 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransTab: Learning Transferable Tabular Transformers Across Tables
May 19, 2022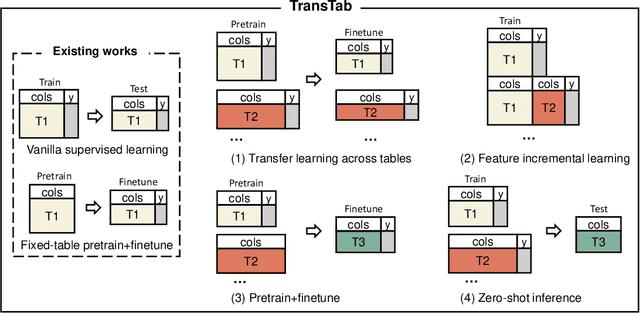
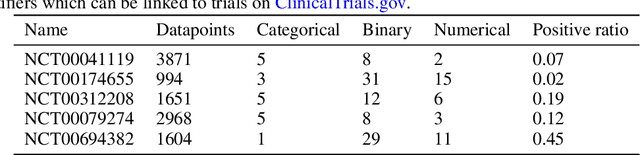
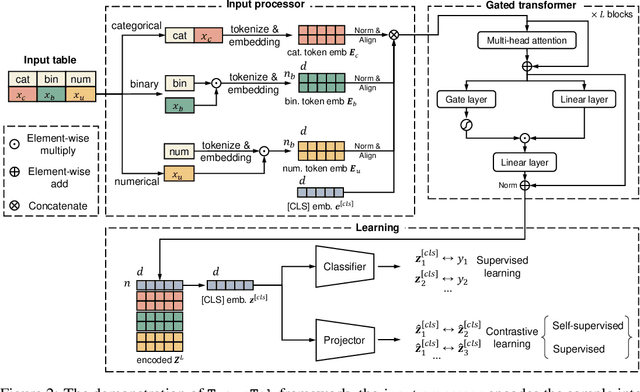
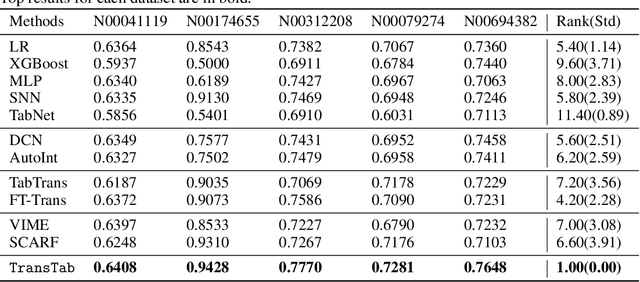
Tabular data (or tables) are the most widely used data format in machine learning (ML). However, ML models often assume the table structure keeps fixed in training and testing. Before ML modeling, heavy data cleaning is required to merge disparate tables with different columns. This preprocessing often incurs significant data waste (e.g., removing unmatched columns and samples). How to learn ML models from multiple tables with partially overlapping columns? How to incrementally update ML models as more columns become available over time? Can we leverage model pretraining on multiple distinct tables? How to train an ML model which can predict on an unseen table? To answer all those questions, we propose to relax fixed table structures by introducing a Transferable Tabular Transformer (TransTab) for tables. The goal of TransTab is to convert each sample (a row in the table) to a generalizable embedding vector, and then apply stacked transformers for feature encoding. One methodology insight is combining column description and table cells as the raw input to a gated transformer model. The other insight is to introduce supervised and self-supervised pretraining to improve model performance. We compare TransTab with multiple baseline methods on diverse benchmark datasets and five oncology clinical trial datasets. Overall, TransTab ranks 1.00, 1.00, 1.78 out of 12 methods in supervised learning, feature incremental learning, and transfer learning scenarios, respectively; and the proposed pretraining leads to 2.3\% AUC lift on average over the supervised learning.}
GOCPT: Generalized Online Canonical Polyadic Tensor Factorization and Completion
May 08, 2022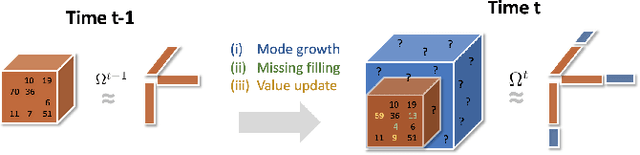
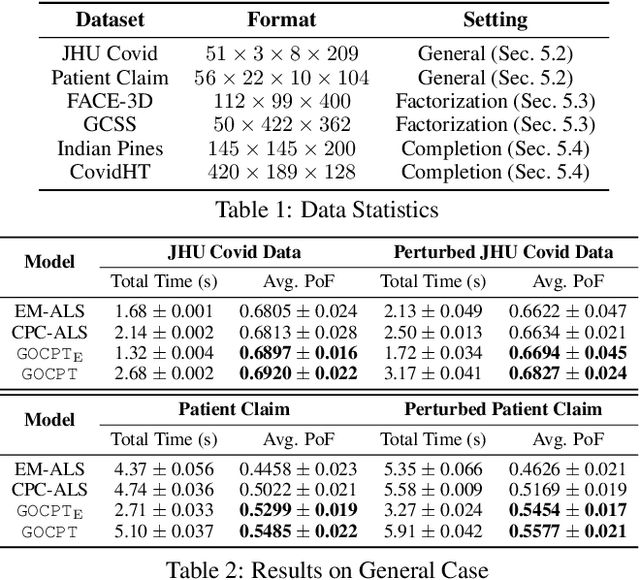
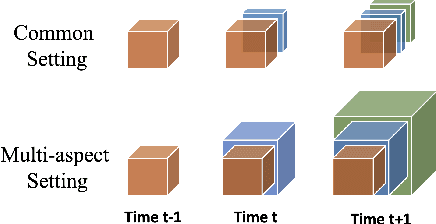
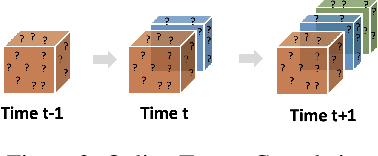
Low-rank tensor factorization or completion is well-studied and applied in various online settings, such as online tensor factorization (where the temporal mode grows) and online tensor completion (where incomplete slices arrive gradually). However, in many real-world settings, tensors may have more complex evolving patterns: (i) one or more modes can grow; (ii) missing entries may be filled; (iii) existing tensor elements can