 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Neural Combinatorial Optimization via Evolving Programmatic Bottlenecks
Jun 18, 2026Neural Combinatorial Optimization (NCO) achieves strong performance, yet its black-box nature remains a key roadblock to deployment and scientific diagnosis. Standard interpretability tools, such as Concept Bottleneck Models (CBMs), are ill-equipped for NCO, whose decisions are dynamic, state-dependent, and lack proper concept vocabulary definition. To close this gap, we introduce Evolving Programmatic Bottlenecks (EPB), to our knowledge, the first framework for interpreting NCO policies by distilling black-box NCO models into human-readable program portfolios. EPB employs an LLM to autonomously evolve a bank of programs, where each program's per-step action distribution serves as the bottleneck. EPB works through an iterative framework: Block I fixes program bank capacity and introduces a hybrid textual-numerical gradient descent scheme that couples numerical gradients for student router updates and textual gradients for LLM-based program revision; Block II dynamically adapts bank capacity via fault-targeted expansion and redundancy pruning. Extensive experiments demonstrate EPB's effectiveness and broad applicability, where the distilled program portfolios largely match original performance. EPB also reveals that NCO behavior shifts across optimization stages and can be approximated as a composition of classic heuristic variants. Our work advances interpretable NCO and establishes EPB as a promising tool for interpreting sequential decision-making models.
Learning Scenario Reduction for Two-Stage Robust Optimization with Discrete Uncertainty
May 14, 2026Two-Stage Robust Optimization (2RO) with discrete uncertainty is challenging, often rendering exact solutions prohibitive. Scenario reduction alleviates this issue by selecting a small, representative subset of scenarios to enable tractable computation. However, existing methods are largely problem-agnostic, operating solely on the uncertainty set without consulting the feasible region or recourse structure. In this paper, we introduce PRISE, a problem-driven sequential lookahead heuristic that constructs reduced scenario sets by evaluating the marginal impact of each scenario. While PRISE yields high-quality scenario subsets, each selection step requires solving multiple subproblems, making it computationally expensive at scale. To address this, we propose NeurPRISE, a neural surrogate model built on a GNN-Transformer backbone that encodes the per-scenario structure via graph convolution and captures cross-scenario interactions through attention. NeurPRISE is trained via imitation learning with a gain-aware ranking objective, which distills marginal gain information from PRISE into a learned scoring function for scenario ranking and selection. Extensive results on three 2RO problems show that NeurPRISE consistently achieves competitive regret relative to comprehensive methods, maintains strong calability with varying numbers of scenarios, and delivers 7-200x speedup over PRISE. NeurPRISE also exhibits strong zero-shot generalization, effectively handling instances with larger problem scales (up to 5x), more scenarios (up to 4x), and distribution shifts.
Towards Efficient Constraint Handling in Neural Solvers for Routing Problems
Feb 17, 2026Neural solvers have achieved impressive progress in addressing simple routing problems, particularly excelling in computational efficiency. However, their advantages under complex constraints remain nascent, for which current constraint-handling schemes via feasibility masking or implicit feasibility awareness can be inefficient or inapplicable for hard constraints. In this paper, we present Construct-and-Refine (CaR), the first general and efficient constraint-handling framework for neural routing solvers based on explicit learning-based feasibility refinement. Unlike prior construction-search hybrids that target reducing optimality gaps through heavy improvements yet still struggle with hard constraints, CaR achieves efficient constraint handling by designing a joint training framework that guides the construction module to generate diverse and high-quality solutions well-suited for a lightweight improvement process, e.g., 10 steps versus 5k steps in prior work. Moreover, CaR presents the first use of construction-improvement-shared representation, enabling potential knowledge sharing across paradigms by unifying the encoder, especially in more complex constrained scenarios. We evaluate CaR on typical hard routing constraints to showcase its broader applicability. Results demonstrate that CaR achieves superior feasibility, solution quality, and efficiency compared to both classical and neural state-of-the-art solvers.
Learning to Optimize Capacity Planning in Semiconductor Manufacturing
Sep 19, 2025In manufacturing, capacity planning is the process of allocating production resources in accordance with variable demand. The current industry practice in semiconductor manufacturing typically applies heuristic rules to prioritize actions, such as future change lists that account for incoming machine and recipe dedications. However, while offering interpretability, heuristics cannot easily account for the complex interactions along the process flow that can gradually lead to the formation of bottlenecks. Here, we present a neural network-based model for capacity planning on the level of individual machines, trained using deep reinforcement learning. By representing the policy using a heterogeneous graph neural network, the model directly captures the diverse relationships among machines and processing steps, allowing for proactive decision-making. We describe several measures taken to achieve sufficient scalability to tackle the vast space of possible machine-level actions. Our evaluation results cover Intel's small-scale Minifab model and preliminary experiments using the popular SMT2020 testbed. In the largest tested scenario, our trained policy increases throughput and decreases cycle time by about 1.8% each.
