires a lot of human effort, it may need several months to carefully tune various model architectures and find a best one. It's even harder to find different excellent models for multiple datasets. Recent works show that the best model structure is related to the dataset used, and one single model cannot adapt to all tasks. In this paper, we propose an automated Question-Answering framework, which could automatically adjust network architecture for multiple datasets. Our framework is based on an innovative evolution algorithm, which is stable and suitable for multiple dataset scenario. The evolution algorithm for search combine prior knowledge into initial population and use a performance estimator to avoid inefficient mutation by predicting the performance of candidate model architecture. The prior knowledge used in initial population could improve the final result of the evolution algorithm. The performance estimator could quickly filter out models with bad performance in population as the number of trials increases, to speed up the convergence. Our framework achieves 78.9 EM and 86.1 F1 on SQuAD 1.1, 69.9 EM and 72.5 F1 on SQuAD 2.0. On NewsQA dataset, the found model achieves 47.0 EM and 62.9 F1.
Learning Multi-granularity User Intent Unit for Session-based Recommendation
Jan 10, 2022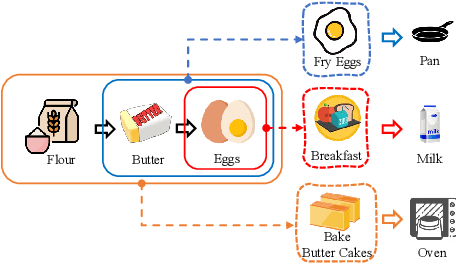
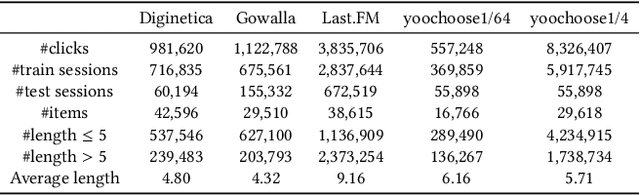
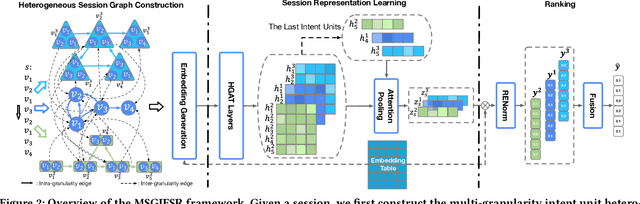
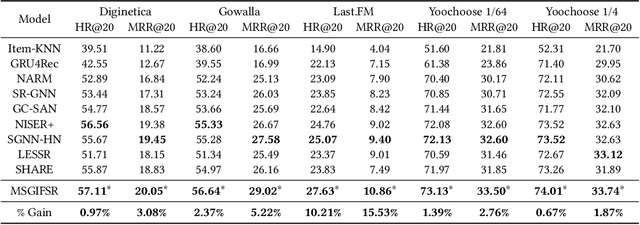
Session-based recommendation aims to predict a user's next action based on previous actions in the current session. The major challenge is to capture authentic and complete user preferences in the entire session. Recent work utilizes graph structure to represent the entire session and adopts Graph Neural Network to encode session information. This modeling choice has been proved to be effective and achieved remarkable results. However, most of the existing studies only consider each item within the session independently and do not capture session semantics from a high-level perspective. Such limitation often leads to severe information loss and increases the difficulty of capturing long-range dependencies within a session. Intuitively, compared with individual items, a session snippet, i.e., a group of locally consecutive items, is able to provide supplemental user intents which are hardly captured by existing methods. In this work, we propose to learn multi-granularity consecutive user intent unit to improve the recommendation performance. Specifically, we creatively propose Multi-granularity Intent Heterogeneous Session Graph which captures the interactions between different granularity intent units and relieves the burden of long-dependency. Moreover, we propose the Intent Fusion Ranking module to compose the recommendation results from various granularity user intents. Compared with current methods that only leverage intents from individual items, IFR benefits from different granularity user intents to generate more accurate and comprehensive session representation, thus eventually boosting recommendation performance. We conduct extensive experiments on five session-based recommendation datasets and the results demonstrate the effectiveness of our method.