change. Existing methods cannot support such complex scenarios. To fill the gap, this paper proposes a Generalized Online Canonical Polyadic (CP) Tensor factorization and completion framework (named GOCPT) for this general setting, where we maintain the CP structure of such dynamic tensors during the evolution. We show that existing online tensor factorization and completion setups can be unified under the GOCPT framework. Furthermore, we propose a variant, named GOCPTE, to deal with cases where historical tensor elements are unavailable (e.g., privacy protection), which achieves similar fitness as GOCPT but with much less computational cost. Experimental results demonstrate that our GOCPT can improve fitness by up to 2:8% on the JHU Covid data and 9:2% on a proprietary patient claim dataset over baselines. Our variant GOCPTE shows up to 1:2% and 5:5% fitness improvement on two datasets with about 20% speedup compared to the best model.
Clinical trial site matching with improved diversity using fair policy learning
Apr 13, 2022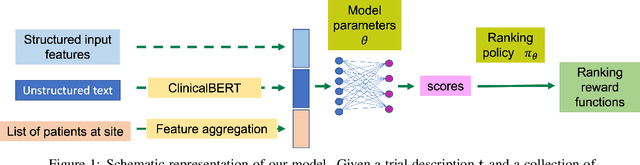
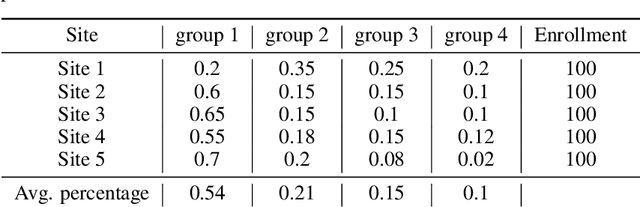
The ongoing pandemic has highlighted the importance of reliable and efficient clinical trials in healthcare. Trial sites, where the trials are conducted, are chosen mainly based on feasibility in terms of medical expertise and access to a large group of patients. More recently, the issue of diversity and inclusion in clinical trials is gaining importance. Different patient groups may experience the effects of a medical drug/ treatment differently and hence need to be included in the clinical trials. These groups could be based on ethnicity, co-morbidities, age, or economic factors. Thus, designing a method for trial site selection that accounts for both feasibility and diversity is a crucial and urgent goal. In this paper, we formulate this problem as a ranking problem with fairness constraints. Using principles of fairness in machine learning, we learn a model that maps a clinical trial description to a ranked list of potential trial sites. Unlike existing fairness frameworks, the group membership of each trial site is non-binary: each trial site may have access to patients from multiple groups. We propose fairness criteria based on demographic parity to address such a multi-group membership scenario. We test our method on 480 real-world clinical trials and show that our model results in a list of potential trial sites that provides access to a diverse set of patients while also ensuing a high number of enrolled patients.
