 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Optimize Capacity Planning in Semiconductor Manufacturing
Sep 19, 2025In manufacturing, capacity planning is the process of allocating production resources in accordance with variable demand. The current industry practice in semiconductor manufacturing typically applies heuristic rules to prioritize actions, such as future change lists that account for incoming machine and recipe dedications. However, while offering interpretability, heuristics cannot easily account for the complex interactions along the process flow that can gradually lead to the formation of bottlenecks. Here, we present a neural network-based model for capacity planning on the level of individual machines, trained using deep reinforcement learning. By representing the policy using a heterogeneous graph neural network, the model directly captures the diverse relationships among machines and processing steps, allowing for proactive decision-making. We describe several measures taken to achieve sufficient scalability to tackle the vast space of possible machine-level actions. Our evaluation results cover Intel's small-scale Minifab model and preliminary experiments using the popular SMT2020 testbed. In the largest tested scenario, our trained policy increases throughput and decreases cycle time by about 1.8% each.
Towards Learning Stochastic Population Models by Gradient Descent
Apr 10, 2024Increasing effort is put into the development of methods for learning mechanistic models from data. This task entails not only the accurate estimation of parameters, but also a suitable model structure. Recent work on the discovery of dynamical systems formulates this problem as a linear equation system. Here, we explore several simulation-based optimization approaches, which allow much greater freedom in the objective formulation and weaker conditions on the available data. We show that even for relatively small stochastic population models, simultaneous estimation of parameters and structure poses major challenges for optimization procedures. Particularly, we investigate the application of the local stochastic gradient descent method, commonly used for training machine learning models. We demonstrate accurate estimation of models but find that enforcing the inference of parsimonious, interpretable models drastically increases the difficulty. We give an outlook on how this challenge can be overcome.
Automatic Gradient Estimation for Calibrating Crowd Models with Discrete Decision Making
Apr 06, 2024Recently proposed gradient estimators enable gradient descent over stochastic programs with discrete jumps in the response surface, which are not covered by automatic differentiation (AD) alone. Although these estimators' capability to guide a swift local search has been shown for certain problems, their applicability to models relevant to real-world applications remains largely unexplored. As the gradients governing the choice in candidate solutions are calculated from sampled simulation trajectories, the optimization procedure bears similarities to metaheuristics such as particle swarm optimization, which puts the focus on the different methods' calibration progress per function evaluation. Here, we consider the calibration of force-based crowd evacuation models based on the popular Social Force model augmented by discrete decision making. After studying the ability of an AD-based estimator for branching programs to capture the simulation's rugged response surface, calibration problems are tackled using gradient descent and two metaheuristics. As our main insights, we find 1) that the estimation's fidelity benefits from disregarding jumps of large magnitude inherent to the Social Force model, and 2) that the common problem of calibration by adjusting a simulation input distribution obviates the need for AD across the Social Force calculations, allowing gradient descent to excel.
Smoothing Methods for Automatic Differentiation Across Conditional Branches
Oct 05, 2023Programs involving discontinuities introduced by control flow constructs such as conditional branches pose challenges to mathematical optimization methods that assume a degree of smoothness in the objective function's response surface. Smooth interpretation (SI) is a form of abstract interpretation that approximates the convolution of a program's output with a Gaussian kernel, thus smoothing its output in a principled manner. Here, we combine SI with automatic differentiation (AD) to efficiently compute gradients of smoothed programs. In contrast to AD across a regular program execution, these gradients also capture the effects of alternative control flow paths. The combination of SI with AD enables the direct gradient-based parameter synthesis for branching programs, allowing for instance the calibration of simulation models or their combination with neural network models in machine learning pipelines. We detail the effects of the approximations made for tractability in SI and propose a novel Monte Carlo estimator that avoids the underlying assumptions by estimating the smoothed programs' gradients through a combination of AD and sampling. Using DiscoGrad, our tool for automatically translating simple C++ programs to a smooth differentiable form, we perform an extensive evaluation. We compare the combination of SI with AD and our Monte Carlo estimator to existing gradient-free and stochastic methods on four non-trivial and originally discontinuous problems ranging from classical simulation-based optimization to neural network-driven control. While the optimization progress with the SI-based estimator depends on the complexity of the programs' control flow, our Monte Carlo estimator is competitive in all problems, exhibiting the fastest convergence by a substantial margin in our highest-dimensional problem.