Creating Training Sets via Weak Indirect Supervision
Oct 07, 2021
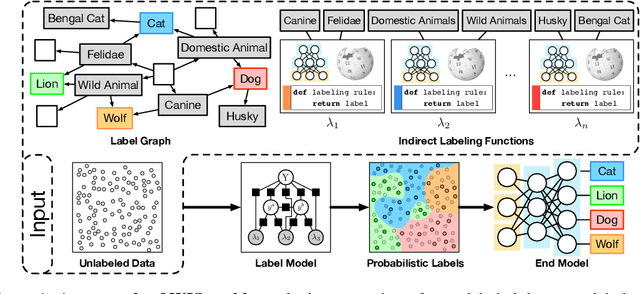
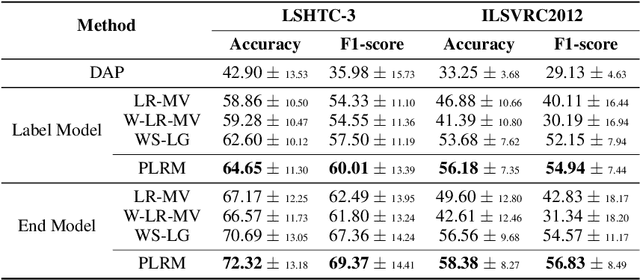
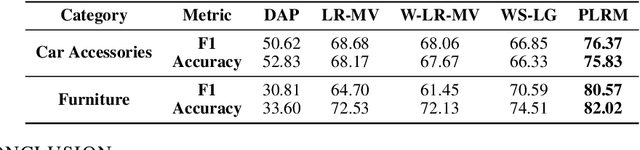
Creating labeled training sets has become one of the major roadblocks in machine learning. To address this, recent Weak Supervision (WS) frameworks synthesize training labels from multiple potentially noisy supervision sources. However, existing frameworks are restricted to supervision sources that share the same output space as the target task. To extend the scope of usable sources, we formulate Weak Indirect Supervision (WIS), a new research problem for automatically synthesizing training labels based on indirect supervision sources that have different output label spaces. To overcome the challenge of mismatched output spaces, we develop a probabilistic modeling approach, PLRM, which uses user-provided label relations to model and leverage indirect supervision sources. Moreover, we provide a theoretically-principled test of the distinguishability of PLRM for unseen labels, along with an generalization bound. On both image and text classification tasks as well as an industrial advertising application, we demonstrate the advantages of PLRM by outperforming baselines by a margin of 2%-9%.
Graph Pointer Neural Networks
Oct 03, 2021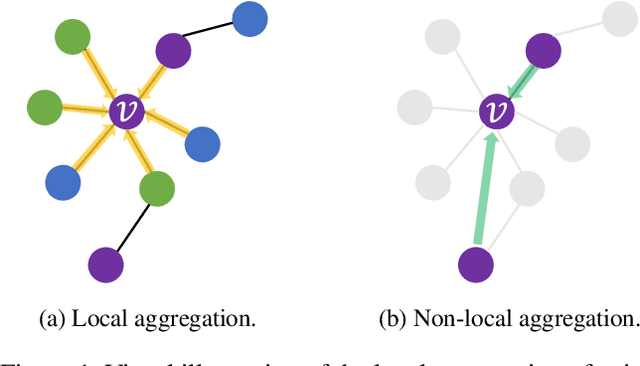
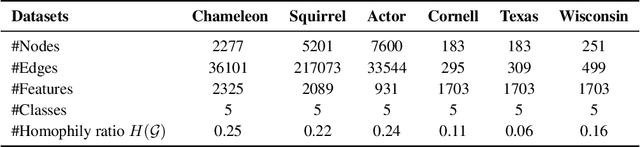
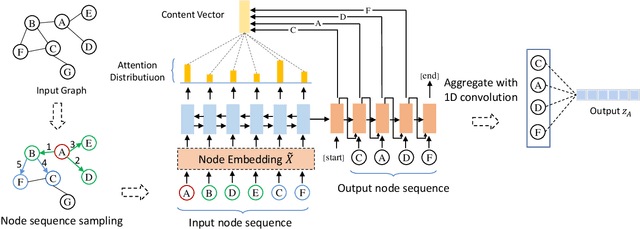
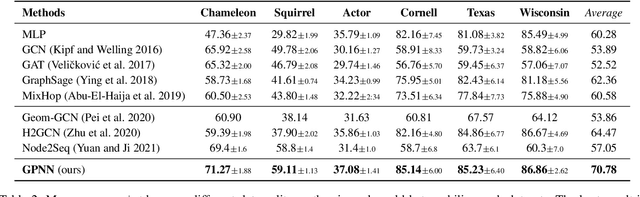
Graph Neural Networks (GNNs) have shown advantages in various graph-based applications. Most existing GNNs assume strong homophily of graph structure and apply permutation-invariant local aggregation of neighbors to learn a representation for each node. However, they fail to generalize to heterophilic graphs, where most neighboring nodes have different labels or features, and the relevant nodes are distant. Few recent studies attempt to address this problem by combining multiple hops of hidden representations of central nodes (i.e., multi-hop-based approaches) or sorting the neighboring nodes based on attention scores (i.e., ranking-based approaches). As a result, these approaches have some apparent limitations. On the one hand, multi-hop-based approaches do not explicitly distinguish relevant nodes from a large number of multi-hop neighborhoods, leading to a severe over-smoothing problem. On the other hand, ranking-based models do not joint-optimize node ranking with end tasks and result in sub-optimal solutions. In this work, we present Graph Pointer Neural Networks (GPNN) to tackle the challenges mentioned above. We leverage a pointer network to select the most relevant nodes from a large amount of multi-hop neighborhoods, which constructs an ordered sequence according to the relationship with the central node. 1D convolution is then applied to extract high-level features from the node sequence. The pointer-network-based ranker in GPNN is joint-optimized with other parts in an end-to-end manner. Extensive experiments are conducted on six public node classification datasets with heterophilic graphs. The results show that GPNN significantly improves the classification performance of state-of-the-art methods. In addition, analyses also reveal the privilege of the proposed GPNN in filtering out irrelevant neighbors and reducing over-smoothing.