MolGenSurvey: A Systematic Survey in Machine Learning Models for Molecule Design
Mar 28, 2022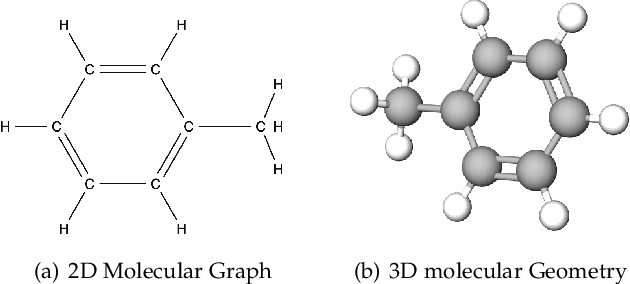

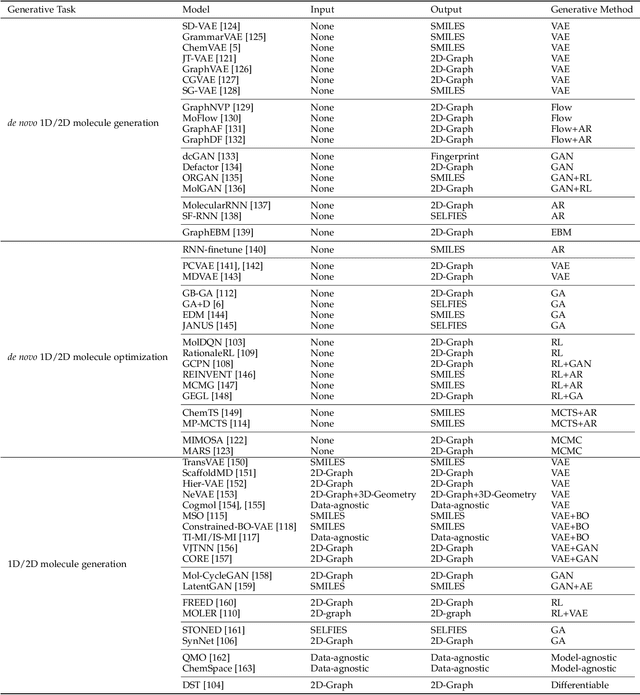
Molecule design is a fundamental problem in molecular science and has critical applications in a variety of areas, such as drug discovery, material science, etc. However, due to the large searching space, it is impossible for human experts to enumerate and test all molecules in wet-lab experiments. Recently, with the rapid development of machine learning methods, especially generative methods, molecule design has achieved great progress by leveraging machine learning models to generate candidate molecules. In this paper, we systematically review the most relevant work in machine learning models for molecule design. We start with a brief review of the mainstream molecule featurization and representation methods (including 1D string, 2D graph, and 3D geometry) and general generative methods (deep generative and combinatorial optimization methods). Then we summarize all the existing molecule design problems into several venues according to the problem setup, including input, output types and goals. Finally, we conclude with the open challenges and point out future opportunities of machine learning models for molecule design in real-world applications.