Differentiable Agent-Based Simulation for Gradient-Guided Simulation-Based Optimization
Mar 23, 2021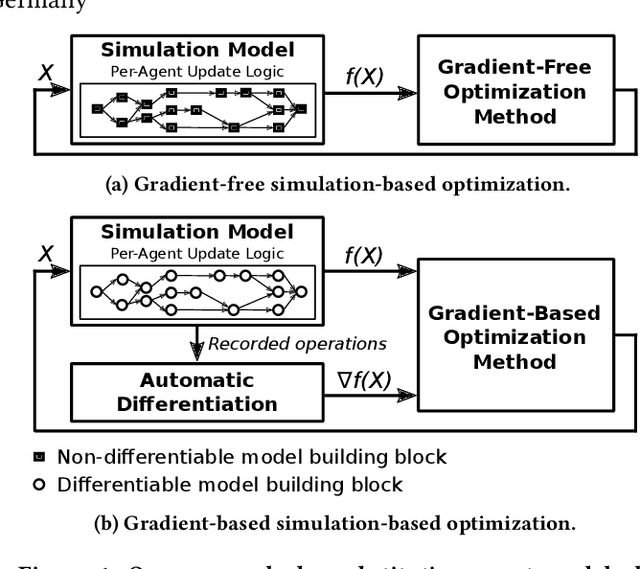
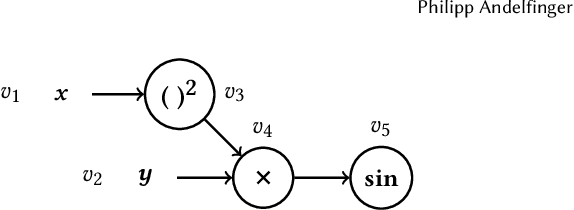
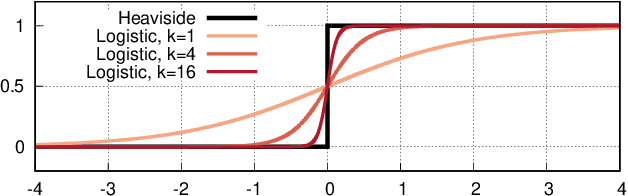
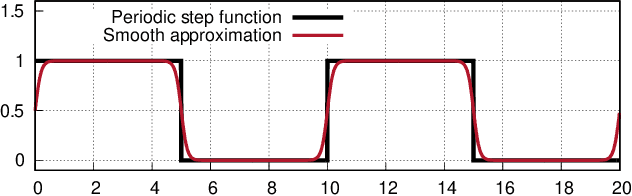
Simulation-based optimization using agent-based models is typically carried out under the assumption that the gradient describing the sensitivity of the simulation output to the input cannot be evaluated directly. To still apply gradient-based optimization methods, which efficiently steer the optimization towards a local optimum, gradient estimation methods can be employed. However, many simulation runs are needed to obtain accurate estimates if the input dimension is large. Automatic differentiation (AD) is a family of techniques to compute gradients of general programs directly. Here, we explore the use of AD in the context of time-driven agent-based simulations. By substituting common discrete model elements such as conditional branching with smooth approximations, we obtain gradient information across discontinuities in the model logic. On the example of microscopic traffic models and an epidemics model, we study the fidelity and overhead of the differentiable models, as well as the convergence speed and solution quality achieved by gradient-based optimization compared to gradient-free methods. In traffic signal timing optimization problems with high input dimension, the gradient-based methods exhibit substantially superior performance. Finally, we demonstrate that the approach enables gradient-based training of neural network-controlled simulation entities embedded in the model logic.