Attentive Knowledge-aware Graph Convolutional Networks with Collaborative Guidance for Recommendation
Sep 05, 2021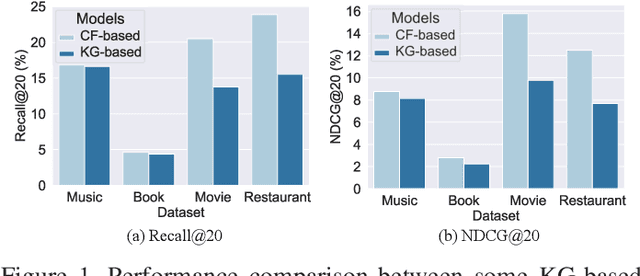
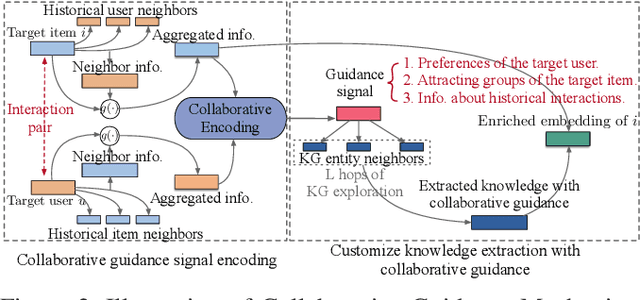
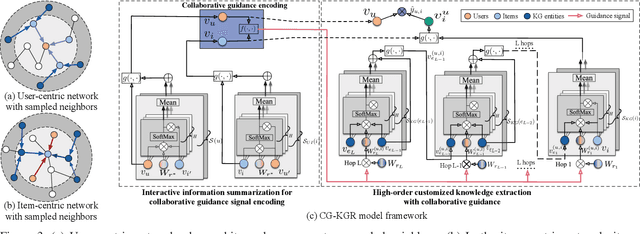
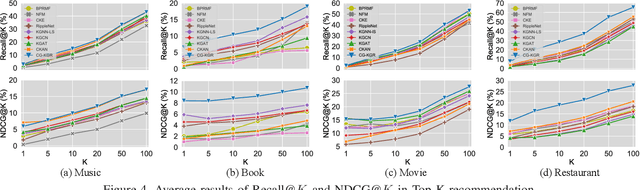
To alleviate data sparsity and cold-start problems of traditional recommender systems (RSs), incorporating knowledge graphs (KGs) to supplement auxiliary information has attracted considerable attention recently. However, simply integrating KGs in current KG-based RS models is not necessarily a guarantee to improve the recommendation performance, which may even weaken the holistic model capability. This is because the construction of these KGs is independent of the collection of historical user-item interactions; hence, information in these KGs may not always be helpful for recommendation to all users. In this paper, we propose attentive Knowledge-aware Graph convolutional networks with Collaborative Guidance for personalized Recommendation (CG-KGR). CG-KGR is a novel knowledge-aware recommendation model that enables ample and coherent learning of KGs and user-item interactions, via our proposed Collaborative Guidance Mechanism. Specifically, CG-KGR first encapsulates historical interactions to interactive information summarization. Then CG-KGR utilizes it as guidance to extract information out of KGs, which eventually provides more precise personalized recommendation. We conduct extensive experiments on four real-world datasets over two recommendation tasks, i.e., Top-K recommendation and Click-Through rate (CTR) prediction. The experimental results show that the CG-KGR model significantly outperforms recent state-of-the-art models by 4.0-53.2% and 0.4-3.2%, in terms of Recall metric on Top-K recommendation and AUC on CTR prediction, respectively.