Why Interpretable Causal Inference is Important for High-Stakes Decision Making for Critically Ill Patients and How To Do It
Mar 09, 2022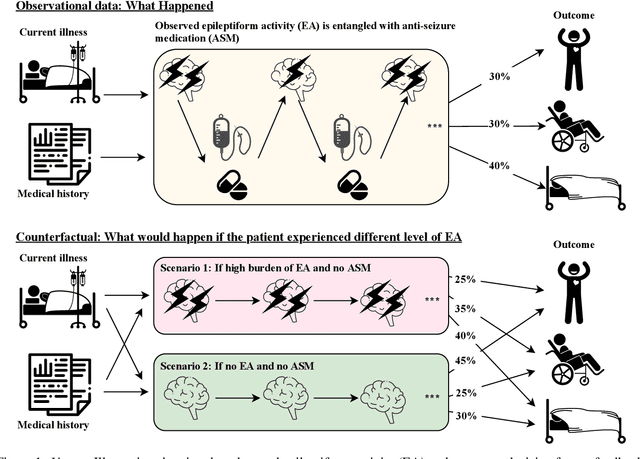
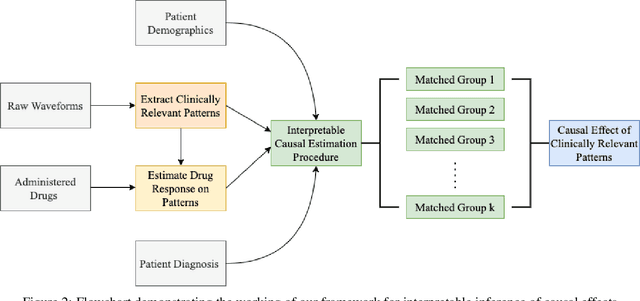
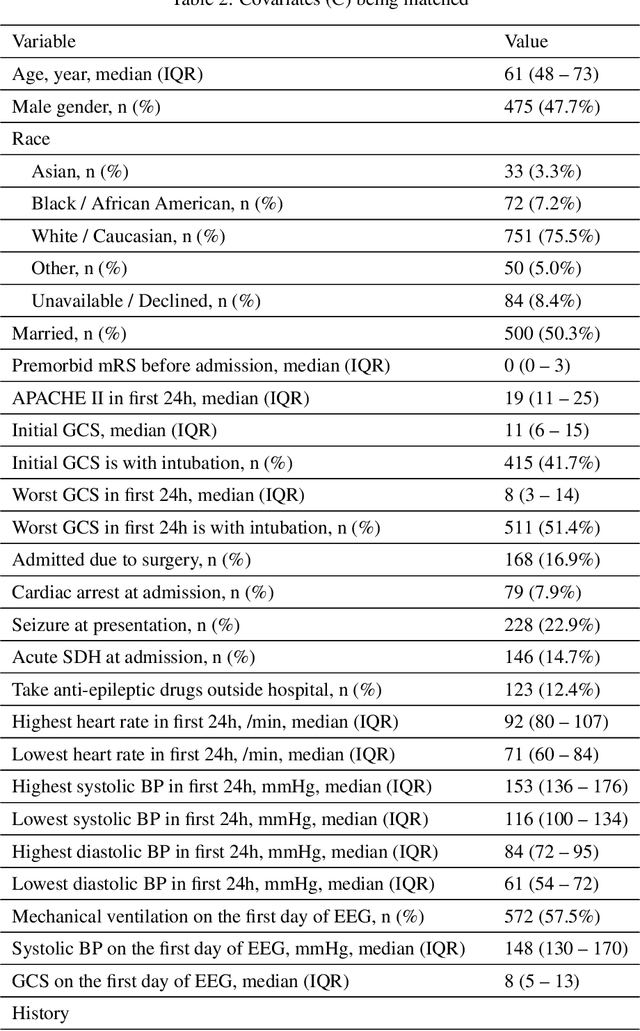
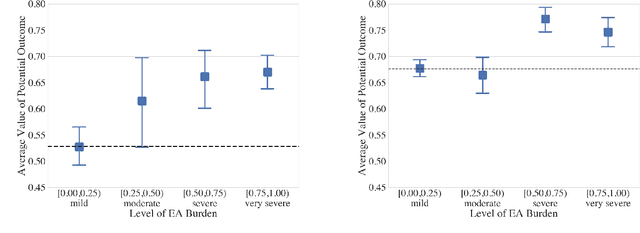
Many fundamental problems affecting the care of critically ill patients lead to similar analytical challenges: physicians cannot easily estimate the effects of at-risk medical conditions or treatments because the causal effects of medical conditions and drugs are entangled. They also cannot easily perform studies: there are not enough high-quality data for high-dimensional observational causal inference, and RCTs often cannot ethically be conducted. However, mechanistic knowledge is available, including how drugs are absorbed into the body, and the combination of this knowledge with the limited data could potentially suffice -- if we knew how to combine them. In this work, we present a framework for interpretable estimation of causal effects for critically ill patients under exactly these complex conditions: interactions between drugs and observations over time, patient data sets that are not large, and mechanistic knowledge that can substitute for lack of data. We apply this framework to an extremely important problem affecting critically ill patients, namely the effect of seizures and other potentially harmful electrical events in the brain (called epileptiform activity -- EA) on outcomes. Given the high stakes involved and the high noise in the data, interpretability is critical for troubleshooting such complex problems. Interpretability of our matched groups allowed neurologists to perform chart reviews to verify the quality of our causal analysis. For instance, our work indicates that a patient who experiences a high level of seizure-like activity (75% high EA burden) and is untreated for a six-hour window, has, on average, a 16.7% increased chance of adverse outcomes such as severe brain damage, lifetime disability, or death. We find that patients with mild but long-lasting EA (average EA burden >= 50%) have their risk of an adverse outcome increased by 11.2%.