Generalizable Heuristic Generation Through Large Language Models with Meta-Optimization
May 27, 2025Heuristic design with large language models (LLMs) has emerged as a promising approach for tackling combinatorial optimization problems (COPs). However, existing approaches often rely on manually predefined evolutionary computation (EC) optimizers and single-task training schemes, which may constrain the exploration of diverse heuristic algorithms and hinder the generalization of the resulting heuristics. To address these issues, we propose Meta-Optimization of Heuristics (MoH), a novel framework that operates at the optimizer level, discovering effective optimizers through the principle of meta-learning. Specifically, MoH leverages LLMs to iteratively refine a meta-optimizer that autonomously constructs diverse optimizers through (self-)invocation, thereby eliminating the reliance on a predefined EC optimizer. These constructed optimizers subsequently evolve heuristics for downstream tasks, enabling broader heuristic exploration. Moreover, MoH employs a multi-task training scheme to promote its generalization capability. Experiments on classic COPs demonstrate that MoH constructs an effective and interpretable meta-optimizer, achieving state-of-the-art performance across various downstream tasks, particularly in cross-size settings.
Learning to Handle Complex Constraints for Vehicle Routing Problems
Oct 28, 2024



Vehicle Routing Problems (VRPs) can model many real-world scenarios and often involve complex constraints. While recent neural methods excel in constructing solutions based on feasibility masking, they struggle with handling complex constraints, especially when obtaining the masking itself is NP-hard. In this paper, we propose a novel Proactive Infeasibility Prevention (PIP) framework to advance the capabilities of neural methods towards more complex VRPs. Our PIP integrates the Lagrangian multiplier as a basis to enhance constraint awareness and introduces preventative infeasibility masking to proactively steer the solution construction process. Moreover, we present PIP-D, which employs an auxiliary decoder and two adaptive strategies to learn and predict these tailored masks, potentially enhancing performance while significantly reducing computational costs during training. To verify our PIP designs, we conduct extensive experiments on the highly challenging Traveling Salesman Problem with Time Window (TSPTW), and TSP with Draft Limit (TSPDL) variants under different constraint hardness levels. Notably, our PIP is generic to boost many neural methods, and exhibits both a significant reduction in infeasible rate and a substantial improvement in solution quality.
Learning Generalizable Models for Vehicle Routing Problems via Knowledge Distillation
Oct 14, 2022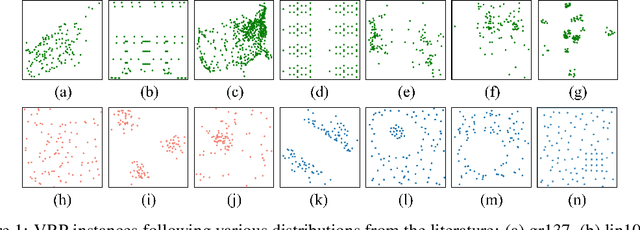
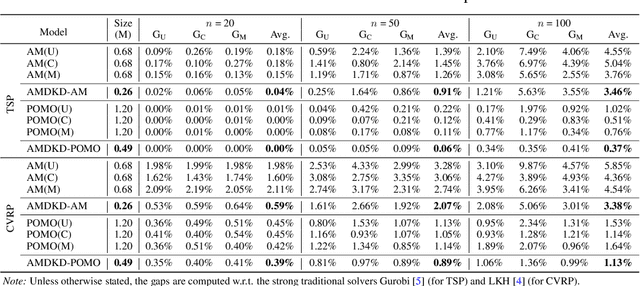
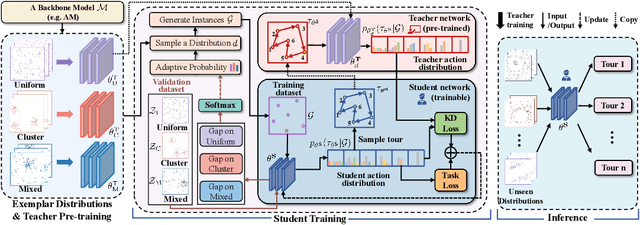
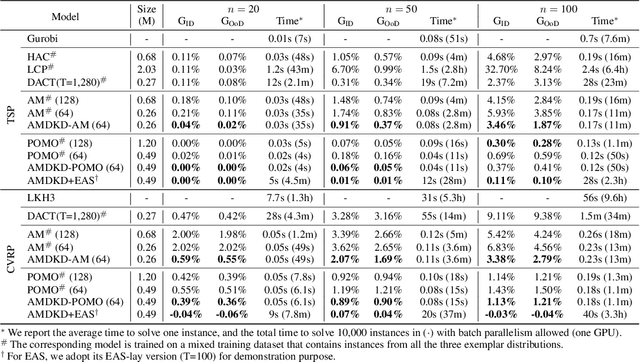
Recent neural methods for vehicle routing problems always train and test the deep models on the same instance distribution (i.e., uniform). To tackle the consequent cross-distribution generalization concerns, we bring the knowledge distillation to this field and propose an Adaptive Multi-Distribution Knowledge Distillation (AMDKD) scheme for learning more generalizable deep models. Particularly, our AMDKD leverages various knowledge from multiple teachers trained on exemplar distributions to yield a light-weight yet generalist student model. Meanwhile, we equip AMDKD with an adaptive strategy that allows the student to concentrate on difficult distributions, so as to absorb hard-to-master knowledge more effectively. Extensive experimental results show that, compared with the baseline neural methods, our AMDKD is able to achieve competitive results on both unseen in-distribution and out-of-distribution instances, which are either randomly synthesized or adopted from benchmark datasets (i.e., TSPLIB and CVRPLIB). Notably, our AMDKD is generic, and consumes less computational resources for inference.