AutoMap: Automatic Medical Code Mapping for Clinical Prediction Model Deployment
Mar 04, 2022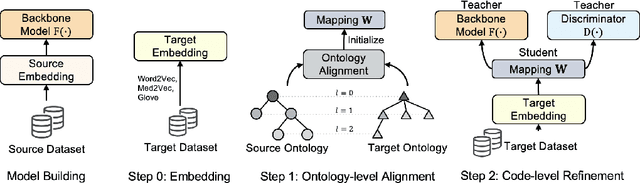
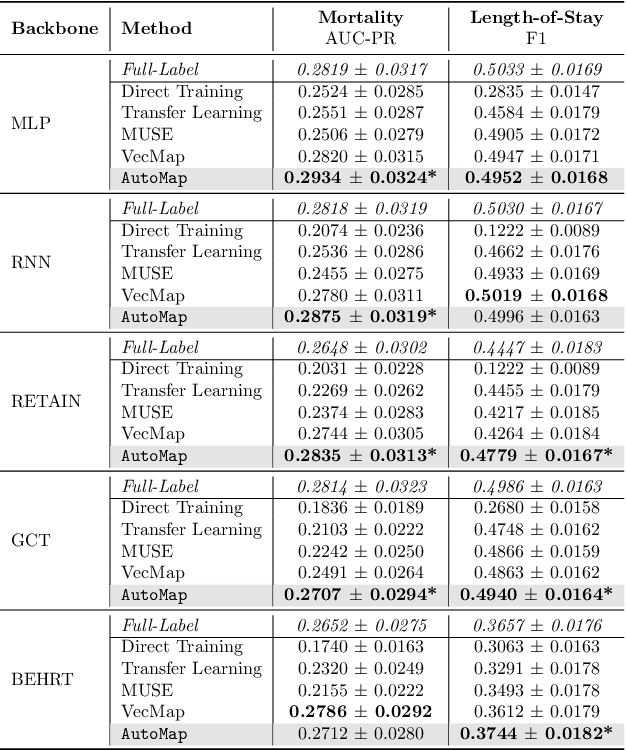
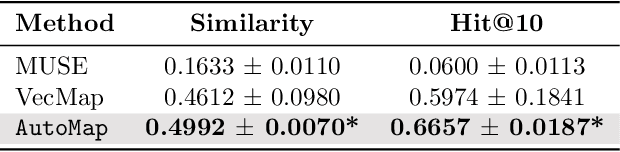
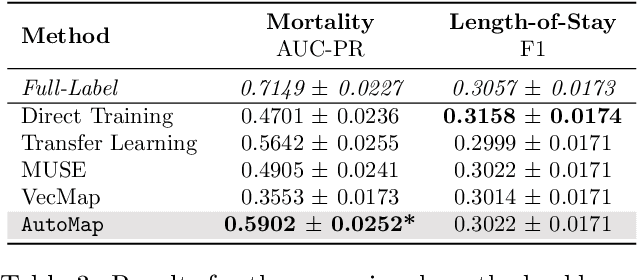
Given a deep learning model trained on data from a source site, how to deploy the model to a target hospital automatically? How to accommodate heterogeneous medical coding systems across different hospitals? Standard approaches rely on existing medical code mapping tools, which have significant practical limitations. To tackle this problem, we propose AutoMap to automatically map the medical codes across different EHR systems in a coarse-to-fine manner: (1) Ontology-level Alignment: We leverage the ontology structure to learn a coarse alignment between the source and target medical coding systems; (2) Code-level Refinement: We refine the alignment at a fine-grained code level for the downstream tasks using a teacher-student framework. We evaluate AutoMap using several deep learning models with two real-world EHR datasets: eICU and MIMIC-III. Results show that AutoMap achieves relative improvements up to 3.9% (AUC-ROC) and 8.7% (AUC-PR) for mortality prediction, and up to 4.7% (AUC-ROC) and 3.7% (F1) for length-of-stay estimation. Further, we show that AutoMap can provide accurate mapping across coding systems. Lastly, we demonstrate that AutoMap can adapt to the two challenging scenarios: (1) mapping between completely different coding systems and (2) between completely different hospitals.
Taking a Step Back with KCal: Multi-Class Kernel-Based Calibration for Deep Neural Networks
Feb 15, 2022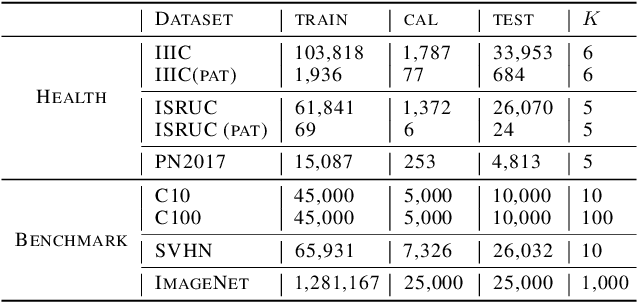
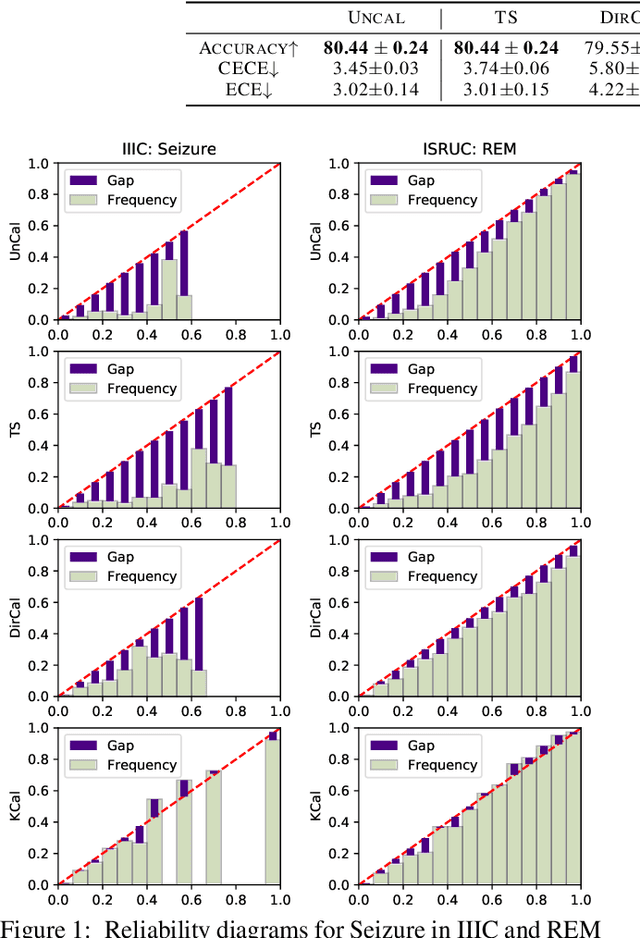
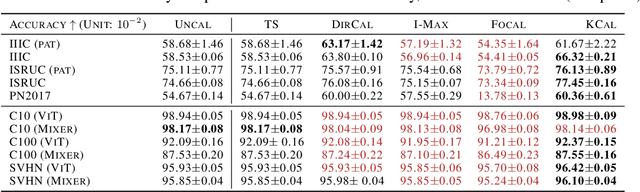
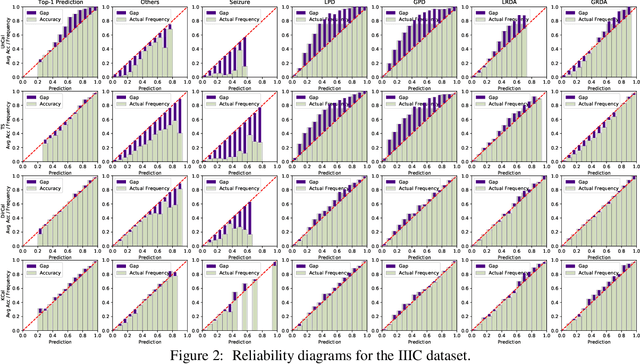
Deep neural network (DNN) classifiers are often overconfident, producing miscalibrated class probabilities. Most existing calibration methods either lack theoretical guarantees for producing calibrated outputs or reduce the classification accuracy in the process. This paper proposes a new Kernel-based calibration method called KCal. Unlike other calibration procedures, KCal does not operate directly on the logits or softmax outputs of the DNN. Instead, it uses the penultimate-layer latent embedding to train a metric space in a supervised manner. In effect, KCal amounts to a supervised dimensionality reduction of the neural network embedding, and generates a prediction using kernel density estimation on a holdout calibration set. We first analyze KCal theoretically, showing that it enjoys a provable asymptotic calibration guarantee. Then, through extensive experiments, we confirm that KCal consistently outperforms existing calibration methods in terms of both the classification accuracy and the (confidence and class-wise) calibration error.
JULIA: Joint Multi-linear and Nonlinear Identification for Tensor Completion
Jan 31, 2022



Tensor completion aims at imputing missing entries from a partially observed tensor. Existing tensor completion methods often assume either multi-linear or nonlinear relationships between latent components. However, real-world tensors have much more complex patterns where both multi-linear and nonlinear relationships may coexist. In such cases, the existing methods are insufficient to describe the data structure. This paper proposes a Joint mUlti-linear and nonLinear IdentificAtion (JULIA) framework for large-scale tensor completion. JULIA unifies the multi-linear and nonlinear tensor completion models with several advantages over the existing methods: 1) Flexible model selection, i.e., it fits a tensor by assigning its values as a combination of multi-linear and nonlinear components; 2) Compatible with existing nonlinear tensor completion methods; 3) Efficient training based on a well-designed alternating optimization approach. Experiments on six real large-scale tensors demonstrate that JULIA outperforms many existing tensor completion algorithms. Furthermore, JULIA can improve the performance of a class of nonlinear tensor completion methods. The results show that in some large-scale tensor completion scenarios, baseline methods with JULIA are able to obtain up to 55% lower root mean-squared-error and save 67% computational complexity.
Self-supervised EEG Representation Learning for Automatic Sleep Staging
Oct 27, 2021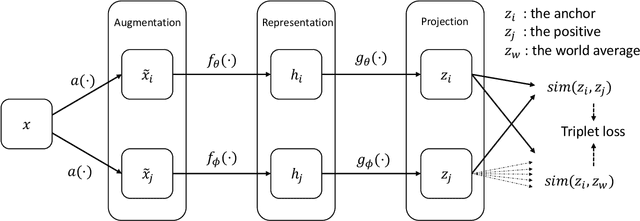
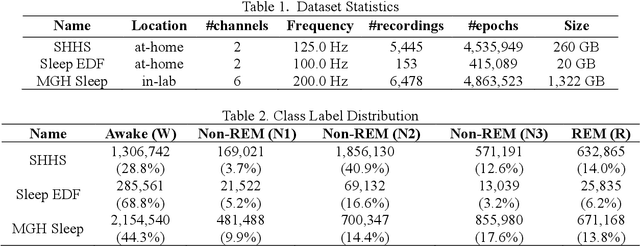
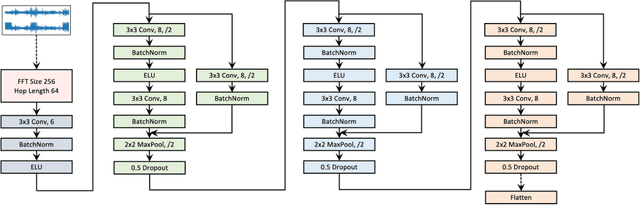
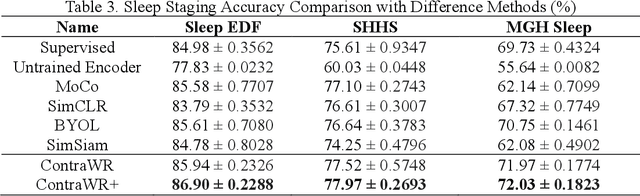
Objective: In this paper, we aim to learn robust vector representations from massive unlabeled Electroencephalogram (EEG) signals, such that the learned representations (1) are expressive enough to replace the raw signals in the sleep staging task; and (2) provide better predictive performance than supervised models in scenarios of fewer labels and noisy samples. Materials and Methods: We propose a self-supervised model, named Contrast with the World Representation (ContraWR), for EEG signal representation learning, which uses global statistics from the dataset to distinguish signals associated with different sleep stages. The ContraWR model is evaluated on three real-world EEG datasets that include both at-home and in-lab recording settings. Results: ContraWR outperforms recent self-supervised learning methods, MoCo, SimCLR, BYOL, SimSiam on the sleep staging task across three datasets. ContraWR also beats supervised learning when fewer training labels are available (e.g., 4% accuracy improvement when less than 2% data is labeled). Moreover, the model provides informative representations in 2D projection. Discussion: The proposed model can be generalized to other unsupervised physiological signal learning tasks. Future directions include exploring task-specific data augmentations and combining self-supervised with supervised methods, building upon the initial success of self-supervised learning in this paper. Conclusions: We show that ContraWR is robust to noise and can provide high-quality EEG representations for downstream prediction tasks. In low-label scenarios (e.g., only 2% data has labels), ContraWR shows much better predictive power (e.g., 4% improvement on sleep staging accuracy) than supervised baselines.
PAC-Bayes Information Bottleneck
Oct 04, 2021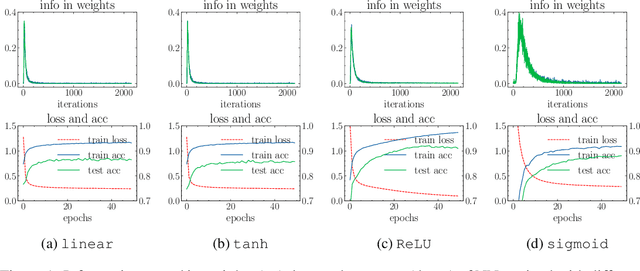
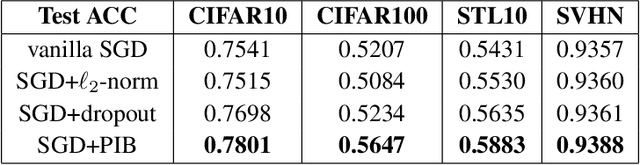
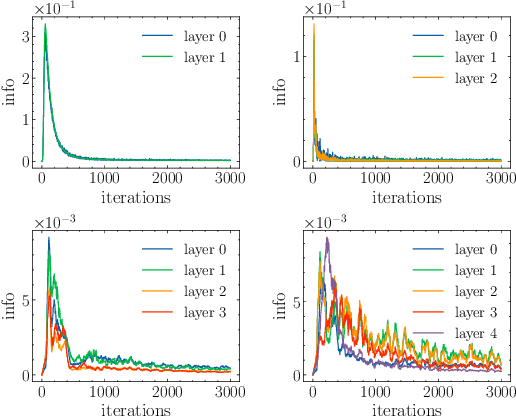
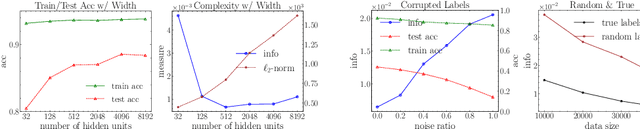
Information bottleneck (IB) depicts a trade-off between the accuracy and conciseness of encoded representations. IB has succeeded in explaining the objective and behavior of neural networks (NNs) as well as learning better representations. However, there are still critics of the universality of IB, e.g., phase transition usually fades away, representation compression is not causally related to generalization, and IB is trivial in deterministic cases. In this work, we build a new IB based on the trade-off between the accuracy and complexity of learned weights of NNs. We argue that this new IB represents a more solid connection to the objective of NNs since the information stored in weights (IIW) bounds their PAC-Bayes generalization capability, hence we name it as PAC-Bayes IB (PIB). On IIW, we can identify the phase transition phenomenon in general cases and solidify the causality between compression and generalization. We then derive a tractable solution of PIB and design a stochastic inference algorithm by Markov chain Monte Carlo sampling. We empirically verify our claims through extensive experiments. We also substantiate the superiority of the proposed algorithm on training NNs.